MySQL InnoDB Cluster
 InnoDB Cluster fornisce una soluzione completa
per rendere disponibile
un database MySQL in alta affidabilita' sfruttando la tecnica
della replica virtualmente sincrona.
InnoDB Cluster fornisce una soluzione completa
per rendere disponibile
un database MySQL in alta affidabilita' sfruttando la tecnica
della replica virtualmente sincrona.
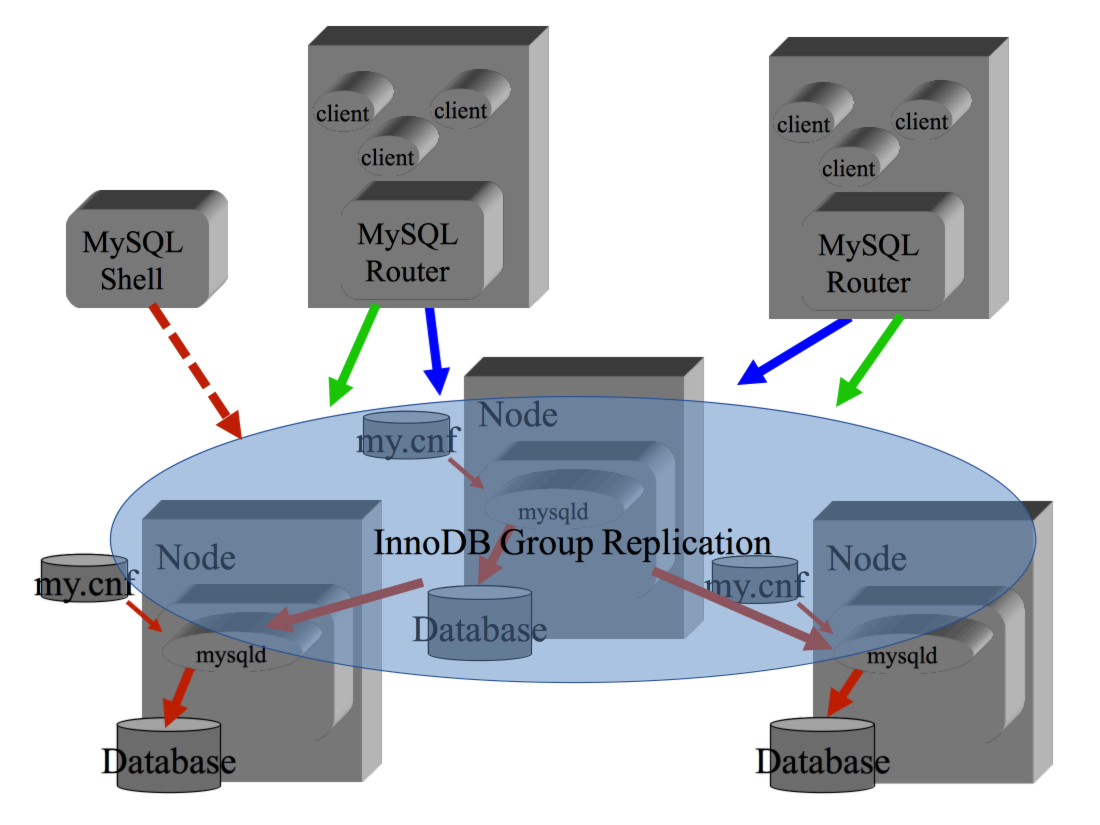
InnoDB Cluster si basa su tre componenti:
il database MySQL configurato in
Group Replication
che mantiene i dati accessibili via SQL,
il componente MySQL Router
che si occupa di indirizzare le connessioni applicative
e l'interfaccia di amministrazione MySQL Shell.
Le applicazioni si collegano alla porta fornita da MySQL Router come se si trattasse
di un normale DB MySQL e vengono connesse in modo trasparente al nodo corretto del cluster.
Nel caso di caduta di un nodo il cluster si occupa di ogni attivita' senza che sia necessario
l'intervento manuale di un DBA.
Nel seguito sono riportate alcune informazioni di interesse
organizzate in paragrafi specifici:
Introduzione,
Architettura,
Installazione,
MySQL Shell,
Configurazione Cluster,
Configurazione Router,
Amministrazione (FAQ),
...
Il contenuto di questo documento e' tecnico.
E' opportuna una conoscenza dell'architettura MySQL,
degli storage Engine
e della Replication
(ed in particolare della Group Replication
e della replica GTID).
Sono utili anche competenze sui proxy e load balancer
per MySQL.
Le versioni di componenti cui fa riferimento questo documento sono:
MySQL 5.7.18, MySQL Router 2.1.3, MySQL Shell 1.0.9
[NdE sono le release disponibili al rilascio in produzione di InnoDB Cluster:
12 Aprile 2017].
Introduzione
La Group Replication di MySQL, introdotta di recente in produzione,
consente di creare topologie di replica in alta affidabilita' gestite in automatico.
I protocolli di rete della Group Replication [NdA una variante dell'algoritmo di Paxos]
si occupano della connessione e disconnessione dei nodi
e di mantenere la sincronizzazione dei dati certificando ogni transazione.
Non sono pero' automatici, nella Group Replication,
la connessione al nodo corretto del cluster e le procedure di amministrazione:
per questo e' stato introdotto l'InnoDB Cluster che semplifica ogni procedura.
La configurazione di replica consigliata e'
quella Single Primary con tre nodi:
il Master e due Slave sempre sincronizzati tra loro.
Ma e' supportata anche la configurazione Multi Primary.
Possono essere aggiunte e rimosse istanze dal cluster
in modo dinamico utilizzando semplici comandi di MySQL Shell.
Per accedere al cluster le applicazioni utilizzano
MySQL Router che le indirizza sempre al DB corretto.
Da MySQL Router sono rese disponibili due differenti porte:
una per le connessioni
in RW (lettura/scrittura) e l'altra per le connessioni in RO (Read Only).
Per amministrare il cluster si utilizza MySQL Shell ed in particolare
le AdminAPI che consentono di creare e gestire il cluster con semplici comandi JavaScript.
I vantaggi dell'architettura InnoDB Cluster come soluzione per l'Alta Affidabilita'
sono molti:
i nodi sono in configurazione share nothing ovvero non e' necessario alcuno
storage sofisticato (eg. SAN) perche' ciascun DB opera localmente;
la funzionalita' di replica MySQL e' molto robusta ed efficiente;
la configurazione e la gestione sono semplificate da MySQL Shell;
il cluster e' elastico adatto a configurazioni variabili ed all'uso in Cloud;
...
Architettura
I database MySQL che compongono il Cluster sono tutti attivi e vi si accede utilizzando
la porta 3306 (per default).
La configurazione dei DB server in Group Replication e' in shared nothing ovvero
ogni nodo e' indipendente e non sono richiesti storage condivisi o HW specializzati.

Tutti i nodi di un gruppo sono connessi tra loro in configurazione N-N
e dialogano mediante uno speciale protocollo di rete.
Vengono gestiti dal protocollo di rete i tipici eventi di ingresso/uscita dei nodi dal
gruppo, la caduta di un nodo, il partitioning della rete, le situazioni di split-brain, ...
L'algoritmo utilizza 2F+1 nodi e garantisce le transazioni fino a che sono attivi F+1 nodi
senza point of failure o blocchi. Quindi tipicamente il numero di nodi e' dispari:
attualmente sono supportati dalla Group Replication gruppi da tre fino a nove nodi.
Il protocollo di replica MySQL si occupa di aggiornare i dati su tutti i nodi
che compongono il cluster. Eventuali conflitti nelle transazioni vengono risolti
durante la fase di certificazione che avviene durante il commit.
 Quanto descritto vale in generale per la Group Replication,
che e' il componente fondamentale del Cluster,
ma e' importante
sottolineare che la configurazione consigliata per l'InnoDB Cluster e'
costituita da 3 nodi in modalita' Single Primary:
si tratta della configurazione con le migliori prestazioni
e nel seguito descriveremo solo questa.
Quanto descritto vale in generale per la Group Replication,
che e' il componente fondamentale del Cluster,
ma e' importante
sottolineare che la configurazione consigliata per l'InnoDB Cluster e'
costituita da 3 nodi in modalita' Single Primary:
si tratta della configurazione con le migliori prestazioni
e nel seguito descriveremo solo questa.
Le informazioni su come e' costruito il cluster vengono mantenute
sull'InnoDB cluster Metadata Schema
[NdA e' il database mysql_innodb_cluster_metadata] che contiene le tabelle
clusters, hosts, instances, replicasets, routers e schema_version
dal contenuto corrispondente.
Il numero dei nodi e' dinamico:
puo' variare in caso di fault, per attivita' amministrative,
durante gli upgrade, quando si inseriscono nuove istanze nel cluster, ...
Anche lo stato delle istanze e' variabile:
nella configurazione Single Primary solo un nodo e' accessibile in scrittura
(gli altri sono in super-read-only)
e puo' cambiare in caso di fault,
quando un'istanza si connette al cluster deve recuperare le transazioni
dagli altri nodi e benche' attiva potrebbe non essere allineata, ...
Non e' quindi cosi' semplice sapere a quale nodo e' corretto connettersi.
Per accedere al nodo corretto del cluster le applicazioni utilizzano
MySQL Router che opera come un proxy server.
MySQL Router viene installato sugli Application Server in locale
ed acceduto da localhost sulle porte 6446 (RW) e 6447 (RO).
Infine MySQL Shell si usa per la configurazione del cluster perche',
mediante i suoi script della AdminAPI, semplifica l'orchestrazione delle attivita'
di setup e di manutenzione dei servizi.
Installazione
L'installazione dei tre componenti e' molto semplice
sopratutto se si utilizzano i repository del
sito ufficiale.
I componenti da installare inzialmente sui tre DB server sono MySQL 5.7 e MySQL Shell 1.0.
Oltre all'installazione del software, i database MySQL vanno anche creati
ed attivati in modo che siano accessibili.
MySQL Router 2.1 viene generalmente installato sugli application server che debbono
accedere a MySQL.
Per l'installazione dei tre componenti... non dico altro:
se siete arrivati a leggere fino a questo
punto e volete installare un cluster vuol dire che sapete farla da soli!
[NdE basta uno yum install ...]
MySQL Shell
MySQL Shell e' un'interfaccia a linea di comando
che opera in modalita' Java Script o SQL.
L'utilizzo e' semplice:
$ mysqlsh --uri root:xxx@localhost
...
Type '\help', '\h' or '\?' for help, type '\quit' or '\q' to exit.
Currently in JavaScript mode. Use \sql to switch to SQL mode and execute queries.
mysql-js> \sql
Switching to SQL mode... Commands end with ;
mysql-sql> \js
Switching to JavaScript mode...
mysql-js> \exit
Per connettersi ad un'istanza di DB si possono utilizzare
in alternativa i comandi \connect root@hostname:3306 o
shell.connect(root@hostname:3306).
L'help e' molto completo e l'interfaccia semplice.
I comandi si danno in SQL (mi piace) o in JavaScript (mi piace)
ed i risultati si ottengono in JSON (non mi piace ma si capisce facilmente)...
Insomma provate!
Configurazione
La configurazione iniziale del cluster puo' essere svolta con
pochi semplici passi.
- Prerequisiti
L'unico prerequisito e' il corretto funzionamento di MySQL sui tre nodi
connessi tra loro in rete.
Tuttavia e' sicuramente consigliabile:
- Utilizzare nodi e configurazioni identiche o almeno il piu' simili possibile.
- Verificare l'assenza di errori nella rete sia per la parte fisica (eg. bassa latenza, assenza disconnessioni, ...)
che nelle configurazioni (eg. DNS, reverse lookup, ...).
- Effettuare tutte le personalizzazioni e configurazioni specifiche
prima di impostare la replica. Teoricamente sarebbe sempre possibile farlo ma in realta' poi
si hanno difficolta' con il super_read_only (nodi in R/O) e
le Errant Transaction
(transazioni eseguite su un solo nodo).
- Utilizzare la stessa password di root per i diversi nodi e creare un
utenza amministrativa per il cluster con
GRANT ALL ON *.* to 'clu_adm'@'%' IDENTIFIED BY 'XXX' WITH GRANT OPTION;
- Ovviamente non utilizzare la password XXX!
- Configurare i MySQL per il Cluster
E' facile perche' si occupa di tutto, o quasi, il comando MySQL Shell:
dba.configureLocalInstance('root@localhost:3306')
Ovviamente il comando va lanciato su tutti e tre i Nodi MySQL
[NdA e' importante utilizzare il comando configureLocalInstance
perche' imposta i parametri necessari in modo persistente].
I passi eseguiti dipendono dalla configurazione presente:
MySQL user 'root' cannot be verified to have access to other hosts in the network.
1) Create root@% with necessary grants
2) Create account with different name
3) Continue without creating account
4) Cancel
Please select an option [1]:
...
- Some configuration options need to be fixed.
+----------------------------------+---------------+----------------+--------------------+
| Variable | Current Value | Required Value | Note |
+----------------------------------+---------------+----------------+--------------------+
| enforce_gtid_consistency | OFF | ON | Restart the server |
| gtid_mode | OFF | ON | Restart the server |
| log_bin | 0 | 1 | Restart the server |
| log_slave_updates | 0 | ON | Restart the server |
| master_info_repository | FILE | TABLE | Restart the server |
| relay_log_info_repository | FILE | TABLE | Restart the server |
| transaction_write_set_extraction | OFF | XXHASH64 | Restart the server |
+----------------------------------+---------------+----------------+--------------------+
...
Teoricamente funziona sempre...
generalmente basta seguire le indicazioni fornite ed
e' solo necessario un riavvio
per attivare i parametri impostati e rilanciare il comando
dalla shell.
Se c'e' qualche errore puo' essere utile
impostare la variable dba.verbose=1 che fornisce un output piu' dettagliato.
- Creare il Cluster
Su un solo nodo, ad esempio db01.xenialab.it che sara' il nodo di Seed iniziale, lanciare i comandi:
var cluster = dba.createCluster('myCluster', {ipWhitelist: "10.0.1.0/24, 192.168.1.1"})
La definizione della white list degli indirizzi dei nodi non e' obbligatoria
ma e' consigliata per un setup di produzione [NdA viene comunque impostata come default la rete locale].
- Aggiungere istanze al Cluster
E' ora possibile aggiungere gli altri DB MySQL a cluster:
cluster.addInstance("root:xxx@db02.xenialab.it:3306")
cluster.addInstance("root:xxx@db03.xenialab.it:3306")
A questo punto il cluster e' attivo e funzionante!
E' gia' possibile utilizzarlo ed effettuare transazioni
puntando direttamente ai DB Server,
manca solo la componente che indirizza automaticamente
le connessioni che configuriamo nel prossimo capitolo.
La procedura di configurazione crea il Metadata Schema
e definisce le utenze di accesso di ogni nodo al Cluster.
Sono tutte componenti interne al Cluster che non richiedono
alcuna gestione.
In pratica viene creato il database mysql_innodb_cluster_metadata
che contiene le tabelle:
clusters, hosts, instances,
replicasets, routers, schema_version.
MySQL Router
Per collegarsi ai nodi del cluster gli utenti/applicazioni
utilizzano MySQL Router che li indirizza nel modo corretto.
Potenzialmente sono possibili molteplici deploy e configurazioni per MySQL Router... scegliamo il modo piu' semplice!
MySQL Router va installato e configurato su ogni Application Server.
La configurazione e' la seguente:
- Configurare MySQL Router per il Cluster
Basta un comando:
# mysqlrouter --bootstrap root:xxx@db01.xenialab.it:3306 --user=mysqlrouter
Bootstrapping system MySQL Router instance... ...
Classic MySQL protocol connections to cluster 'myCluster':
- Read/Write Connections: localhost:6446
- Read/Only Connections: localhost:6447
X protocol connections to cluster 'myCluster':
- Read/Write Connections: localhost:64460
- Read/Only Connections: localhost:64470
E' chiaro quali siano le porte da utilizzate inizialmente: 6446 (R/W) e 6446 (R/O)!
Il comando di bootstrap crea il file di configurazione mysqlrouter.conf
che contiene le sezioni con le configurazioni di dettaglio.
La configurazione e' completa ed immediatamente utilizzabile;
modificare le porte o gli indirizzi di ascolto
richiede la semplice modifica del file di configurazione
che puo' essere effettuata in qualsiasi momento.
- Attivare MySQL Router
# nohup mysqlrouter &
Per attivare automaticamente come servizio il proxy su CentOS 7 i comandi sono
[NdaA da utilizzare in alternativa al lancio in nohup]:
# systemctl enable mysqlrouter
# systemctl start mysqlrouter
Una volta configurato MySQL Router si puo' avviare con mysqlrouter &
o, meglio, definendolo ed attivandolo come servizio (eg. sudo systemctl enable mysqlrouter; sudo systemctl start mysqlrouter).
Ecco le sezioni piu' significative del file di configurazione del router
che riportano i nodi del cluster e le porte di accesso:
[metadata_cache:myCluster]
router_id=3
bootstrap_server_addresses=mysql://localhost:3310,mysql://localhost:3320,mysql://localhost:3330
user=mysql_router3_xxxxxxxxxxxx
metadata_cluster=myCluster
ttl=300
[routing:myCluster_default_rw]
bind_address=0.0.0.0
bind_port=6446
destinations=metadata-cache://myCluster/default?role=PRIMARY
mode=read-write
protocol=classic
[routing:myCluster_default_ro]
bind_address=0.0.0.0
bind_port=6447
destinations=metadata-cache://myCluster/default?role=SECONDARY
mode=read-only
protocol=classic
Ovviamente si puo' preparare a mano e modificare ogni parametro...
ma generato con il comando di bootstrap e poi modificato e' molto piu' facile.
Tra i parametri che e' possibile variare il bind_address impostato consente connessioni
provenienti da qualsiasi IP, se si vogliono consentire solo connessioni locali va utilizzata
l'impostazione bind_address=127.0.0.1.
Altro parametro molto importante e' bind_port
che indica la porta utilizzata in LISTEN
[NdA si puo' anche utilizzare la sintassi bind_address=127.0.0.1:6446 per cambiare entrambe i parametri].
Quando MySQL Router viene avviato legge il file di configurazione,
si connette ad una delle istanze registrate,
ricava la configurazione aggiornata del cluster dal meta-database,
analizza lo stato del cluster ed e' quindi pronto ad operare come proxy per le connessioni.
Avvertenze per l'uso
Il cluster e' configurato (3 passi), il proxy e' attivo (2 passi): passiamo alle applicazioni!
Facilissimo:
per collegarsi al DB ed effettuare modifiche basta collegarsi in locale alla porta 6446
[NdA o a quella configurata successivamente].
Idealmente non vi sarebbero altre modifiche nelle applicazioni...
ma in questo capitolo cercheremo di vedere i cambiamenti piu' importanti.
E' disponibile una seconda porta per le sessioni in sola lettura: 6447.
Molte applicazioni prevedono l'uso di una seconda connessione in lettura perche'
in questo modo si bilancia il carico su tutti i nodi disponibili
ottenendo migliori prestazioni.
Come fa l'utente o l'applicazione a capire su quale nodo va a finire?
Premesso che non sono fatti suoi... ecco la query:
$ mysql --user=root -p --host=127.0.0.1 --port=6446
mysql> select @@hostname, @@port;
+------------------------+--------+
| @@hostname | @@port |
+------------------------+--------+
| db01.xenialab.it | 3306 |
+------------------------+--------+
Insomma basta chiedere nome host e porta,
sono quelli del DB su cui si e' stati indirizzati!
Le applicazioni che utilizzano l'InnoDB Cluster
debbono rispettare alcuni vincoli:
- Ogni tabella deve avere una chiave primaria
- Viene replicato e va utilizzato solo l'Engine InnoDB
(si puo' utilizzare anche l'Engine MEMORY che ovviamente non viene replicato)
- E' consigliato l'isolation level READ COMMITTED (che non utilizza Gap Locks) e non e' supportato il SERIALIZABLE
- Non sono supportati in fase di certificazione: savepoint, table locks, named locks
In particolare la presenza della primary key per ogni tabella e l'utilizzo del solo Engine InnoDB
sono requisiti fondamentali per le applicazioni...
in qualche caso l'adeguamento dei programmi non richiede alcuno sforzo, in altri potrebbe essere impegnativo.
Nel caso di utilizzo delle configurazione multi-primary sono presenti ulteriori vincoli
(eg. non e' possibile utilizzare DDL e DML contemporaneamente, non sono supportate le foreign key).
Ulteriori indicazioni sono contenute in questo documento...
Configurazioni alternative
La configurazione vista e' solo una di quelle possibili.
Senza entrare in dettagli vediamo alcune possibili alternative.
Oltre alla modalita' di configurazione descritta e' possibile creare un cluster
partendo da una configurazione gia' attiva di Group Replication,
e' solo un poco piu' complesso...
Fondamentalmente al termine della configurazione manuale
della Group Replication viene
importata la definzione del cluster con
var cluster = dba.createCluster('myCluster', {adoptFromGR: true})
InnoDB Cluster supporta anche la configurazione multi-primary,
come descritto in questo documento.
In questo caso il comando per la creazione del cluster e':
var cluster = dba.createCluster('MPClu', {multiMaster: true, force: true})
Il nodo Primary di InnoDB Cluster puo' essere anche uno slave di
una normale configurazione in replica.
Potrebbe sembrare strano ma in realta' e' una modalita' molto utile
per effettura una migrazione riducendo i disservizi.
E' anche possibile configurare una replica tradizionale tra
due InnoDB Cluster. In questo caso pero' vanno evitate
interazioni tra i metadati del cluster con
set replicate_wild_ignore_table=mysql_innodb_cluster_metadata.%
[NdA e' anche opportuno utilizzare la versione 5.7.19 o sup.].
Per provare la configurazione del cluster e' possibile
creare istanze sandbox di MySQL.
In questo caso tutte le istanze sono ospitate sullo stesso server
ed utilizzano porte socket diverse.
Una piu' completa descrizione della configurazione in Sandbox e'
contenuta in questo documento.
NB La configurazione in sandbox non e' adatta per un deploy in produzione.
E' sicuramente molto veloce utilizzare Docker
per attivare istanze MySQL.
Su Docker, oltre al repository ufficiale MySQL,
e' disponibile anche un esempio completo di InnoDB cluster gia' implementato
e molto utile come test:
mattalord/innodb-cluster.
Amministrazione (FAQ)
- Come si controlla lo stato del cluster?
-
Utilizzando i seguenti comandi MySQL Shell:
var cluster = dba.getCluster("myCluster")
cluster.describe()
cluster.status()
cluster.checkInstanceState('db01.xenialab.it:3306')
Ovviamente e' lo stato del cluster il piu' importante... se c'e' OK va bene!
Nel seguito riportiamo qualche dettaglio in piu' sugli stati del cluster
- Come si interrompe e riavvia la replica su un nodo?
- Come si disconnette temporaneamente un nodo dal cluster?
-
Vi sono diversi motivi per farlo: ad esempio per riconfigurare qualche
parametro di tuning... I passi corretti sono:
- STOP GROUP_REPLICATION;
- mysqladmin shutdown (o equivalenti)
Per riconnettere il nodo:
- cluster.rejoinInstance('root:xxx@db02.xenialab.it:3306')
- Come si aggiungono nuovi nodi/istanze al cluster?
- Come si rimuove un'istanza dal cluster?
- In caso di disconnessione di un nodo come lo si riconnette al cluster?
- Sono caduti piu' nodi, come si ricostituisce il cluster?
-
Nel caso in cui siano caduti meno nodi della tolleranza
si riconnettono le istanze come visto nel punto precedente:
cluster.rejoinInstance('root:xxx@db02.xenialab.it:3306')
-
Se invece viene perso il Quorum il cluster non consente piu' operazioni
in scrittura sui dati (per evitare corruzioni).
Per ripristinare l'accesso e' necessario il comando:
cluster.forceQuorumUsingPartitionOf("root:xxx@db01.xenialab.it:3306")
Attenzione a non generare situazioni di Split Brain!
Bisogna verificare che non vi siano altri nodi attivi
prima di forzare il riavvio di una partizione del cluster.
Una volta eseguito il comando i nodi non raggiungibili passano
dallo stato UNREACHABLE a MISSING ed e' nuovamente possibile
effettuare operazioni di scrittura sul DB.
- E' caduto tutto ed il cluster non riparte. Che faccio?
-
Non dovrebbe succedere [NdA che cadano tutti i nodi]...
ma, risolti i problemi di base, si deve ripartire con:
shell.connect('root:xxx@db01.xenialab.it:3306');
var cluster = dba.rebootClusterFromCompleteOutage();
E' "corretto" che il cluster non riparta da solo!
Anche in questo caso attenzione a non generare situazioni di Split Brain!
Se non funziona va ricreato il Cluster da zero
[NdA cluster.dissolve({force: true}) Attenzione: cancella tutto].
- La situazione del cluster ora e' corretta ma il Router non lascia accedere...
- Quale e' lo stato di dettaglio del cluster?
- Ci sono diversi punti di vista...
Dal punto di vista dello stato della replica la situazione puo' essere:
- OK : ovviamente e' tutto a posto!
- OK_PARTIAL : qualche nodo non e' disponibile ma il cluster tollera ulteriori failure.
- OK_NO_TOLERANCE : ci sono dei nodi non attivi ed
un'ulteriore rottura porrebbe il cluster in situazione degradata.
- NO_QUORUM : non e' possibile formare la maggioranza di nodi: il cluster puo' operare
in sola lettura. I dati sono comunque corretti e sicuri su almeno un nodo.
- UNKNOWN : stato del cluster come visto da un'istanza non ONLINE.
Dal punto di vista delle singole istanze queste hanno diversi stati (quando viste da se stesse):

- ONLINE : ovviamente e' tutto a posto!
- RECOVERING : il nodo sta entrando in un gruppo effettuando il recupero delle transazioni.
- OFFLINE : il plugin e' stato caricato ma il nodo non e' configurato.
- ERROR : ovviamente c'e' un problema!
Le istanze hanno stati diversi quando viste dall'esterno:
- ONLINE : ovviamente e' tutto a posto!
- RECOVERING : il nodo sta entrando in un gruppo effettuando il recupero delle transazioni.
- UNREACHABLE : il nodo non e' piu' visibile dagli altri componenti del gruppo.
- (MISSING) : il nodo non e' raggiungibile [NdA perche' non ancora attivato].
Le istanze possono essere in modalita' R/W (read and writable) o R/O (read only).
Lo stato di dettaglio della Group Replication si verifica con semplici SELECT sul performance_schema:
SELECT * FROM performance_schema.replication_group_members;
SELECT * FROM performance_schema.replication_group_member_stats;
SELECT * FROM performance_schema.replication_applier_status;
SHOW BINLOG EVENTS;
Dal punto di vista delle applicazioni tutti gli stati riportati sono indifferenti:
il MySQL Router indirizza sempre i client verso l'istanza corretta.
Nel caso in cui il nodo cui si e' connessi abbia un fault basta effettuare
una riconnessione e si viene indirizzati ad un nodo funzionante.
- Si puo' modificare la configurazione della Group Replication senza usare i comandi MySQL Shell?
-
Non e' consigliato.
Tuttavia e' possibile modificare manualmente ogni configurazione.
Il problema e' che eventuali variazioni sulle istanze non saranno contenute nel Meta Database.
Per riallineare la configurazione:
cluster.rescan()
- Un nodo non vuole entrare nel gruppo?
-
Per controllare se un nodo ha l'impostazione corretta si utilizza il comando
dba.checkInstanceConfiguration(). I principali controlli sono relativi ai
parametri di configurazione ed alla presenza di sole tabelle InnoDB con
chiave primaria. Ecco le query utilizzabili per verificare quest'ultimo
requisito:
SELECT table_schema, table_name, engine
FROM information_schema.tables
WHERE engine NOT IN ('InnoDB', 'MEMORY')
AND table_schema NOT IN ('mysql', 'performance_schema', 'information_schema');
SELECT t.table_schema, t.table_name
FROM information_schema.tables t
LEFT JOIN information_schema.table_constraints c
ON t.table_schema = c.table_schema
AND t.table_name = c.table_name
WHERE t.table_type = 'BASE TABLE'
AND t.table_schema NOT IN ('mysql', 'performance_schema', 'information_schema')
GROUP BY t.table_schema, t.table_name
HAVING sum(if(c.constraint_type='PRIMARY KEY', 1, 0)) = 0;
L'elenco completo dei controlli e' riportato in questo script.
Difficili da diagnosticare sono i problemi legati al networking.
DNS, reverse lookup, file hosts, white list, ... possono ingannare:
come un nodo viene chiamato o come pensa di chiamarsi e' molto importante!
Ulteriori problemi e work around sono descritti con la Group Replication.
Varie ed eventuali
La documentazione ufficiale su InnoDB Cluster e' disponibile sul
sito ufficiale MySQL.
Le AdminAPI sono invece descritte su
questa pagina.
InnoDB Cluster e la Group Replication vengono costantemente aggiornati:
e' importante utilizzare le versioni piu' recenti
di MySQL,
di MySQL Router e
di MySQL Shell.
In attesa della versione 8.0, in cui le release verranno allineate,
le versioni piu' recenti sono [NdA 2018-08-15]:
- mysql-community-server-5.7.23
- mysql-router-2.1.6
- mysql-shell-1.0.11
Oltre ai bug-fixing, presenti in ogni rilascio, sicuramente sono utili
alcuni piccoli miglioramenti introdotti nel tempo:
(MySQL 5.7.19) transaction savepoint support ed i nuovi parametri
group-replication-unreachable-majority-timeout,
group-replication-transaction-size-limit;
(5.7.20) automatic disallow writes leaving the group
ed il parametro group-replication-member-weight;
...
(MySQL Shell 1.0.11) gestione completa del super_read_only;
...
(MySQL Router 2.1.5) riconnessione automatica al primary durante il bootstrap, supportate fino a 5.000 connessioni,
[NdA introduce un bug aggirabile facilmente con connect_timeout=1000]
(MySQL Router 2.1.6) fissa il bug del connect timeout;
(MySQL Router 8.0.4 RC) routing_strategy;
(8.0.16) autorejoin;
...
Simile ad InnoDB Cluster come funzionalita' e protocolli utilizzati e'
Galera Cluster.
Le due soluzioni presentano funzionalita' e caratteristiche comuni
ma anche importanti differenze tecniche...
un confronto spassionato non e' semplice.
Versione 8.0
Molte le
novita' per InnoDB cluster nella versione 8.0: meritano un capitolo a parte!
In effetti per alcune funzionalita' particolarmente importanti
e' stato anche effettuato il backport nella versione 5.7
(eg. savepoint support).
Le versioni piu' recenti sono [NdA 2018-08-15]
hanno ora la stessa numerazione:
mysql-community-server-8.0.12, mysql-router-8.0.12 e mysql-shell-8.0.12
Sono disponibili ulteriori routing strategies:
First-available,
Next-available,
Round-robin e
Round-robin-with-fallback.
E' stato superato il limite delle 500 connessioni client,
e' supportato pienamente l'IPv6,
dalla versione 8.0.16 e' supportato l'autorejoin con il parametro group_replication_autorejoin_tries,
...