Anatomia di SQLite
SQLite
e' il database relazionale piu' installato nel mondo!
SQLite e' molto semplice e la sua libreria puo' essere facilmente
inclusa nei programmi che lo utilizzano e
cosi' avviene in milioni di casi.
SQLite e' rilasciato come software in Public Domain,
quindi utilizzabile nel modo piu' ampio e senza alcuna limitazione.
Questo documento riporta i dettagli sulla struttura interna di SQLite
e sulla sua architettura.
Documenti introduttivi sono: Introduzione a SQLite
(una semplice introduzione a SQLite)
e Sotto il programma... SQLite
(l'analisi della struttura dei database SQLite usati dai piu' diffusi programmi per PC e Mobile).
Questo documento riporta dettagli tecnici sull'architettura interna di SQLite:
la sua lettura e' quindi riservata ad un pubblico adulto. Adulto in termini informatici:
se pensate che un albero binario serva a fare le traversine dei treni difficilmente
riuscirete a capire tutto il contenuto di questa pagina...
Per chi volesse comunque cimentarsi con la lettura trovera' elementi su:
architettura,
struttura fisica,
transazioni,
struttura logica,
pizza o spaghetti? (un esempio completo di analisi del contenuto di un DB),
ci sei o ci fai? (un esempio sul reperimento di dati cancellati).
Architettura
SQLite e' semplicemente una libreria. Il database e' semplicemente un file.
Basta includere la libreria nel link ed un qualsiasi programma
puo' utilizzare le funzioni di SQLite (sono presenti le API per
principali linguaggi di programmazione).
La libreria richiede pochi KB. E' tuttavia possibile diminuirne
ulteriormente la dimensione ed ottimizzarlo si dispositivi
con limitate caratteristiche HW.
SQLite non utilizza alcun processo, thread, segmento di memoria, ...
La struttura dati e' costituita da un solo file.
Il file ha un formato fisso ed e' identico
su tutte le piattaforme (eg. Big/Little Endian, 32/64 bit, Intel/Sparc/RISC/...).
Il database puo' essere spostato tra sistemi diversi con
una semplice copia ed utilizzato nello stesso modo su qualsiasi piattaforma.
Processi/programmi diversi possono accedere allo stesso DB.
Il lock in scrittura e' a livello del file, quindi dell'intero DB.
Quando un programma/processo
effettua una modifica nessun altro puo' leggere i dati (se non si utilizza il WAL).
SQLite e' molto robusto e soddisfa le caratteristiche ACID.
SQLite non e' adatto a gestire un grande numero di utenti in concorrenza, per
questo esistono ottimi database come Oracle, MySQL, PostgreSQL, DB2, SQLServer, ...
solo per citarne alcuni.
Ma per un singolo programma che deve memorizzare dati SQLite e' una scelta
ottimale.
Struttura fisica
Tutti i dati di database SQLite sono mantenuti su un solo file: il database file.
Oltre al database file possono essere presenti altri
file per la gestione delle transazioni:
il rollback journal o se SQLite e' in WAL (Write-Ahead Logging) mode, il write-ahead log file.
Per modificare la modalita' di gestione del journaling si utilizza il comando
PRAGMA journal_mode = [ DELETE | TRUNCATE | WAL | ... ].
Il file di database e' costituito da pagine. Tutte le pagine hanno la stessa dimensione che
puo' variare da 512 a 65536. Il numero massimo di pagine e' 231-2.
La dimensione massima del database e' di circa 140TB.
Ogni pagina ha un solo utilizzo:
b-tree page (table/index, interior/leaf),
freelist page (trunk, leaf),
overflow page,
pointer map page,
lock-byte page.
Il significato dovrebbe essere abbastanza ovvio dal nome...
cosa sono le foglie di un b-tree lo diamo per scontato.
La prima pagina (SQLite comincia da 1)
ha un header di 100 byte che descrive la struttura del DB
e' una b-tree page (table leaf per essere precisi) e contiene come dati
la tabella di catalogo di SQLite.
In questa pagina abbiamo cercato di descrivere solo il minimo
indispensabile per riuscire ad analizzare il file di database;
fate riferimento per maggiori dettagli a SQLite file format
cui abbiamo attinto direttamente.
Database Header Format
| Offset | Size | Description
|
|---|
| 0 | 16 |
The header string: "SQLite format 3\000"
|
| 16 | 2 |
The database page size in bytes. Must be a power of two between 512
and 32768 inclusive, or the value 1 representing a page size of 65536.
|
| 18 | 1 |
File format write version. 1 for legacy; 2 for WAL.
|
| 19 | 1 |
File format read version. 1 for legacy; 2 for WAL.
|
| 20 | 1 |
Bytes of unused "reserved" space at the end of each page. Usually 0.
|
| 21 | 1 |
Maximum embedded payload fraction. Must be 64.
|
| 22 | 1 |
Minimum embedded payload fraction. Must be 32.
|
| 23 | 1 |
Leaf payload fraction. Must be 32.
|
| 24 | 4 |
File change counter.
|
| 28 | 4 |
Size of the database file in pages. The "in-header database size".
|
| 32 | 4 |
Page number of the first freelist trunk page.
|
| 36 | 4 |
Total number of freelist pages.
|
| 40 | 4 |
The schema cookie.
|
| 44 | 4 |
The schema format number. Supported schema formats are 1, 2, 3, and 4.
|
| 48 | 4 |
Default page cache size.
|
| 52 | 4 |
The page number of the largest root b-tree page when in auto-vacuum or
incremental-vacuum modes, or zero otherwise.
|
| 56 | 4 |
The database text encoding. A value of 1 means UTF-8. A value of 2
means UTF-16le. A value of 3 means UTF-16be.
|
| 60 | 4 |
The "user version" as read and set by the user_version pragma.
|
| 64 | 4 |
True (non-zero) for incremental-vacuum mode. False (zero) otherwise.
|
| 68 | 24 |
Reserved for expansion. Must be zero.
|
| 92 | 4 |
The version-valid-for number.
|
| 96 | 4 |
SQLITE_VERSION_NUMBER
|
I primi 16 caratteri rendono facilmente riconoscibile un file di database SQLite.
Tutti i valori sono in big-endian (1 byte piu' significativo).
La dimensione del DB e' ottenuta moltiplicando la dimensione della pagina (byte 16)
per il numero di pagine (byte 28); se il risultato e' invalido (capita spesso con
le versioni meno recenti) la dimensione del DB e' semplicemente la dimensione
del file.
 Le foglie del b-tree per le tabelle hanno un header di 8 byte (12 byte per gli indici e per le pagine interne).
Poi viene rappresentato il cell pointer array che contiene i puntatori a tutti i record
contenuti nella pagina.
Segue lo spazio non allocato.
Infine i record con i dati inseriti dal basso verso l'alto.
Le foglie del b-tree per le tabelle hanno un header di 8 byte (12 byte per gli indici e per le pagine interne).
Poi viene rappresentato il cell pointer array che contiene i puntatori a tutti i record
contenuti nella pagina.
Segue lo spazio non allocato.
Infine i record con i dati inseriti dal basso verso l'alto.
I record vengono memorizzati al fondo della pagina. Via via che vengono aggiunti diminuisce
lo spazio libero, quando non e' piu' sufficiente viene allocata una nuova pagina (ovviamente
sono previste pagine di overflow per le update). Quando tutti i record di una pagina sono
cancellati la pagina viene inserita nella freelist. I dati non sono cancellati
ed il database non viene ridotto di dimensioni
(a meno che non sia attiva la modalita' auto_vacuum).
Si tratta di una caratteristica molto
importante per le analisi forensics poiche' consente di reperire anche dati
storici cancellati.
B-tree Page Header Format
| Offset | Size | Description
|
|---|
| 0 | 1 |
A flag indicating the b-tree page type
A value of 2 means the page is an interior index b-tree page.
A value of 5 means the page is an interior table b-tree page.
A value of 10 means the page is a leaf index b-tree page.
A value of 13 means the page is a leaf table b-tree page.
Any other value for the b-tree page type is an error.
|
| 1 | 2 |
Byte offset into the page of the first freeblock
|
| 3 | 2 |
Number of cells on this page
|
| 5 | 2 |
Offset to the first byte of the cell content area. A zero value is used to represent an offset of 65536, which occurs on an empty root page when using a 65536-byte page size.
|
| 7 | 1 |
Number of fragmented free bytes within the cell content area
|
| 8 | 4 |
The right-most pointer (interior b-tree pages only)
|
Immediatamente successivo all'header della pagina e' il cell pointer.
Si tratta di un array con due byte per ogni riga.
Segue lo spazio libero della pagina: non c'e' nulla da dire... non contiene nulla!
Infine nella pagina sono presenti i dati!
Per ogni record vi e' un header con la lunghezza totale, una descrizione del tipo di dato per ogni colonna
ed in coda il contenuto delle colonne.
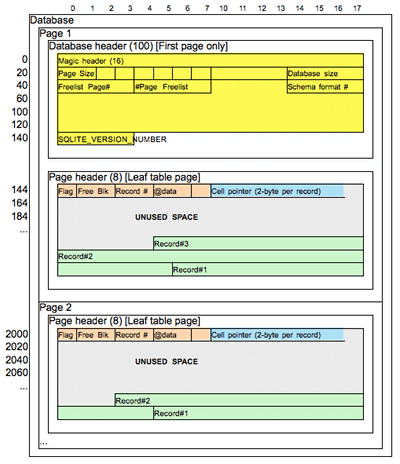 Riassumendo... abbiamo un solo file composto da piu' pagine;
un header iniziale di 100 byte; ogni pagina ha un uso ben preciso;
la prima pagina contiene l'header del database;
ogni pagina di dati (B-tree table leaf) contiene un header di pagina,
una serie di puntatori ai record presenti, spazio vuoto ed infine i dati.
Riassumendo... abbiamo un solo file composto da piu' pagine;
un header iniziale di 100 byte; ogni pagina ha un uso ben preciso;
la prima pagina contiene l'header del database;
ogni pagina di dati (B-tree table leaf) contiene un header di pagina,
una serie di puntatori ai record presenti, spazio vuoto ed infine i dati.
Lo schema complessivo delle pagine di database e' riassunto nella figura a destra.
Header del record e descrizione delle colonne utilizzano
un varint: un numero a dimesione variabile con codice di Huffman
(e' molto efficiente: i valori piu' bassi vengono sempre rappresentati con un solo byte).
I dati vengono memorizzati con 5 differenti storage class:
- NULL.
- INTEGER. Intero con segno che utilizza: 1, 2, 3, 4, 6, o 8 byte a secondo della necessita'.
- REAL. Numero reale in formato 8-byte IEEE floating point.
- TEXT. Stringa di testo (UTF-8, UTF-16BE, UTF-16LE).
- BLOB. Il dato e' memorizzato esattamente come e' stato inserito.
La scelta avviene dato per dato e non per colonna. Quindi ogni record ha l'indicazione
del tipo di dato memorizzato.
Serial Type Codes Of The Record Format
| Serial Type | Content Size | Meaning
|
|---|
| 0 | 0 |
NULL
|
| 1 | 1 |
8-bit twos-complement integer
|
| 2 | 2 |
Big-endian 16-bit twos-complement integer
|
| 3 | 3 |
Big-endian 24-bit twos-complement integer
|
| 4 | 4 |
Big-endian 32-bit twos-complement integer
|
| 5 | 6 |
Big-endian 48-bit twos-complement integer
|
| 6 | 8 |
Big-endian 64-bit twos-complement integer
|
| 7 | 8 |
Big-endian IEEE 754-2008 64-bit floating point number
|
| 8 | 0 |
Integer constant 0. Only available for schema format 4 and higher.
|
| 9 | 0 |
Integer constant 1. Only available for schema format 4 and higher.
|
| 10,11
| |
Not used. Reserved for expansion.
|
| N≥12 and even
| (N-12)/2 |
A BLOB that is (N-12)/2 bytes in length
|
| N≥13 and odd
| (N-13)/2 |
A string in the database encoding and (N-13)/2 bytes in length.
|
SQlite utilizza lo spazio strettamente necessario. Se un numero definito come
DDL come real e' in realta' un numero intero, viene rappresentato nel DB come tale
e poi restituito all'applicazione con il formato completo.
La freelist ha una struttura semplice.
La prima pagina della freelist e' puntata dall'intero 4-byte in posizione 32 del DB header,
il numero di pagine della freelist e' riportato nell'intero 4-byte in posizione 36 del DB header.
La lista principale e' costituita dalle trunk page.
Le pagine di questa lista contengono un puntatore 4-byte alle altre della lista
o 0 quando la lista e' terminata. In posizione 4 ciascuna pagina di questa lista
contiene il numero delle pagine libere foglie.
Quando tutti i record di una pagina sono cancellati la pagina viene inserita
nella freelist. Se la pagina viene inserita come foglia nella freelist nessuna
modifica ai dati viene effettuata.
Struttura fisica per la gestione delle transazioni
Oltre al file di database puo' essere presente un file per la gestione delle
transazioni.
Il Rollback Journal viene creato quando parte una transazione ed
e' dedicato a quella transazione (con SQLite viene eseguita una sola
transazione alla volta). Il nome del file e' lo stesso del file di
database cui viene appesa la stringa -journal.
L'header del file e' 0xd9d505f920a163d7.
Al termine della transazione il Rollback Journal viene cancellato
o annullato.
Dalla versione 3.7 e' possibile utilizzare il Write-Ahead Log.
La differenza principale con il Rollback Journal e' che il WAL log
puo' contenere piu' transazioni e queste possono essere riportate
sul database in modo asincrono.
Il nome del file e' lo stesso del file di
database cui viene appesa la stringa -wal.
L'header del file e' 0x377f0682 o 0x377f0683.
Il WAL log contiene diverse transazioni, queste vengono scaricate
sul DB durante i checkpoint. Il WAL log tipicamente non viene
mai cancellato.
Struttura logica
Il dizionario dati o catalogo e' costituito da una sola tabella:
sqlite_master. Il contenuto della tabella sqlite_master e'
memorizzato nella pagina 1. La definizione e' come se fosse la seguente:
CREATE TABLE sqlite_master(
type text,
name text,
tbl_name text,
rootpage integer,
sql text
);
La tabella sqlite_master contiene la definizione di tutti gli altri oggetti
creati nel database.
Con una semplice select si possono determinare tutti gli oggetti presenti
nel DB: tabelle, indici, viste, trigger, ...
Anche se dati vengono memorizzati internamente solo su 5 differenti storage class
(NULL, INTEGER, REAL, TEXT, BLOB) SQLite supporta la maggioranza delle definizioni
di datatype: INT
INTEGER
TINYINT
SMALLINT
MEDIUMINT
BIGINT
UNSIGNED BIG INT
INT2
INT8
CHARACTER
VARCHAR
VARYING CHARACTER
NCHAR
NATIVE CHARACTER
NVARCHAR
TEXT
CLOB
REAL
DOUBLE
DOUBLE PRECISION
FLOAT
BLOB
NUMERIC
DECIMAL
BOOLEAN
DATE
DATETIME
...
La scelta sulla storage class di memorizzazione avviene per affinita' e comunque cercando
di occupare il minor spazio fisico possibile.
Tutti i datatype di SQLite sono una specializzazione delle storage class descritte in precedenza.
Non esiste una storage class per le date che vengono memorizzate come testo
(eg. formato ISO8601: YYYY-MM-DD HH:MM:SS.SSS) o come numerico (eg. secondi da Epoch
ma ci sono moltissime variazioni sul tema).
La scelta e' ovviamente effettuata da chi scrive il programma che utilizza SQLite.
Pizza o Spaghetti?
E' ora di vedere un esempio pratico. Creiamo una tabella, introduciamo i dati
e quindi vediamo il contenuto in binario del database:
sqlite3 my.db
SQLite version 3.7.6
create table vota(product, point number);
insert into vota(product, point) values ('pizza', 10);
insert into vota(product, point) values ('spaghetti', 9.5);
^D
ls -l my.db
-rw-r--r-- 1 root root 2048 Apr 1 17:17 my.db
od -c my.db
0000000 S Q L i t e f o r m a t 3 \0 DB Header
0000020 004 \0 001 001 \0 @ \0 \0 \0 003 \0 \0 \0 002
0000040 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 001 \0 \0 \0 001
0000060 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 001 \0 \0 \0 \0
0000100 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0
0000120 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 003
0000140 \0 - 342 036 \r \0 \0 \0 001 003 302 \0 003 302 \0 \0 PAGE1 Header
0000160 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0
* Free space
0001700 \0 \0 < 001 006 027 025 025 001 ] t a b l e v
0001720 o t a v o t a 002 C R E A T E T Catalog
0001740 A B L E v o t a ( p r o d u c
0001760 t , p o i n t n u m b e r )
0002000 \r \0 \0 \0 002 003 337 \0 003 365 003 337 \0 \0 \0 \0 PAGE2 Header
0002020 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0
* Free space
0003720 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 024 Record #2
0003740 002 003 037 \a s p a g h e t t i @ # \0
0003760 \0 \0 \0 \0 \0 \t 001 003 027 001 p i z z a \n Record #1
0004000
Dal dump si vede subito che si tratta di un DB SQLite: l'header e' chiarissimo!
(NdE la colonna a destra con le descrizioni e' stata aggiunta per facilitare la lettura,
il comando unix "od" presenta solo i dati in ottale/...)
Analizzando il contenuto del file e' facile vedere che la base dati
e' costituita da due pagine di 1024 byte. La prima contiene la tabella
di catalogo. La seconda i dati della tabella delle votazioni.
I dati sono memorizzati al fondo della pagina partendo dal primo.
Il voto (difficile decidere se e' meglio la pizza o gli spaghetti) e'
memorizzato in maniera differente perche' in un caso e' un valore intero
(il 10 e' rappresentato come INTEGER storage class su 1 byte: serial 1).
Dettagli:
Page 1
DB HEADER (inizio: 000, lunghezza: 100 byte)
Magic header(000, 16): SQLite format 3\0
Page size(020, 2): 004 \0 big-endian ovvero in ottale 400 -> 1024
File format write version(022, 1): 1 -> legacy (2=WAL)
File format read version(023, 1): 1 -> legacy (2=WAL)
Database size(034, 4): 0 0 0 2 -> 2 pagine (2 pagine x 1024 -> 2048 dimensione totale)
Freelist (040, 4): 0 0 0 0 -> nessuna pagina cancellata
Page header (0144, 8)
Flag(0144, 1): \r (ASCII 13) -> leaf table b-tree page (2=ind int., 5=tab int., 10=ind leaf, 13 tab leaf)
Free Block(0145, 2): 0 0
Number of cells(0147, 2): 0 1 (1 record la definizione della tabella vota)
Content pointer(0151, 2): 03 0302 -> 962 (NB 03 0302 e' 01702)
Number of fragments(0153, 1): 0
Cell pointer array(0154, 2): 03 0302 -> 01702 (la lunghezza del cellpointer e' 2*#record)
Unallocated space
Record#1 (01702)
Header
Header lenght: < (ASCII 60)
Column description
...
Page 2 (02000, 1024)
Page header (02000, 8)
Flag(02000, 1): \r (ASCII 13) -> leaf table b-tree page
Free Block(02001, 2): 0 0
Number of cells(02003, 2): 0 2 (2 record: finalmente i dati!)
Content pointer(02005, 2): 03 0337 -> 01737
Number of fragments(02007, 1): 0
Cell pointer array(02010, 4): 03 0365 -> 01765 (#1 record 03765)
03 0377 -> 01737 (#2 record 03737)
Unallocated space
Record #2
Header(3737):
Header lenght: 03
Column description(03742,2)
037 -> maggiore di 12 e dispari -> stringa; lunghezza (N-13)/2 037->31 (31-13)/2 :-> TEXT(9)
\a 007 -> 64-bit floating point
Data
TEXT(9): "spaghetti"
FLOAT: -> 9.5 (non ho fatto i conti: mi fido)
Record #1
Header(3765): \t (ASCII 09)
Header lenght: 03
Column description(03770,2)
027 -> maggiore di 12 e dispari -> stringa; lunghezza (N-13)/2 027->23 (23-13)/2 :-> TEXT(5)
001 -> intero 8 bit
Data
TEXT(5): "pizza"
INTEGER: \n (ascii 10) -> 10
Chiaro? Spero di si!
Si tratta solo di leggere il contenuto del file in binario seguendo il tracciato e le regole viste
in precedenza.
Ci sei o ci fai?
Ci sei?
Ovvero come trovare i dati cancellati?
Quanto abbiamo visto fino ad adesso in questa pagina sulla struttura interna di SQLite
ci consente di approfondire gli esempi contenuti in
Sotto il programma... SQLite
per trovare i dati cancellati.
Quando un utente cancella i messaggi sul proprio iPhone questi non
vengono cancellati ma solo segnati come cancellati. Non viene fatta
una DELETE ma una UPDATE di un flag. L'utente non puo' piu' vederli dal suo iPhone
ma la query seguente eseguita sul DB SQLite sms.db e' comunque in grado di ritrovarli:
SELECT ROWID, case flags when 2 then 'Ricevuto' when 3 then 'Inviato' when 33 then 'Fail'
when 129 then '*Del' else 'Unkn' end as tipo,
address as numero_tel, datetime(date,'unixepoch','localtime') as data, text as messaggio
FROM message
... TODO
Tuttavia vi sono condizioni in cui l'iPhone cancella effettivamente i messaggi con una
DELETE (eg. dopo una sincronizzazione con iTunes). In questo caso i dati sono cancellati
e non possono essere ritrovati con una SELECT. Ma le pagine che contenevano i dati non
sono effettivamente cancellate bensi' vengono inserite nella freelist di SQLite.
Quindi fanno ancora parte del file di database anche se non piu' accessibili da SQL.
Il primo modo per determinare se vi sono pagine cancellate e' quello di utilizzare
il tool sqlite3_analyze
(disponibile sul sito ufficiale SQLite).
Il comando e' semplice e, avendo capito i concetti riportati in questa pagina,
l'output che riporta e' ben comprensibile.
Anziche' seguire la freelist (partendo dal puntatore in posizione 32 del DB Header),
un semplice trucco per determinare le pagine cancellate e' quello di copiare il DB file ed effettuare
il vacuum sulla copia. Le pagine differenti tra il file originale e quello copiato sono quelle eliminate
dal vacuum e contengono i dati cancellati. Una semplice lettura del diff consente di comprendere
se c'e' qualcosa di interessante da analizzare ulteriormente.
sqlite3_analize sms.db
... TODO
Infine e' possibile analizzarne i dati in binario cononoscendo la struttura
interna di SQLite come fatto nell'esempio precedente.
Anziche' partire dal catalogo e cercare le pagine leaf B-tree (che contengono i dati "vivi"),
andremo a cercare nella spazzatura seguendo la freelist che contiene le pagine cancellate:
od -c sms.db
0000000 S Q L i t e f o r m a t 3 \0
0000020 004 \0 001 001 \0 @ \0 \0 \0 003 \0 \0 \0 002
... TODO
Esempi piu' completi di analisi si trovano su:
http://www.simplecarver.com/exchange/articles/article-41.html
http://forensicsfromthesausagefactory.blogspot.it
Un prodotto in grado di effettuare il recovery dei dati cancellati
e' epilog
(NdA gira solo su MS-Windows e non ho avuto ancora occasione di utilizzarlo).