PostgreSQL e' considerato il piu' completo e robusto
Database Relazionale Open Source e non ha nulla da invidiare a sistemi commerciali.
I suoi principali punti di forza sono:
Questo documento e' stato preparato utilizzando la versione 15.1 di PostgreSQL su Linux ma e', mutatis mutandis, valido anche per le altre versioni. Lo scopo di questa pagina e' quella di introdurre le funzionalita' e caratteristiche di PostgreSQL.
Questo documento presenta diversi aspetti di PostgreSQL: Installazione, Configurazione, Utilizzo (SQL, Database/Schema), Amministrazione (Utenti, etc), Architettura, Configurazioni complesse, Storia PostgreSQL, ...
Documenti simili a questo sono Qualcosa in piu' su PostgreSQL (9.0) e Postgres DBA SQL scripts.
L'installazione di PostgreSQL e' disponibile su molteplici piattaforme ed e' molto semplice.
Basta seguire le indicazioni del
sito ufficiale
per la propria piattaforma:
Molte distribuzioni Linux hanno gia' i repository di PostgreSQL configurati ma i comandi riportati nel seguito possono essere utilizzati in tutte le condizioni.
Per RHEL / Rocky Linux / CentOS / SL / OL 7, 8, 9, Fedora 36 e successivi:
# Install the repository RPM: sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm # Disable the built-in PostgreSQL module: sudo dnf -qy module disable postgresql # Install PostgreSQL: sudo dnf install -y postgresql15-server # Initialize the database and enable automatic start: sudo /usr/pgsql-15/bin/postgresql-15-setup initdb sudo systemctl enable postgresql-15 sudo systemctl start postgresql-15
Per Debian / Ubuntu:
# Create the file repository configuration: sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list' # Import the repository signing key: wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add - # Update the package lists: sudo apt-get update # Install the latest version of PostgreSQL. If you want a specific version, use 'postgresql-15': sudo apt-get -y install postgresqlFatto!
Oltre a postgresql-server sono a volte disponibili come pacchetti aggiuntivi separati postgresql-client e postgresql-contrib. Se non sono gia' presenti e' consigliabile installare anche questi due pacchetti.
Una volta installato PostgreSQL puo' essere utilizzato immediatamente.
Pero' le impostazioni dei parametri di accesso e tuning sono molto limitate.
E' quindi opportuno effettuare una configurazione di base.
Quindi vediamo i file di configurazione!
Il file postgresql.conf
(il path dipende dalla distribuzione, ad esempio in /var/lib/pgsql/data)
e' il principale file di configurazione
e nel seguito sono riportati alcuni dei parametri piu' importanti:
listen_addresses = '*' # (change requires restart) port = 5432 # (change requires restart) max_connections = 100 # (change requires restart) shared_buffers = 128MB # (change requires restart) work_mem = 4MB # min 64kB hash_mem_multiplier = 2.0 # 1-1000.0 multiplier on hash table work_mem synchronous_commit = on # off, local, remote_write, remote_apply, or on max_wal_size = 1GB min_wal_size = 80MB
Il file pg_hba.conf contiene le abilitazione specifiche dei client agli utenti/database presenti:
# TYPE DATABASE USER ADDRESS METHOD # "local" is for Unix domain socket connections only local all all trust # IPv4 and IPv6 local connections: host all all 127.0.0.1/32 trust host all all ::1/128 trust # Allow replication connections from localhost local replication all trust host replication all 127.0.0.1/32 trust host replication all ::1/128 trust # NB the following line open the remote accesses from all IPs #host all all all scram-sha-256
Bene ora che sono configurati gli accessi da remoto (togliendo il commento all'ultima linea) si puo' accedere anche dall'esterno. Il comando per effettuare la rilettura dei file di configurazione senza riavviare la base dati e': pg_ctl reload
Per un utilizzo in produzione della base dati e' necessario eseguire un tuning iniziale della base dati perche' alcuni valori sono molto bassi. Maggiori dettagli sulla configurazione dei parametri di Postgres sono riportati nel documento PostgreSQL Tuning.
Per accedere con l'interprete dei comandi a PostgreSQL il comando e'
psql [db_name] da cui e' possibile utilizzare i
normali comandi SQL. Ogni comando va terminato con un ;
e per uscire dall'interprete utilizzare un ^D.
Per ottenere l'help sull'SQL: \h,
per ottenere l'help sul psql: \?,
per ottenere l'elenco delle tabelle: \dt,
la descrizione di una tabella: \d table_name, ...
Se sono differenti rispetto ai default per connettersi in locale
e' necessario impostare le
variabili d'ambiente PGPORT (5432) e PGDATA.
L'accesso da esterno avviene indicando l'host, la porta (default 5432), il database
ed ovviamente username/password.
 L'SQL di PostgreSQL e' molto completo ed aderente agli standard piu' recenti.
E' quindi molto semplice da utilizzare per chiunque conosca gia' l'SQL
di un qualsiasi altro database relazionale.
L'SQL di PostgreSQL e' molto completo ed aderente agli standard piu' recenti.
E' quindi molto semplice da utilizzare per chiunque conosca gia' l'SQL
di un qualsiasi altro database relazionale.
Naturalmente oltre all'interprete di comandi si utilizzano anche
client grafici come pgAdmin, DBeaver, ...
Postgres ha sempre avuto una forte attenzione agli standard SQL ed e' uno dei database piu' aggiornati da questo punto di vista.
Naturalmente sono presenti tutti gli statement DML SQL:
SELECT, INSERT, DELETE, UPDATE;
gli statement di DDL sono i classici CREATE, ALTER, DROP;
la gestione degli accessi si effettua ccon GRANT e REVOKE ...
Sono supportati molteplici datatype e conversioni
[NdA rispetto ad altri DB PostgreSQL e' piu' preciso ed a volte richiede un cast],
sono disponibili CTE, windows functions,
Persistent Stored Modules (SQL/PSM),
Management of External Data (SQL/MED), ...
Per default e' attivo l'autocommit e l'isolation level e' Read Committed.
PostgreSQL supporta molteplici datatype.
I principali datatype per stringhe PostgreSQL sono: VARCHAR(N), CHAR(N), TEXT.
Non vi sono differenze prestazionali tra questi datatype
e vengono gestite automaticamente stringhe fino ad 1GB grazie all'uso dei TOAST
(The Oversized-Attribute Storage Technique).
I principali datatype sulle date PostgreSQL sono: TIMESTAMP, DATE, TIME, INTERVAL.
Le colonne TIMESTAMP e TIME possono essere definite con oppure senza timezone.
I principali datatype numerici PostgreSQL sono:
SMALLINT (2 byte), INTEGER (4 byte), BIGINT (8 byte);
DECIMAL o NUMERIC (con la possibilita' di indicare precisione e scala);
REAL (4 byte), DOUBLE PRECISION (8 byte).
Un numero intero puo' essere autoincrementale se definito come SERIAL
[NdA con le versioni piu' recenti e' meglio utilizzare la sintassi standard: BIGINT GENERATED ALWAYS AS IDENTITY].
 Su un database cluster PostgreSQL vengono creati uno o piu' database;
il database postgres e' sempre presente. Ogni database ha un suo catalogo (data dictionary).
All'interno di ogni database vengono
creati uno o piu' schema; lo schema public viene creato per default.
All'interno degli schema vengono create le table. Per identificare una tabella
si utilizza la sintassi schema.table.
Su un database cluster PostgreSQL vengono creati uno o piu' database;
il database postgres e' sempre presente. Ogni database ha un suo catalogo (data dictionary).
All'interno di ogni database vengono
creati uno o piu' schema; lo schema public viene creato per default.
All'interno degli schema vengono create le table. Per identificare una tabella
si utilizza la sintassi schema.table.
Su un database cluster PostgreSQL vengono autorizzati piu' utenti e ruoli.
Un utente puo' lavorare sui
diversi database se e' autorizzato, ma deve scegliere su quale database operare
al momento della connessione.
Un utente ha il diritto di effettuare modifiche sugli oggetti da lui creati
perche' ne risulta owner.
E' possibile modificare il default per la ricerca e creazione degli oggetti con l'impostazione
del search_path.
La scelta su come isolare utenti ed applicazioni (su database differenti, su schema differenti, tutti assieme appassionatamente nello schema public) e' una scelta del DBA che dipende da molti fattori... PostgreSQL permette tutte le possibilita': dal completo isolamento alla condivisione totale.
 Con le versioni piu' recenti di PostgreSQL alcune delle attivita'
di gestione piu' significative sulla base dati sono effettuate automaticamente
(eg. vacuum, analyze).
Tra i piu' importanti compiti che restano al DBA:
Con le versioni piu' recenti di PostgreSQL alcune delle attivita'
di gestione piu' significative sulla base dati sono effettuate automaticamente
(eg. vacuum, analyze).
Tra i piu' importanti compiti che restano al DBA:
La maggioranze delle attivita' si possono svolgere con l'interfaccia Client/Server
di pgAdmin. Qualche volta e' necessario agire sui file di configurazione oppure
lanciare qualche comando in SQL...
Tra le funzioni SQL di amministrazione piu' utilizzate:
pg_cancel_backend(pid) pg_terminate_backend(pid)
pg_reload_conf()
...
Vi sono alcune utili tabelle che riportano le statistiche di sistema che possono essere interrogate con normali query SQL: pg_stat_XYZ e pg_statio_XYZ (eg. pg_stat_activity e pg_stat_database).
Su PostgreSQL gli utenti (o role) sono gestiti a livello di cluster e sono quindi creati per tutti i database ospitati nell'istanza. E' possibile definire piu' utenti "amministratori" e gestire le scadenze delle password. La creazione di un utente consente il login ma non concede alcun GRANT all'utente. Alle utenze per applicazioni verticali viene spesso assegnata la proprieta' di un intero database (e di conseguenza tutti i diritti). Ma per una gestione piu' corretta della sicurezza le utenze ed i ruoli vanno abilitati con il principio del "minimo privilegio". Distinti dagli utenti/ruoli sono gli SCHEMA che debbono essere creati a parte. I GRANT vanno definiti esplicitamente a livello di database, di schema e di singolo oggetto:
CREATE USER xyz WITH LOGIN; CREATE SCHEMA AUTHORIZATION abc;do ALTER USER xzy PASSWORD 'xyz'; GRANT CONNECT ON DATABASE mydb TO xyz; GRANT USAGE ON SCHEMA abc TO xyz; GRANT SELECT ON "MyTable" TO xyz;Ovviamente il GRANT per oggetto va ripetuto per ogni singolo oggetto... Puo' quindi essere comodo uno script come:
SELECT 'GRANT SELECT ON ' || relname || ' TO xyz;'
FROM pg_class JOIN pg_namespace ON pg_namespace.oid = pg_class.relnamespace
WHERE nspname = 'public'
AND relkind IN ('r', 'v')
Per semplificare e' possibile autorizzare tutte le tabelle presenti in uno schema:
GRANT SELECT ON ALL TABLES IN SCHEMA public TO xyz;Lo statement precedente opera per le tabelle gia' create... per il futuro:
ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES TO xyz;I superpoteri?
alter user xyz with superuser;Da ultimo, ma non meno importante, bisogna sempre ricordare il search_path per la sessione [o per l'utente]!
[alter user xyz] set search_path=xyz,public;
PostgreSQL e' un database Object-Relational molto completo e la descrizione
dei tutte le componenti utili per l'amministrazione richiede piu' spazio
di quanto disponibile in questo documento introduttivo.
Per approfondire altri aspetti e' possibile seguire questi link:
Backup/Restore,
VACUUM,
DBA SQL scripts,
Statistiche prestazionali,
Tuning database,
Ottimizzazione SQL,
Sicurezza,
...
In questo capitolo cerchiamo di riassumere gli aspetti dell'architettura di PostgreSQL.
La struttura dei processi presenta una serie di processi di background, tra cui il principale, in attesa delle connessioni utente, e gli eventuali processi utente:
postgres 17 0 0 21:48 ? 00:00:00 postgres postgres 25 17 0 21:48 ? 00:00:00 postgres: checkpointer postgres 26 17 0 21:48 ? 00:00:00 postgres: background writer postgres 28 17 0 21:48 ? 00:00:00 postgres: walwriter postgres 29 17 0 21:48 ? 00:00:00 postgres: autovacuum launcher postgres 30 17 0 21:48 ? 00:00:00 postgres: logical replication launcher postgres 1918 17 0 11:59 ? 00:00:00 postgres: postgres postgres 10.10.10.69(57796) idle postgres 1919 17 0 11:59 ? 00:00:00 postgres: postgres bench 10.10.10.69(57797) idle postgres 2263 17 12 12:32 ? 00:03:02 postgres: bench bench 10.10.10.69(58144) UPDATE postgres 2264 17 12 12:32 ? 00:02:59 postgres: bench bench 10.10.10.69(58148) UPDATE postgres 2266 17 12 12:32 ? 00:02:59 postgres: bench bench 10.10.10.69(58153) SELECT postgres 2270 17 12 12:32 ? 00:02:59 postgres: bench bench 10.10.10.69(58157) idle
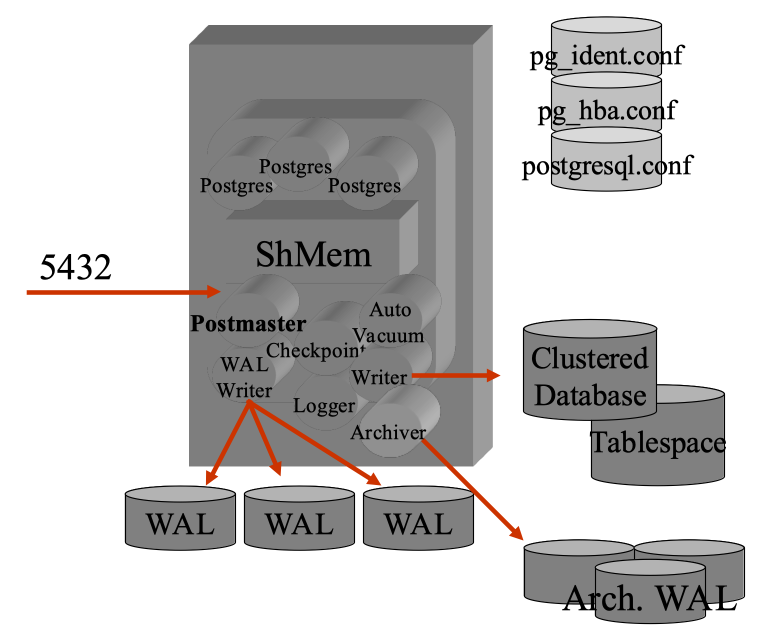 Nell'elenco di processi riportato sopra vi sono i processi di sistema
ed un processo per ogni connessione utente
[NdA raccolti durante l'esecuzione di un benchmark].
Il processo principale e' il
postmaster che si occupa della gestione delle
connessioni (e' in LISTEN sulla porta socket 5432)
ed e' il "padre" di tutti i processi, sia di sistema (eg. walwriter)
sia quelli relativi alle connessione utente.
Su ogni processo utente e' riportata l'origine e l'attivita' in corso...
molto comodo per il DBA e per il sistemista!
Tutti i processi girano come utente postgres ed eseguono un attach
al segmento di shared memory su cui vengono mantenuti buffer e lock.
Nell'elenco di processi riportato sopra vi sono i processi di sistema
ed un processo per ogni connessione utente
[NdA raccolti durante l'esecuzione di un benchmark].
Il processo principale e' il
postmaster che si occupa della gestione delle
connessioni (e' in LISTEN sulla porta socket 5432)
ed e' il "padre" di tutti i processi, sia di sistema (eg. walwriter)
sia quelli relativi alle connessione utente.
Su ogni processo utente e' riportata l'origine e l'attivita' in corso...
molto comodo per il DBA e per il sistemista!
Tutti i processi girano come utente postgres ed eseguono un attach
al segmento di shared memory su cui vengono mantenuti buffer e lock.
PostgreSQL utilizza un sofisticato ottimizzatore cost-based. Quando viene sottomesso uno statement SQL l'ottimizzatore determina il query tree da utilizzare con un algoritmo genetico basato sulle statistiche.
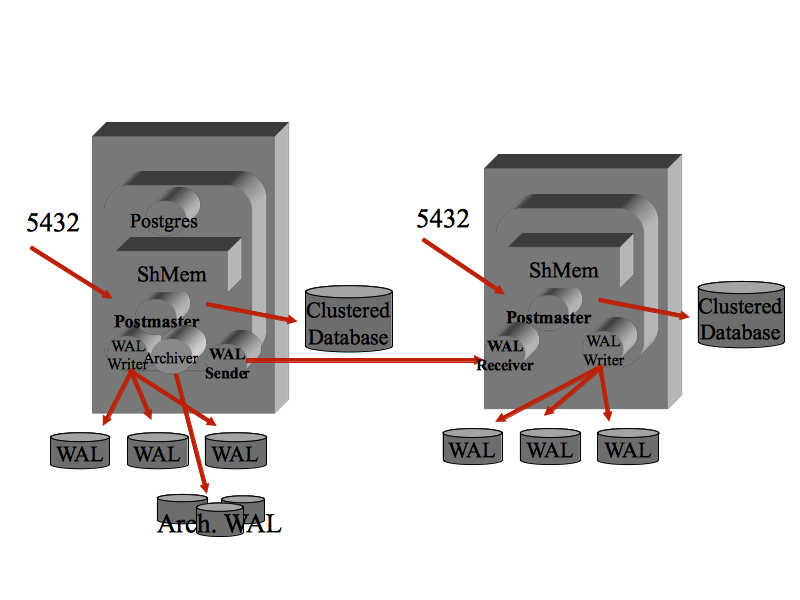
La gestione delle transazioni in PostgreSQL avviene con la tecnica del MVCC
(Multiversion Concurrency Control)
e la consistenza dei dati su disco e' assicurata con il logging
(Write-Ahead Logging).
Ogni transazione al commit effettua una scrittura
sul WAL (Write-Ahead Log): in questo modo e' certo che le attivita' confermate alla
transazione sono state scritte su disco.
La scrittura sul WAL e' sequenziale e molto veloce.
La scrittura effettiva sui
file delle tabelle e degli indici viene effettuata successivamente
ottimizzando le seek e le scritture sul disco
da parte di processi appositi (background writer, checkpointer).
 Sono disponibili decine di moduli aggiuntivi che arricchiscono le funzionalita'
di base di Postgres e che possono essere aggiunti con il semplice comando SQL
CREATE EXTENSION. Alcuni sono rivolti ad DBA (eg. pg_stat_statements),
altri per funzionalita' utili alle applicazioni (eg. pgcrypto),
altri per connettersi a database remoti (eg. postgres_fdw).
Sono disponibili decine di moduli aggiuntivi che arricchiscono le funzionalita'
di base di Postgres e che possono essere aggiunti con il semplice comando SQL
CREATE EXTENSION. Alcuni sono rivolti ad DBA (eg. pg_stat_statements),
altri per funzionalita' utili alle applicazioni (eg. pgcrypto),
altri per connettersi a database remoti (eg. postgres_fdw).
PostgreSQL puo' essere utilizzato in configurazioni complesse con diversi livelli e modalita' di replicazione, scalabilita', HA (High Availability, alta affidabilita'), DR (Disaster Recovery), Load Balancing, ... Alcune configurazioni richiedono hardware (eg. NAS) o software specifici (eg. fail over cluster: RHCS, VCS), altre utilizzano software di middleware aggiuntivi (eg. PgBouncer, Pgpool-II), ... ma fondamentalmente la base per tutte le piu' recenti configurazioni in alta affidabilita' e' la Streaming Replication.
La configurazione della replica e' simile ad un Point In Time Recovery. La principale differenza e' che il database di partenza non e' stato perduto ma e' ancora perfettamente attivo come Primary. Il server secondario o di Standby deve essere installato e configurato come il server primario (stesse versioni, directory, utenti, ...) e va allineato inizialmente con un restore di un backup fisico (pg_basebackup) del primario.
Dal punto di vista funzionale la replica PostgreSQL e' molto ricca: utilizza la tecnica della Streaming Replication, i nodi secondari possono essere utilizzati in lettura come Hot Standby, e' possibile utilizzare la cascading replication, e' possibile utilizzare la replica sincrona con un pool di standby, sono presenti parametri specifici di tuning della replica, e' disponibile la logical replication, ...
Maggiori dettagli sulla configurazione della replica sono riportati nel documento Replica in PostgreSQL.
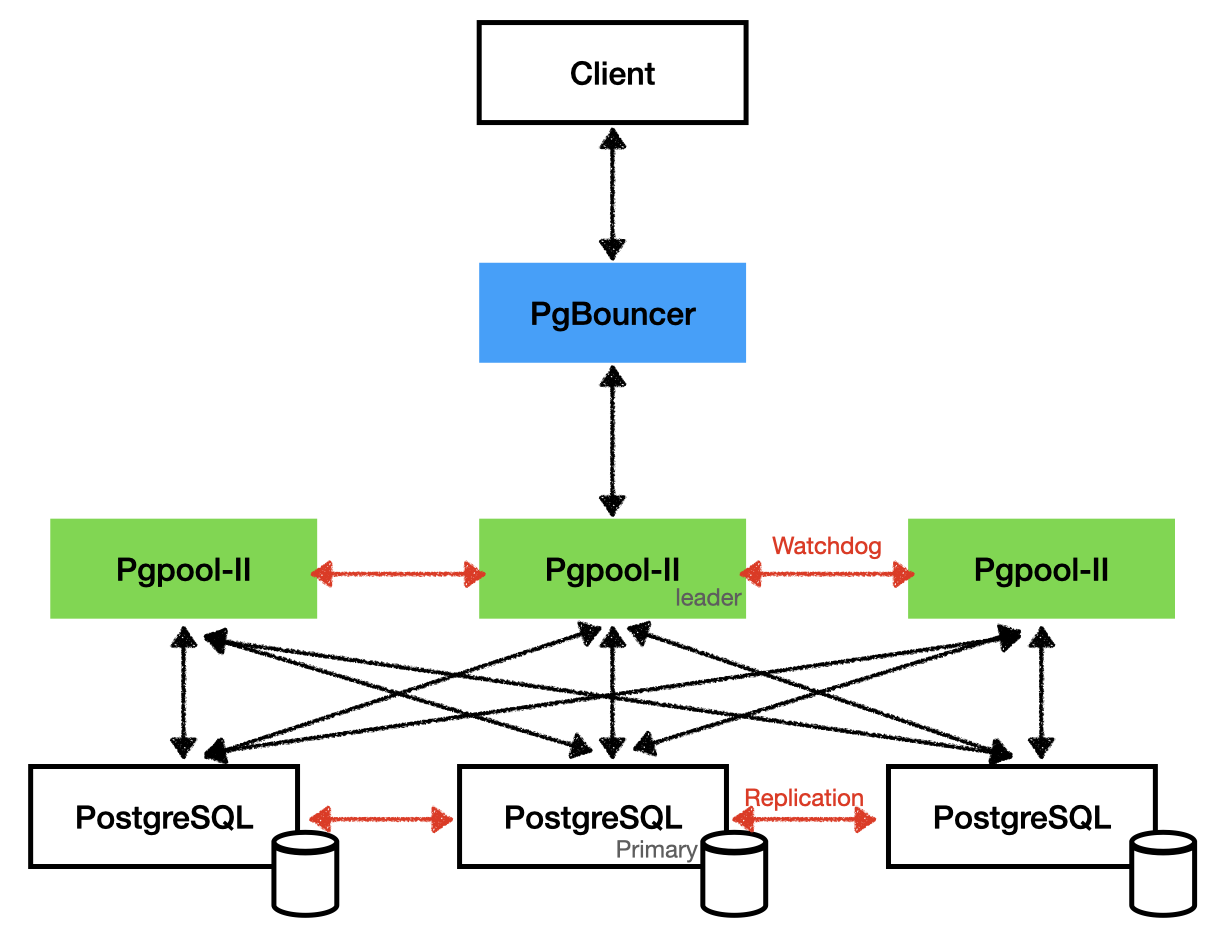
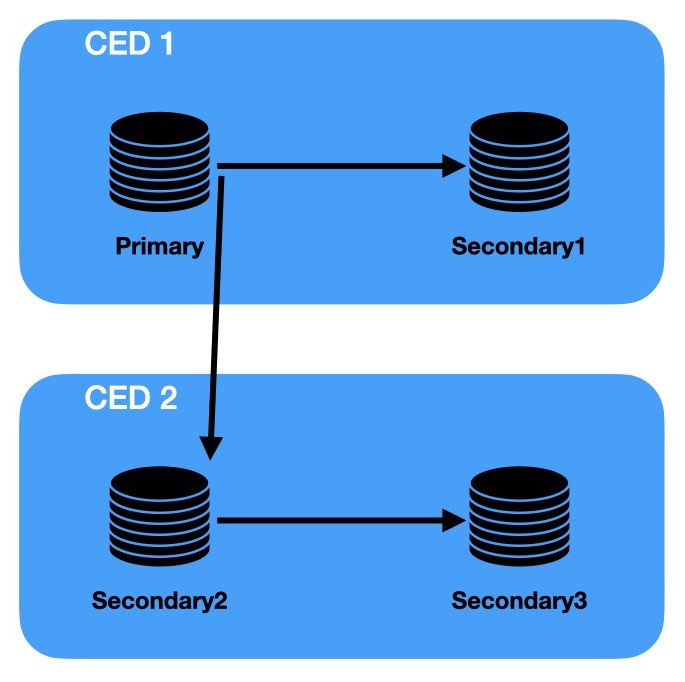
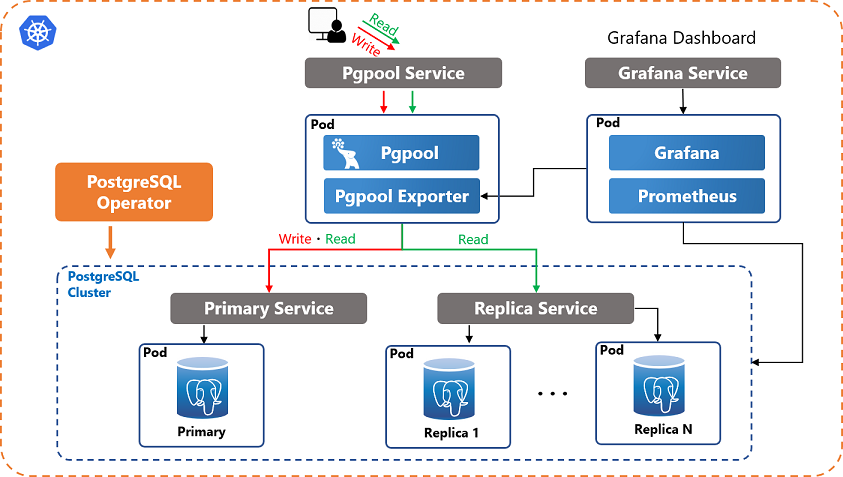
La versione piu' recente disponibile come versione di produzione e' la 17.0 [NdA 2024-09].
Le release di PostgreSQL si sono sempre distinte per la qualita'
e per la completezza di funzionalita' (eg object-oriented).
Da sempre Postgres e' considerato il database relazionale Open Source piu' completo
e piu' robusto. Ma vediamo un po' di storia...
Le radici di PostgreSQL risalgono al lontano 1977 quando, nella
famosa universita' di Berkeley, venne sviluppato l'RDBMS Ingres.
Nel 1986, sponsorizzato dal DARPA,
parte un nuovo progetto dal nome di The Berkeley POSTGRES Project.
Il nome stesso del progetto indica un'evoluzione rispetto ad Ingres:
Postgres infatti e' un database Obejct-Relational.
Nel 1994 viene realizzato l'interprete SQL che verra' poi rilasciato
come Open Source col nome definitivo di PostgreSQL.
Le prestazioni e, sopratutto, l'affidabilita' di PostgreSQL sono da subito paragonabili a quelle dei piu'
diffusi RDBMS commerciali del tempo.
Rispetto ad altri database Open Source (eg. MySQL) risulta molto piu' completo ma
anche piu' complesso.
La versione la 8.1 (2005-11) ha introdotto
il 2 Phase Commit, la definizione dei parametri
come IN/OUT/INOUT nelle funzioni SQL,
la gestione dei roles, il partizionamento delle tabelle
oltre a miglioramenti sull'ottimizzatore e sulle performance in generale.
Nella versione 8.2 sono stati introdotti:
multirow DML, index DDL during DML, SQL:2003 statistical functions,
faster locking, FILLFACTOR, monitor/logging.
La 8.3, molto stabile e diffusa, ha introdotto:
Full text search, XML, updatable cursors,
asynchronous commit, dedicated writes.
La 8.4 e' stata ottimizzata per migliorare le performances.
La versione 9.0 ha introdotto alcune importanti
funzionalita' per l'utilizzo Enterprise come la Streaming Replication
e l'Hot Stand-by. In precedenza funzionalita' simili
erano disponibili solo installando moduli esterni.
La 9.1 (2011-09) ha aggiunto estensioni sulla replicazione (Synchronous Replication)
e sull'SQL PL/pgSQL (CREATE TABLE IF NOT EXISTS, INSTEAD OF triggers on views, FOREACH).
La versione 9.2 (2012-09) prosegue nell'arricchimento delle funzionalita' sulla replicazione
(Cascading replication, backup sui server di standby con pg_basebackup), sulle ottimizzazioni
(index-only scan), con il datatype JSON e sulla gestibilita' (ulteriori informazioni sulla pg_stat_activity).
L'evoluzione continua:
(9.3) updatable views, writeable foreign tables;
(9.4) logical WAL decoding, pg_stat_archiver, JSONB;
(9.5) UPSERT, CUBE and ROLLUP;
(9.6) Synchronous replication on multiple standby servers, parallel sequential scan.
Con la versione 10 cambia la numerazione delle major release che sono
costituite solo piu' da un numero. La versione 10 introduce la logical replication,
il partizionamento nativo e l'autenticazione SCRAM-SHA-256.
Nella versione 11 sono introdotte le stored procedures, il controllo
transazionale nel PL/pgSQL ed il supporto completo delle window functions.
Con la versione 12 e' possibile eseguire i REINDEX CONCURRENTLY ed e' stata cambiata
la modalita' di configurazione della Straming Replication.
Con la versione 13 continuano le migliorie prestazionali e sono disponibili le
trusted extensions.
Nella versione 14 sono stati aggiunti gli OUT in Stored procedures, SEARCH e CYCLE options in CTE.
Con la versione 15 e' stato aggiunto il comando di MERGE
e sono presenti nuove funzionalita' per la replica logica...
Sono diverse le ottimizzazioni ed i miglioramenti prestazionali
con la versione 16
(eg. parallel execution with OUTER and FULL joins, logical replication in parallel, improved performance of vacuum freezing).
La versione 17
introduce il privilegio di MAINTAIN, aggiunge ulteriori funzioni per il trattamento dei JSON,
backup incrementale,
login trigger,
MAINTAIN privilege,
...
L'elenco delle versioni di PostgreSQL e delle relative funzionalita'
e' riportato in questa pagina web.
I sorgenti di PostgreSQL e gli eseguibili sono tutti liberamente
scaricabili dal sito PostgreSQL.
Molte distribuzioni unix/linux hanno gia' i pacchetti di Postgres configurati
anche se spesso le versioni non sono aggiornate quanto
il sito di download ufficiale
che e' la fonte consigliata.
PostgreSQL e' distribuito con la PostgreSQL License
che e' una licenza molto libera simile alle licenze BSD o MIT.
Anche grazie alla licenza aperta sono molti i database e gli ambienti che hanno chiare origini Postgres
o interfacce di accesso compatibili come:
EnterpriseDB,
Vertica,
Aurora PostgreSQL,
Netezza,
Greenplum,
Redshift,
YugabyteDB,
Everest,
HadoopDB,
CockroachDB,
Google Spanner,
AlloyDB,
...
Alcune extensioni di PostgreSQL sono particolarmente diffuse e vanno citate per la loro importanza,
anche perche' ne aumentano le funzionalita' in modo particolarmente significativo tanto da poter
quasi essere considerati un altro database:
PostGIS, TimescaleDB, pgvector, ...
Oltre che on-premises PostgreSQL e' disponibile in Cloud come servizio gestito:
![]() Amazon RDS,
Amazon RDS,
![]() Microsoft Azure Database,
Microsoft Azure Database,
![]() Google Cloud SQL,
EDB BigAnimal,
Alibaba Cloud (Aspara), Heroku;
come fork con separazione tra Compute e Storage: Amazon Aurora Pg, Google AlloyDB, Neon, PolarDB;
in sharding: CitusData, Azure CosmosDB;
come database distribuito compatibile: Google Spanner, CockroachDB, YugabyteDB, ...
per citare solo i piu' noti.
Google Cloud SQL,
EDB BigAnimal,
Alibaba Cloud (Aspara), Heroku;
come fork con separazione tra Compute e Storage: Amazon Aurora Pg, Google AlloyDB, Neon, PolarDB;
in sharding: CitusData, Azure CosmosDB;
come database distribuito compatibile: Google Spanner, CockroachDB, YugabyteDB, ...
per citare solo i piu' noti.
Titolo: Testo: Introduzione a PostgreSQL
Livello: Base
Data: 31 Ottobre 2022 🎃
Versione: 1.0.2 -
31 Ottobre 2024
Autore:
mail [AT] meo.bogliolo.name