L'UTF-8 e' una rappresentazione dei caratteri Unicode che utilizza
un numero variabile di byte per rappresentare un carattere.
La rappresentazione e' generalmente efficiente poiche'
i caratteri piu' comuni (gli ASCII, ma per essere
corretti i caratteri Basic Latin) sono rappresentati con un solo byte.
Gli altri caratteri vengono rappresentati con due, tre o quattro byte.
Pertanto la lunghezza in byte di una stringa puo'
essere fino a quattro volte maggiore del numero di caratteri.
L'UTF8 e' stato definito in un RFC ed e' la modalita' di rappresentazione
piu' comune su Internet.
L'UTF-8 e' infatti utilizzato
da una ampia serie di browser per la rappresentazione dei caratteri
nazionalizzati.
Poiche' l'UTF 8 e' una rappresentazione dei caratteri Unicode
e' necessario riportare qualche notizia su tale standard.
Unicode e' uno standard per la rappresentazione dei caratteri.
Il suo obiettivo e' quello di una definizione unica per tutti
i caratteri di tutti i linguaggi.
Unicode non definisce una specifica implementazione
e quindi una univoca rappresentazione dei caratteri.
Sono possibili diverse implementazioni dello standard
che rispondono ad esigenze specifiche.
Alcune implementazioni utilizzano una lunghezza variabile
(eg. UTF-8),
altre fissa (naturalmente su piu' byte),
alcune privilegiano l'efficienza computazionale,
altre cercano di ridurre lo spazio di memoria utilizzato, ...
Unicode definisce tutti i caratteri di tutti i linguaggi
e li riporta codificandone un nome ed un progressivo.
I caratteri sono raccolti in tabelle.
Nel seguito sono riportate alcune delle tabelle maggiormente significative.
Nella tabella seguente sono riportate alcuni Code Points per i
caretteri ed i simboli piu' diffusi.
Benche' esistano diverse alternative e possibilita'
per la definzione di una base dati con caratteri multilingua,
quella piu' comune utilizza il character set UTF8.
L'UTF8 e' quindi un character set che implementa lo Unicode.
L'UTF8 utilizza un byte per i caratteri ASCII (7 bit),
due byte per i caratteri "europei", tre byte per l'ebraico, ...
Le dimensioni sul DB e sulle applicazioni debbono quindi essere aumentate.
Non tutte le sequenze di byte sono stringhe corrette in UTF-8.
Nella tabella seguente sono riportate le sequenze legali in UTF-8
ed i Code Point corrispondenti.
Per tradurre in UTF-8 un carattere Unicode
e' sufficiente trovare il Code Point del carattere
ed utilizzare la precedente tabella per trovarne la rappresentazione.
Leggendo la tabella e' chiaro che se il primo bit e' 0 si tratta di un carattere
rappresentato da un solo byte mentre se e' 1 si tratta di un carattere rappresentato
da una sequenza di byte.
Attenzione: vi sono sequenze di byte che non corrispondono ad un carattere UTF-8!
Ad esempio C2 69 non e' una sequenza UTF-8 valida: nella tabella appena presentata
non ha alcuna rappresentazione.
L'RDBMS Oracle permette una gestione completa della nazionalizzazione.
Puo' infatti gestire differenti formati di date, valute, rappresentazioni
numeriche e, naturalmente, di character set.
Per maggiori dettagli sulla gestione della nazionalizzazione
consultate il documento
Nazionalizzazione in Oracle.
Su Unix storicamente si sono sempre utilizzati i soli caratteri ASCII,
anzi qualcuno ricordera' anche la simpatica gestione del login in
uppercase per consentire di lavorare anche sulle teletype...
Ma molto tempo e' passato da allora! Un comando utile per
eliminare caratteri "strani", magari UTF8, e':
Non poteva mancare qualche bella immagine!
Per comporre i caratteri UTF-8 a due byte va utilizzata la regola di composizione vista in precedenza.
Il primo byte sara' C2 per i primi 64 caratteri, C3 per i successivi e cosi' via fino DF.
Il secondo byte e' dato dalla somma esadecimale di colonna+riga+80
(eg. il carattere sara' C2 A9, la à sara' C3 A0).
Per il simbolo dell'euro € il Code Point e' € ovvero 20AC.
Nella tabella e' su 3 byte, facendo i conti la codifica UTF-8 risulta essere: E2 82 AC
Il sito ufficiale di Unicode, completo e di facile consultazione si trova su
http://www.unicode.org
Un interessante esempio di rappresentazione di caratteri in molteplici linguaggi si trova su:
questa pagina.
La rappresentazione di Unicode in UTF-8 e' stata proposta come standard.
L'RFC puo' essere trovata su
ftp://ftp.rfc-editor.org/in-notes/rfc2279.txt
Testo: UTF 8
Control and Basic Latin 0000 Glyph
8859-1 (Latin-1), Based on ISO 00A0 Glyph
8859-2, -3, -4, -9 (European Latin), Based on ISO 0100 Glyph A - Glyph B
8859-7 (Greek), Based on ISO 0370 Glyph
8859-5 (Cyrillic), Based on ISO 0400 Glyph
8859-6 (Arabic), Based on ISO 0600
8859-8 (Hebrew), Based on ISO 05D0
Currency Symbols 20A0 Glyph
Ovvi svantaggi sono la crescita delle dimensioni del DB
e riduzione di prestazioni per le conversioni.
Le conversioni sono particolarmenti pesanti quando si utilizzano
formati di lunghezza fissa (eg. il datatype CHAR su Oracle).
Gli svantaggi sono bilanciati dal vantaggio di supportare piu'
linguaggi in contemporanea.
Code Points 1st Byte 2nd Byte 3rd Byte 4th Byte
U+0000..U+007F 00..7F
U+0080..U+07FF C2..DF 80..BF
U+0800..U+0FFF E0 A0..BF 80..BF
U+1000..U+FFFF E1..EF 80..BF 80..BF
U+10000..U+3FFFF F0 90..BF 80..BF 80..BF
U+40000..U+FFFFF F1..F3 80..BF 80..BF 80..BF
U+100000..U+10FFFF F4 80..8F 80..BF 80..BF
Per i caratteri ad un byte la conversione e' facile... il valore e' quello del CP (Code Point).
I caratteri a due byte utilizzano un secondo byte che va da 80 a BF. BF-80 = 3F
quindi ogni 40 CP si aumenta di uno il primo byte. Mentre per il secondo byte
si deve aggiungere 80 al modulo del CP con 40.
La scelta del character set su Oracle deve essere effettuata a
livello di database impostando il Database character set oppure,
a partire dalla versione 8, impostando il
National Character Set che specifica il character set dei tipi
di dati
NCHAR ed NVARCHAR.
Oltre all'UTF8 Oracle supporta il character set
AL16UTF16 con una codifica Unicode su due byte a lunghezza fissa.
tr -c -d "[:print:]\n"
Molto potente e' il comando iconv (provate a lanciarlo con --list):
iconv -f UTF8 -t UTF16 inputfile
myMac:~ meo$ iconv -t UTF-8 | od -cx
KKààèèéé
0000000 K K 303 240 303 240 303 250 303 250 303 251 303 251
4b4b a0c3 a0c3 a8c3 a8c3 a9c3 a9c3
La prima tabella e' la C0
che contiene i primi Code Point di Basic Latin A.
Per comporre i caratteri UTF-8 ad un byte
basta riportare prima la colonna e poi la riga della tabella (eg.
il carattere sara' 41, la K sara' 4B).
C0 Controls and Basic Latin (Range:0000-007F)

C1 Controls and Latin Supplement (Range: 0080-00FF)
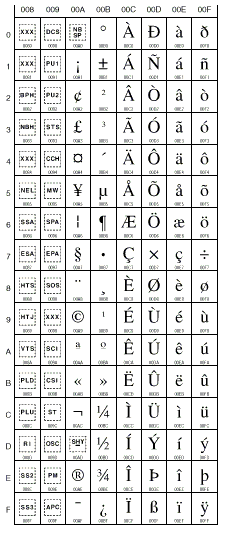
Latin Extended-A (Range: 0100-017F)

Latin Extended-B (Range: 0180-024F)

Greek (Range: 0370-03FF)

Cyrillic (Range: 0400-047F)

Currency Symbols (Range: 20A0-20CF)

E' di sicuro interesse per gli informatici, che notoriamente sono masochisti.
Infatti utilizza la seguente significativa frase ripetuta in tutti i linguaggi:
Posso mangiare il vetro, non mi fa male!
Data: 31 Gennaio 2003
Versione: 1.0.3 - 14 Febbraio 2008
Autore: mail@meo.bogliolo.name