Kettle
La suite Open Source Pentaho
contiene diversi pacchetti tra loro integrati che consentono la gestione
completa di tutte le problematiche della Business Intelligence e dei Data Warehouse.
Kettle Data Integration
e' la componente ETL di
Pentaho,
ovvero si occupa dell'estrazione, della trasformazione e del trasferimento dei dati.
Kettle e' una suite molto potente e completa adatta sia alle esigenze piu' semplici
di Data Management
che a configurazioni complesse e di grandi dimensioni
come richiesto nei progetti di Data Warehouse e di Business Intelligence.
Questo documento presenta diversi aspetti di Kettle:
Introduzione,
Installazione,
La Suite Kettle - Pentaho Data Integration,
Spoon,
Pan e Kitchen,
Carte,
Sizing,
Performance,
Tips and Tricks,
Varie ed eventuali,
Novita' (Big Data e NoSQL),
...
Questo documento, rivolto ad un pubblico adulto (scherzo... ma questo documento e' sintetico
e quindi si rivolge ad un lettore esperto) e' stato mantenuto dalla versione 4.1
di Pentaho Kettle Community (Q1 2011) fino alla versione 8.3 (Q2 2019).
La Suite Pentaho nel suo insieme e' descritta
in questo documento.
La conoscenza dei database relazionali e dell'SQL
sono un prerequisito per la comprensione di questo documento.
Un documento, un po' vecchiotto, ma molto semplice ed introduttivo sui Data Warehouse
e' Data Warehouse: un'introduzione.
Introduzione
Kettle e' lo strumento di ETL fornito da Pentaho.
ETL sta per Extract, Transform and Load.
Ovvero reperire i dati da diverse sorgenti, trasformarli e caricarli da qualche parte.
In realta' la suite
Pentaho Kettle fa anche un passo in piu': il Transport e quindi a volte si usa l'acronimo ETTL.
Storicamente si tratta del pacchetto Open Source Kettle. Ora un
nuovo nome ufficiale piu' lungo: Pentaho Data Integration o Pentaho DI
e fa parte della Suite di Hitachi Vantara...
pero' io sono vecchio quindi continuero' a chiamarlo Kettle!
Kettle e' molto completo e copre tutte le funzionalita' di un ETL.
Kettle e' realizzato per la maggior parte in Java ed
un'unica distribuzione e' utilizzabile su piu' piattaforme (eg. Linux, MS-Windows, MAC OS).
I componenti principali di kettle sono: Spoon (disegno grafico dei passi dell'ETL),
Pan (esecuzione da linea di comando delle trasformazioni),
Kitchen (esecuzione dei job),
Carte (console per l'esecuzione remota).
Nei prossimi capitoli vedremo in dettaglio l'architettura dei singoli componenti,
le funzionalita' di ogni modulo
ed alcuni esempi pratici.
Installazione
L'installazione e' semplice...
e' sufficiente scaricare il software corretto [NdA ovviamente l'ultima versione:
al Q2 2019 e' pdi-ce-8.3.0.0-371.zip] dal sito
Sourceforge
ed basta scaricarlo su una directory (eg. /usr/local/pdi) perche' sia gia' utilizzabile
[NdA le versioni piu' recenti sono disponibili sul sito
Hitachi Vantara].
Nella directory si trovano le applicazioni Java, che possono girare su
qualsiasi piattaforma, ed alcuni script per il lancio dei programmi sulle piattaforme
piu' comuni (eg. .sh per Unix/Linux, .bat per WinX, .app per MAC OS).
E' consigliabile utilizzare un'utenza non amministrativa
per il lancio di programmi.
Basta creare un'utente (eg. pentaho:pentaho) e verificare
i permessi su /usr/local/pdi.
La maggioranza dei tool di Pentaho sono realizzati in Java (swing per la parte grafica).
E' quindi necessario disporre di una JVM recente
[NdA nell'ultima versione e' supportata anche l'OpenJDK 8].
Per impostare il JRE corretto e' sufficiente
impostare la variabile d'ambiente PENTAHO_JAVA_HOME.
Se si utilizza un'interfaccia grafica X e' ovviamente necessario impostare la variabile DISPLAY.
E' opportuno aggiornare/installare i driver JDBC posti nella directory: data-integration/lib.
Problemi? Parliamone!
La Suite Kettle - Data Integration
Kettle e' lo strumento di ETL
fornito da Pentaho. ETL sta per Extract, Transform and Load. In realta' la suite
Pentaho fa anche un passo in piu': il Transport e quindi a volte si usa l'acronimo ETTL (k ETTL e).
Ecco l'origine del nome del pacchetto Open Source Kettle;
ora il nome ufficiale e' Pentaho Data Integration
pero' sono vecchio... quindi continuero' a chiamarlo Kettle!
Spesso si utilizzano anche i nomi Pentaho DI, PDI, ... ma e' sempre lo stesso oggetto.
Kettle e' molto completo e copre tutte le funzionalita' di un ETL classico.
Kettle e' realizzato per la maggior parte in Java
ed un'unica distribuzione e' utilizzabile su tutte le piattaforme (eg. Linux, WinX, MAC OS).
I componenti principali della Suite Kettle sono: Spoon (disegno grafico dei passi dell'ETL),
Pan (esecuzione da linea di comando delle trasformazioni),
Kitchen (esecuzione da linea di comando dei job),
Carte (console per l'esecuzione remota).
Gli oggetti fondamentali di Kettle sono le Trasformazioni ed i Job.
 Le Trasformazioni indicano come debbono essere raccolti, trasformati e ricaricati i dati.
Le trasformazioni sono composte da vari Step connessi tra loro da collegamenti chiamati Hop.
Una tipica trasformazione inizia con uno Step di Input, uno o piu' Step di trasformazione ed uno
Step di Output.
Vi sono diversi possibili Step organizzati per tipologia:
Input, Output, Transform, Utility,
Flow, Scripting, Lookup, Joins, Data Warehouse, Validation, Statistics, Job,
Mapping, Inline, Experimental, Bulk loading,
...
Le Trasformazioni indicano come debbono essere raccolti, trasformati e ricaricati i dati.
Le trasformazioni sono composte da vari Step connessi tra loro da collegamenti chiamati Hop.
Una tipica trasformazione inizia con uno Step di Input, uno o piu' Step di trasformazione ed uno
Step di Output.
Vi sono diversi possibili Step organizzati per tipologia:
Input, Output, Transform, Utility,
Flow, Scripting, Lookup, Joins, Data Warehouse, Validation, Statistics, Job,
Mapping, Inline, Experimental, Bulk loading,
...
A sua volta ciascuna tipologia di Step contiene decine di possibilita'. Ad esempio
uno Step di Input puo' prelevare i dati: da una tabella di un DB relazionale (un qualsiasi database
raggiungibile via JDBC), da un file con tracciato record fisso, da un file CSV,
da un foglio MS-Excel, ...
Gli Hop che collegano i vari step di una trasformazione rappresentano il flusso dei dati e trasportano
il contenuto dei Field da uno Step a quello successivo.
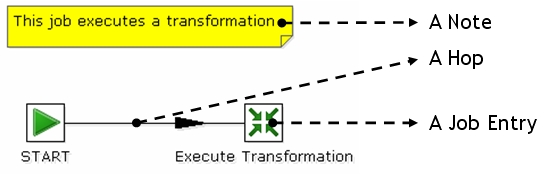 I Job sono graficamente simili alle trasformazioni poiche' sono anch'essi composti da una serie
di Step collegati tra loro con Hop.
I Job servono a coordinare tra loro differenti trasformazioni ed attivita' sui sistemi ospite
(eg. ricezione file, script SQL).
Un tipico Job inizia con uno Step di Start e quindi una sequenza di Step per lanciare
script, Trasformazioni e Job.
Vi sono diversi possibili Step organizzati per tipologia:
Utility, General, Mail, File management, Conditions,
Scripting, Bulk loading, XML, Repository, File tranfer,
...
I Job sono graficamente simili alle trasformazioni poiche' sono anch'essi composti da una serie
di Step collegati tra loro con Hop.
I Job servono a coordinare tra loro differenti trasformazioni ed attivita' sui sistemi ospite
(eg. ricezione file, script SQL).
Un tipico Job inizia con uno Step di Start e quindi una sequenza di Step per lanciare
script, Trasformazioni e Job.
Vi sono diversi possibili Step organizzati per tipologia:
Utility, General, Mail, File management, Conditions,
Scripting, Bulk loading, XML, Repository, File tranfer,
...
Gli Hop che collegano i vari Step di un Job rapprentano il flusso di controllo e definiscono
la successione degli step da eseguire.
Con Spoon si disegnano graficamente le Trasformazioni ed i Job.
Gli altri tool, come il Kitchen, servono invece ad eseguire i job realizzati con Spoon.
Spoon
Con Spoon si disegnano con una UI grafica le Trasformazioni ed i Job.
L'interfaccia grafica di Spoon presenta tutti i dettagli di quanto si sta programmando.
Per eseguire Spoon? Basta lanciare spoon.sh
[NdA oppure con un doppio click sull'icona del programma su PC].
Trasformazioni
 Le trasformazioni sono composte da vari Step connessi tra loro da collegamenti chiamati Hop.
Una tipica trasformazione inizia con uno Step di Input, uno o piu' Step di trasformazione ed uno
Step di Output. Ogni Hop trasmette attraverso una serie di campi (Field) le informazioni allo
Step successivo.
Tutta la programmazione avviene in modo grafico e guidato:
le connessioni ai database sono create con semplici wizard,
le tabelle vengono esplorate facilmente in automatico,
i campi sono selezionati con un click, ...
i collegamenti tra un passo e quello sucessivo possono essere definiti in automatico o
selezionati campo per campo, ...
Le trasformazioni sono composte da vari Step connessi tra loro da collegamenti chiamati Hop.
Una tipica trasformazione inizia con uno Step di Input, uno o piu' Step di trasformazione ed uno
Step di Output. Ogni Hop trasmette attraverso una serie di campi (Field) le informazioni allo
Step successivo.
Tutta la programmazione avviene in modo grafico e guidato:
le connessioni ai database sono create con semplici wizard,
le tabelle vengono esplorate facilmente in automatico,
i campi sono selezionati con un click, ...
i collegamenti tra un passo e quello sucessivo possono essere definiti in automatico o
selezionati campo per campo, ...
Vi sono diversi possibili step di trasformazione organizzati per tipologia:
Input, Output, Transform, Utility,
Flow, Scripting, Lookup, Joins, Data Warehouse, Validation, Statistics, Job,
Mapping, Inline, Experimental, Bulk loading,
...
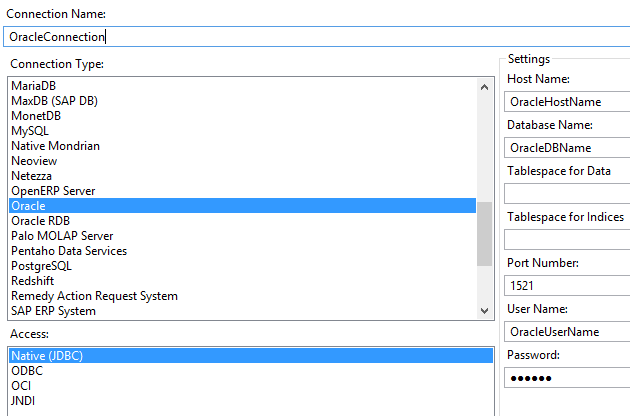 Gli step di Input ed Output sono particolarmente potenti.
E' possibile accere a database via JDBC, ODBC, OCI e JNDI... Con il JDBC sono disponibili
wizard guidati per la definizione della connessione ad una cinquantina di tipi di database differenti,
praticamente tutti:
AS/400, Hadoop Hive, DB2, Ingres, MS Access, MS SQL Server,
MySQL,
Oracle,
PostgreSQL,
SAP ERP,
SQLite,
Sybase, Teradata, dBase III, ...
Gli step di Input ed Output sono particolarmente potenti.
E' possibile accere a database via JDBC, ODBC, OCI e JNDI... Con il JDBC sono disponibili
wizard guidati per la definizione della connessione ad una cinquantina di tipi di database differenti,
praticamente tutti:
AS/400, Hadoop Hive, DB2, Ingres, MS Access, MS SQL Server,
MySQL,
Oracle,
PostgreSQL,
SAP ERP,
SQLite,
Sybase, Teradata, dBase III, ...
In uno Step di Table Input, per default, vengono raccolti tutti i campi dalla tabella di partenza.
E' possibile farli indicare sigolarmente e, sopratutto
e' possibile agire sull'SQL generato di default
introducendo eventuali join e/o tutte le clausole necessarie.
In uno Step di Table Output viene eseguito un mapping automatico
sui dati in arrivo ma anche in questo caso e' possibile personalizzarlo.
In uno Step di Table Output per default viene utilizzato il Batch Mode, che e' piu' veloce,
ma e' possibile utilizzare la modalita' Single Row che consente di gestire
ogni riga (eg. per estrarre eventuali valori errati).
Altrettanto potente e' la possibilita' di combinare le informazioni, eventualmente
provenienti da sorgenti differenti, con operazioni di sort, join, split, ...
disegnandone il flusso con una sequenza di Hop.
Gli Hop nelle trasformazioni indicano il flusso dei dati, non la sequenza di
esecuzione: in generale gli step vengono eseguiti come thread in parallelo.
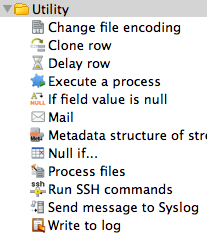
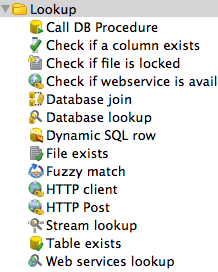
Ecco i principali tipi di Step di trasformazione che dimostrano la grande quantita' di funzioni disponibili in Kettle:



Una delle piu' tipiche trasformazioni richiede il collegamento (Join) tra tabelle/sorgenti dati differenti.
Con Kettle e' possibile realizzarlo in molti modi differenti.
Se le tabelle sono sullo stesso database e' assolutamente opportuno utilizzare un join SQL
modificando il testo della query dello Step di "Table Input":
questo e' il modo che fornisce le migliori prestazioni ed evita pesanti trasferimenti di dati.
Se le sorgenti di dati sono differenti (eg. un lookup su file di testo) si puo' utilizzare un "Database Join";
in questo caso viene effettuata una ricerca per ogni riga proveniente dal flusso principale. Questo metodo e'
adatto solo se la tabella di lookup e' di modeste dimensioni e la ricerca avviene in memoria.
Un'altra possibilita' e' quella di utilizzare il "Merge Join".
In questo caso le due sorgenti di dati debbono essere ordinate sulla chiave di join;
generalmente il modo piu' efficiente e' sfruttare la clausola ORDER BY dell'SQL
nello Step di "Table Input".
 Vi sono oltre cento tipi diversi di Step di trasformazione...
generalmente sono piu' che sufficienti,
ma nel caso in cui sia necessaria la piu' completa liberta'
di programmazione e' possibile utilizzare il linguaggio Java Script
(Tipologia: Scripting Step: Modified Java Script Value).
Con questo e' possibile definire nuovi field ed assegnare loro un valore con un qualsiasi algoritmo:
Vi sono oltre cento tipi diversi di Step di trasformazione...
generalmente sono piu' che sufficienti,
ma nel caso in cui sia necessaria la piu' completa liberta'
di programmazione e' possibile utilizzare il linguaggio Java Script
(Tipologia: Scripting Step: Modified Java Script Value).
Con questo e' possibile definire nuovi field ed assegnare loro un valore con un qualsiasi algoritmo:
//Dimmelo (Java Script)
var msg='';
var i=0;
for (i=0; i<3; i++) msg=msg+Field1+'\n';
Altrettanto potente e' la magia nera delle
regular expressions. Si riesce a fare quasi tutto... certo non sono sempre banali!
Ulteriore possibilita' e' quella di definire Step aggiungendo nuovi Plug-in.
Altre utili indicazioni nel disegno degli step di trasformazione sono disponibili nella
FAQ, sul
Wiki di Kettle
o, come sempre, navigando con Google (con cui ho trovato questo
bell'esempio):
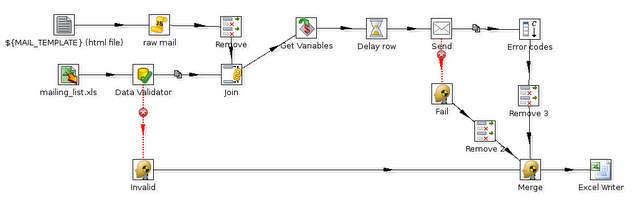
L'esempio mostra il join di piu' flussi, l'error handling, ...
ma per una gestione piu' complessa servono i job: continuate a leggere!
Job
Anche i Job vengono definiti in modo grafico con Spoon.
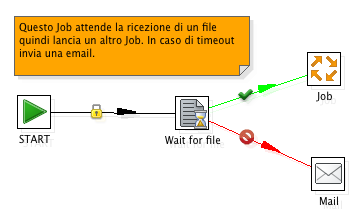
I Job servono a coordinare tra loro differenti trasformazioni ed attivita' sui sistemi ospite
(eg. ricezione file, script SQL).
Nei Job gli Hop indicano la sequenza di
esecuzione e vengono eseguiti in sequenza.
Il flusso seguito non e' quindi di dati ma quello della corretta (o meno) esecuzione dei passi.
Un tipico Job inizia con uno Step di Start e quindi una sequenza di Step per lanciare
script, Trasformazioni ed altri Job con un ordine preciso.
Vi sono diversi possibili Step organizzati per tipologia:
Utility, General, Mail, File management, Conditions,
Scripting, Bulk loading, XML, Repository, File tranfer,
...
che vengono connessi da Hop a seconda del successo o meno di ogni singolo passo.
Un esempio?
In questo caso un loop (cosa che tipicamente non si fa...):
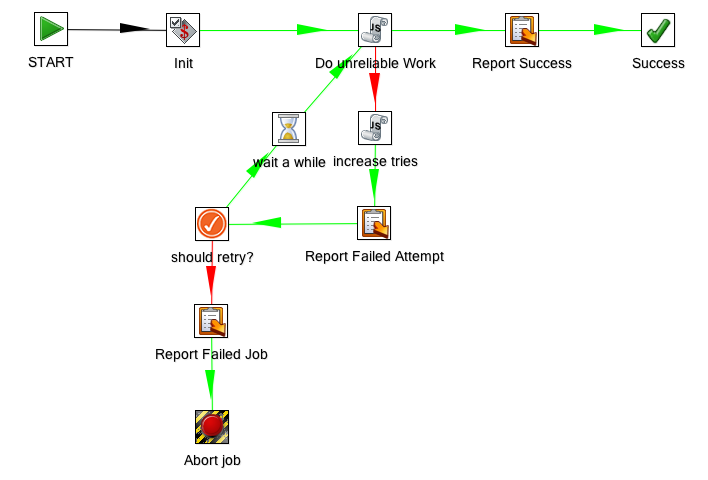
Le azioni piu' tipiche di un Job sono il lancio di trasformazioni e di altri Job
nella sequenza desiderata: caricamento dei dati su area di stage, denormalizzazione dati, ...
Anche per i Job gli Step disponibili sono parecchi;
ecco i principali tipi di Step che dimostrano la grande quantita' di funzioni disponibili in Kettle
[NdA aggiornati alla versione 8.3: in ogni versione vi sono aggiunte ed esclusioni]:

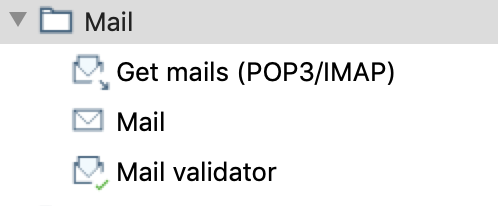
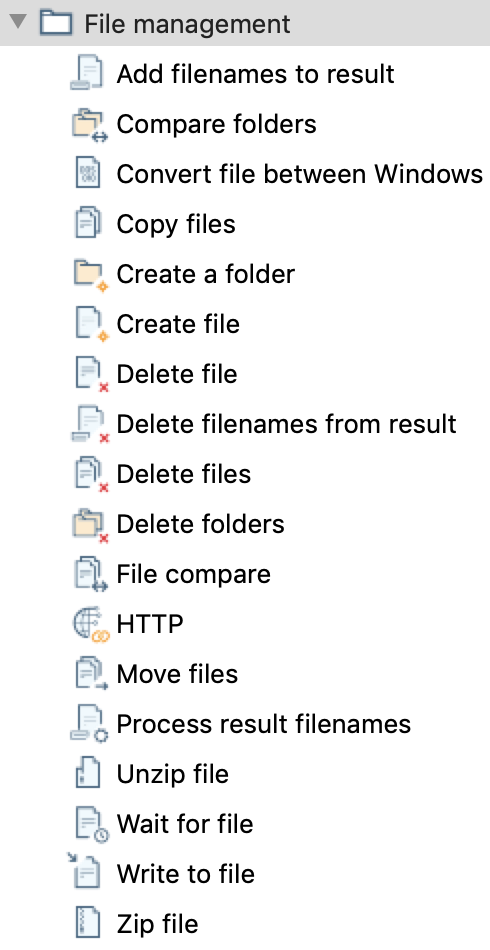
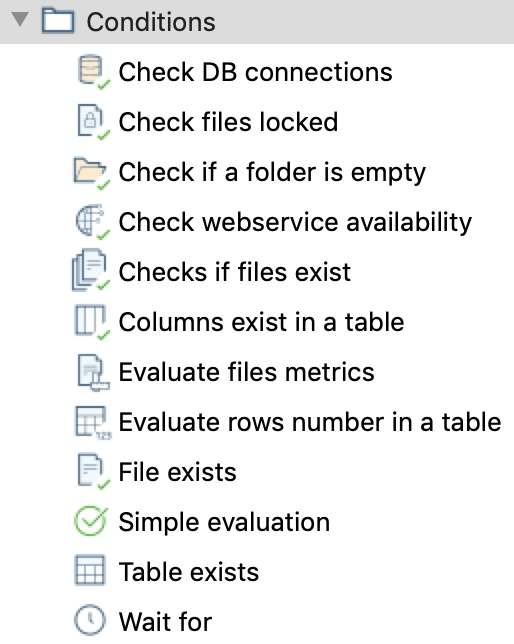
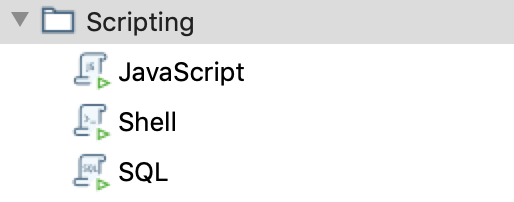
Tipicamente i JOB vengono disegnati con Spoon ma
un Job puo' anche essere creato in automatico con un wizard!
Wizard
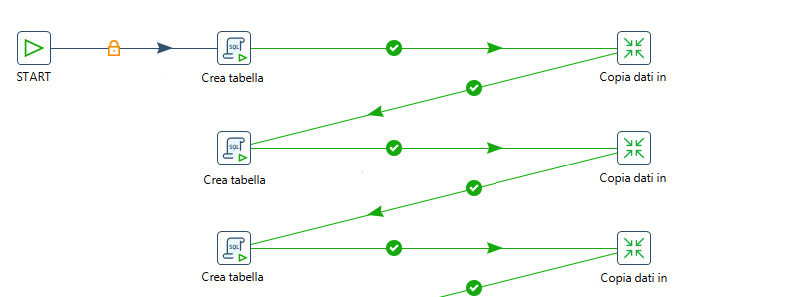
Spoon fornisce alcuni utili Wizard richiamabili dal menu Tool (eg. Tools -> Wizard -> Copy Tables)...
basta definire le connessioni al DB di partenza e di arrivo e con qualche click si effettua il
ribaltamento di un'intera base dati: dalla creazione delle tabelle alle singole trasformazioni per
ciascuna tabella.
Il tipo di database tra step di Input e di Output
puo' essere differente (eg. Oracle, MySQL, PostgreSQL, DB2, ...): in questo modo e' possibile
effettuare una migrazione strutture/dati completa.
Una volta creati tutti gli oggetti (tipicamente un job che richiama piu' trasformazioni in sequenza)
e' possibile modificarli singolarmente
adattandoli ad eventuali esigenze specifiche.
Repository
Le trasformazioni ed i Job disegnati con Spoon vengono salvati su un Repository.
Il repository puo' essere su DB o su una directory.
Quando il repository e' su una directory
questa contiene semplicemente le trasformazioni come singoli file XML con il suffisso .ktr
ed i Job con il suffisso .kjb.
E' definito un utente admin senza password.
Quando il repository e' su una base dati relazionale questo e' composto da una quarantina di tabelle
di facile interpretazione (eg. r_transformation contiene tutte le trasformazioni).
Sono presenti due utenti di default: admin/admin e guest/guest.
Il grande vantaggio dell'utilizzo di una base dati come repository e' che
tutte le trasformazioni ed i job possono essere condivisi da piu' persone.
L'aggiornamento degli oggetti non richiede alcun deploy poiche' tutti
gli oggetti vengono scaricati ogni volta dal repository e sono sempre aggiornati.
Il file in cui vengono riportati i repository dell'utente e'
$HOME/.kettle/repositories.xml.
Da Spoon e' possibile lanciare le trasformazioni o i Job ed effettuarne il debug,
pero' in ambiente di produzione tipicamente l'esecuzione avviene su server appositi e
con una precisa schedulazione.
Pan e Kitchen
Le Trasformazioni realizzate con Spoon vengono lanciate con Pan.
Ecco come lanciare una trasformazione, anche molto complessa, da linea di comando:
/usr/local/pdi/pan.sh -file /home/pentaho/repos/LetturaDati.ktr
Semplicissimo! E' ovviamente possibile preprare script piu' complessi, inserirli a crontab,
verificarne il codice d'errore, ...
Come gia' riportato e' anche possibile richiamare oggetti mantenuti sul repository;
in questo caso e' ovviamente necessario indicare gli estremi di connessione al repository.
L'output viene tipicamente ridiretto su un log ed analizzato in caso di problemi:
INFO 07-06 06:10:02,486 - Using "/tmp/vfs_cache" as temporary files store.
INFO 07-06 06:10:02,712 - Pan - Start of run.
INFO 07-06 06:10:02,902 - Lettura dati per DWH - Dispatching started for transformation [Lettura dati per DWH]
INFO 07-06 06:10:02,929 - Lettura dati per DWH - This transformation can be replayed with replay date: 2011/06/07 06:10:02
INFO 07-06 06:10:03,233 - DB DWH - Connected to database [Self DB] (commit=100)
INFO 07-06 06:10:03,599 - DB AS_UTIL - Finished reading query, closing connection.
INFO 07-06 06:10:03,614 - DB AS_UTIL - Finished processing (I=27, O=0, R=0, W=27, U=0, E=0)
INFO 07-06 06:10:03,625 - DB DWH - Finished processing (I=0, O=27, R=27, W=27, U=0, E=0)
INFO 07-06 06:10:03,626 - Pan - Finished!
INFO 07-06 06:10:03,627 - Pan - Start=2011/06/07 06:10:02.713, Stop=2011/06/07 06:10:03.126
INFO 07-06 06:10:03,627 - Pan - Processing ended after 0 seconds.
INFO 07-06 06:10:03,627 - Lettura dati per DWH -
INFO 07-06 06:10:03,627 - Lettura dati per DWH - Step DB AS_UTIL.0 ended successfully, processed 27 lines. ( - lines/s)
INFO 07-06 06:10:03,628 - Lettura dati per DWH - Step DB DWH.0 ended successfully, processed 27 lines. ( - lines/s)
Oltre a Pan, che serve per le trasformazioni, per la schedulazione dei Job viene utilizzato Kitchen.
Kitchen utilizza una sintassi e parametri
praticamente identici quelli di Pan, naturalmente il nome passato come parametro deve essere quello
di un Job.
Inserire a crontab una trasformazione lanciata con pan o un job eseguito con kitchen e' banale:
# Lancia il job ogni sabato alle sei di mattina...
6 6 * * 6 /usr/local/pdi/kitchen.sh -file /home/pentaho/repo/Aggiorna1.kjb >> /tmp/cron1.log 2>&1
Nel tempo l'esecuzione di kitchen e' divenuta sempre piu' lenta a causa di diversi
componenti aggiuntivi... e' possibile escludere quelli non necessari per renderne
piu' veloce l'avvio [NdA esempio aggiornato per Pentaho Kettle 8.2]:
==================================================================================
Patch1 (WARNING: no libwebkitgtk-1.0 detected, some features will be unavailable)
==================================================================================
Modificare spoon.bat come segue (aggiungere le righe ***)
*** if [ -z "$IS_KITCHEN" ]; then
HASWEBKITGTK=`ldconfig -p | grep webkitgtk-1.0`
export LIBWEBKITGTK="$HASWEBKITGTK"
export JavaScriptCoreUseJIT=0
if [ -z "$HASWEBKITGTK" ] && [ "1" != "$SKIP_WEBKITGTK_CHECK" ]; then
echo "#######################################################################"
echo "WARNING: no libwebkitgtk-1.0 detected, some features will be unavailable"
echo " Consider installing the package with apt-get or yum."
echo " e.g. 'sudo apt-get install libwebkitgtk-1.0-0'"
echo "#######################################################################"
fi
*** fi
==================================================================================
Patch 2 (eliminare karaf e tutti i componenti non necessari)
==================================================================================
Creare una cartella di backup ../data-integration-8.2-bak e spostare i seguenti file/directories
data-integration-8.2-bak
=== classes
=== kettle-lifecycle-listeners.xml
=== kettle-registry-extensions.xml
=== log4j.xml
=== lib
=== mondrian-*.jar
=== org.apache.karaf.*.jar
=== pdi-engine-api-*.jar
=== pdi-engine-spark-*.jar (non presente)
=== pdi-osgi-bridge-core-*.jar
=== pdi-spark-driver-*.jar (non presente)
=== pentaho-connections-*.jar
=== pentaho-cwm-*.jar
=== pentaho-hadoop-shims-api-*.jar
=== pentaho-osgi-utils-api-*.jar
=== plugins
=== kettle5-log4j-plugin
=== pdi-xml-plugin
=== pentaho-big-data-plugin
=== system
=== karaf
=== mondrian
=== osgi
Thanks to Alessandro Governa
Aggiornamento per la versione 8.3 [NdA provato su Mac]:
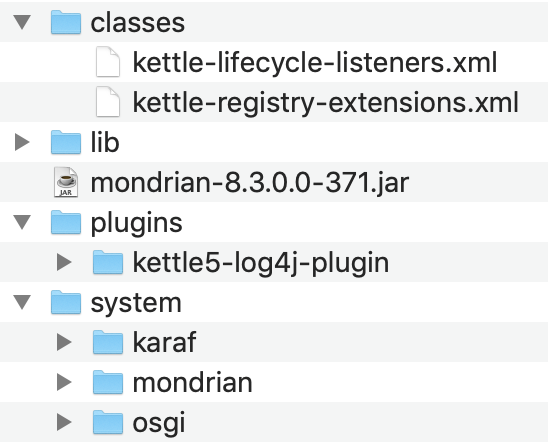 Naturalmente i plugin possono cambiare a seconda delle esigenze...
Naturalmente i plugin possono cambiare a seconda delle esigenze...
Carte
Per l'esecuzione remota dei Job viene utilizzato Carte.
Carte e' un servizio web e viene attivato con
nohup carte.sh servename port
Carte e' ospitato da un semplice servlet container (yetty).
L'utente e la password di default sono "cluster" ed e' possibile
richiamare le diverse funzionalita' partendo da
http://server:port/kettle/status/
Ecco la pagina iniziale:
Status
| Transformation name | Carte Object ID | Status | Last log date | Remove from list |
| Test1 | 4003dd05-8f63-45b2-bfab-bfb30ebdc793 | Waiting | - | Remove |
| Test3 | 4003dd05-8f63-45b2-bfab-bfb30ebdc793 | Stopped | - | Remove |
| Job name | Carte Object ID | Status | Last log date | Remove from list |
| Test2 | 4021de14-bfab-45b2-bfab-bf45b2bdc841 | Waiting | - | Remove |
Configuration details:
| Parameter | Value |
| The maximum size of the central log buffer | 0 lines (No limit) |
| The maximum age of a log line | 0 minutes (No limit) |
| The maximum age of a stale object | 0 minutes (No limit) |
These parameters can be set in the slave server configuration XML file: (Using defaults)
Sizing
Per utilizzare Spoon e' consigliabile un buon desktop con sufficiente memoria
Le prestazioni di Spoon non sono
di solito un problema poiche' e' utilizzato per programmare ed effettuare test,
non per effettuare attivita' massive.
Per rendere efficienti le trasformazioni lanciate con Pan e' invece necessario un server adeguatamente
dimensionato. Ogni step utilizza connessioni differenti ed i Job possono generalmente essere eseguiti
in parallelo. E' molto importante anche la collocazione in rete dell'ETL: e' necessario evitare
inutili passaggi tra reti differenti e Firewall. Una scelta possibile sono i DB Server di partenza
o di arrivo, ma spesso si preferisce centralizzare tutti gli ETL su un unico server, posto nella stessa rete,
per avere un maggior controllo e flessibilita'.
 Il dimensionamento dello storage e' un elemento molto importante.
Anche per il lemma di Meo (della legge di Hofstadter):
In un Data Warehouse ci vuole sempre piu' spazio di quanto previsto,
anche se dimensionato tenendo conto del lemma di Meo!
Il dimensionamento dello storage e' un elemento molto importante.
Anche per il lemma di Meo (della legge di Hofstadter):
In un Data Warehouse ci vuole sempre piu' spazio di quanto previsto,
anche se dimensionato tenendo conto del lemma di Meo!
Scherzi a parte si tratta di un aspetto importante e da non sottovalutare...
Performance
Quando il gioco si fa duro... i duri cominciano a giocare!
Per ottenere il massimo delle prestazioni:
si sfrutta al massimo il parallelismo,
si utilizza la modalita' batch (use_batch=Y, ignore_errors=Y) e
si configura con attenzione il numero di record per commit,
si lavora per delta,
si dimensionano adeguatamente i server e le connessioni di rete,
si schedulano con attenzione i job load e le finestre temporali,
si effettua solo il minimo necessario richiesto,
si utilizzano i Bulk load (disponibili verso diversi tipi di DB),
si effettua un tuning specifico delle basi dati (eg. nologging, drop idx, partitioning, noconstraint),
si spezzano le fasi di ETL ed, eventualmente, si utilizzano tool specifici per alcune di esse (eg. SQL*Loader),
si valuta l'utilizzo della versione Enterprise,
...
Il fatto che i tool di Kettle siano applicazioni Java non e' un problema:
si trova sempre il modo di rendere efficiente la parte che si trova sul percorso critico
e di gestirla come Job Kettle.
Gli step delle trasformazioni vengono eseguiti in parallelo, percio' i tempi di inizio e fine
dello step non sono indicativi: uno step puo' essere durato a lungo perche' non riceveva l'input dallo
step precedente. E' invece importante controllare l'attivita' eseguita dai singoli step.
Il massimo del dettaglio si ottiene abilitando il monitoraggio:
e' ben descritto in questa pagina...
Tips and Tricks
Una volta compresa la logica di base Spool e gli altri tool di Kettle sono semplici
da utilizzare. Tuttavia qualche breve consiglio puo' essere utile...
-
Se si modificano le strutture dati delle tabelle durante la sessione di Spoon
si possono avere degli errori. Questi sono dovuti al fatto che Spoon utilizza una
cache per non rileggere ogni volta dal database... basta ripulire la cache
dal menu principale: Tools->Database->Clear Cache.
-
I wizard di Spoon per la copia di tabelle operano bene con gli utenti
proprietari degli oggetti.
E' pero' facilmente possibile generare Job e Trasformazioni
con il wizard utilizzando l'utente proprietario
e poi modificare le connessioni successivamente...
Anche eventuali errori di conversione delle strutture
(eg. dovuti a differenti lunghezze degli identificatori ammesse dai diversi DB)
possono essere facilmente risolte a posteriori.
Conviene lasciar fare tutto il lavoro al wizard per correggere dopo
eventuali inesattezze nelle trasformazioni (eg. aggiungendo gli apici dove servono).
-
Se si realizzano trasformazioni che debbono operare in piu' ambienti
(eg. dev, test, prod) e' opportuno utilizzare una variabile per indicare
la connessione come descritto nella
FAQ ufficiale.
-
Tra gli Step di INPUT oltre Table Input, utilizzabile con tutti i database
che forniscono un driver JDBC,
sono sempre piu' utilizzati
interfacce REST e Web Services.
Qualche ulteriore indicazione e' fornita in
questo documento.
-
I wizard di Kettle creano Job e Trasformazioni con nomi molto chiari
ma che contengono blank. Per lanciare comandi su tali file e' necessario
racchiudere il nome tra apici (eg "Copia [TSTDB01].[MYTAB] in ...").
Questo apparentemente rende difficile la realizzazione di script che li gestiscano.
In realta' su Unix il problema e' facilmente aggirabile utilizzando
la variabile d'ambiente IFS che definisce i caratteri di separazione.
Ecco un esempio:
# Questo script lancia tutti i Job contenuti in una directory di scheduling
# Puo' essere lanciato in modo semplice da crontab
SAVEIFS=$IFS
IFS=$(echo -en "\n\b")
for I in `ls /usr/local/pdi/myhome/schedul/*.kjb`
do
date
echo Scheduling $I
/usr/local/pdi/kitchen.sh -file $I >> /usr/local/pdi/myhome/log/sched.log
done
IFS=$SAVEIFS
date
echo Finished Scheduling Kettle Jobs
-
Anche se il modo migliore e' quello di agire sull'interfaccia grafica di Spoon
ed utilizzare variabili... possono capitare casi in cui e' necessaria una modifica
massiva degli script.
In questo caso puo' essere utile il sed:
sed -i -e 's/tstdb.mydomain.it/prod.acme.com/' *.ktr
Naturalmente il comando puo' essere modificato per cambiare il nome dell'utente, dell'istanza Oracle, della porta di connessione...
-
Un'altro esempio di script sed e' la modifica di un Job per indicare
che le trasformazioni richiamate non vanno raccolte da Repository (che e' il default)
ma dal file system. Ecco un'estratto del file .kjb di partenza:
<entry>
<name>Copy data to [jms_transactions]</name>
<description>This job entry executes the transformation to copy data
from: [Pg DB tst].[jms_messages]
to: [Ora DWH].[jms_messages]</description>
<type>TRANS</type>
<specification_method>rep_name</specification_method>
<trans_object_id/>
<filename/>
<transname>copy [Pg DB tst].[jms_messages] to [Ora DWH]</transname>
<directory>/</directory>
<arg_from_previous>N</arg_from_previous>
...
E come deve essere trasformato:
<entry>
<name>Copy data to [jms_messages]</name>
<description>This job entry executes the transformation to copy data
from: [Pg DB tst].[jms_messages]
to: [Ora DWH].[jms_messages]</description>
<type>TRANS</type>
<specification_method>filename</specification_method>
<trans_object_id/>
<filename>/usr/local/pdi/Repos/copy [Pg DB tst].[jms_messages] to [Ora DWH].ktr</filename>
<transname/>
<arg_from_previous>N</arg_from_previous>
...
In questo caso lo script e':
sed -i -e 's/<specification_method>rep_name/<specification_method>filename/;s/\(.*\)\(<transname>\)\(.*\)\(<\/transname\)\(.*\)/\1<filename>\/usr\/local\/pdi\/Repo\/\3.ktr<\/filename>/;s/<filename\/>/<transname\/>/' myjob.kjb
Facile? Beh ovviamente il modo "giusto" e' quello di utilizzare il repository ed agire da interfaccia, ma in qualche caso puo' servire!
Fino ad ora abbiamo visto solo qualche suggerimento. Volete conoscere un vero trucco?
Avete dimenticato una password usata con Kettle ed avete solo il formato crittografato?
Beh ecco come fare!
Problemi? Parliamone!
Spoon e' un'applicazione Java: funziona sempre su qualsiasi SO, ma se non funzionasse...
- Aggiornare il JRE/JDK all'ultima versione
- Aggiornare il PDI all'ultima versione
- Aggiornare i driver JDBC
- Lanciare SpoonDebug.sh (o SpoonDebug.bat)
- Abbassare i parametri di memoria (eg. PENTAHO_DI_JAVA_OPTIONS="-Xms1024m" "-Xmx2048m" "-XX:MaxPermSize=256m" vs -Xms512m -Xmx1024m )
[NdA oppure comprarsi un PC migliore]
- Per MS-Windows sostituire "start javaw" con "java" e mettere in pause
- A volte si presentano strani problemi negli upgrade di versione...
provate a rinominare le directory .kettle e .pentaho (Spoon ripartendo le ricrea con le impostazioni di default)
- Per Mac OS X:

- Abilitare l'uso di applicazione esterne (si fa in System Preferences -> Security & Privacy)
- Lanciare il comando sudo xattr -dr com.apple.quarantine /usr/local/pdi-ce-8.2.0.0-342/data-integration/Data\ Integration.app
[NdA o il path che avete utilizzato per installare Kettle].
- Lanciare l'applicazione Data Integration.app [NdA di solito configuro il Keep in Dock]
-
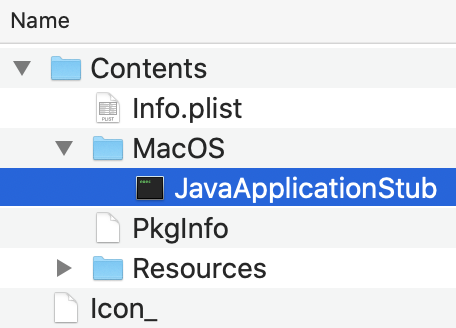 Ancora non parte? Su Data Integration.app eseguite Show Package Contents
e quindi lanciate JavaApplicationStub nella directory MacOS come nella figura a destra
[NdA in questo caso per lanciare facilmente l'applicazione utilizzo un alias sul desktop]
Ancora non parte? Su Data Integration.app eseguite Show Package Contents
e quindi lanciate JavaApplicationStub nella directory MacOS come nella figura a destra
[NdA in questo caso per lanciare facilmente l'applicazione utilizzo un alias sul desktop]
Se qualche trasformazione va in out of memory...
- Semplificare!
- Semplificare!
- Lavorare in single row anziche' in batch.
- Alzare i parametri di memoria (eg. PENTAHO_DI_JAVA_OPTIONS="-Xms1024m" "-Xmx2048m" "-XX:MaxPermSize=256m" raddoppiare!)
- Non fate fare a Java cio' che puo' fare meglio e piu' in fretta l'SQL sul DB
Se non funziona l'accesso ai DB...
- Occhio alle versioni dei driver, spesso vi sono bug o incompatibilita'
- aggiornare il JRE/JDK all'ultima versione
- Tutti i trucchi o le opzioni JDBC sono supportate: basta conoscerle e saperle utilizzare!
- Utilizzare /SID in caso di utilizzo di Oracle RAC o sulla versione 12c e successive
- Oracle non supporta il datatype Boolean, meglio disabilitare il flag nelle impostazioni avanzate
Novita': Big Data e NoSQL

La nuova versione community di Pentaho Kettle (4.3), disponibile dal 2Q 2012,
introduce come di consueto nuovi strumenti per la
trasformazione dei dati ed i job (eg. Bulk load per Postgres e per Elastic Search).
Ma la novita' principale e' nel supporto sempre piu' ampio di database Big Data e NoSQL:
oltre allo storico Hadoop (il cui supporto e' stato comunque aggiornato alle versioni piu'
recenti e semplificato) sono disponibili trasformazioni per Cassandra, HBase, MapReduce e MongoDB.
La diffusione dei database Big Data e' sempre maggiore ed e' importante poter disporre di uno
strumento per l'ETL.
Da questo punto di vista Kettle risulta uno degli strumenti migliori e piu' utilizzati,
anche per la liberta' della sua licenza ed al costante aggiornamento.
Infatti i componenti per i Big Data sono disponibili nella versione community dalla 4.3
e tutto Kettle e' passato da LGPL ad Apache (che e' molto meno restrittiva come licenza).
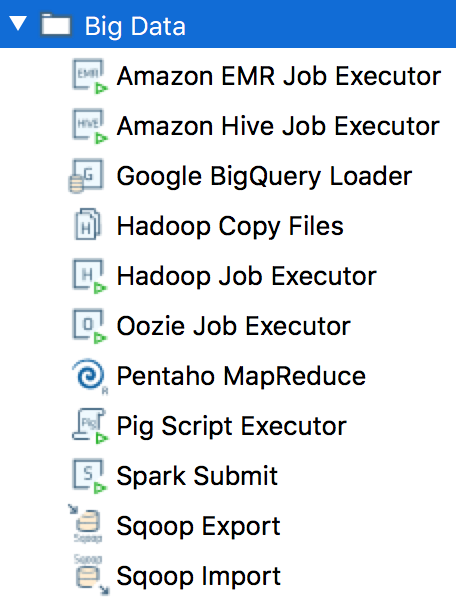
A destra sono riportate le immagini degli step Big Data
utilizzabili nei Job e nelle Trasformazioni di Kettle.
E' un elenco in costante aggiornamento:
rimanete sintonizzati!
L'integrazione e' in realta' ancora piu' ampia:
Kettle implementa anche alcuni tipici algoritmi con Step specifici (eg. Map-Reduce),
molti DB NoSQL forniscono interfacce JDBC (eg. Hive), ...
[NdE 2015-06 Kettle 5.4: si aggiunge il Job step "Spark Submit"]
[NdA 2018-04 Kettle 8.1: nuovi Step disponibili e rappresentati nelle figure]
Maggiori dettagli sull'apposita sezione del
sito ufficiale.
Varie ed eventuali
La Suite Pentaho nel suo insieme e' descritta
nel documento Pentaho.
Le versioni di Pentaho/Kettle sono riportate,
sempre aggiornate, su questo puzzolente documento.
La suite Pentaho e' ora [NdE 2017-09] mantenuta da Hitachi Vantara.