MySQL e' un potente e diffuso database relazionale Open Source. La semplicita', la velocita' e la flessibilita' lo hanno reso il piu' diffuso DB per applicazioni web spesso in architettura LAMP. Ma le sue funzionalita' ne consentono un uso anche in modo massivamente parallelo ed in Cloud Computing.
Nel seguito sono riportate alcune informazioni di interesse organizzate in paragrafi specifici: Replicazione, Scalabilita' orizzontale, Esempio di configurazione, Sviluppo di applicazioni (Sharding e Partitioning, memcache), Cloud Computing.
La funzionalita' di replica dati di MySQL e' semplice da configurare, e' molto flessibile ed e' adatta per aumentare la scalabilita' del database e per un uso in Cloud. In questo documento viene presentato un esempio per scalare una base dati MySQL su decine o centinaia di server. Vengono inoltre presentati i principali aspetti tecnici per implementare una base dati MySQL in Cloud.
In una tipica configurazione di MySQL replication sono presenti
un solo Master, su cui avvengono tutte le modifiche dei dati,
ed uno o piu' Slave, su cui vengono replicati i dati e che viene utilizzato in sola lettura.
Poiche' una tipica applicazione su DB esegue un numero molto elevato di letture
rispetto alle modifiche, il numero dei DB Slave puo' essere elevato garantendo
cosi' tempi di risposta ottimali per tutte le SELECT.
Le attivita' di modifica vengono invece dirette al Master su cui
e' garantita la consistenza dei dati.
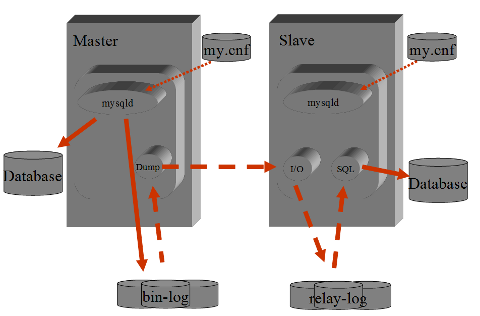
La replicazione su MySQL e' statement based ed asincrona.
Il Master si occupa di registrare su file (bin-log file)
tutti gli statement che vengono eseguiti sulla base dati
e che operano una qualche modifica ai dati (DML e DDL).
Lo Slave si collega con un thread al Master, raccoglie
il contenuto dei bin-log, lo trasferisce in locale e quindi
si occupa di applicarlo alla base dati.
La parte svolta dal Master e' molto semplice, poco onerosa
e "stupida". In pratica ospita una sessione client per ogni
Slave configurato.
La maggioranza delle opzioni di configurazione e la gestione
ricadono sullo Slave. E' questo che si occupa della ricezione
dei log, del loro allienamento e della corretta applicazione
degli statement SQL sulla base dati.
La replicazione in MySQL e' molto flessibile e
sono possibili molte alternative.
Gli Storage Engine utilizzati sullo Slave possono essere diversi
da quelli utilizzati sul Master. Questo consente di scegliere
l'Engine piu' adatto allo scopo (eg InnoDB sul Master in cui avvengono
le transazioni, MyISAM sullo slave su cui vengono effettuate
un selezioni o i backup).
Nel caso piu' semplice di replicazione un Master viene replicato su uno Slave. Se gli accessi in lettura al database sono molto elevati (eg. siti web molto acceduti) e' possibile configurare in modo semplice decine di Slave. In questo caso si parla di scalabilita' orizzontale: e' infatti possibile aumentare il throughtput del sistema in modo lineare semplicemente aggiungendo piu' macchine dello stesso tipo. La scalabilita' verticale e' invece tipicamente piu' costosta poiche' richiede di incrementare la potenza di una macchina aggiungendo componenti o sostituendola con una piu' performante.
Con la particolare configurazione descritta nel seguito
e' possibile aumentare il numero di Slave DB senza appesantire il Master
raggiungendo cosi' le centinaia di server Slave.
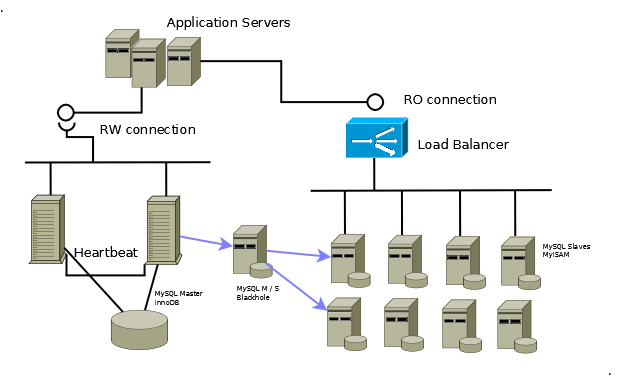
Uno Slave puo' comportarsi a sua volta da Master e questo puo'
essere utilizzato in cascata piu' volte.
In particolare, se il numero di Slave che si vuole mantenere
allineati e' molto elevato, si utilizza la catena
A -> B => Cn dove n e' puo' essere grande quasi a piacere.
A e' configurato come Master.
B e' configurato come Slave di A e Master di tutti i Cn.
In questa configurazione tutte le modifiche vengono applicate
sulla base dati A e trasferite su tutti i sistemi C acceduti in sola lettura.
E' una configurazione di replica MySQL
in daisy chain tra i primi livelli di master e petalosa sugli slave.
Per sfruttare al meglio tale architettura e' opportuno che le applicazioni
utilizzino due connessioni differenti: una per gli update e l'altra per le SELECT.
In caso contrario e' necessario separare gli accessi... ed e' possibile
farlo con MySQL Proxy.
Come abbiamo visto utilizzando la replicazione e' possibile costruire complesse architetture di database MySQL che soddisfano ai piu' stringenti requisiti di affidabilita' e scalabilita'.
| MySQL Massive Replication | MySQL Massive Replication and Proxy |
| 
|
Troppe parole! Vediamo un esempio: un database Master con 16 Slave per un'applicazione che utilizza connessioni distinte RO/RW.
[mysqld] server-id=10 log-bin=mysql-bin innodb_buffer_pool_size = 512M innodb_additional_mem_pool_size = 16M innodb_file_io_threads = 4 innodb_thread_concurrency = 16 innodb_flush_log_at_trx_commit = 2 innodb_log_buffer_size = 8M innodb_lock_wait_timeout = 120
[mysqld] server-id=20 log-bin=mysql-bin log-slave-updates default-storage-engine=BLACKHOLE
[mysqld] server-id=1XX read_only=1 key_buffer_size = 64M table_cache = 2048 read_buffer_size = 2M sort_buffer_size = 8M query_cache_size = 16M
Gia' fatto!?
Naturalmente va provato tutto (eg. comportamento delle applicazioni sulle primary key in auto increment)...
ma la configurazione di decine o centinaia di Slave e' tutta qui!
La replicazione di MySQL e' generalmente trasparente alle applicazioni.
Accedere ai dati sul Master o sugli Slave non comporta infatti alcuna differenza.
L'unica avvertenza e' quella di dirigere tutte le attivita' di modifica verso il Master.
Per fare in modo che tutte le attivita' di modifica siano rivolte al Master e' possibile
agire in due modi:
La scrittura di applicazioni utilizzate in modo efficiente da migliaia o milioni di
utenti in contemporanea richiede un'attenta progettazione.
Con un'utilizzo attento di MySQL e' possibile scalare in modo orizzontale
sul database cosi' come e' possibile farlo sugli application server.
La prima distinzione e' quella tra gli accessi in scrittura e quelli in lettura,
nel prossimi capitoli le connessioni saranno ancora piu' differenziate o saranno
precedute da accessi non relazionali.
Un ultimo commento...
Le basi dati debbono essere ben disegnate e cosi' deve essere anche per le applicazioni!
Indici non selettivi, tabelle non normalizzate, accessi inutili o ripetuti sono errori
comuni...
Su applicazioni usate in modo appena significativo gli errori di
disegno rendono praticamente insufficiente qualsiasi infrastruttura sia predisposta.
Prima di pretentere la scalabilita' di un'applicazione, prova a farla funzionare bene!
Al crescere delle dimensioni della base dati l'accesso in scrittura diventa sempre piu' pesante. E questo sia sul Master che sugli Slave che debbono comunque replicare le modifiche occorse. A questo punto l'unica soluzione e' diminuire la dimensione della base dati!
Una prima possibilita' e' quella di isolare componenti applicative
ed utilizzare database differenti per ciascun gruppo. In questo modo
e' possibile utilizzare gruppi di database differenti ciascuno di minori
dimensioni.
E' inoltre possibile dividere le tabelle applicativamente in modo orizzontale.
Questo richiede generalmente una modifica relativamente semplice nelle applicazioni
per determinare a quale database accedere. Naturalmente si perde la possibilita'
di effettuare join... ma se il problema e' quello di gestire milioni di accessi
in contemporanea nessun join globale potrebbe essere efficiente.
La scelta su come suddividere le basi dati e' molto importante.
Questa tecnica di partizionamento orizzontale delle tabelle e'
detta sharding.
Con MySQL, cosi' come su tutti i DB relazionali, e' semplice implementare
lo Sharding a livello applicativo.
Dalla versione 5.1 di MySQL e' disponibile il partitioning.
Con il partitioning non e' richiesta alcuna modifica applicativa poiche'
si tratta di un meccanismo di memorizzazione interno alla base dati.
Con il pruning il partizionamento puo' fornire miglioramenti
prestazionali elevati. Tuttavia tutte le partizioni sono ospitate sullo stesso server.
Quindi se, oltre a migliorare l'accesso ad una tabella, e' necessario separare il carico
scalandolo su piu' server, il partizionamento non e' sufficiente e
debbono essere applicate le tecniche descritte nei paragrafi
precedenti.
Con MySQL il partitioning e' completamente trasparente a livello applicativo
anche se vanno utilizzati alcuni accorgimenti nelle query per sfruttarlo appieno.
La tecnica di raccogliere in una cache i dati che vengono richiesti piu' volte puo' essere applicata a piu' livelli migliorando notevolmente le prestazioni e consentendo un numero maggiore di accessi alla applicazione ed al database. Lo stesso avviene quando e' possibile effettuare eleborazioni pesanti prima che vengano richieste. Anche la dernomalizzazione e l'overnormalizzazione dei dati possono dare buoni risultati. Ma tutte queste tecniche dipendono dall'applicazione e richiedono generalmente una codifica accorta ed impegnativa.
memcache e' una cache distribuita che consente di reperire in modo
rapido i valori associati ad una chiave. L'uso di memcache permette di
evitare accessi ad una base dati nelle ricerche piu' utilizzate e semplici.
L'implementazione e' semplice. Uno o piu' server mantengono in memoria
una cache costituita da una enorme tabella ad hash. La chiave puo' essere
lunga fino a 250 caratteri, il dato fino ad un MB. L'utilizzo e' in
client server (tipicamente sulla porta 11211) con API disponibili
praticamente con ogni linguaggio.
In pratica anziche' ricercare il risultato con l'SQL come in questo esempio (PHP):
$risultato = array();
$sql = "SELECT * FROM emp WHERE ename like ". $cond;
$res = mysql_query($sql, $mysql_connection);
while($rec = mysql_fetch_assoc($res)){
$risultato[] = $rec;
}
Si effettua prima una ricerca su memcache, nella maggior parte dei casi
si ottiene la risposta (in tempi brevissimi). Se non si trova il risultato su memcache
si ricavano i dati richiesti accedendo al DB e poi si inserisce il record nella cache
per rendere piu' veloci i successivi accessi.
Modificare il codice e' molto semplice, bastano una if() e due comandi in piu':
if( ! $risultato = $memcache->get("emp like:" . $cond) ){
$risultato = array();
$sql = "SELECT * FROM emp WHERE ename like ". $cond;
$res = mysql_query($sql, $mysql_connection);
while($rec = mysql_fetch_assoc($res)){
$risultato[] = $rec;
}
$memcache->set("emp like:" . $cond, $risultato, 3600);
}
Non e' tutto cosi' facile perche' ci sono da gestire gli update, le cancellazioni,
la sincronizzazione tra server, ...
memcache non e' sempre applicabile perche' non c'e' autenticazione, gestione delle transazioni,
possibilita' di query complesse, ...
Ma e' terribilmente semplice e veloce!
In particolare se usato per evitare accessi alla base dati per query eseguite moltissime volte.
memcache e' un software Open Source e puo' essere scaricato da questo sito.
MySQL e' facilmente utilizzabile in ambienti virtualizzati. Generalmente non e' necessaria alcuna variazione nella configurazione. In qualche caso si presentano limiti prestazionali legati all'accesso verso lo storage, in questo caso e' opportuno un tuning specifico.
MySQL fornisce direttamente il supporto per alcune soluzioni Cloud come IaaS (eg. MySQL su Amazon EC2). Direttamente sul sito MySQL si possono trovare i riferimenti per la virtualizzazione ed il Cloud Computing. Oltre alle AMIs (Amazon Machine Images) e' inoltre possibile utilizzare anche il servizio Amazon RDS.
Ma in questo capitolo, piu' che il supporto ufficiale e gli accordi commerciali, vogliamo riportare alcuni importanti aspetti tecnici nella configurazione di MySQL in un Cloud.
Riassumendo MySQL e' un ottimo DB per un utilizzo in Cloud.
Semplice, flessibile e facilmente gestibile.
Con l'utilizzo di tecniche di replicazione, Sharding e cache (eg. memcache)
puo' scalare in modo molto elevato.
Per l'utilizzo di tecniche NoSQL... ne parleremo un'altra volta!
Titolo: Testo: Scalabilita' e Cloud Computing con MySQL Replication
Livello: Avanzato
Data:
1 Aprile 2010
Versione: 1.0.7 - 14 Febbraio 2016
Autore: mail [AT] meo.bogliolo.name