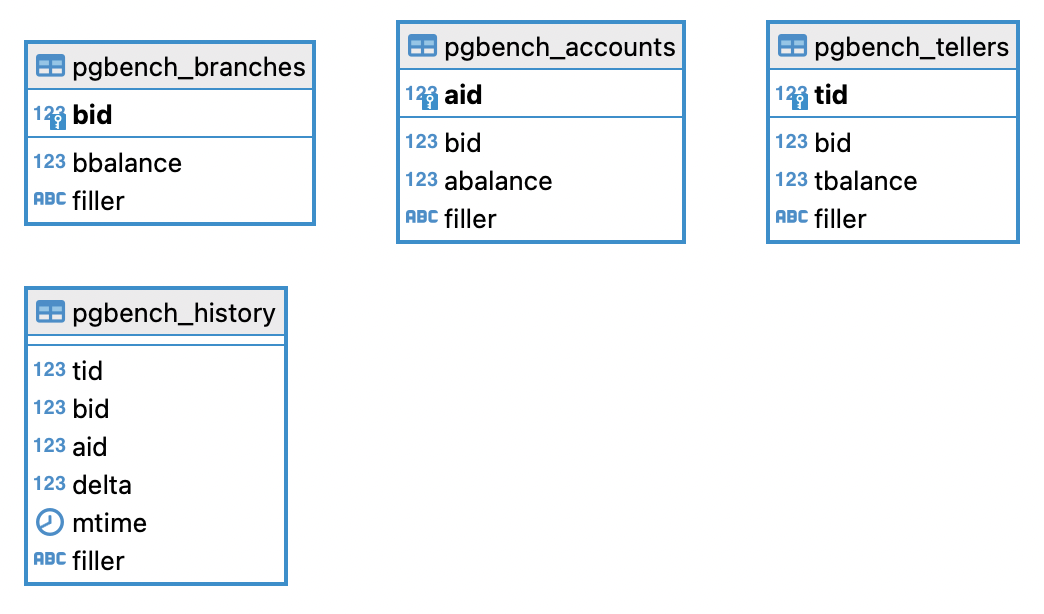
Lo schema e' costituito da tabelle con la seguente cardinalita':
La verifica delle prestazioni di un database relazione fa parte dei compiti principali di un DBA (DataBase Administrator). Questo documento cerca, con un taglio volutamente semplice e pratico, di fornire indicazioni utili per effettuare benchmark significativi su applicazioni reali orientate ai dati.
La prima parte del documento riporta i principali benchmark standard
per la valutazione delle prestazioni degli RDBMS
(Relational DataBase Management System).
I benchmark standard sono molto utili per confrontare RDBMS diversi o lo stesso RDBMS su piattaforme
differenti. Ma non sono molto utili per analizzare applicazioni reali.
Vengono quindi riportati diversi esempi di codice
per l'implementazione di benchmark.
Gli esempi sono basati su un benchmark standard
ma possono essere facilmente adattati a situazioni reali.
Gli esempi sono, in alcuni casi, programmi completi e funzionanti,
in altri casi snippet di codice.
Nel capitolo seguente vengono riportati alcuni tool Open Source e commerciali per misurare le prestazioni.
La parte finale del documento riporta la terminologia, alcuni importanti concetti di base, ... insomma una serie di indicazioni che, forse, dovrebbero essere riportate all'inizio ma che, essendo un poco piu' noiose, ho deciso di tenere alla fine!
Il Transaction Processing Performance Council (TPC) e' un organismo internazionale che disegna benchmark standard e ne omologa i risultati. I benchmark del TPC sono ritenuti i piu' importanti e significativi per la valutazione delle prestazioni dei sistemi che ospitano DBMS. Quindi li riportiamo per primi! I principali benchmark definiti dal TPC sono:
Ogni benchmark viene definito con un documento di specifiche molto
ampio e completo che ne definisce ogni aspetto (eg. scala o dimensione
della base dati, proprieta' ACID, durata minima dei run di test,
popolamento base dati, ...).
Per essere pubblicati
i risultati dei benchmark debbono essere validati da un Advisor
e vanno accompagnati da un documento che riporta tutti i dettagli
della configurazione e delle prove svolte.
L'impegno per effettuare un benchmark ufficiale e' molto oneroso
e viene sostenuto solo dai principali vendor HW e SW a fronte del
rilascio di nuovi e significativi prodotti.
I benchmark TPC sono molto utili poiche' forniscono una
metrica significativa e di facile raffronto
(eg. tpmC: transazioni TPC-C al minuto;
Price/tpmC: costo per transazione)
e possono essere implementati anche senza soddisfare
tutti i requisiti per l'omologazione fornendo comunque risultati
significativi.
Nel seguito utilizzeremo il benchmark TPC-B quale riferimento
per la realizzazione di
programmi in diversi ambienti e con differenti RDBMS.
Alcune implementazioni Open Source ispirate ai
test TPC si trovano in
questo link oppure in
questo link;
i workload sono differenti e quindi i risultati non
sono teoricamente confrontabili con i risultati dei benchmark TPC standard...
ma sono comunque significativi!
Oracle ha implementato un paio di questi test nel kit
OLT.
L'AS3AP (Ansi Standard Sql Scalable And Portable)
e' un benchmark che prevede una
serie di test da eseguire, tutti correttemente,
su una base dati in 24 ore di tempo. La metrica utilizzata e' la
dimensione della base dati (la dimensione massima di una base dati
che consenta di eseguire l'intero test nelle 12 ore previste).
Il test AS3AP e' stato ripresentato in diverse varianti
e versioni...
Una benchmark suite disponibile free in rete e'
l'OSDB (Open Source Database Benchmark) [NdE oramai non piu' mantenuto] all'indirizzo
http://sourceforge.net/projects/osdb
(ref. http://osdb.sourceforge.net).
Si tratta di un bench derivato dall'AS3AP ma con alcune significative differenze
(eg. non e' previsto il test di recovery, non ci sono limitazioni nella pubblicazione dei risultati)
che lo rendono piu' facilmente realizzabile.
Molto utilizzato e' anche sysbench perche' disponibile su tutte
le distribuzioni linux con una serie di test e di driver gia' configurati per accedere a MySQL ed a PostgreSQL:
con tre comandi da terminale si esegue un benchmark standard!
Con i sorgenti MySQL viene distribuita la MySQL benchmark suite (e l'utility "crash-me"). Sebbene possano essere utilizzate per la misurazione delle prestazioni, l'obiettivo della suite e' quello di verificare la presenza e la corretta implementazione delle funzionalita' in SQL. L'implementazione e' tale da consentire un raffronto (di tipo funzionale) anche con altri RDBMS. E' naturalmente disponibile come sorgente...
Con l'evolvere delle funzionalita' delle basi dati nascono e si diffondono nuovi benchmark. Sulle basi dati chiave-valore cosi' diffusi sulle piattaforme in Cloud e' possibile utilizzare YCSB (Yahoo! Cloud Serving Benchmark)...
Il test
EMP7
non e'
standard, ma e' terribilmente semplice da eseguire.
Con l'utente SCOTT/TIGER (demo di Oracle)
e' sufficiente eseguire,
impostando set timing on,
una select count(*) from emp, emp, ... 7 volte!
La tabella EMP ha 14 righe, ripetendo
sette volte il nome della tabella il numero di righe selezionate
e' pari a 147= 105.413.504 quindi cento milioni di righe circa:
perfetto per un test!
Il test e' CPU bound, va eseguito a sistema scarico ed interessa
il valore minimo ottenuto. Semplicissimo...
ma per i piu' pigri c'e' lo
script EMP7.sql gia' pronto.
Con altri RDBMS e' utilizzabile lo stesso test avendo l'avvertenza
di creare una tabella EMP con 14 righe. La sintassi puo' variare
leggermente poiche' alcuni RDBMS non accettano self-join...
Inoltre alcuni ottimizzatori riescono ad effettuare il prodotto
cartesiano senza accedere fisicamente a tutte le righe.
La query di partenza,
valida anche per Oracle in modo da poterlo confrontare
ad "armi pari", e' approssimativamente questa:
SELECT COUNT(*) FROM emp emp1, emp emp2, emp emp3, emp emp4, emp emp5, emp emp6, emp emp7 WHERE emp7.deptno=10;Un elenco di risultati ottenuti di recente con il benchmark EMP7 su differenti piattaforme e database e' riportato in questo Report. Il benchmark puo' essere eseguito utilizzando script gia' predisposti per differenti ambienti: Oracle, MySQL, Informix, PostgreSQL, SQLite, DB2, MS SQLServer, Grinder/Jython via JDBC, Hadoop Pig (uses this data file), ClickHouse, ... Maggiori dettagli sull'EMP7 si trovano su questo link.
Naturalmente i risultati di diversi benchmark dipendono dalle
prestazioni dei processori, dischi, software di base, ...
utilizzati dai sistemi in esame.
Anche se non e' l'obiettivo di questo documento, e' importante riportare
qualche indicazione per una valutazione di massima.
Per conoscere le prestazioni
dei processori presenti sulle varie macchine
e' possibile riferirsi benchmark specifici.
Tra i piu' validi ed utilizzati quelli pubblicati
dallo SPEC tra cui quelli
relativi alle CPU: CINT2000 e CFP2000.
I benchmark pubblicati dallo SPEC sono molteplici ed oltre
a quelli sulle prestazioni dei processori sono molto utilizzati
quelli relativi alla misurazione di applicazione J2EE.
Non conoscendo nulla sui sistema sotto test
e' possibile eseguire qualche semplice bench
per la misurazione della velocita' del processore.
Un programma C
compilato con l'ottimizzazione abilitata che effettua 100.000.000
di cicli ed assegnazioni a reali (double) puo' essere facilmente
utilizzato per confrontare le prestazioni di processori differenti:
Esempio ciclo su double
Controlli sulle prestazioni dello storage possono essere realizzati
in modo semplice con il comando dd mentre per la rete il
comando ping, con le diverse opzioni, permette
di effettuare tutti i test necessari sul network.
Ma per chi non si accontenta...
Oracle ha sviluppato un test per i dischi che simula il carico dell'RDBMS:
ORION
(ovviamente Oracle non lo dice ma il tool funziona benissimo per valutare le prestazione
dello storage anche se poi si utilizza un altro RDBMS ;-).
Mentre Netperf e' il piu' noto tool Open Source
per misurare le prestazioni di una rete.
Se quanto riportato fino ad ora non e' sufficiente... un'ampia raccolta di benchmark e' pubblicata nella Linux Benchmark Suite Homepage... buona lettura!
Il TPC-B e' un benchmark tipico per la misurazione delle prestazioni di una base dati a fronte di un carico transazionale.
La transazione TPC-B viene eseguita su una banca ipotetica
che ha una o piu' filiali. Su ciascuna filiale
piu' cassieri e conti correnti.
La transazione prevede un movimento di cassa
su un conto aggiornando le tabelle relative al conto,
al cassiere ed alla filiale.
Lo schema e' costituito da tabelle con la seguente cardinalita':
La transazione effettua il seguente ciclo di operazioni:
Il TPC-C e' un benchmark per la misurazione delle prestazioni
di una base dati a fronte di un carico transazionale.
La sua definizione e' piu' completa del benchmark TPC-B
poiche' prevede la presenza di un job-mix di transazioni
differenti. La base dati di riferimento e' quella di un magazzino.

La transazione misurata e' quella dell'Order Entry, ma e' presente un job-mix di altre transazioni eseguite in contemporanea sulla stessa base dati.
I programmi di test riportati nel seguito, che realizzano la transazione TPC-B standard, consentono l'effettuazione di una serie di prove parametrizzabili per simulare differenti situazioni. Poiche' sono riportati i sorgenti di tutti i programmi e gli script e' possibile utilizzarli sia per eseguire la transazione standard TPC-B che modificarli per inserire il proprio codice applicativo realizzando cosi' un benchmark reale.
I programmi ricevono come parametri gli elementi necessari
all'elaborazione su un RDBMS (eg. Username/password),
ed altri parametri di configurazione del test.
Il numero di esecuzioni in ciclo, le utenze attive,
la durata del tempo di pensamento ed il fattore di scala sono configurabili.
E' cosi' possibile generare attivita' differenti sulla base dati.
Con tempi di pensamento uguali a 0 si simulano attivita' batch.
Impostando ad un valore reale il tempo di pensamento dell'utente
(eg. 10 sec), possono essere effettuati test di stress.
Innalzando il numero di cicli il test risulta
meno influenzato da variazioni statistiche
(ma naturalmente richiede piu' tempo per l'esecuzione).
Il fattore di scala consente di utilizzare
lo stesso programma con generazione di codici random piu' ampi
(numero di branch) che agiscono su basi dati via via crescenti.
Innanzi tutto va preparata la base dati creando lo schema
(eg.
schema su Oracle
schema su MySQL
),
popolandolo con i dati richiesti
(eg.
caricamento dati su Oracle
caricamento dati su MySQL
)
e creando le eventuali Stored Procedure
(eg.
Stored Procedure in Oracle
Stored Procedure in MySQL
).
Possono quindi essere utilizzati i seguenti programmi,
realizzati su alcuni tra i piu' diffusi RDBMS:
I programmi implementano la transazione standard TPC-B ma possono essere semplicemente modificati per realizzare qualsiasi transazione applicativa.
I test effettuati con tempo di pensamento uguale a 0 simulano una attivita'
di tipo batch ed offrono un elemento di paragone
sulle prestazioni ottenibili sulle varie macchine.
Vengono in genere effettuate diverse serie di test
con numeri di utenze parallele crescenti.
Lo standard TPC-B prevede test con tempo di pensamento pari a 0.
I test effettuati con un tempo di pensamento uguale a 10
(simile al tempo di un utente reale)
non pesano eccessivamente sulla macchina ospite:
l'elapsed totale e' dovuto in gran parte ai tempi utente
e la variazione dei tempi dovuta ad un numero
maggiore di utenti operanti sulla stessa macchina e' limitato.
E' naturalmente possibile in questo modo simulare
un numero di utenti e di connessioni maggiori
generando un carico complesso e verificare cosi' eventuali limiti
del sistema e delle configurazioni adottate (eg. numero di sessioni utente).
Su un sistema Unix lanciare decine o centinaia di programmi in parallelo
e' banale. Lanciando i programmi descritti sopra o variazioni degli stessi
che sia piu' vicine alle applicazioni effettivamente presenti, e' possibile
simulare il carico voluto.
Meno banale e' invece il caricamento iniziale delle basi dati,
la creazione dei programmi di test (se si utilizzano test differenti
da quelli standard) e fare in modo che i test siano semplicemente
ripetibili...
Un programma che realizza il bench emp7 e' lo script Jython EMP7.PY richiamabile con Grinder su qualsiasi RDBMS raggiungibile via JDBC. La versione sotto forma di script SQL e' personalizzata per RDBMS: Oracle, MySQL, Informix, PostgreSQL, SQLite, DB2, Hadoop Pig (uses this data file), ...
Altro benchmark interessante e' quello relativo all'esecuzione di cicli nel linguaggio procedurale utilizzato per la realizzazione di Trigger e Stored Procedure: Procedural Language - Loop. Disponibile per basi dati diverse: Oracle, MySQL, PostgreSQL, ... Non e' mio ma e' molto indicativo anche lo script SQL JLOCI
Una volta pronti i programmi, la misurazione delle prestazioni non e' complessa.
Per raccogliere dati significativi e' necessario avere qualche
accortezza nel preparare i test: escludere i ramp-up ed i ramp-down,
effettuare i test a sistema dedicato, caricare il sistema con
il "rumore" corretto.
In caso contrario i dati raccolti sono semplicemente non significativi.
La matematica e la statistica sarebbero un obbligo per una corretta
raccolta dei dati ma
e' possibile procedere anche in modo empirico effettuando alcuni run
di test controllando che i risultati siano stabili.
Prima di effettuare le registrazioni dei tempi vengono quindi eseguiti
alcuni cicli: sia per prova, che per far andare a regime il sistema.
I tempi sono raccolti raccogliendo la media dei tempi elapsed totali.
Un numero di sessioni maggiore si ottiene semplicemente lanciando
piu' script in parallelo.
Teoricamente la preparazione di uno scenario di test con i corretti
ramp-up, il randez-vous per la partenza sincronizzata, la misurazione
di ogni singolo run e la completa analisi statistica di tutti i dati
e' l'unica modalita' utilizzabile.
Un trucco? Anziche' raccogliere i dati di tutti i programmi lanciati...
e' sufficiente costruire un buon rumore di fondo con n-1 processi
e, con sistema stabile, eseguire misurazioni precise di un singolo processo.
In poche ore potrete ottenere risultati affidabili che altrimenti avrebbero
richiesto settimane o strumenti appositi.
Raccolti i dati su uno spreadsheet e' semplice ottenere le statistiche
sui benchmark effettuati.
Nella figura che segue e' riportata una situazione tipica. Al crescere
del numero di utenti il Throughtput sale fino ad un massimo per rimanere
quasi costante per un certo periodo e quindi diminuire per il crescere
dell'overhead generato dal grande numero di sessioni parallele.
In un sistema stabile le prestazioni decadono lentamente.
In molti casi pero' si verifica il fenomeno del trashing in cui
il throughtput scende bruscamente a fronte di un maggiore carico
sul sistema.
In altri casi ancora, superato un certo limite, il sistema non elabora
piu' correttamente e le transazioni richieste dagli utenti vanno in errore.

E' spesso utile utilizzare programmi appositi per l'esecuzione di benchmark come quelli descritti nel seguito (The Grinder, JMeter, Hammer DB, Load Runner, Benchmark Factory). Il questo caso la raccolta dei dati, il lancio dei programmi, ... vengono eseguiti in automatico. Ma attenzione, nessuno strumento rendera' significativo un bechmark quando gli obiettivi non sono ben definiti!
The Grinder [NdA descrizione in italiano] e' un ottimo software free source per eseguire benchmark su applicazioni web. The Grinder puo' essere utilizzato facilmente anche per la realizzazione di benchmark su un DB relazionale. Infatti i test vengono scritti in Jython [NdA Jython e' un interprete Python realizzato in Java, la sintassi e' la stessa del Python] e possono quindi accedere ai DB via JDBC.
Nella figura che segue viene riportata l'esecuzione del benchmark TPC-B eseguita con questo script Jython. Prima di eseguire il test va creata la base dati lanciando lo script di creazione DB.

Altro esempio e' il benchmark emp7. In realta' le possibilita' del Grinder sono molto piu' ampie che la semplice esecuzione di benchmark su una base dati.
The Grinder e' fornito un HTTP Proxy per la registrazione della navigazione su applicazioni web. Gli script registrati possono essere modificati e composti tra loro realizzando scenari molto completi. E' inoltre possibile preparare script con qualsiasi livello di complessita' programmando con il semplice e potente linguaggio Jython (Python+Java). I test vengono sottomessi da una batteria di Agenti (generalmente ospitati su sistemi differenti) coordinati da un'unica console. I parametri di esecuzione sono modificabili agendo su un semplice file di configurazione che consente di definire il test in ogni sua componente (eg. numero di run, utenti simulati, distribuzione dei tempi, variazione del think time, ...) I risultati raccolti sono di semplice intepretazione e verifica da parte degli utenti e programmatori. Infine i file che contengono i risultati dei test (gia' mediati e con il calcolo del TPS) sono facilmente importabili su uno spreadsheet per generare report e statistiche molto efficaci, ...
Per maggiori dettagli sul Grinder si puo' fare riferimento alla documentazione in linea sul sito ufficiale ed anche a questa paginetta in italiano.
JMeter e' un'applicazione Open Source mantenuta da Apache che consente di effettuare test prestazionali. Sviluppata in Java ed inizialmente utilizzata per il test di applicazioni Web e' in realta' molto adatta anche per il test di basi dati connesse via JDBC.
E' piu' comune utilizzare JMeter per simulare accessi ad applicazioni web; anche in questo caso pero' puo' essere utilizzato per effettuare un benchmark sul database che e' utilizzato dall'applicazione.
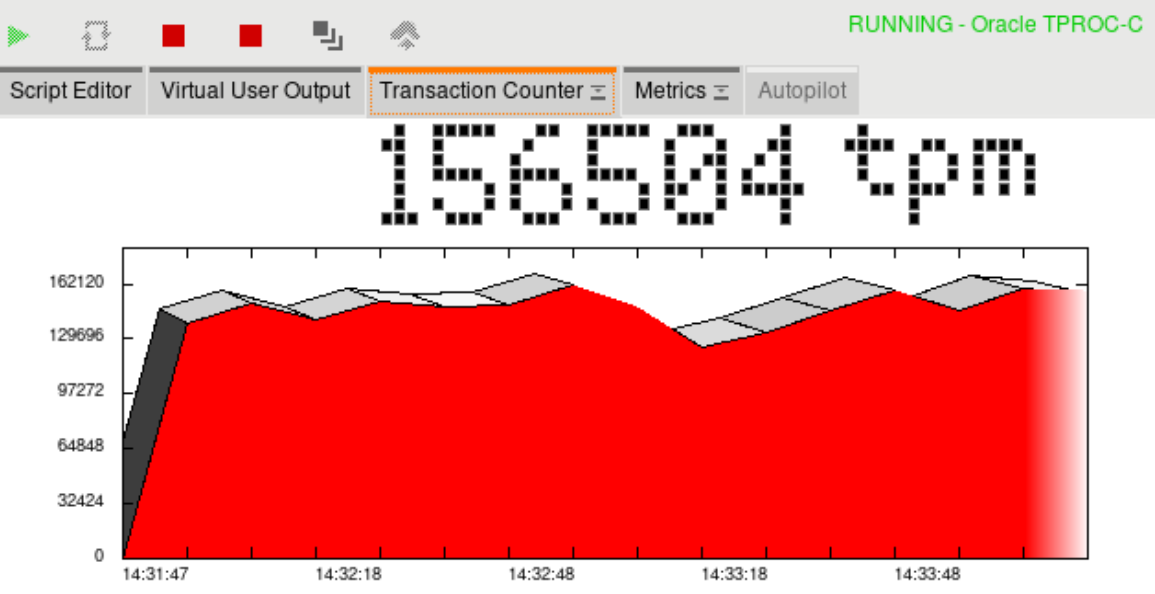
HammerDB e' un tool Open Source che implementa il benchmark TPC-C. E' mantenuto dal TPC su GitHub.
Disponibile su Linux e Windows per i database Oracle, SQL Server, IBM DB2, MySQL, MariaDB and PostgreSQL HammerDB e' particolarmente utile perche' fornisce risultati facilmente confrontabili [NdA i risultati non sono quelli ufficiali del benchmark e non possono essere confrontati tra release differenti; ma a parte queste due limitazioni HammerDB e' molto utile per valutare le differenze di prestazioni cambiando database e/o configurazioni].

|

|
La programmazione puo' essere effettuata con un interfaccia grafica o con un opportuno linguaggio di scripting.
I test vengono gestiti da una console centrale (Controller). Il Controller invia i comandi alle stazioni di test (Load Generator Agent o iniettori) che sottomettono le prove simulando il comportamento reale di centinaia o migliaia di utenti. La schedulazione dei test consente di definire in modo semplice test sequenziali, intervalli di ramp-up, ...
I dati vengono raccolti su un repository centrale che consente la loro sucessiva analisi. La reportistica generata da Load Runner e' molto completa ed integra i dati raccolti sui vari test con lo stato dei sistemi e delle basi dati interessati (se il tutto e' configurato opportunamente).
Oltre al sito ufficiale [NdA LoadRunner e' stato sviluppato da Mercury Interactive, Hewlett Packard Enterprise ha acquistato Mercury Interactive, Micro Focus ha acquistato da HP la componente dei servizi software tra cui LoadRunner] ho trovato questa concisa, ma tecnicamente assai completa, pagina su web.
Benchmark Factory e' un prodotto della Quest che consente la conduzione di Benchmark complessi su DB relazionali con un interfaccia grafica semplice e completa. La Quest (ora acquisita da Dell) e' molto conosciuta per i suoi prodotti di gestione delle basi dati come TOAD e Spotlight. In Benchmark Factory una serie di wizard guidano la creazione degli scenari di test e la conduzione dei benchmark in modo semplice e veloce. Il software gestisce automaticamente il ramp-up delle sessioni, la raccolta delle statistiche e la generazione dei grafici dei risultati. Tra i benchmark che e' possibile generare con pochi click vi e' il TPC-B gia' descritto in precedenza. Il prodotto puo' essere acquisito con un numero variabile di utenti virtuali simulati ed utilizza una connessione diretta netX all'RDBMS Oracle.

Un benchmark non risolve tutto. Un'architettura o un'applicazione disegnate in modo errato possono essere misurate, i sistemi possono avere un tuning accurato, ... ma il problema va corretto alla fonte. Da questo punto di vista l'esecuzione di un benchmark standard o di un'applicazione con funzionalita' simili servono da raffronto.
Eseguire un test sulle prestazioni e' come andare da un
oracolo.
La cosa piu' importante non sono le risposte che ci da'
ma le domande che noi facciamo!
Sembra una banalita' filosofica ma prima di analizzare al
millesimo di secondo i risultati ottenuti su un complesso
scenario eseguito da migliaia di utenti... e' meglio prima
capire a cosa servono il sistema e le applicazioni,
comprendere l'architettura dei vari componenti e
realizzare cosi' un test significativo!
Per un test di carico significativo e' a volte necessario disporre di piu' macchine su cui lanciare gli agenti. Altrettanto importanti sono le connessioni di rete che debbono essere ad alta velocita' e connesse direttamente, o il piu' direttamente possibile, ai sistemi che si vogliono misurare. In caso contrario ci si puo' accorgere che le nostre misurazioni, con un meccanismo complesso e con lunghe rilevazioni, stanno solo rilevando qualcosa che e' gia' perfettamente noto come la banda della rete o le prestazioni del nostro PC!
Quando si effettuano i test e' opportuno (leggi necessario) monitorare il comportamento dei sistemi coinvolti con gli strumenti di controllo delle performance (eg. vmstat 5). Questo vale sia per i sistemi che ospitano le applicazioni sotto test (eg. web server, application server, DB Server), che per i sistemi su cui viene generato il carico che per eventuali sistemi di supporto (eg. proxy server, load balancer, ...).
Vi sono parecchi altri tool importanti per il benchmark dei database non riportati in precedenza [NdA perche' piu' recenti o piu' di nicchia]: pgbench, DbUnit, Swingbench, sysbench, Oracle RAT, sqlmap [NdA un po' fuori tema...], TSDB [NdA anche questo fuori tema ma almeno relativo alle prestazioni], ...
I dati ottenuti nell'esecuzione dei test possono essere estrapolati per cercare di effettuare previsioni sul comportamento di un sistema sotto condizioni differenti.
Teoricamente i test restituiscono valori solo per i casi testati. Ma quando la risposta di un sistema e' "regolare" (non presenta una varianza elevata) e' possibile utilizzare l'interpolazione per calcolare i risultati dei casi non sperimentati. Personalmente uso solo l'interpolazione lineare (l'unica che riesco a capire ;-).
In molti casi un sistema presenta un bottleneck. E spesso questo si comporta con un tempo di servizio che non dipende dalla coda. Oltre a semplificare l'analisi del sistema riducendola all'analisi di una sola coda e quindi trattandola con metodi analitici e' inoltre possibile indicare dove agire per poter scalare le prestazioni sino al livello necessario. In pratica si tratta di determinarne la massima quantita' di servizio ed utilizzare questo come fattore per la valutazione dell'impatto.
Ma quali sono le formule per l'analisi di una coda? Dipende dalla coda!
La teoria parla di D/D/1, M/M/1 ... con un bel numero di casi e combinazioni.
Una formula utilizzata e' (utenti*richieste) / (periodo*TPS) dove il periodo e' in secondi ed il TPS e' relativo agli oggetti richiesti. In modo un po' piu' formale e' la legge dell'utilizzazione: U = XS. X ovviamente e' il Throughtput,
S il tempo di servizio ed U l'utilizzazione.
Molto utilizzata sono anche la formula di Little: N = XR (N numero medio di richieste, R tempo medio di risposta)
e la Response Law per i sistemi chiusi R=N/X-Z (Z tempo di pensamento).
Utilizzando la formula w=N/X e conoscendo il throughtput massimo, si riesce ad ottenere
analiticamente il numero massimo di utenti concorrenti che soddisfano le condizioni desiderate.
Ad esempio utilizzando la formula di Little e' possibile determinare il numero massimo di utenti simultanei
(eg. con tempo di pensamento=10) che consentano un tempo di risposta medio inferiore ai 5 secondi.
Le Bound Analisys consentono di modellere il comportamento di sistemi complessi
partendo da dati raccolti in modo molto semplice.
Naturalmente i risultati ottenuti con formule e calcoli non sono certi ma forniscono un'indicazione di massima. Per altro anche i dati di partenza non sono certi... ma ottenuti con un test. Tuttavia se le condizioni non cambiano in modo significativo il grado di affidabilita' e' comunque buono. Nel caso di variazioni significative (naturalmente ci si augura variazioni migliorative) su applicazioni o sul SW di base e' necessario effettuare nuove misurazioni.
Nello strano mondo della simulazione, dell'analisi delle prestazioni, degli stress test, ... si utilizzano una serie di termini che e' importante conoscere:
Anche un po' di matematica e statistica non farebbero male: distribuzione normale, uniforme, Erlang, generazione di numeri casuali, esponenziale negativa, teoria delle code, bottleneck analysis, coda M/M/1 (e' la classificazione delle catene di Markov), ... ma ve le risparmio!
Titolo: Benchmarking Relational DBMS
Livello: Avanzato
Data:
1 Novembre 2005
Versione: 1.0.17 - 14 Febbraio 2021
Autore: mail [AT] meo.bogliolo.name