Pentaho
Pentaho
e' la piu' diffusa suite di prodotti Open Source per la Business Intelligence.
E' composto da diversi pacchetti tra loro integrati che consentono la gestione
completa di tutte le problematiche della Business Intelligence e dei Data Warehouse.
Questo documento, rivolto ad un pubblico adulto (scherzo... ma questo documento e' sintetico
e quindi si rivolge ad un lettore esperto) si riferisce alla versione Community piu' recente
di Pentaho (NdE Q1 2011: DI 4.1, BI 3.8, RD 3.8, ...)
su Linux (CentOS 5.6) per x86_64 ma e' valido, mutatis mutandis, anche per le altre versioni.
[NdE le versioni piu' recenti, al Q3 2012, sono: DI (pdi-ce) 4.3, BI (biserver-ce) 4.5 e RD (prd-ce) 3.9].
Questo documento presenta diversi aspetti di Pentaho:
Installazione,
Kettle - ETL - Pentaho Data Integration,
BI Server - Business Intelligence Platform,
Mondrian - OLAP - Multidimensional Analysis ,
Weka - Data Mining,
Report Designer,
Enterprise Version,
Altre soluzioni,
...
La conoscenza dei database relazionali e dell'SQL sono un prerequisito
per comprendere appieno questo documento.
Una pagina, un po' vecchiotta, ma molto semplice ed introduttiva sui Data Warehouse
e' Data Warehouse: un'introduzione.
Una pagina con maggiori informazioni su Kettle (la parte di ETL)
e' disponibile qui.
Oltre alla edizione Community Pentaho distribuisce anche una edizione Enterprise
della propria suite
con funzionalita' aggiuntive e con un supporto Enterprise (anche 7x24).
Questo documento si riferisce ai soli componenti e caratteristiche della versione
Pentaho Community, tranne che
nell'ultimo capitolo.
Installazione
L'installazione e' generalmente semplice...
E' sufficiente scaricare il software corretto dal sito
Sourceforge.
I nomi dei componenti della suite sono cambiati piu' volte nel corso del tempo...
i componenti piu' utilizzati sono attualmente:
Data Integration, Business Intelligence Server, Report Designer, Pentaho Metadata.
I file sono tipicamente tarball (eg. pdi-ce-4.3.0-stable.tar.gz biserver-ce-4.5.0-stable.tar.gz) ed e'
sufficiente scaricarli e decomprimerli su una directory (eg. /usr/local/data-integration).
Si tratta principalmente di applicazioni Java, che possono girare su
qualsiasi piattaforma, e di alcuni script per il lancio sulle piattaforme
piu' comuni (eg. .sh per Unix/Linux, .bat per WinX, .app per MAC OS).
Come gia' riportato
la maggioranza dei tool di Pentaho sono realizzati in Java. E' quindi necessario disporre di una JVM
recente (eg. jre-6u25-linux-x64-rpm.bin scaricato da http://java.oracle.com).
Per impostare il JRE corretto e' sufficiente
impostare la variabile d'ambiente PENTAHO_JAVA_HOME (eg. PENTAHO_JAVA_HOME=/usr/java/jre1.6.0_25; export PENTAHO_JAVA_HOME) prima di lanciare i comandi di Pentaho (oppure nel .bash_profile).
[NdA su alcune versioni viene usata la variabile _PENTAHO_JAVA_HOME ed in qualche caso
e' necessario impostare PATH=$PENTAHO_JAVA_HOME/bon:$PATH]
Se si utilizza un'interfaccia grafica X e' ovviamente necessario impostare la variabile DISPLAY.
In qualche caso puo' essere necessario installare qualche ulteriore driver JDBC...
Basta mettere il .jar nella directory corretta!
Kettle - ETL - Data Integration
 Da qualche parte bisogna pure iniziare... e la parte di ETL e' molto importante!
Generalmente si parte dalla BI Platform,
ma di solito mi occupo degli aspetti piu' tecnici
sui database e non delle funzionalita' per gli utenti: quindi preferisco partire dal basso
con i dati.
Da qualche parte bisogna pure iniziare... e la parte di ETL e' molto importante!
Generalmente si parte dalla BI Platform,
ma di solito mi occupo degli aspetti piu' tecnici
sui database e non delle funzionalita' per gli utenti: quindi preferisco partire dal basso
con i dati.
Innanzi tutto la nomeclatura. L'argomento di questo capitolo sono gli strumenti di ETL
forniti da Pentaho. ETL sta per Extract, Transform and Load. In realta' la suite
Pentaho fa anche un passo in piu': il Transport e quindi a volte si usa l'acronimo ETTL.
Storicamente si tratta del pacchetto Open Source Kettle che ha un nome piu' corto
del nuovo nome ufficiale Pentaho Data Integration o Pentaho DI...
pero' io sono vecchio quindi continuero' a chiamarlo Kettle!
Kettle e' molto completo e copre tutte le funzionalita' di un ETL.
Un'unica distribuzione e' utilizzabile su piu' piattaforme (eg. Linux, WinX, MAC OS)
ed e' realizzato per la maggior parte in Java.
I componenti principali di kettle sono: Spoon (disegno grafico dei passi dell'ETL),
Pan (esecuzione delle Trasformazioni da linea di comando),
Kitchen (esecuzione dei Job da linea di comando),
Carte (esecuzione remota).
Con Spoon si disegnono graficamente le Trasformazioni ed i Job.
L'interfaccia grafica di Spoon presenta tutti i dettagli di quanto si sta programmando,
come appare nella figura a destra.
Per eseguire Spoon? Basta lanciare spoon.sh
Le trasformazioni sono composte da vari Step connessi tra loro da collegamenti chiamati Hop.
Una tipica trasformazione inizia con uno Step di Input, uno o piu' Step di trasformazione ed uno
Step di Output. Tutta la programmazione avviene in modo grafico e guidato:
le connessioni ai database sono create con semplici wizard,
le tabelle vengono esplorate facilmente in automatico,
i campi sono selezionati con un click, ...
i collegamenti tra un passo e quello sucessivo possono essere definiti in automatico o
selezionati campo per campo, ...
Vi sono diversi possibili step organizzati per tipologia: Input, Output, Transform, Lookup, ...
E' importante sottolineare che gli step di Input ed Output sono particolarmente potenti.
E' possibile accere a database via JDBC, ODBC, OCI e JNDI... Con il JDBC sono disponibili
wizard guidati per la definizione della connessione ad una quarantina di tipi di database differenti.
Ed ovviamente e' possibile agire sull'SQL generato di default
introducendo tutte le clausole necessarie.
Altrettanto potente e' la possibilita' di combinare le informazioni, eventualmente
provenienti da sorgenti differenti, con operazioni di sort, join, split, ...
disegnandone il flusso con una sequenza di Hop.
Alcune utili indicazioni nel disegno degli step sono disponibili sul
Wiki.
Ecco alcuni Step che dimostrano la grande quantita' di funzioni disponibili in Kettle:



 Anche i Job vengono definiti in modo grafico.
Particolarmente potenti sono i wizard disponibili nel menu Tool (eg. Tools -> Wizard -> Copy Tables)...
basta definire le connessioni al DB di partenza e di arrivo e con qualche click si effettua il
ribaltamento di un'intera base dati: dalla creazione delle tabelle alle singole trasformazioni per
ciascuna tabella.
Il tipo di database tra step di Input e di Output
puo' essere differente (eg. Oracle, MySQL, PostgreSQL, DB2, ...): in questo modo e' possibile
effettuare una migrazione strutture/dati completa.
Una volta creati tutti gli oggetti (trasformazioni) e' possibile modificarli singolarmente
adattandoli ad eventuali esigenze specifiche.
Anche i Job vengono definiti in modo grafico.
Particolarmente potenti sono i wizard disponibili nel menu Tool (eg. Tools -> Wizard -> Copy Tables)...
basta definire le connessioni al DB di partenza e di arrivo e con qualche click si effettua il
ribaltamento di un'intera base dati: dalla creazione delle tabelle alle singole trasformazioni per
ciascuna tabella.
Il tipo di database tra step di Input e di Output
puo' essere differente (eg. Oracle, MySQL, PostgreSQL, DB2, ...): in questo modo e' possibile
effettuare una migrazione strutture/dati completa.
Una volta creati tutti gli oggetti (trasformazioni) e' possibile modificarli singolarmente
adattandoli ad eventuali esigenze specifiche.
Le trasformazioni ed i Job disegnati con Spoon vengono salvati su un Repository.
Il repository puo' essere su DB o su una directory.
Quando il repository e' su una directory
questa contiene semplicemente le trasformazioni come singoli file XML con il suffisso .ktr
ed i Job con il suffisso .kjb.
Da Spoon e' possibile lanciare tutte le trasformazioni ed effettuarne il debug,
pero' a regime l'esecuzione avviene su server dedicati e schedulata a tempo.
Le Trasformazioni realizzate con Spoon vengono lanciate con Pan.
Ecco come lanciare una trasformazione, anche molto complessa, da linea di comando:
/usr/local/data-integration/pan.sh -file /usr/local/data-integration/Repo/LetturaDati.ktr
Semplicissimo! E' ovviamente possibile preprare script piu' complessi, inserirli a crontab,
verificarne il codice d'errore, ...
L'output viene tipicamente ridiretto su un log ed analizzato in caso di problemi:
INFO 07-06 06:10:02,486 - Using "/tmp/vfs_cache" as temporary files store.
INFO 07-06 06:10:02,712 - Pan - Start of run.
INFO 07-06 06:10:02,902 - Lettura dati per DWH - Dispatching started for transformation [Lettura dati per DWH]
INFO 07-06 06:10:02,929 - Lettura dati per DWH - This transformation can be replayed with replay date: 2011/06/07 06:10:02
INFO 07-06 06:10:03,233 - DB DWH - Connected to database [Self DB] (commit=100)
INFO 07-06 06:10:03,599 - DB AS_UTIL - Finished reading query, closing connection.
INFO 07-06 06:10:03,614 - DB AS_UTIL - Finished processing (I=27, O=0, R=0, W=27, U=0, E=0)
INFO 07-06 06:10:03,625 - DB DWH - Finished processing (I=0, O=27, R=27, W=27, U=0, E=0)
INFO 07-06 06:10:03,626 - Pan - Finished!
INFO 07-06 06:10:03,627 - Pan - Start=2011/06/07 06:10:02.713, Stop=2011/06/07 06:10:03.626
INFO 07-06 06:10:03,627 - Pan - Processing ended after 0 seconds.
INFO 07-06 06:10:03,627 - Lettura dati per DWH -
INFO 07-06 06:10:03,627 - Lettura dati per DWH - Step DB AS_UTIL.0 ended successfully, processed 27 lines. ( - lines/s)
INFO 07-06 06:10:03,628 - Lettura dati per DWH - Step DB DWH.0 ended successfully, processed 27 lines. ( - lines/s)
Oltre a Pan, per la schedulazione dei Job viene utilizzato Kitchen mentre per
l'esecuzione remota viene utilizzato Carte.
Per utilizzare Spoon e' consigliabile un buon desktop con sufficiente memoria
Le prestazioni di Spoon non sono
di solito un problema poiche' e' utilizzato per programmare ed effettuare test,
non per effettuare attivita' massive.
Per rendere efficienti le trasformazioni lanciate con Pan e' invece necessario un server adeguatamente
dimensionato. Ogni step utilizza connessioni differenti ed i Job possono generalmente essere eseguiti
in parallelo. E' molto importante anche la collocazione in rete dell'ETL: e' necessario evitare
inutili passaggi tra reti differenti e Firewall. Una scelta possibile sono i DB Server di partenza
o di arrivo, ma spesso si preferisce centralizzare tutti gli ETL su un unico server, posto nella stessa rete,
per avere un maggior controllo e flessibilita'.
 Quando il gioco si fa duro...
si fa un'analisi fatta bene!
Ma se veramente il progetto e' significativo e bisogna ottimizzare...
si sfrutta al massimo il parallelismo,
si configura con attenzione il numero di record per commit,
si lavora per delta,
si dimensionano adeguatamente i server e le connessioni di rete,
si schedulano con attenzione i job load e le finestre temporali,
si effettua solo il minimo necessario richiesto,
si utilizzano i Bulk load (disponibili verso diversi tipi di DB),
si effettua un tuning specifico delle basi dati (eg. nologging, drop idx, partitioning, noconstraint),
si spezzano le fasi di ETL ed, eventualmente, si utilizzano tool specifici per alcune di esse (eg. SQL*Loader),
si valuta l'utilizzo della versione Enterprise...
insomma i duri cominciano a giocare!
Quando il gioco si fa duro...
si fa un'analisi fatta bene!
Ma se veramente il progetto e' significativo e bisogna ottimizzare...
si sfrutta al massimo il parallelismo,
si configura con attenzione il numero di record per commit,
si lavora per delta,
si dimensionano adeguatamente i server e le connessioni di rete,
si schedulano con attenzione i job load e le finestre temporali,
si effettua solo il minimo necessario richiesto,
si utilizzano i Bulk load (disponibili verso diversi tipi di DB),
si effettua un tuning specifico delle basi dati (eg. nologging, drop idx, partitioning, noconstraint),
si spezzano le fasi di ETL ed, eventualmente, si utilizzano tool specifici per alcune di esse (eg. SQL*Loader),
si valuta l'utilizzo della versione Enterprise...
insomma i duri cominciano a giocare!
Il fatto che i tool di Kettle siano applicazioni Java non e' un problema:
si trova sempre il modo di rendere efficiente la parte che si trova sul percorso critico
e di gestirla come Job Kettle.
Concludendo Kettle e' una suite molto potente e completa adatta sia alle esigenze piu' semplici
di Data Management
che a configurazioni complesse e di grandi dimensioni
come richiesto nei progetti di Data Warehouse e di Business Intelligence.
BI Server - Business Intelligence Platform
 La piattaforma di Business Intelligence e' al tempo stesso potente e semplice da utilizzare.
Con il BI server e' possibile realizzare, accedendo con un browser, report e cubi OLAB
oppure rendere disponibili su web le applicazioni realizzate con gli altri tool di Pentaho
[NdE la versione descritta in questo paragrafo e' relativamente vecchia
ma i concetti di base sono ancora validi,
una descrizione piu' aggiornata si trova su questo documento].
La piattaforma di Business Intelligence e' al tempo stesso potente e semplice da utilizzare.
Con il BI server e' possibile realizzare, accedendo con un browser, report e cubi OLAB
oppure rendere disponibili su web le applicazioni realizzate con gli altri tool di Pentaho
[NdE la versione descritta in questo paragrafo e' relativamente vecchia
ma i concetti di base sono ancora validi,
una descrizione piu' aggiornata si trova su questo documento].
L'utilizzo e' molto semplice: si tratta di un'applicazione web che con un menu ed alcuni wizard
consente la creazione, la gestione e l'utilizzo di contenuti (che possono essere report, dashboard,
cubi multidimensionali, ...).
Dal punto di vista tecnico si tratta di un'applicazione Java ospitata su un server Tomcat.
L'installazione e' banale: un semplice unzip (o un gunzip e tar x).
Per attivarla basta lanciare lo script biserver-ce/start_pentaho.sh ed e' possibile accedere
alla User Console con un browser su http://localhost:8080.
Effettuato il login (l'utente amministratore di default e'
joe/password) si accede alla Home Page:
Un Analysis view e' un cubo OLAP. Con BI Server e' facile da costruire e da utilizzare.
La parte complessa e' la query SQL con cui estrarre i dati, ma questa la diamo per scontata!
Nella query la cosa importante e' raccogliere tutti
i dati di dettaglio ed i valori delle dimensioni di analisi.
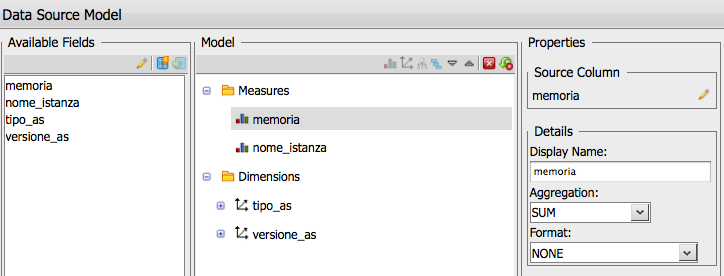
La definizione del cubo di analisi si effettua impostando le dimensioni di analisi
in fase di creazione o modifica del data source, mentre la scelta delle righe/colonne e dei filtri
e' dinamica e puo' essere cambiata durante l'utilizzo.
Ecco un esempio:


Definito un cubo e' poi possibile giocare (il programma di visualizzazione e' jpivot)
raggruppando o mettendo condizioni sulle dimensioni
di analisi. Oppure, come gia' ricordato, selezionando la prima icona
(quella a forma di cubo) si possono modificare le righe
e le colonne per analizzare i dati.
Con BI Server possono essere creati report attraverso un semplice wizard:


Con il BI Server, oltre che realizzare semplici cubi OLAP e report, e' anche possibile
utilizzare applicazioni piu' complesse realizzate con gli altri tool di Pentaho (eg. Report Designer).
La pubblicazione e' molto semplice perche' e' possibile effettuarla direttamente
con i tool di sviluppo semplicemente indicando l'URL del BI Server.
E' solo necessario configurare
una password per la pubblicazione nel file publisher_config.xml.
Il path di default e' .../pentaho-solutions/system/publisher_config.xml.
La password inizialmente non e' impostata per ragioni di sicurezza e non e'
cosi possibile effettuare il publishing fino a che non viene configurata.
Ogni oggetto pubblicato viene salvato con una serie di file
all'interno della directory pentaho-solutions.
I file presenti dipendono dal tipo di oggetto ma e' sempre presente un file di
tipo .xaction che riporta gli estremi dell'oggetto e delle attivita' da svolgere.
I report e le dashboard che e' possibile realizzare con Pentaho e pubblicare sulla BI Platform
sono molto accattivanti. Ecco uno dei molti esempi disponibili:
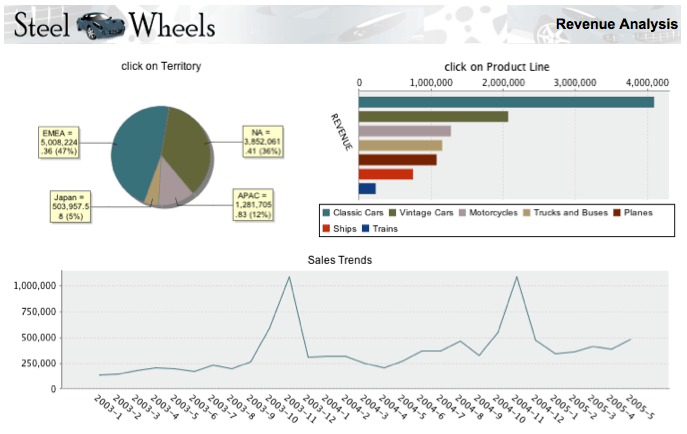
Dalla User Console e' possibile effettuare alcune operazioni
di amministrazione sugli oggetti definiti quali definire DB Connection,
schedulare report, autorizzare altri utenti, ...
Le attivita' di gestione del server BI a livello globale
sono pero' effettuate con la console di amministrazione (pac: Pentaho Administration Console).
Anche la console di amministrazione e' un'applicazione Tomcat.
Per attivarla basta lanciare lo script administration-console/start-pac.sh ed e' possibile accedere
alla User Console con un browser su http://localhost:8099.
Effettuato il login (l'utente amministratore di default e'
admin/Pentaho o admin/password a seconda delle versioni) e' possibile accedere alle funzioni amministrative.
Le funzioni principali sono la gestione di utenti e ruoli
e la definizione delle DB connection.
E' anche possibile ripulire le cache o schedulare attivita' amministrative.
Ma se si vuole fare qualcosa in piu'... bisogna mettere le mani sui file di configurazione
ed ai programmi!
Tomcat non e' difficile da gestire e configurare. Il principale file di configurazione e'
server.xml.
La pagina di login iniziale e' configurabile agendo sul file
\tomcat\webapps\pentaho\mantleLogin\loginsettings.properties.
Le utenze e le password sono riportate in chiaro e possono essere modificate a piacere.
E' possibile non visualizzare la lista degli utente impostando showUsersList=false.
La pagina di login puo' essere cambiata completamente (per esempio mettendo il logo
del cliente) agendo sul file /tomcat/webapps/pentaho/jsp/PUC_Login.JSP (che ovviamente
e' una pagina JSP).
Possono essere modificate anche le stringhe di messaggio
(tutte le stringhe di messaggio: non solo gli errori ma anche quanto visualizzato
sui menu, i titoli delle finestre, i messaggi in fase di caricamento, gli errori, ...)
agendo sul file
\tomcat\webapps\pentaho\mantle\messages\messages_en.PROPERTIES (ed ovviamente _it per l'italiano).
Questo per iniziare: si tratta di pagine JSP, file .html, file .properties, ...
tutto puo' essere personalizzato!
Una semplice guida sull'argomento e'
questa!
La programmazione con le JSP puo' non essere alla portata di tutti...
allora e' disponibile il CDF (Community Dashboard Framework)
che consente di "legare assieme" componenti creando una dashboard
senza alcuna necessita' di programmazione in JSP (basta creare/modificare file HTML, CSS, ...).
Concludendo la Pentaho BI Server Platform e' un ambiente molto completo per la Business Intelligence
che offre funzionalita' paragonabili, se non superiori, alla maggioranza delle soluzioni BI commerciali.
Mondrian - OLAP - Multidimensional Analysis
Mondrian e' il prodotto che fa i cubotti! Vediamo cosa sono...
I dati presentati da un OLAP hanno una forma particolare utilizzata per l'analisi multidimensionale.
Mentre una tabella relazionale mantiene i dati in tabelle formate da righe e colonne,
i dati OLAP consistono in assi (potenzialmente molti) e celle.
Mondrian e' un motore OLAP (Online Analytical Processing) scritto in Java.
Mondiran esegue query scritte nel linguaggio MDX
(MultiDimensional eXpressions: una specie di SQL per cubi OLAP),
legge dati da un database relazionale, e presenta i resultati in
formato multidimensionale attraverso un API.
Quindi, per essere precisi, Mondrian e' un ROLAP (Relational) poiche' si basa su una base dati relazionale per
ricavare i dati senza necessita' di un preprocessing iniziale.
In Mondrian uno schema definisce un database multidimensionale.
Il formato di uno schema e' l'XML.
Uno schema definisce il modello logico con tutti i cubi, le misure, le dimensioni, i membri, le gerarchie,
i livelli ed il mapping al modello fisico.
Il cubo e' l'elemento piu' alto che contiene tutto il resto.
Una misura e' un valore che che si vuole controllare (eg. il valore di un ordine).
Una dimensione e' su cosa si vogliono analizzare i dati (eg. il cliente, l'oggetto della fornitura)
e puo' essere messo in gerarchia su piu' livelli (eg. la regione del cliente).
Le dimensioni di tipo temporale (type="TimeDimension") vengono
mappate in modo specifico da Mondrian con la gerarchia year/month/week/day.
Mondrian supporta i piu' comuni mapping ai modelli fisici:
una singola fact table, lo star schema, lo snowflake schema, ...
Maggiori dettagli? Leggete questo documento...
Ora basta teoria, proviamo praticamente con il tool grafico
Mondrian Schema Workbench!

Quando il gioco si fa duro...
le prestazioni possono non essere all'altezza delle attese.
Capita spesso con i ROLAP, a mio parere perche' sono troppo facili da realizzare,
magari direttamente sui dati di produzione!
In questi casi va disegnata con attenzione una base dati ad hoc:
il classico disegno normalizzato per gli OLTP non va bene.
Meglio un disegno denormalizzato della base dati (eg. fact table, star schema),
creazione di tabelle di raggruppamento per le dimensioni piu' utilizzate,
dati caricati con un ETL (ovviamente Kettle con Pentaho),
aggiornamento dati notturno o settimanale, ...
L'utilizzo di un database dedicato (Data Warehouse, Data Mart, ... poco importa),
consente di ottimizzare in modo verticale le prestazioni per il tipo di utilizzo
ed il carico previsto. La scalabilita' sul carico e' orizzontale
(il DB e' in sola lettura, basta replicarlo).
Insomma i duri cominciano a giocare!
Ma le prestazioni non sono l'unico punto critico...
La chiarezza dei dati e' fondamentale nella BI.
Quello che non e' ben definito va chiarito o eliminato!
Se invece il problema e' di usabilita' o facilita' dell'interfaccia (jpivot non e' il massimo)...
beh si spezzano i cubi e si realizzano interfacce ad hoc.
Se anche questo non basta... forse l'utente ha chiesto un OLAP ma in realta' voleva una dashboard!
Concludendo Mondrian e' uno strumento potente e "standard" per l'analisi multidimensionale.
La visualizzazione dei cubotti con jpivot non e' la piu' accattivante,
tra quelle presenti sul mercato, ... ma e' completa e potente.
Weka - Data Mining
Se Mondrian serve ad analizzare i dati nel loro insieme, raggruppandone i valori e mostrandoli
aggregati su un cubo a piu' dimensioni ... Weka fa il contrario: consente di scavare nei dati
mostrandone i dettagli e le differenze.
Infatti Weka e' lo strumento di Data Mining della Suite Pentaho.
In realta' il nome ufficiale e' Pentaho Data Mining Community Edition (CE) ma per tutti si chiama Weka.
Weka e' un'insieme di tool di machine learning e data mining.
Ogni tipologia di componente e' definita come un'interfaccia Java che deinisce quali metodi debbono
essere implementati per sviluppare un nuovo componente.
Tale struttura aperta ha favorito la realizzazione di centinaia di classi e generalmente non e'
piu' necessario sviluppare alcun nuovo oggetto ma sfruttare uno dei moltissimi presenti.
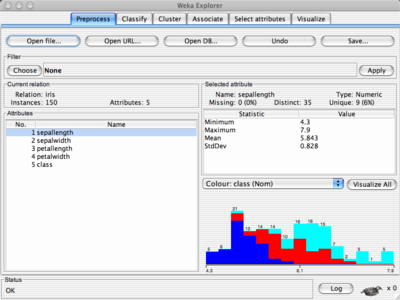
Il punto di partenza e' quello dei dataset, che sono i dati in input (Instance class),
descritti in un file ARFF.
Viene poi applicato un filtro di preprocessing.
Il package weka.filters e' utilizzato per trasformare (preprocessing) i dati di input.
I Classifier sono gli algoritmi di machine learning sono disponibili decine di algoritmi differenti...
Ora basta teoria, proviamo praticamente con il tool grafico
Weka Knowledge Explorer!
Ogni package Weka ha un pannello di visualizzazione (eg. Filter, Classifier, Clusterer, Association, and Attribute Selection, ...)
con una visualizzazione bidimensionale delle predizioni.
Perche' mi piaceva ho messo anche quello della rete neurale...
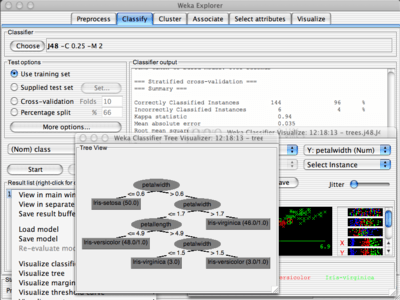
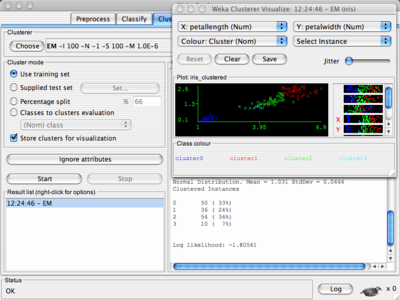

Il maggior rischio con il data mining?
Scoprire l'acqua calda!
Bisogna fare attenzione ai dati introdotti, a cosa si vuole realmente cercare ed ai numeri...
Concludendo con Weka si ha molto di piu' di quello che si e' generalmente in grado di capire
e di utilizzare di uno strumento di data mining e machine learning.
E' completo, espandibile ed aperto: un'ottima suite.
Report Designer
Pentaho Report Designer... disegna i report!
Non c'e' molto da scrivere sulla teoria perche' si tratta di concetti relativamente banali...
in realta' il Reporting di Pentaho e' un prodotto molto completo, con moltissime funzionalita'
(alcune non proprio immediate) che consente di preparare report e dashboard molto
efficaci.
Quindi non c'e' molto da scrivere ma moltissimo da provare poiche' e' questo lo strumento piu' utilizzato
di tutta la Suite Pentaho. Ecco un esempio:
Enterprise Edition
Pentaho distribuisce una versione Enterprise,
a pagamento, della sua suite di prodotti.
Sulla versione Enterprise e' fornito il supporto completo.
La versione Enterprise mostra una maggiore integrazione delle varie componenti
(anche se le piu' recenti versioni Community sono ben integrate e facilmente utilizzabili).
Nella versione Enterprise sono presenti features specifiche non disponibili nelle versioni
community: queste funzionalita' riguardano tipicamente gli aspetti di gestione (eg. Enterprise Console),
di centralizzazione degli accessi, un maggior livello di parallelismo, ...
Anche se la versione Enterprise ha un costo, questo e' generalmente
inferiore al costo di soluzioni completamente commerciali.
Il costo dipende dal numero di CPU... indicativamente 5K$ per CPU con forti sconti a salire sul numero di CPU.
Il costo e' annuo e comprensivo del supporto (non c'e' un costo di licenza iniziale).
etc
Pentaho non e' l'unica suite BI disponibile: e' importante conoscere le diverse alternative.
Anche se si tratta di soluzioni tecnicamente molto differenti.
Principali soluzioni Open Source:
Pentaho,
Jaspersoft,
Talend,
PSPP,
icCube,
SpagoBI,
Palo,
...
Principali soluzioni proprietarie (i primi 4 vendor sono chiamati Big Four):
Microsoft
Analysis Services;
Oracle
Essbase (Hyperion),
BI EE,
OLAP,
IBM
Cognos,
Cognos TM1 (Applix),
SPSS;
SAP
Business Objects,
Microstrategy,
SAS,
Jedox,
...
Non fatevi ingannare dalle poche righe precedenti: sono solo alcuni dei prodotti presenti sul mercato
e ciascun ambiente richiederebbe da solo centinaia di pagine di descrizione.
Stay tuned: l'analisi dei dati sara' sempre piu' importante nei prossimi, forse nuvolosi,
anni a venire...