MySQL Group Replication
La Group Replication di MySQL, introdotta di recente in produzione,
consente di creare topologie di replica in alta affidabilita'.
I protocolli di rete del Plugin della Group Replication
si occupano della connessione e disconnessione dei nodi
e di mantenere la sincronizzazione dei dati.
Le applicazioni piu' importanti della Group Replication sono l'implementazione
di sistemi in alta affidabilita' e la realizzazione di configurazioni in Cloud.
Nel seguito sono riportate alcune informazioni di interesse
organizzate in paragrafi specifici:
Introduzione,
Architettura,
Installazione e configurazione,
Avvertenze per l'uso,
Amministrazione (FAQ),
...
Il contenuto di questo documento e' tecnico.
E' opportuna una conoscenza dell'architettura MySQL,
degli storage Engine
e della Replication.
Introduzione
La funzionalita' di replica dati di MySQL e' molto utilizzata
perche' e' semplice da configurare, aggiunge un carico ridotto ed e' molto flessibile.
Tuttavia il suo funzionamento e' asincrono e non garantisce l'allineamento degli slave
in caso di fault.
Per ridurre la perdita di dati e' stata introdotta nella versione 5.5 di MySQL la
replica semi-sicrona che ritarda il commit fino a
che almeno uno slave abbia ricevuto nel relay log la transazione,
ma questo risolve solo parzialmente il problema.
Inoltre entrambe le modalita' di replica asincrona e semisincrona
richiedono un intervento sistemistico
per l'aggiunta di nuovi nodi e la gestione di eventuali fault.
La Group Replication
di MySQL
consente di creare gruppi di replica
elastici (ovvero che gestiscono automaticamente l'ingresso/uscita di nodi),
fault-tolerant (ovvero che gestiscono automaticamente la caduta di uno o piu' nodi)
ed in alta disponibilita' (ovvero che gestiscono automaticamente le situazioni di blocco).
Un nome molto diffuso per i gruppi di replica e' anche MGR Cluster (MySQL Group Replication Cluster).
Con la Group Replication i nodi di un gruppo
dialogano mediante uno speciale protocollo di rete che gestisce
i tipici eventi di ingresso/uscita dei nodi dal
gruppo, la caduta di un nodo, le situazioni di split-brain, ...
mentre ciascun nodo si occupa localmente di mantenere le connessioni con i client ed
eseguire le query SQL in modo efficiente.
La replica asicrona MySQL non consentiva di implementare la replica multi-master
[NdA o meglio la configurazione e' tecnicamente consentita
ma se vengono modificati gli stessi record la replica si blocca].
Nella Group Replication la configurazione piu' semplice e consigliata
e' quella con un single-primary
ma e' completamente supportata anche la configurazione multi-master o,
meglio, multi-primary.
I nodi vengono mantenuti sempre sincronizzati tra loro
gestendo gli eventuali conflitti.
La fase di verifica della transazione viene chiamata certification test.
Se il risultato e' positivo la transazione viene trasferita (writeset)
ed eseguita su tutti i nodi del cluster nello stesso ordine.
Se il certification test fallisce la transazione viene abortita
ed effettuato un rollback.
Architettura
Le applicazioni client si collegano ad uno qualsiasi dei nodi appartenenti al gruppo
che si comporta come un database standalone.
La configurazione dei DB server e' in shared nothing ovvero
ogni nodo e' indipendente e non sono richiesti storage condivisi o HW specializzati.

Tutti i nodi di un gruppo sono connessi tra loro in configurazione N-N
e dialogano mediante uno speciale protocollo di rete [NdE una variante dell'algoritmo di Paxos].
Vengono gestiti dal protocollo di rete i tipici eventi di ingresso/uscita dei nodi dal
gruppo, la caduta di un nodo, le situazioni di split-brain, ...
L'algoritmo utilizza 2F+1 nodi e garantisce le transazioni fino a che sono attivi F+1 nodi
senza point of failure o blocchi. Quindi tipicamente il numero di nodi e' dispari:
attualmente sono supportati gruppi da tre fino a nove nodi.
A differenza della replica asincrona, dove la latenza di rete puo' introdurre lag ma non genera problemi,
la Group Replication richiede una connessione di rete veloce e con ampia banda [NdE su IPv4 al momento].
Il numero di nodi che compongono un gruppo e' variabile in modo elastico.
Il throughput di un gruppo scala linearmente per le operazioni di lettura
ma NON scala nelle operazioni di scrittura.
E' significativo sottolineare che il protocollo di rete utilizza connessioni N-N
ovvero ogni nodo dialoga singolarmente con gli altri nodi in modo diretto e
senza utilizzare multicast [NdA i multicast spesso non sono utilizzabili nei Cloud].
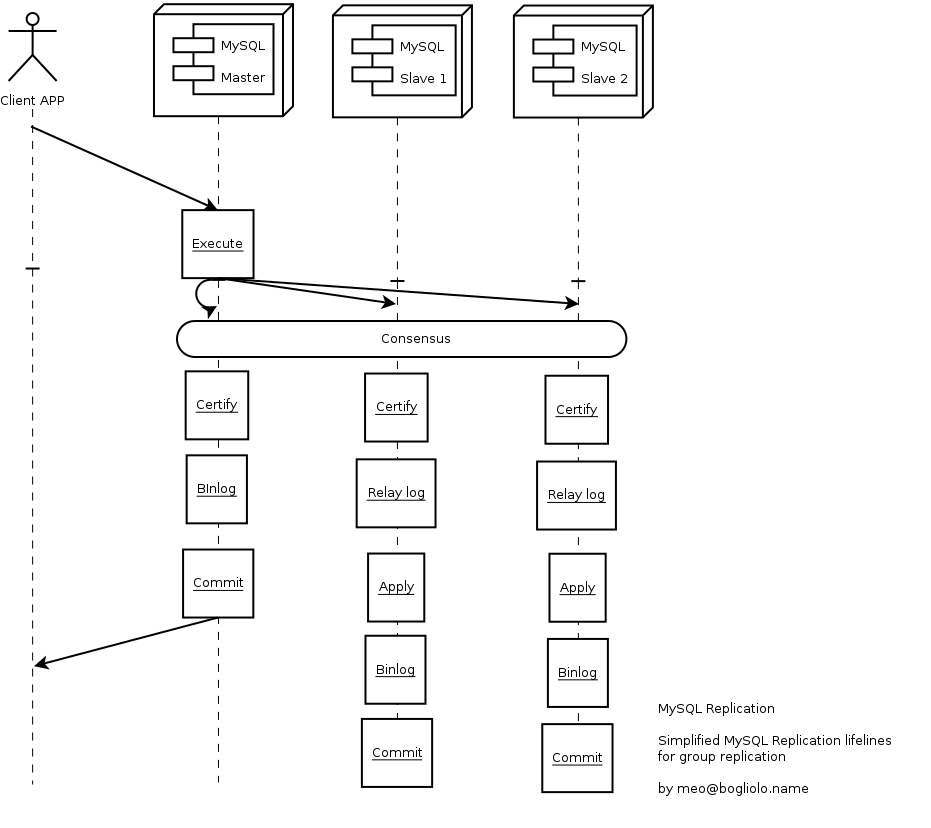 Le attivita' di lettura vengono eseguite localmente e cosi' avviene per
le istruzioni di DML fino al momento del commit.
Prima di effettuare il commit
il cluster verifica (certification test) se l'operazione
puo' essere eseguita senza conflitti.
Per fare questo la transazione viene impacchettata (write-set),
inviata su tutti i nodi, confermata (certification-test) ed eseguita (commit).
Le transazioni vengono effettuate nello stesso ordine su tutti i nodi
che risultano quindi sincronizzati.
Le attivita' di lettura vengono eseguite localmente e cosi' avviene per
le istruzioni di DML fino al momento del commit.
Prima di effettuare il commit
il cluster verifica (certification test) se l'operazione
puo' essere eseguita senza conflitti.
Per fare questo la transazione viene impacchettata (write-set),
inviata su tutti i nodi, confermata (certification-test) ed eseguita (commit).
Le transazioni vengono effettuate nello stesso ordine su tutti i nodi
che risultano quindi sincronizzati.
L'esecuzione degli statement e' ottimistica e non richiede lock distribuiti.
Il certification test viene eseguito a maggioranza e non richiede che i
nodi siano tutti attivi.
Questo approccio e' definito virtually synchronous replication
nel senso che i nodi applicano gli stessi write-set nello stesso ordine
anche se in realta' le scritture e le commit sono demandate ai DB locali
ed avvengono in modo asincrono.
La Group Replication non e' sincrona ma eventually synchronous,
ovvero le transazioni sono applicate nello stesso ordine su tutti i nodi
ma non necessariamente nello stesso momento.
La Group Replication supporta le modalita' single-primary node
(con un solo nodo abilitato alla scrittura) e multi-primary node
(con tutti i nodi abilitati).
Dal punto di vista tecnico la Group Replication MySQL e' costituita
da un Plugin che implementa i necessari protocolli di rete tra i nodi
del gruppo di replica.
La Group Replication utilizza in modo nativo
l'Engine InnoDB,
la replica asincrona
ed il GTID di MySQL.
 Ogni nodo puo' essere in uno stato differente (eg. ONLINE, RECOVERING, ...). Lo stato corrente e' indicato
dalla tabella replication_group_members del performance schema.
Ogni nodo puo' essere in uno stato differente (eg. ONLINE, RECOVERING, ...). Lo stato corrente e' indicato
dalla tabella replication_group_members del performance schema.
Quando il plugin e' stato caricato ma il nodo non e' configurato lo stato e' OFFLINE;
quando un nodo sta entrando in un gruppo effettuando il recupero delle transazioni
da un Donor lo stato e' RECOVERING; nello stato ONLINE il nodo partecipa attivamente
al gruppo ed i client possono effettuare transazioni.
Possono verificarsi problemi ed i nodi vanno in stato di ERROR;
quando un nodo non e' piu' visibile dagli altri componenti del gruppo viene
posto in stato UNREACHABLE.
Se la configurazione e' in single-primary e va in errore il nodo primario
viene immediatamente eletto un nuovo primary tra i nodi rimasti
[NdA dalla 5.7.20 l'elezione tiene conto del parametro group-replication-member-weight].
Dal punto di vista della configurazione e del monitoraggio la Group Replication
e' completamente integrata con il data dictionary ed i performance schema di MySQL
[NdA in effetti le relative viste erano gia' disponibili nei precedenti rilasci della 5.7].
Installazione e configurazione
Questa pagina fa riferimento all'installazione
di MySQL 5.7.17 [NdE la prima versione in cui il pluging della Group Replication e' disponibile in GA]
su Linux RedHat/CentOS/OEL.
L'installazione richiede il download di MySQL
che deve essere scaricato dal sito ufficiale.
L'installazione e' semplice perche' vengono distribuiti gli RPM per le principali
distribuzioni Linux: con il comando rpm -ilv si installano entrambe i binari.
Come su ogni DB MySQL la configurazione dei parametri si effettua agendo sul file my.cnf.
La Group Replication richiede la configurazione della replica GTID,
il binlog format a ROW (per l'individuazione dei writeset),
la disabilitazione dei check sui binlog [NdE ma potrebbe essere abilitata in futuro], ...
Ecco l'elenco dei parametri necessari:
server_id=N
gtid_mode=ON
enforce_gtid_consistency=ON
master_info_repository=TABLE
relay_log_info_repository=TABLE
binlog_checksum=NONE
log_slave_updates=ON
log_bin=binlog
binlog_format=ROW
Per evitare i GAP Lock e' consigliato (ma non obbligatorio) utilizzare anche il parametro
transaction_isolation = READ-COMMITTED.
Veniamo ora ai parametri relativi alla Group Replication
che specificano l'hash utilizzato, il nome del gruppo e l'elenco dei nodi iniziali da contattare.
Viene utilizzato il prefisso loose- per consentire l'avvio di MySQL
anche se il plugin non e' ancora attivato:
transaction_write_set_extraction=XXHASH64
loose-group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa"
loose-group_replication_start_on_boot=off
loose-group_replication_local_address= "mysql1:33061"
loose-group_replication_group_seeds= "mysql1:33061,mysql2:33061,mysql3:33061"
loose-group_replication_bootstrap_group=off
loose-group_replication_single_primary_mode=on
Come per la replica asincrona e' opportuno configurare un'utente specifico:
SET SQL_LOG_BIN=0;
CREATE USER rpl_user@'%';
GRANT REPLICATION SLAVE ON *.* TO rpl_user@'%' IDENTIFIED BY 'rpl_pass';
SET SQL_LOG_BIN=1;
CHANGE MASTER TO MASTER_USER='rpl_user', MASTER_PASSWORD='rpl_pass' FOR CHANNEL 'group_replication_recovery';
E' ora possibile attivare il plugin e la Group Replication sul primo nodo (Seed)
facendo creare il gruppo [NdE questa operazione viene anche chiamata bootstrap del gruppo]:
INSTALL PLUGIN group_replication SONAME 'group_replication.so';
SET GLOBAL group_replication_bootstrap_group=ON;
START GROUP_REPLICATION;
SET GLOBAL group_replication_bootstrap_group=OFF;
Per i nodi successivi i passi e le configurazioni
sono gli stessi con un'unica differenza nei comandi
all'avvio (perche' il gruppo e' gia' stato creato ed avviato):
INSTALL PLUGIN group_replication SONAME 'group_replication.so';
START GROUP_REPLICATION;
Avvertenze per l'uso
L'utilizzo della Group Replication puo' richiede alcune modifiche alle applicazioni
che debbono rispettare alcuni vincoli:
- Viene replicato e va utilizzato solo l'Engine InnoDB
- Ogni tabella deve avere una chiave primaria
- E' consigliato l'isolation level READ COMMITTED (che non utilizza i Gap Locks) ed fortemente sconsigliato il SERIALIZABLE
- Non sono supportati: i table locks ed i named locks [in fase di certificazione della transazione,
ma in modalita' Single Primary funzionano],
i savepoint
[NdA i savepoint sono supportati dalla 5.7.19. E' una funzionalita' piu' importante di quanto sembri
a prima vista:
i savepoint sono utilizzati dall'opzione –-single-transaction di mysqldump]
- Inoltre, solo per la configurazione multi-primary:
- Non sono supportati DDL e DML concorrenti
- Non sono supportati foreign keys con cascading constraints
- Non e' supportato l'isolation level SERIALIZABLE
La gestione dei SERIAL non richiede modifiche applicative ma e' importante sapere che
le colonne in autoincrement ricevono valori incrementati di
un valore definito in
GROUP_REPLICATION_AUTO_INCREMENT_INCREMENT (default 7),
quindi non sono consecutivi.
L'esecuzione di transazioni che opera su un numero molto elevato di GTID
puo' generare errori: vanno evitate transazioni di dimensione elevata o
di durata troppo ampia.
Alcuni vincoli possono essere risolti con parametri di configurazione,
ma e' sicuramente opportuno effettuare test applicativi specifici.
Poiche' i DBA non si fidano mai dei test applicativi...
e' possibile effettuare anche verifiche esterne:
-- Utilizzo di tabelle con Engine diverse da InnoDB
SELECT table_schema, table_name, engine, table_rows,
round((index_length+data_length)/1024/1024,2) AS sizeMB
FROM information_schema.tables
WHERE (engine != 'InnoDB' and engine != 'Memory')
AND table_schema NOT IN ('information_schema', 'mysql', 'performance_schema')
ORDER BY table_schema, table_name;
-- Assenza di primary keys
SELECT tables.table_schema, tables.table_name, tables.engine
FROM information_schema.tables
LEFT JOIN (SELECT table_schema, table_name
FROM information_schema.statistics
GROUP BY table_schema, table_name, index_name
HAVING SUM(case when non_unique = 0 and nullable != 'YES' then 1 else 0 end) = count(*) ) puks
ON tables.table_schema = puks.table_schema and tables.table_name = puks.table_name
WHERE puks.table_name is null
AND tables.table_type = 'BASE TABLE' AND Engine="InnoDB";
-- Utilizzo savepoint
-- SELECT event_name, count_star, sum_errors
-- FROM performance_schema.events_statements_summary_global_by_event_name
-- WHERE event_name like '%savepoint%'
-- AND count_star>0;
Nel caso di utilizzo della configurazione multi-primary va anche verificato:
-- Utilizzo di DML
SELECT event_name, count_star, sum_errors
FROM performance_schema.events_statements_summary_global_by_event_name
WHERE event_name REGEXP '.*sql/(create|drop|alter).*'
AND event_name NOT REGEXP '.*user'
AND count_star>0;
La configurazione multi-primary,
oltre ad avere maggiori vincoli applicativi,
ha anche prestazioni inferiori:
la configurazione consigliata e' quella single-primary.
In configurazione multi-primary, la fase di certificazione della transazione
richiede un tempo maggiore rispetto all'esecuzione serializzata su un solo nodo.
Per le attivita' di lettura vengono bilanciati gli accessi e quindi non vi sono
differenze tra single-primary e multi-primary
[NdE anche se con il multi-primary vi e' un nodo in piu'].
Per sfruttare appieno l'alta affidabilita' della Group Replication
il client deve effettuare la riconnessione nel caso di caduta del nodo
cui e' connesso.
Ad esempio per applicazioni che utilizzano il JDBC il connettore MySQL supporta il
failover
e le
topologie di replica:
l'applicazione deve gestire correttamente le eventuali exception.
Vi sono diverse casistiche da gestire...
per esempio quando si verifica un partizionamento i nodi esclusi dal cluster
restano aperti in sola lettura evitando lo split brain e la perdita di dati
ma consentendo dirty reads
[NdA in realta' in caso di split brain i nodi in minoranza
attendono fino al group-replication-unreachable-majority-timeout (5.7.19)
e quindi effettuano un rollback delle transazioni per porsi in stato super_read_only=ON].
Maggiori dettagli sui limiti nell'utilizzo della group replication
sono descritti nella
documentazione ufficiale.
L'architettura completa prevede l'utilizzo di load balancer o proxy quali
MySQL Router/Fabric,
proxySQL,
HAproxy,
Nginx,
[NdE MySQL Proxy non e' piu' supportato],
... appositamente configurati.
E' finalmente disponibile come GA l'architettura MySQL InnoDB Cluster
che utilizza la Group Replication e la nuova versione di MySQL Router.
La configurazione di InnoDB Cluster e' semplificata dagli script dell'AdminAPI
e MySQL Router effettua l'indirizzamento corretto per gli utenti/applicazioni.
Amministrazione (FAQ)
Cosa si deve controllare e
come e' possibile agire quando si verificano dei problemi?
In questo capitolo vengono riportate le indicazioni
relative ai casi piu' comuni.
- Come si controlla la replica GR?
- Come si aggiungono nodi al gruppo di replica?
-
La procedura di aggiunta di un nodo prevede gli stessi passi gia' descritti per
la configurazione iniziale. In fase di join viene scelto un nodo Donor
che si occupa di inviare tutti i binlog al nuovo nodo.
-
Nel caso in cui i binlog siano gia' stati cancellati (purged) per ribaltare i dati
si parte semplicemente
da un backup. Dalla 5.6 con il GTID attivo basta un normale
mysqldump --all-databases --single-transaction --triggers --routines ...
che imposta il GTID_PURGED al valore corretto al termine del restore
[NdA con un valore uguale al gtid_executed del master al momento del backup].
- Come si controllano gli eventi?
-
Oltre all'opportuna verifica sul file di log, in cui sono riportati gli errori
piu' significativi,
un modo molto semplice per controllare gli eventi occorsi e' il comando:
SHOW BINLOG EVENTS [LIMIT n];
- Come si verifica qual'e' il primary member?
-
Nella configurazione single-primary e' necessario determinare il primary member
verso cui indirizzare le modifiche. Ecco come:
SELECT VARIABLE_VALUE
FROM performance_schema.global_status
WHERE VARIABLE_NAME= 'group_replication_primary_member';
Quella riportata era la query ufficiale... ma io preferisco questa:
SELECT member_id, member_host, member_port
FROM performance_schema.global_status
JOIN performance_schema.replication_group_members
WHERE VARIABLE_NAME= 'group_replication_primary_member'
AND member_id=variable_value;
- Cosa si puo' fare quando il numero di nodi attivi scende sotto al quorum?
-
Nel caso di eventi quali il network partitioning o fault multipli
il numero di nodi attivi potrebbe non essere piu' sufficiente per
raggiungere il quorum e la replica si blocca. In questi casi e' possibile forzare
l'elenco dei nodi attivi al subset desiderato con:
SET GLOBAL group_replication_force_members="mysql1:33061,mysql2:33061";
- Viene segnalato ERROR 3098 (HY000): The table does not comply with the requirements by an external plugin. Che faccio?
-
La tabella su cui si sta cercando di effettuare un comando di INSERT
non e' corretta dal punto di vista della Group Replication.
Ci sono diverse possibili cause: un esempio classico e' quando non c'e' una primary key definita...
va creata la primary key!
- Un nodo non vuole entrare nel gruppo?
- Riparto da uno slave "pulito" e con un backup "corretto"...
-
Ovviamente l'analisi del problema parte sempre dall'error log...
I controlli sono relativi ai
parametri di configurazione ed alla presenza di sole tabelle InnoDB con
chiave primaria. Ecco le query utilizzabili per verificare quest'ultimo
requisito:
SELECT table_schema, table_name, engine
FROM information_schema.tables
WHERE engine NOT IN ('InnoDB', 'MEMORY')
AND table_schema NOT IN ('mysql', 'performance_schema', 'information_schema');
SELECT t.table_schema, t.table_name
FROM information_schema.tables t
LEFT JOIN information_schema.table_constraints c
ON t.table_schema = c.table_schema
AND t.table_name = c.table_name
WHERE t.table_type = 'BASE TABLE'
AND t.table_schema NOT IN ('mysql', 'performance_schema', 'information_schema')
GROUP BY t.table_schema, t.table_name
HAVING sum(if(c.constraint_type='PRIMARY KEY', 1, 0)) = 0;
L'elenco completo dei controlli e' riportato in questo script.
-
Un'altra possibile condizione d'errore puo' essere generata da errant transaction:
[ERROR] Plugin group_replication reported: 'This member has more executed transactions than those present in the group. Local transactions: ... > Group transactions: ...'
[ERROR] Plugin group_replication reported: 'The member contains transactions not present in the group. The member will now exit the group.
In generale questo vuol dire che sono state effettuare delle transazioni locali sul nodo:
NON debbono essere effettuate! [NdA per evitarle: event-scheduler=OFF, skip-slave-start, skip-networking]
L'errore puo' essere aggirato con Empty Transaction Injection
oppure impostando sul secondario il parametro
SET GLOBAL group_replication_allow_local_disjoint_gtids_join=ON;
e riattivando la group replication [NdA da non dimenticare al termine
di ripristinare il valore del parametro, la variabile e' deprecata dalla 5.7.21]
- Viene segnalato 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'
- Viene segnalato ERROR 1840 (HY000): GTID_PURGED can only be set when GTID_EXECUTED is empty.
- Problema simile al precedente. Eseguo un reset master sullo Slave e rilancio.
E' un problema tipico di quando si effettua un restore di un DB su uno slave
non completamente "pulito". Il restore ribalta tutti i dati ma non e' in grado
di reimpostare il GTID_PURGED se ci sono gia' transazioni registrate.
Varie ed eventuali
La documentazione ufficiale della Group Replication e' disponibile
sul sito MySQL.
La Group Replication e' stata introdotta come GA in MySQL 5.7,
le diversi versioni di MySQL sono riportate nel documento
You Server Stinks.
La Group Replication e' il componente fondamentale, con MySQL Router e MySQL Shell,
dell'InnoDB Cluster.
Molto simile alla Group Replication come funzionalita' e tecnologie utilizzate e'
Galera Cluster anche se in realta' il confronto andrebbe
effettuato con InnoDB Cluster.
Per una descrizione dell'algoritmo di Paxos e le differenze rispetto al two phase commit si puo' leggere
questo documento.