La funzionalita' di replica dati di MySQL e' semplice da configurare, non richiede praticamente manutenzione, e' molto flessibile e non aggiunge carico al database Master. E' percio' comprensibile che sia molto utilizzata. Gli impieghi sono diversi: per disporre di copie di database in HA (High Availability: alta affidabilita'), per creare una batteria di database per siti web molto acceduti, per semplificare modalita' e procedure di backup, ...
Nel seguito sono riportate alcune informazioni di interesse organizzate in paragrafi specifici: Introduzione, Configurazione, Architettura, Amministrazione (FAQ), Avvertenze per l'uso, Nuove funzionalita' (Stored Routine (5.0), Row Based Replication (5.1), Semi-synchronous (5.5), Crash safe, delayed, GTID, ... (5.6), Online CHANGE MASTER, Multi-source, ... (5.7), Group Replication, InnoDB Cluster, ... (8.0) ), Backup da Slave, Point in Time Recovery.
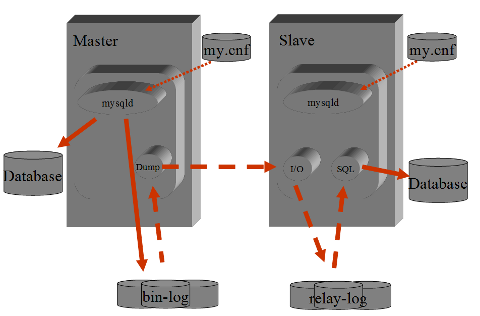
La replicazione su MySQL e' statement based ed asincrona.
Il Master si occupa di registrare su file (bin-log file)
tutti gli statement che vengono eseguiti sulla base dati
e che operano una qualche modifica ai dati (DML e DDL).
Lo Slave si collega con un thread al Master, raccoglie
il contenuto dei bin-log, lo trasferisce in locale e quindi
si occupa di applicarlo alla base dati.
La parte svolta dal Master e' molto semplice, poco onerosa
e "stupida". In pratica ospita una sessione client per ogni
Slave configurato.
La maggioranza delle opzioni di configurazione e la gestione
ricadono sullo Slave. E' questo che si occupa della ricezione
dei log, del loro allienamento e della corretta applicazione
degli statement SQL sulla base dati.
Sono possibili differenti configurazioni. Un Master puo' servire piu' Slave. Uno Slave puo' essere a sua volta Master di altri Slave. Possono essere esclusi/inclusi dalla replicazione database, tabelle, ... Il Master e gli Slave possono essere differenti praticamente in tutto: Storage Engine, parametri di configurazione/tuning, versioni, struttura, ... insomma: continuate a leggere!
La configurazione della replication e' piuttosto semplice anche se le possibilita' sono molteplici. La documentazione completa e' presente nel sito ufficiale, quindi nel seguito riportiamo solo un esempio di configurazione molto semplice... ma che copre tutti i punti fondamentali!
| Attivita' sul Master | Attivita' sullo Slave | Note |
|
[mysqld]
server-id=10 log-bin=mysql-bin | La configurazione del Master e' semplice: basta definire un server-id univoco ed indicare il nome dei file di log binario. Se l'utilizzo del database e' significativo e' opportuno porre il binlog su un file system separato per evitare un file system full. Altri parametri utili sono riportati nel seguito. | |
|
[mysqld]
server-id=20 read_only=1 | Anche la configurazione dello Slave e' semplice: server-id univoco e, se non si vuole che vengano modificati i dati sulla replica, parametro read_only. Altri parametri utili sono riportati nel seguito. | |
| grant replication slave on *.* to 'rep'@'%' identified by 'xyz'; | Non e' obbligatorio definire un nuovo utente ma e' consigliato sia per sicurezza che per semplicita' di configurazione e controllo | |
| Backup | Restore | Le modalita' backup/restore sono molteplici e dipendono da molti fattori. Nel caso piu' semplice le basi dati sono vuote e non c'e' nulla da fare! Se non avvengono modifiche sul Master un semplice mysqldump e' sufficiente... Altrimenti e' importante fare in modo che sia garantito l'allineamento delle basi dati (eg. FLUSH TABLES WITH READ LOCK; e backup oppure mysqldump --all-databases --single-transaction --triggers --routines --events --master-data). |
| show master status; | Con questo comando si ottiene lo stato della replicazione. In particolare sono necessari il nome del file ed il progressivo che servono per configurare la replicazione sullo Slave. Il comando deve essere lanciato prima di modificare i dati sul Master (UNLOCK TABLES). | |
| change master to master_host='myMaster.MyDomain.it', master_user='rep', master_port=3306, master_password='xyz', master_log_file='mysql-bin.000001', master_log_pos=69; | Con questo comando lo Slave sa come connettersi al Master. Vengono creati i file master.info e relay-log.info. I parametri in italico sono quelli ottenuti con il comando show master status. | |
| start slave; | Per far partire i thread dello Slave. Sono utilizzati un thread remoto (sul Master per inviare il bin-log) e due thread locali (per ricevere il bin-log ed applicarlo). | |
| show slave status\G | Gia' fatto! Non c'e' altro da configurare, con questo comando si controlla lo stato della replicazione. |
I passi riportati e le spiegazioni sono un po' semplificati ma...
funzionano e rendono l'idea (spero ;-)
E' ovvio che per far leggere i nuovi parametri del my.cnf e'
necessario riavviare il server, che per lanciare uno statement SQL
e' necessario collegarsi alla base dati...
E' inoltre fondamentale controllare l'utilizzo di spazio da parte
dei binlog: possono crescere molto piu' in fretta della base dati.
A seconda delle configurazioni utilizzate dovra' essere impostata
una pulizia periodica dei binlog obsoleti.
La configurazione vista nel paragrafo precedente e' gia' perfettamente funzionante e richiede l'impostazione di due soli parametri:server-id log-bin. E' pero' possibile configurare ulteriori parametri che forniscono ulteriori funzionalita' alla replicazione MySQL.
I database da replicare (di default vengono tutti replicati) si indicano con il parametro binlog-do-db oppure al contrario si possono escludere con binlog-ignore-db; queste impostazioni si effettuano sul Master ed hanno un grado di selettivita' diverso a seconda che si utilizzi la statement replication o la row replication. Analoghi parametri sono disponibili sullo Slave: il parametro replicate-do-db ovvero il parametro replicate-ignore-db. Per indicare singole tabelle si utilizzano i parametri replicate-do-table e che possono utilizzare wildcard.
I parametri di configurazione utilizzabili, come abbiamo visto, sono molteplici... Per riassumere riportiamo una configurazione adatta ad una semplice architettura in cui sono presenti un master ed uno slave configurati in replicazione per HA:
| Parametri Master | Parametri Slave |
|
[mysqld]
server-id=10 log-bin=mysql-bin binlog-ignore-db=test |
[mysqld]
server-id=20 log-bin=mysql-bin binlog-ignore-db=test read_only=1 |
Per essere sicuri che sullo slave non avvengano accessi e' stato utilizzato il parametro read_only=1 che bisogna aver cura di rimuovere quando lo Slave diventa Master (evento chiamato promote).
Se le autorizzazioni sono differenti (eg. su uno slave utilizzato
solo per backup) e' possibile evitare gli errori sugli utenti
mancanti con slave_skip_errors=1396.
Se i server sono ospitati su un cluster active-passive o comunque vi e' la
possibilita' che l'hostname venga cambiato e' opportuno fissare
i nomi del file di relay e del relativo indice con i parametri
relay-log=relay-bin relay-log-index=relay-bin.index.
Nelle configurazioni su basi dati modificate in modo pesante
e' necessario un opportuno dimesionamento dei file systems
eventualmente dedicando un file system separato per i binlog.
Con il parametro expire_logs_days si definisce la retention dei binlog sul Master.
Utili sono anche i parametri max_binlog_size per definire la
dimensione massima dei binlog sul Master,
max-relay-log-size e relay-log-space-limit
per limitare rispettivamente
la dimensione dei relay-log e lo spazio totale occupato
sullo Slave.
Il parametro log_bin_trust_function_creators=1 rilassa le condizioni per la creazione di stored procedure quando il bin-log e' abilitato.
Per garantire una gestione ACID dei dati e garantire la completa replicazione
anche in caso di crash vanno impostati i parametri:
innodb_flush_log_at_trx_commit=1 sync_binlog=1
[NdE innodb-safe-binlog se < 5.0.3 ed anche innodb_flush_log_at_timeout se > 5.6.6]
... che rendono significativamente piu'
lenti MySQL e la replicazione quando e' presente uno storage con alta latenza e bassi IOP!
Nei casi in cui non sia presente uno stringente requisito di Durability
e' possibile migliorare signficativamente le prestazioni
su sistemi in replica con un numero elevato di transazioni
con l'impostazione dei parametri:
innodb_flush_log_at_trx_commit=2 sync_binlog=0
La replicazione utilizza alcuni processi e file di appoggio.
Il processo mysqld sul Master salva sul file bin-log gli statement
di DML e DDL che sono eseguiti sulla base dati.
E' possibile configurare il formato del binlog che puo' contenere gli statement
eseguiti (STATEMENT) o i dati modificati (ROW).
Sul file bin-log.index e' mantenuto l'elenco dei bin-log attivi sul master.
Per mantenere allineati i dati lo Slave utilizza piu' thread.
Il primo e' una connessione remota
al Master ed ha il compito di raccogliere i dati dal bin-log
(BinLog Dump) ed e' sempre attivo.
Gli altri thread sono locali ed hanno il compito di
ricevere il contenuto del bin-log (Slave I/O) sui relay-log
e di applicarlo alla base dati (Slave SQL).
In caso d'errore nell'inserimento dei dati il thread Slave SQL
si interrompe mentre lo Slave I/O continua a raccogliere i dati
dal Master. Con show slave status\G si ottiene l'indicazione
dell'errore occorso; una volta corretto il problema la replicazione
riprende dal punto in cui si era interrotta applicando il relay-log.
La replicazione in MySQL e' molto flessibile e sono possibili diverse alternative.
In alcuni casi particolari e' possibile far proseguire la replica, anche se si verificano alcune tipologie di errori, impostando slave_skip_errors. La tabella seguente riporta i codici degli errori piu' comunemente ignorati:
| Error# | Symbol | Message |
| 1032 | ER_KEY_NOT_FOUND | Can't find record in '%s' |
| 1054 | ER_BAD_FIELD_ERROR | Unknown column '%s' in '%s' |
| 1062 | ER_DUP_ENTRY | Duplicate entry '%s' for key %d |
| 1136 | ER_WRONG_VALUE_COUNT_ON_ROW | Column count doesn't match value count at row %ld |
| 1396 | ER_CANNOT_USER | Operation %s failed for %s |
| 1452 | ER_NO_REFERENCED_ROW_2 | Cannot add or update a child row: a foreign key constraint fails (%s) |
L'impostazione del parametro slave_skip_errors richiede il riavvio dello Slave.
Un'alternativa e' set global slave_exec_mode=IDEMPOTENT che non considera gli errori di chiave duplicata in INSERT
o di chiave non trovata in DELETE.
Queste impostazioni vanno utilizzate in casi particolari e con opportune cautele perche'
possono provocare gravi divergenze nelle repliche.
La replicazione puo' essere eseguita solo su alcuni database o su specifiche tabelle. Quali database replicare si indicano con il parametro replicate-do-db (attenzione: utilizza la USE se in modalita' statement) sullo Slave o con il parametro binlog-do-db sul Master. Per replicare singole tabelle si utilizza il parametro replicate-do-table (che puo' utilizzare wildcard). E' anche possibile indicare quali DB o TABLE non replicare o applicare con parametri analoghi in cui il do e' sostituito con ignore (eg. replicate-ignore-table).
Ad esempio si puo' usare: replicate-ignore-db=mysql, binlog-ignore-db=test e slave_skip_errors=1396 per non replicare gli accessi al database delle autorizzazioni o di test e proseguire nella replicazione anche in caso di errori sulle utenze.
Dal punto di vista architetturale e' importante notare che i parametri sul Master (binlog-) incidono su quello che viene scritto o meno sui binlog. Al contrario i parametri sullo Slave (replicate-) indicano cosa eseguire o cosa ignorare da parte del thread Slave_SQL. Quindi agendo su un parametro di ignore binlog- si puo' ridurre la dimensione dei binlog e del traffico di rete, agendo sui parametri di ignore replicate- si riduce solo l'applicazione degli statement SQL sullo Slave.
Il nome dei relay log sullo Slave e' basato sull'hostname,
se l'hostname e' soggetto a cambiamenti (eg. failover cluster)
la replicazione si blocca;
e' possibile impostare il
nome dei relay log con i parametri relay-log e relay-log-index.
E' semplice comprendere
in quale modo agiscono i parametri
considerando l'architettura utilizzata da MySQL.
Con i parametri binlog-*
si governa quali comandi SQL vengono scritti o meno sul
file bin-log da parte del Master.
Con i parametri replicate-*
si indica quali comandi SQL vengono applicati dallo Slave.
Gli Engine utilizzati sullo Slave possono essere diversi da quelli utilizzati sul Master. Questo consente di scegliere l'Engine piu' adatto allo scopo (eg InnoDB sul Master in cui avvengono le transazioni, MyISAM sullo slave su cui vengono effettuate selezioni complesse o backup).
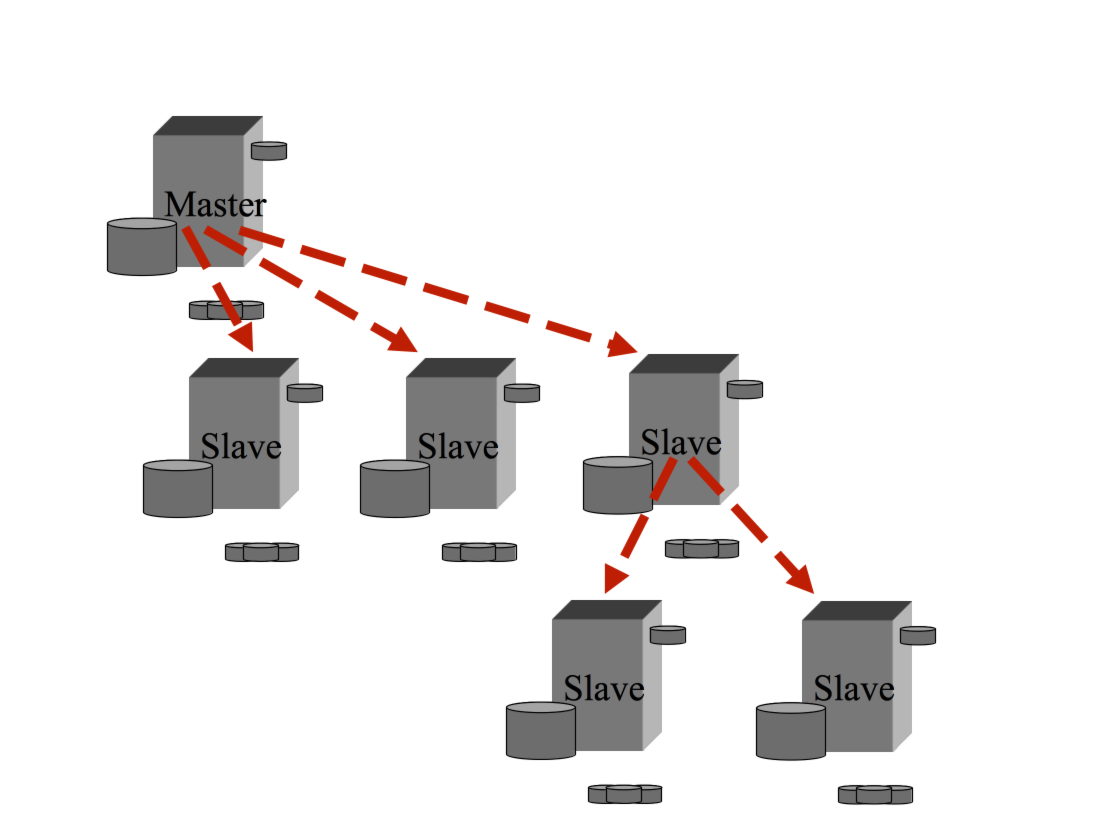 Nel caso piu' semplice un Master viene replicato su uno Slave.
Se gli accessi in lettura al database sono molto elevati (eg. siti web
molto acceduti) e' possibile configurare piu' Slave server
e far connettere le sessioni applicative in lettura sugli Slave.
Per replicare un Master su piu' Slave non e' necessario alcun
cambiamento alla procedura indicata all'inizio:
basta applicare i comandi previsti per lo Slave
su piu' server!
Nel caso piu' semplice un Master viene replicato su uno Slave.
Se gli accessi in lettura al database sono molto elevati (eg. siti web
molto acceduti) e' possibile configurare piu' Slave server
e far connettere le sessioni applicative in lettura sugli Slave.
Per replicare un Master su piu' Slave non e' necessario alcun
cambiamento alla procedura indicata all'inizio:
basta applicare i comandi previsti per lo Slave
su piu' server!
Uno Slave puo' comportarsi a sua volta da Master e questo puo'
essere utilizzato in cascata piu' volte.
In particolare, se il numero di Slave che si vuole mantenere
allineati e' molto elevato, si utilizza la catena
A -> B => Cn dove n e' puo' essere grande a piacere.
A e B vanno configurati come Master, su B deve essere
definito il parametro log-slave-updates
[NdA ed ovviamente il parametro log-bin],
B e Cn vanno configurati come Slave di A e B rispettivamente.
Il server B puo' essere utilizzato dalle applicazioni in lettura
oppure puo' essere dedicato solo alla replica. In questo
ultimo caso si utilizza tipicamente l'Engine Blackhole
per non utilizzare spazio in locale
[NdA naturalmente B deve comunque poter mantenere i bin-log sufficienti
per la gestione della replica,
quindi serve comunque dello spazio disco]
e non avere l'overhead del
caricamento dei dati.
In questa configurazione tutte le modifiche vengono applicate
sulla base dati A. I log vengono trasferiti sul sistema B con
il minimo impatto su A poiche' vi e' un solo server ad accedere
ai dati. Poiche' B utilizza l'Engine Blackhole non vi e'
alcun rallentamento ed il sistema e' dedicato ad ospitare
i demoni dei diversi server C utilizzati in lettura.
Una descrizione piu' completa di questa configurazione
si trova in questo documento.
E' possibile configurare due nodi in modo che ciascuno agisca da Slave dell'altro (two-way replication); tuttavia la replica di MySQL non ha alcun meccanismo di locking distribuito o di risoluzione delle contese: in caso di modifica degli stessi dati la replica va in errore e si blocca. La replica multi-master va quindi adottata solo in casi molto particolari in cui e' presente un robusto meccanismo di routing degli accessi nell'applicazione client [NdA personalmente la sconsiglio vivamente].
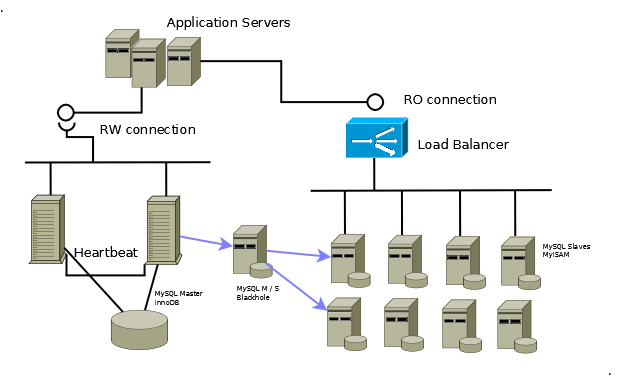
Come abbiamo visto utilizzando la replicazione e' possibile costruire complesse architetture di database MySQL che soddisfano ai piu' stringenti requisiti di alta affidabilita', continuita' di servizio, prestazioni, trasparenza applicativa, scalabilita', ... La figura che segue mostra un'architettura con un cluster Active/Passive per la base dati Master e una batteria di Slave e spero sia abbastanza chiara:
La replicazione su MySQL richiede un impegno molto limitato
da parte del DBA. Ma qualcosa bisogna comunque fare...
Cosa si deve controllare quando e' attiva la replicazione e
come e' possibile agire quando si verificano dei problemi?
In questo capitolo vengono riportate le indicazioni
relative ai casi piu' comuni.
Sara' banale ma in realta' capita spesso: il file system non deve arrivare al 100%! Va sempre controllato e se necessario si deve prevedere un FS separato per i binlog.
+----+-------------+-----------+------+---------+--------+--------------------------------- | Id | User | Host | db | Command | Time | State +----+-------------+-----------+------+---------+--------+--------------------------------- | 2 | system user | | NULL | Connect | 696969 | Waiting for master to send event | 3 | system user | | NULL | Connect | 696969 | Has read all relay log; waiting ... ...
Mi ripeto... Sara' banale ma in realta' capita spesso: il file system non deve arrivare al 100%!
SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1; START SLAVE;Nota: con il GTID non e' possibile effettuare lo skip delle transazioni in questo modo ed e' necessaria un'iniezione
Nel caso in cui passi troppo tempo potrebbero non essere piu' disponibili tutti i bin-log necessari alla sicronizzazione ed e' necessario un ripristino. Tra le diverse modalita' possibili questa e' una delle piu' dirette:
STOP SLAVE mysqldump --single-transaction --all-databases --master-data # Ovviamente sul Master !!! Restore # basta un mysql < backup.out START SLAVETerminati i passi indicati lo slave recuperera' quanto avvenuto nel frattempo sul Master (si controlla verificando il valore di Seconds behind master di SHOW SLAVE STATUS \G)
Per cancellarli si utilizza il comando PURGE MASTER LOGS TO 'mysql-bin.000069';
che rimuove i binary log precedenti a quello indicato.
La pulizia puo' anche essere schedulata a tempo effettuando un # mysqladmin flush-logs
e PURGE MASTER LOGS BEFORE DATE_SUB(now(), INTERVAL 15 DAY);.
Sicuramente meno pulito, ma funziona lo stesso, cancellare da sistema operativo i file
e poi correggere il bin-log.index che e' un normale file di testo...
Qualunque comando si utilizzi...
e' necessario controllare che i bin-log siano gia' stati caricati su tutti gli Slave!
Anche se molto potente, la replicazione di MySQL ha alcuni limiti che non consentono di replicare tutto in tutti i casi... come nei bugiardini delle medicine i rischi ed i limiti si trovano scritti in piccolo nelle avvertenze per l'uso (eg. System Functions, Triggers).
IMPORTANTE: non fate scoppiare il file system del bin log!
Se le modifiche su una base dati sono significative e' opportuno utilizzare
un file system separato per i bin-log, in caso d'errore almeno il DB continua a funzionare...
Alcuni comandi e funzioni, per le funzionalita' particolari che implementano,
non vengono sempre replicati correttamente. Ad esempio:
LOAD_FILE()
UUID()
USER()
FOUND_ROWS()
SYSDATE()
GET_LOCK()
RAND()
VERSION()
...
[NdE in realta' con il MIXED MODE alcune funzioni vengono
trattate correttamente nelle ultime versioni ma e' comunque opportuno
evitarle]
Alcune sintassi DML non sono deterministiche e quindi vanno evitate
con la replication.
La INSERT...SELECT o la DELETE...LIMIT
debbono utilizzare la clausola ORDER BY per essere deterministiche.
L'utilizzo di Engine differenti all'interno della stessa transazione
puo' generare problemi con la replicazione...
in realta' puo' generare problemi anche senza la replica!
Alcune applicazioni sono piu' replicabili di altre: dipende dall'uso dell'SQL.
Se la vostra applicazione utilizza Stored Routine, con la gestione di SIGNAL,
scatena triggers, che agiscono su colonne in autoincrement,
con tabelle partizionate, ...
e' meglio controllarla con attenzione!
E' possibile utilizzare versioni differenti, Engine differenti e (non ricordo da quando ma si puo')
strutture dati differenti tra Master e Slave... Ma pensateci bene prima di crearvi dei problemi da soli!
Sebbene siano perfettamente replicabili modifiche massive di dati generalmente non e' conveniente
effettuare variazioni pesanti sul Master. Queste infatti introducono un lag significativo nella replicazione.
Le alternative sono diverse: ad esempio spezzare le istruzioni massive in piu' statemente SQL
oppure disabilitare la replicazione con SET SQL_BIN_LOG=0 ed effettuare allineamenti manuali...
Quando si sviluppa un'applicazione che deve operare con una configurazione di MySQL in replica, oltre a tenere conto dei limiti cui abbiamo accennato (eg. non usare la RAND()) e' possibile sfruttarne le caratteristiche per ottenere migliori prestazioni ed una maggiore scalabilita': basta utilizzare connessioni differenti per le scritture e le letture. In questo modo e' possibili limitare il carico sul master alle sole scritture distribuendo le attivita' di lettura sugli slave.
Vi sono differenze significative tra le versioni di MySQL (ed i fork ;-) sia nelle funzionalita' (eg. ROW BASED) che nell'elenco di Bug presenti e risolti. Meglio convergere su una versione recente, consolidata ed allineata per tutti i nodi che partecipano alla replication.
La replicazione su MySQL e' disponibile dalla versione 3.23.15 (2000)
e si e' dimostrata da subito veloce, semplice da configurare/amministrare
e di basso impatto sulle prestazioni.
Le diverse nuove funzionalita' inserite nel tempo a livello di database hanno
richesto, in qualche caso, un aggiornamento della parte di replicazione.
Gli aggiornamenti piu' importanti sono riportati nei paragrafi seguenti.
Per le Stored Routines (disponibili dalla 5.0) un'importante considerazione e' relativa all'utilizzo del binary-log necessario per la replication, ma anche per il recovery point-in-time. Per rendere replicabili le azioni svolte dalle stored routine e' utilizzata una sintassi specifica per indicare le modifiche svolte sui dati. Infatti sul binary log viene riportata la stored routine richiamata ed il risultato di questa deve essere replicabile per poter riapplicare il log. Per tale ragione e' importante dichiarare se il comportamento della stored routine e' deterministico (ovvero si ripete sempre uguale a fronte degli stessi dati) e se vengono modificati dati.
CREATE PROCEDURE test1 ... DETERMINISTIC MODIFIES SQL DATA ... BEGIN ...Poiche' il thread di replicazione gira in stato privilegiato sugli Slave e' richiesto il privilegio SUPER oppure l'impostazione del parametro --log-bin-trust-routine-creators.
La replicazione su MySQL e' storicamente Statement Based.
Questo la rende
particolarmente efficiente ma, in qualche caso, vi sono dei limiti.
Ad esempio nell'utilizzo di trigger e stored routine, con statement SQL
che utilizzano valori random, con alcuni comandi quali LOAD_FILE(),
SYSDATE, con le UDF (user defined functions), ...
Per questo e' stata introdotta la possibilita' di replicare i
dati anche con un meccanismo Row Based.
Dalla versione 5.1 (5.1.8 per essere precisi) e' possibile utilizzare
tre differenti modalita' per registrare sul binary log (binlog_format):
Tipicamente la modalita' piu' efficiente ed affidabile e' STATEMENT [NdE in questa specifica versione MySQL]. La modalita' ROW e' utile per replicare correttamente stored procedures e trigger non deterministici.
La replicazione su MySQL e' asincrona, e' quindi possibile che, per causa di un fault, le ultime transazioni eseguite sul Master non siano ancora state replicate sugli Slave. La conseguenza e' un'effettiva perdita di dati fino all'ultima transazione trasmessa agli Slave.
Dalla versione 5.5 e' possibile impostare la replicazione semi-sincrona nella quale il Master,
prima di effettuare il commit locale, attende che almeno uno slave abbia ricevuto i dati della
transazione.
In questo modo almeno uno Slave ha ricevuto l'ultima transazione committata e
quindi non si possono verificare perdite di dati.
Sebbene si tratti di un protocollo piu' semplice e veloce rispetto al
Two Phase Commit,
le transazioni sono comunque rallentate.
Per impostare la replicazione semi-sincrona e' quindi importante che la latenza nella comunicazione
tra Master e Slave sia molto bassa.
Le figure seguenti riportano le differenze in termini di scambio di messaggi tra
replica asincrona e semi-sincrona:
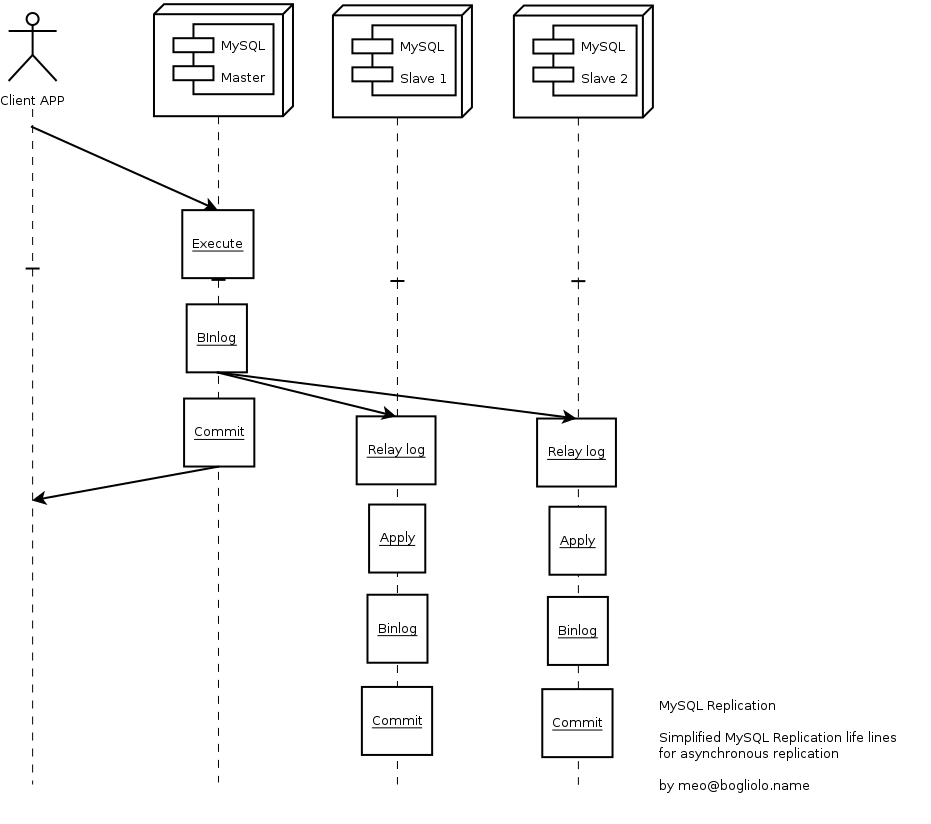
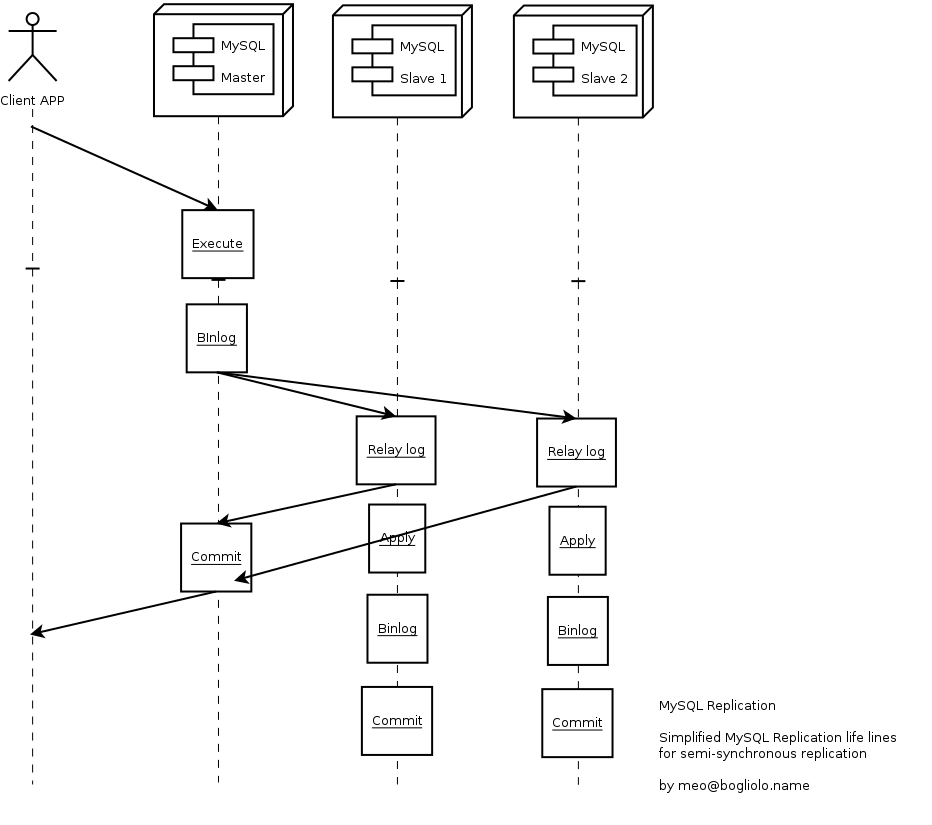
La replicazione semi-sincrona e' implementata mediante due plug-in (uno per il master ed il secondo per gli slave). Nel caso in cui nessuno Slave abbia il plug-in attivo o quando si verificano problemi, il master, dopo un timeout, ritorna nella modalita' asincrona di replicazione senza bloccare o ritardare ulteriormente le transazioni.
La configurazione della replica semi sincrona e' abbastanza semplice: richiede l'attivazione del plugin e l'impostazione delle variabili sul master:
A questo punto e' tutto configurato ma... bisogna riavviare gli slave per farli
registrare come semi-sincroni. Si puo' fare on-line con:
STOP SLAVE IO_THREAD;
START SLAVE IO_THREAD;
La versione 5.6 di MySQL [N.d.E in produzione da Febbraio 2013] contiene diverse utili nuove funzionalita' per la replicazione dei dati:
La versione 5.7 di MySQL [NdE 2015-10], prevede diverse novita' per la replication:
La versione 5.7.17 di MySQL, appena rilasciata in produzione [NdE 2016-12] contiene il plugin per la Group Replication che consente di gestire la replica multimaster.
I protocolli di rete della Group Replication
si occupano della connessione e disconnessione dei nodi
e di mantenere la sincronizzazione dei dati...
il tutto in modo automatico.
Nella Group Replication la configurazione piu' semplice e' quella con un single-primary
ma e' supportata anche la configurazione multi-master o, per essere allineati con la terminologia
ufficiale, la configurazione multi-primary.
Al momento del commit viene eseguita la certificazione della transazione
che verifica se le modifiche possono avvenire senza conflitti.
In caso d'errore viene semplicemente eseguito il rollback della transazione.
Con il rilascio di MySQL Router 2.1 e MySQL Shell in GA [NdE 2017-04] e' disponibile l'architettura MySQL InnoDB Cluster che integra la replication in una completa soluzione in HA (alta affidabilita').
La componente di replica utilizzata da MySQL Cluster InnoDB e' la Group Replication (introdotta in MySQL 5.7.17) e le applicazioni utilizzano MySQL Router per connettersi ai nodi attivi del Cluster. La configurazione e la gestione del cluster sono semplificate dall'AdminAPI di MySQL Shell.
Appena avro' tempo descrivero' le novita' piu' importanti della replica per la versione 8.0! [NdE che pigro questo Autore] [NdA aggiungo il paragrafo seguente solo per smentire l'Editore].
Sono molte le evoluzioni sulla replica introdotte nella versione 8.0.
In effetti alcune sono risultate cosi' importanti che e' stato poi
eseguito un backport sulla versione 5.7 (eg.
il supporto dei savepoint nella group replication, necessario per l'opzione –-single-transaction di mysqldump,
e' stato rilasciato prima nella 8.0.1 e poi nella versione 5.7.19).
Molti i cambiamenti dal punto di vista della sicurezza in questa versione...
se lo slave non si connette con l'errore "Authentication requires secure connection"
va impostato il parametro master_ssl=1.
Tra i cambiamenti minori il parametro expire_logs_day e' stato deprecato
ed e' possibile utilizzare il piu' flessibile
binlog_expire_log_seconds.
Dalla 8.0.22 il comando SHOW SLAVE STATUS e' deprecato e va utilizzato SHOW REPLICA STATUS.
Dalla 8.0.23 e' disponibile una nuova sintassi per il comando
CHANGE MASTER TO MASTER_HOST ...
che viene modificato in
CHANGE REPLICATION SOURCE TO SOURCE_HOST ...;
entrambe le sintassi sono supportate.
Con la versione 8.0.26 ulteriori parametri contenenti i prefissi master e slave sono stati deprecati e
sostituiti con i prefissi rispettivamente source e replica.
Per attivare la replica MySQL e' necessario partire da un backup consistente. Per qualche applicazione potrebbe non essere possibile effettuare un backup consistente del Master a causa della durata dei lock. In questo caso e' possibile utilizzare il backup uno slave gia' attivo. Ecco i passi corretti per dare il minor impatto alla replica ed alle applicazioni:
Chiaro? Penso di si!
[NdA nelle ultime versioni e' stata inserita l'opzione --dump-slave che riporta i valori dei binlog del master
ed interrompe l'SQL thread] [NdE l'opzione --dump-slave e' disponibile dalla versione 5.5.3].
Attenzione!
Le indicazioni riportate sopra sono da seguire se si vuole agganciare il nuovo slave allo stesso master.
Se invece si vuole utilizzare la cascading replication, ovvero agganciare il nuovo slave allo slave
da cui si sta effettuando il backup, gli estremi per la configurazione della replica si ottengono
con SHOW MASTER STATUS.
L'istruzione CHANGE MASTER ha molti altri parametri... sono descritti prima in questo documento.
Il parametro --master-data=2 funziona solo se e' stato abilitato il binary logging sullo slave.
Per la sincronizzazione la cosa piu' semplice e' sospendere l'SQL thread,
comunque consigliato il parametro per il locking --single-transaction.
In caso di DB di grandi dimensioni conviene comprimere il dump con gzip.
Per aggiungere un altro Slave identico ai precedenti un'altra semplice tecnica e': STOP SLAVE SQL_THREAD; backup/restore fisico di tutto il DB, modificare del server_id sul nuovo slave; START SLAVE su entrambe gli slave.
Quanto visto fino ad ora sui bin-log ad uso della replication
puo' essere applicato con uno scopo differente:
il Point-in-time Recovery (PITR). Il PITR consente di ripristinare un database
fino al momento desiderato (eg. appena prima di una DROP TABLE lanciata per errore).
Il database va semplicemente configurato con il bin-log attivo (parametro log-bin
nel file my.cnf).
Per il restore l'idea di base e' quella di partire da un salvataggio
completo ed affidabile, su cui vengono applicati i comandi contenuti nei file
di bin-log fino al momento desiderato.
I bin-log sono in formato binario, il comando mysqlbinlog trasforma il
contenuto binario nelle istruzioni SQL corrispondenti.
Per ottenere le variazioni occorse il comando e':
Potrebbe anche essere utilizzato in pipe con mysql... ma un minimo di controllo da parte del DBA di solito e' opportuno prima di lanciare i comandi SQL sul database [NdA per analizzare i binlog sono anche utili le opzioni di mysqlbinlog -v, -vv o --base64-output=DECODE-ROWS].
Per indicare il momento fino a cui arrivare o da cui partire
si utilizzano i parametri --start-datetime --stop-datetime.
La data va indicata con formato std ISO: --stop-datetime="2012-04-01 10:00:00".
E' anche possibile indicare la transazione precisa da cui partire o arrivare
con i parametri --start-position --stop-position.
In caso di ripristino di un DB lo spazio disponibile e' spesso un problema...
Nella conversione da binario ad SQL la dimensione indicativamente aumenta del 50%.
La configurazione ed i comandi di amministrazione per la gestione di un DB su cui si utilizza il
binlog per il PITR sono gli stessi gia' descritti per la gestione del Master...
Il solo parametro log-bin nel file my.cnf e' sufficiente
per attivare il salvataggio dei binlog.
Il parametro non e' dinamico e quindi e' necessario il riavvio del server.
Altro parametro utile, introdotto dalla 5.1, e' binlog_format=mixed
che permette di utilizzare la modalita' piu' conveniente di logging
tra STATEMENT e ROW.
Nel caso del PITR non serve attendere che tutti gli Slave siano sincronizzati
(non ci sono Slave) per il purge dei binlog ed e' sufficiente arrivare all'ultimo full backup
affidabile.
Disponendo di un backup ogni sera il comando per effettuare la cancellazione dei binlog e':
PURGE MASTER LOGS BEFORE DATE_SUB(now(), INTERVAL 2 day);
Un altro approccio, sicuramente piu' flessibile perche' consente di aggirare eventuali
problemi con lo skip, e' quello di utilizzare uno slave
e di far interrompere la replica fino ad uno specifico momento con:
START SLAVE UNTIL MASTER_LOG_FILE = 'log_name', MASTER_LOG_POS = log_pos
oppure
START SLAVE SQL_THREAD UNTIL SQL_AFTER_GTIDS = xxx
se si utilizza la replica GTID.
Titolo: MySQL Replication
Livello: Avanzato
Data:
1 Aprile 2008
Versione: 1.0.25 - 11 Aprile 2022
Autore: mail [AT] meo.bogliolo.name