Statistiche prestazionali in PostgreSQL
PostgreSQL
e' un potente DBMS relazionale Open Source noto per
la robustezza e la ricchezza di funzionalita'.
Questo documento descrive le principali statistiche prestazionali presenti in PostgreSQL
e gli strumenti di monitoraggio disponibili nella release base del database, come moduli aggiuntivi
e come oggetti esterni.
Il documento fa riferimento alla versione 9.2
di PostgreSQL su Linux ma e', mutatis mutandis, valido anche per le altre versioni
[NdA il documento Monitoraggio con PostgreSQL v.10
riporta le novita' delle versioni successive].
Dopo una breve introduzione sui principali elementi dell'archittettura di PostgreSQL,
vengono analizzati le principali statistiche prestazionali e strumenti di monitoraggio disponibili:
Architettura,
Monitoraggio
(Query SQL,
Tools,
Tracing/Logging,
Sistema Operativo),
pg_stat_statements,
Buffer Cache,
PostgreSQL Statspack,
...
Un documento introduttivo su PostgreSQL
e' Introduzione a PostgreSQL,
un documento piu' completo e' Qualcosa in piu' su PostgreSQL
mentre sul partizionamento
e' presente un capitolo relativo a PostgreSQL in DIVIDE ET IMPERA !
Architettura
La conoscenza dell'architettura di PostgreSQL e' fondamentale per le attivita' di monitoraggio
prestazionale.
La struttura dei processi di PostgreSQL presenta una serie di processi di background,
tra cui il principale (Postmaster) e gli eventuali processi utente
(Postgres Server).
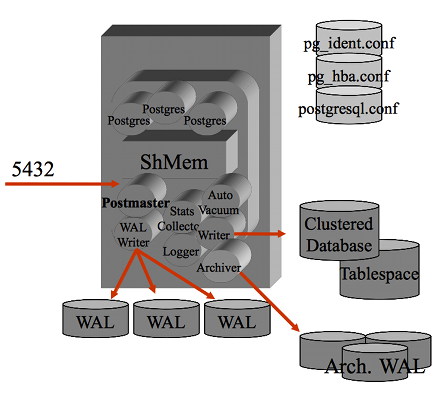 Il processo
postmaster e' il processo principale che si occupa della gestione delle
connessioni (e' in LISTEN sulla porta socket di default 5432)
ed e' il "padre" di tutti i processi, sia di sistema (eg. wal writer)
sia quelli relativi alle connessione utente.
Tutti i processi girano come utente postgres ed eseguono un attach
al segmento di shared memory su cui vengono mantenuti i buffer della cache ed i lock.
L'architettura dei processi di PostgreSQL si e' mantenuta costante,
col passare delle versioni si sono aggiunti via via nuovi processi di sistema
specializzati.
PostgreSQL utilizza i meccanismi di IPC standard su Unix. Vengono utilizzati alcuni semafori
ed un segmento shared memory.
Naturalmente la dimensione del segmento di shared memory dipende dai parametri
utilizzati nella configurazione (eg. shared_buffers).
Il processo
postmaster e' il processo principale che si occupa della gestione delle
connessioni (e' in LISTEN sulla porta socket di default 5432)
ed e' il "padre" di tutti i processi, sia di sistema (eg. wal writer)
sia quelli relativi alle connessione utente.
Tutti i processi girano come utente postgres ed eseguono un attach
al segmento di shared memory su cui vengono mantenuti i buffer della cache ed i lock.
L'architettura dei processi di PostgreSQL si e' mantenuta costante,
col passare delle versioni si sono aggiunti via via nuovi processi di sistema
specializzati.
PostgreSQL utilizza i meccanismi di IPC standard su Unix. Vengono utilizzati alcuni semafori
ed un segmento shared memory.
Naturalmente la dimensione del segmento di shared memory dipende dai parametri
utilizzati nella configurazione (eg. shared_buffers).
La gestione delle transazioni in PostgreSQL avviene con la tecnica del MVCC
(Multiversion Concurrency Control)
e la consistenza dei dati su disco e' assicurata con il logging
(Write-Ahead Logging).
L'isolation level di default e' Read Committed, e' implementato anche il
Serializable e sono teoricamente supportati
tutti gli isolation level previsti dallo standard (eg. Read Uncommitted, Repeteable Read che vengono
mappati sul livello superiore).
In pratica ogni transazione al commit effettua una scrittura
sul WAL: in questo modo e' certo che le attivita' confermate alla
transazione sono state scritte su disco.
La scrittura sul WAL e' sequenziale e molto veloce.
La scrittura effettiva sui
file delle tabelle e degli indici viene effettuata successivamente
ottimizzando le seek e le scritture sul disco.
Il Clustered Database e' la struttura del file system che contiene i dati.
All'interno vengono mantenuti i file di configurazione ($PGDATA/*.conf),
i log delle transazioni (nella directory $PGDATA/pg_xlog)
e le strutture interne della base dati che contengono
tabelle ed indici (suddivise per database nella directory $PGDATA/base).
Ad ogni oggetto (tabella, indice, ...) corrisponde ad un file
(indicato da pg_class.relfilenode), e sono tipicamente presenti file ulteriori
per la gestione degli spazi come la free space map (suffisso _fsm) e visibilty map
(suffisso _vm).
La pagina ha dimensione 8KB mentre i wal log hanno come dimensione
16MB.
Quando viene sottomesso uno statement SQL l'ottimizzatore determina
il query tree da utilizzare con un algoritmo genetico basato sulle
statistiche. PostgreSQL utilizza un ottimizzatore cost-based.
L'algoritmo genetico e' utilizzato per ridurre il numero delle combinazioni
dei possibili percorsi di ricerca.
PostgreSQL esegue in automatico le attivita' di analyze
(raccolta delle statistiche necessarie
all'ottimizzatore) e di vacuum (cancellazione dei blocchi non piu' necessari al MVCC).
La configurazione dei parametri di PostgreSQL viene effettuata nel file postgresql.conf,
mentre il file pg_hba.conf contiene le abilitazioni di connessione per gli utenti.
Maggiori dettagli sull'architettura di PosgreSQL sono riportati in questo documento.
Monitoraggio della base dati
Le versioni piu' recenti di PostgreSQL hanno liberato il DBA da alcune delle attivita'
di gestione piu' ripetitive sulla base dati che sono effettuate automaticamente
(eg. vacuum, analize).
Ma restano comunque tra i piu' importanti compiti del DBA le attivita' di controllo e monitoraggio
del sistema.
Le modalita' di controllo si possono effettuare con strumenti molto differenti tra loro:
SQL,
Tools (Pg Admin, phpPgAdmin),
Tracing/Logging,
Sistema Operativo.
SQL
 Vediamo quello che puo' essere fatto con l'SQL per monitorare una base dati PostgreSQL.
Vi sono parecchie utili viste di sistema che riportano le statistiche e possono essere
interrogate con normali query SQL.
Vediamo quello che puo' essere fatto con l'SQL per monitorare una base dati PostgreSQL.
Vi sono parecchie utili viste di sistema che riportano le statistiche e possono essere
interrogate con normali query SQL.
All'interno di ogni database PostgreSQL viene mantenuto un ricco Catalog
che consente di controllare con query SQL gli oggetti presenti
nella base dati (eg. pg_database, pg_class, pg_tables, pg_settings, ...).
Ecco un esempio di query sull'utilizzo di spazio degli oggetti:
SELECT relname as Oggetto, rolname as Ruolo,
(CASE WHEN relkind = 'r' THEN 'Table'
WHEN relkind = 'i' THEN 'Index'
WHEN relkind = 'S' THEN 'Sequence'
WHEN relkind = 'v' THEN 'View'
WHEN relkind = 'c' THEN 'Composite'
WHEN relkind = 't' THEN 'Toast'
WHEN relkind = 'f' THEN 'Foreign'
ELSE 'Unknown '||relkind END) as Tipo,
(CASE WHEN relpersistence = 'p' THEN 'Permanent'
WHEN relpersistence = 'u' THEN 'Unlogged'
WHEN relpersistence = 't' THEN 'Temporary'
ELSE 'Unknown '||relpersistence END) as Persistenza,
relpages as Pagine, relpages*8/1024 as Dimensione_MB
FROM pg_class, pg_authid
WHERE relowner=pg_authid.oid
ORDER BY relpages DESC
LIMIT 100;
Ovviamente gli oggetti di maggiori dimensioni sono quelli piu' significativi
per l'analisi delle prestazioni.
La colonna relpersistence e' disponibile dalla versione 9.1: nelle versioni precedenti non puo' essere utilizzata.
Molto importanti per le prestazioni sono ovviamente gli indici.
Oltre che per le primary key e' molto importante definire indici
anche per le unique key e per le foreign key,
sopratutto se le tabella hanno una dimensione significativa.
E' naturalmente possibile utilizzare indici composti;
PostgreSQL, a seconda delle versioni, supporta diverse altre tipologie di indici.
L'ottimizzatore di Postgres e' molto sofisticato ed e' in grado di
scegliere gli indici migliori; per verificare le scelte si utilizza l'EXPLAIN.
Questa query genera le DDL di CREATE per tutti gli indici prestazionali
(cerca le FK su tabelle che superano un dimensione minima senza indici);
mentra questa seconda query genera le DROP per gli indici non utilizzati.
Naturalmente entrambe le query vanno utilizzate comprendendone la logica...
I dati sulle attivita' svolte da PostgreSQL
vengono caricati dallo Statistics Collector (>7.2) che e'
abilitato per default (parametro track_activities).
I nomi delle viste di sistema sono pg_stat_XXX e pg_statio_XXX dove XXX e' sostituito con l'elemento di interesse
(eg. pg_stat_activity, pg_stat_database,
pg_stat_bgwriter,
pg_stat_[all | sys | user]_[tables | indexes],
pg_statio_[all | sys | user]_[tables | indexes],
...).
Sicuramente la vista piu' interessante e' la pg_stat_activity che riporta
lo stato di tutte le connessioni alla base dati:
SELECT * FROM pg_stat_activity;
datid | datname | procpid | usesysid | usename | app ... | query_start | waiting | current_query
-------+----------+---------+----------+----------+---- ... +-------------------------------+---------+--------------
12180 | postgres | 83238 | 10 | postgres | psq ... | 2012-01-12 12:16:27.124733+01 | f | select * from
...
Dalla versione 9.2 la vista pg_stat_activity e' cambiata e fornisce maggiori informazioni.
In particolare la vista 9.2 riporta l'ultima query eseguita e l'indicazione se e' ancora attiva o meno.
In precedenza veniva riportata solo la query corrente o lo stato <IDLE>.
Se la query e' particolarmente lunga viene troncata nella vista pg_stat_activity;
tuttavia e' possibile definire la lunghezza massima con il parametro
track_activity_query_size=16384
[NdA l'impostazione richiede il riavvio, il parametro e' disponibile dalla 8.4].
La vista pg_stat_activity e' disponibile a tutti gli utenti
pero' ciascuno puo' vedere solo i propri statement,
solo gli utenti superuser possono vedere tutte le attivita'.
Per aggirare questo limite e' possibile utilizzare:
CREATE FUNCTION get_sa() RETURNS SETOF pg_stat_activity AS
$$ SELECT * FROM pg_catalog.pg_stat_activity; $$
LANGUAGE sql
VOLATILE
SECURITY DEFINER;
CREATE VIEW pg_stat_activity_all AS SELECT * FROM get_sa();
GRANT SELECT ON pg_stat_activity_all TO pg_power;
Altra vista importante e' la pg_locks che riporta i lock attivi nella base dati:
In generale i lock piu' interessanti sono quelli
bloccati in attesa che una risorsa venga liberata:
SELECT relation::regclass, *
FROM pg_locks
WHERE not granted;
Mettendo assieme sessioni e lock:
SELECT bl.pid as blocked_pid, a.usename as blocked_user,
kl.pid as blocking_pid, ka.usename as blocking_user, a.current_query as blocked_stmt
FROM pg_catalog.pg_locks bl
JOIN pg_catalog.pg_stat_activity a on bl.pid = a.procpid
JOIN pg_catalog.pg_locks kl
JOIN pg_catalog.pg_stat_activity ka on kl.pid = ka.procpid
on bl.transactionid = kl.transactionid and bl.pid != kl.pid
WHERE not bl.granted;
Molto importanti per il tuning di PostgreSQL sono le viste
pg_stat_database, pg_stat_bgwriter perche'
contengono le principali metriche sulle attivita' svolte sui database
dalle applicazioni e dai processi di background:
il numero delle sessioni attualmente connesse (numbackends),
il progressivo dei commit/rollback (xact_commit, xact_rollback);
il numero di richieste di chekpoint (checkpoints_req),
le scritture dal buffer, ...
Vediamo qualche altro utile esempio di query SQL: le dieci tabelle piu' accedute,
tutte le tabelle con l'indicazione delle letture logiche e fisiche,
tutti gli indici con l'indicazione delle letture logiche e fisiche,
transazioni, IO /secondo ed Hit Ratio, ...
Eccole:
SELECT relname, idx_tup_fetch + seq_tup_read AS Total_read
FROM pg_stat_user_tables
ORDER BY Total desc
LIMIT 10;
SELECT relid, relname, heap_blks_read, heap_blks_hit, idx_blks_read, idx_blks_hit
FROM pg_statio_user_tables
ORDER BY relname;
SELECT relid, indexrelid, relname, indexrelname, idx_blks_read, idx_blks_hit
FROM pg_statio_user_indexes
ORDER BY relname, indexrelname;
SELECT sum( xact_commit/(EXTRACT(EPOCH FROM (now()-pg_postmaster_start_time()))*1000) ) TPS,
sum( (blk_read_time+blk_write_time)/(EXTRACT(EPOCH FROM (now()-pg_postmaster_start_time()))*1000) ) IOcpu,
sum((blks_hit)*100.0/nullif(sum(blks_read+blks_hit), 0),2) hit_ratio
FROM pg_stat_database;
SELECT seconds_since_start / total_checkpoints / 60 AS mbc
FROM (SELECT EXTRACT(EPOCH FROM (now() - pg_postmaster_start_time())) AS seconds_since_start,
(checkpoints_timed+checkpoints_req) AS total_checkpoints
FROM pg_stat_bgwriter
) AS sub;
Nell'ultima statistica le tempistiche sull'IO vengono riportate solo se il parametro track_io_timing e' impostato a true
(il default e' false anche perche' ha un costo prestazionale).
Tools
Vi sono molteplici ottimi programmi di amministrazione
per una base dati postgresql. Tra i tanti citiamo il pgAdmin ed il phpPgAdmin.
Si tratta di strumenti semplici da utilizzare e potenti.
Sono cosi' semplici da utilizzare... che non li descrivo affatto!
Naturalmente i dati visualizzati da tutti questi strumenti sono estratti con
normali SELECT... e non vi e' nessuna attivita' che non si possa
svolgere con comandi SQL diretti, ma l'interfaccia grafica rende tutto piu' semplice.
Il tempo passa... ed i tool migliorano! Ecco le interfacce grafiche
di pgAdmin 4 e di OmniDB con PostgreSQL 10:
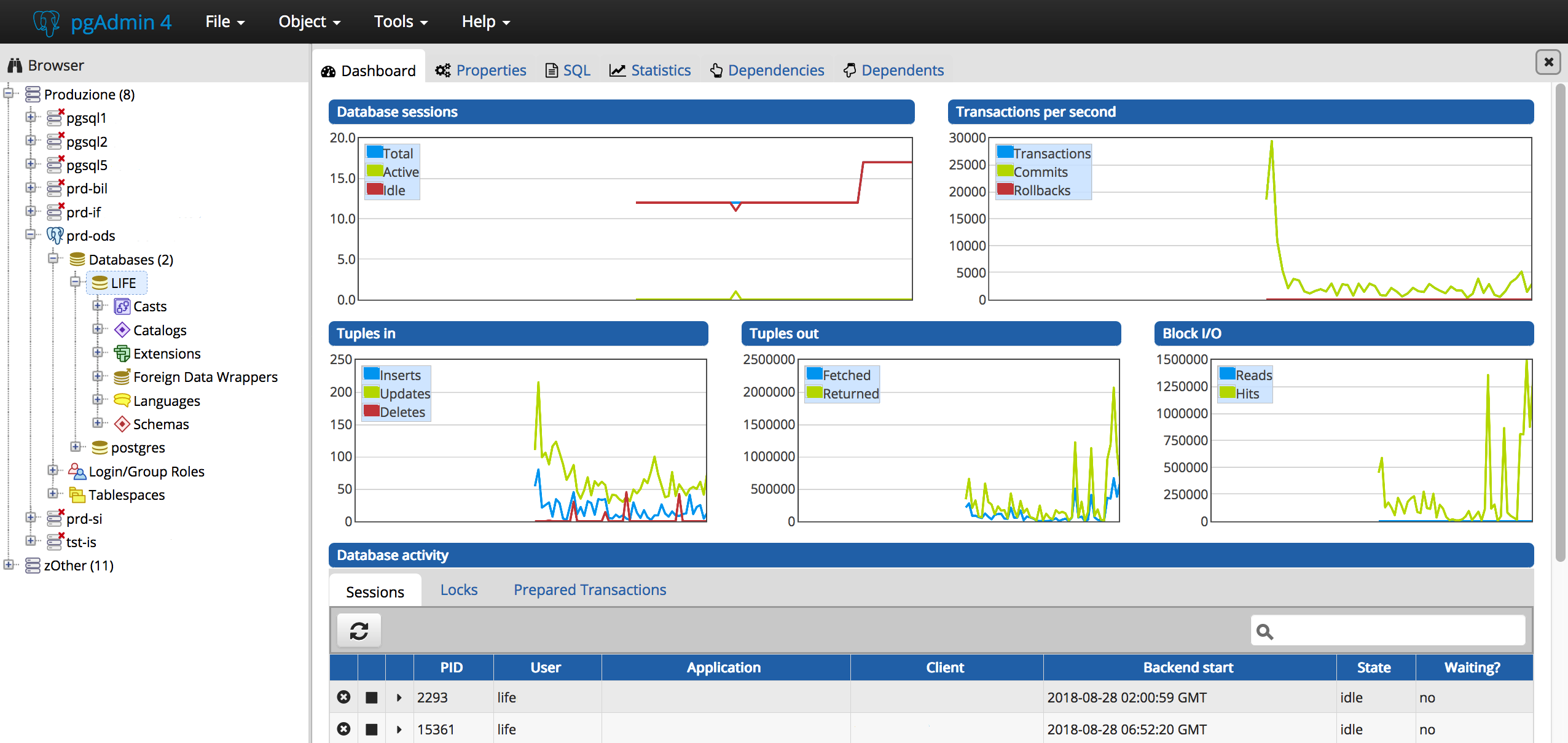
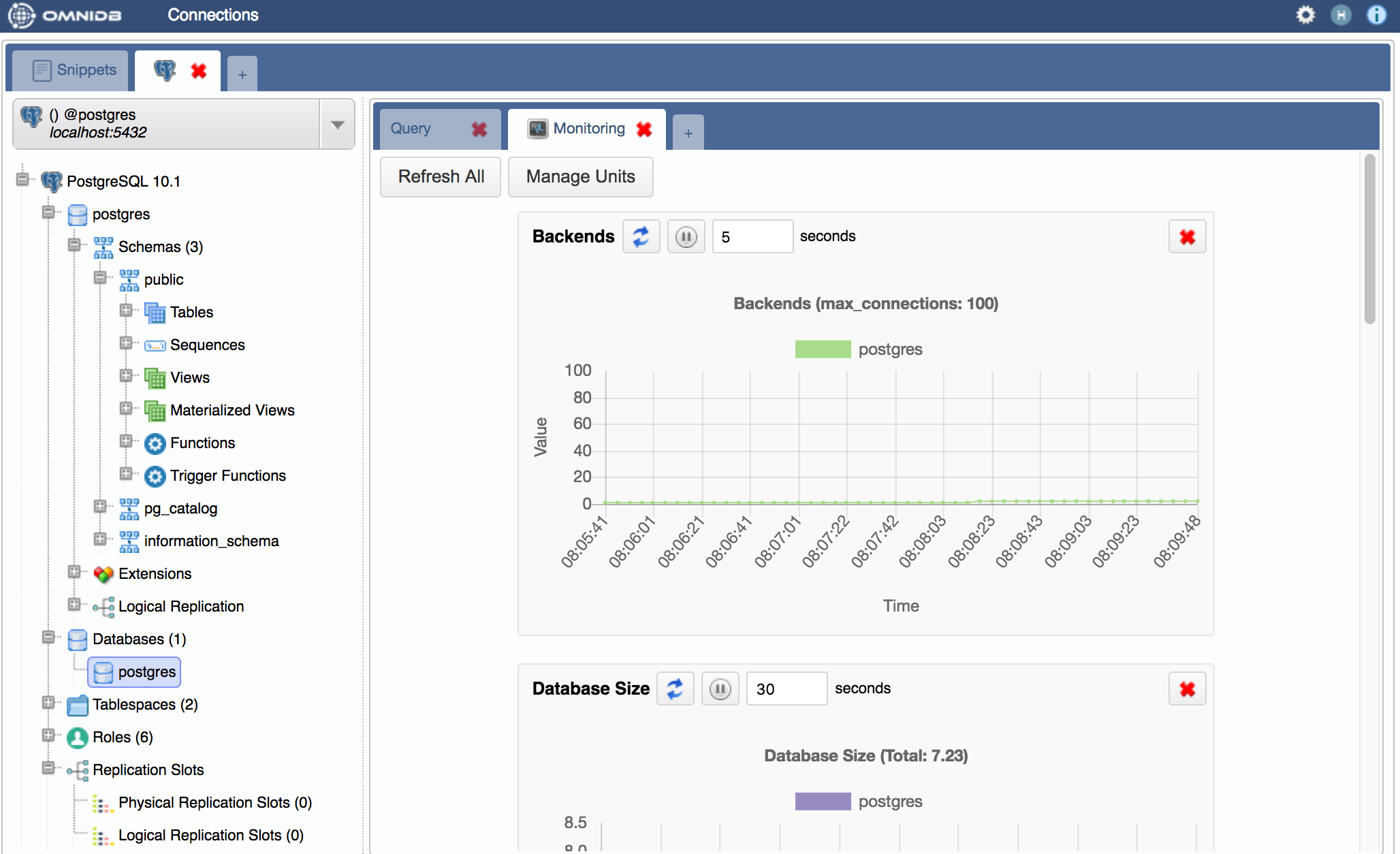
Logging e Tracing
PostgreSQL offre molteplici possibilita' per il logging ed il tracing.
I parametri di logging vengono specificati agendo sul file postgresql.conf.
E' possibile indicare dove effettuare il logging (eg. log_destination, logging_collector, ...),
quando effettuare il logging (eg. log_min_messages che piu' essere impostato sui livelli:
DEBUG5, DEBUG4, DEBUG3, DEBUG2, DEBUG1, INFO, NOTICE, WARNING, ERROR, LOG, FATAL, PANIC),
di cosa effettuare il log (eg. log_connections, log_disconnections, log_duration (pesante),
log_lock_waits, ...), ...
Per il controllo delle performance e' sicuramente utile l'impostazione
log_min_duration_statement=10000 che traccia gli statement SQL con durata superiore
a 10 secondi.
Il parametro log_statement permette di indicare quali tipi di comandi SQL debbono essere
tracciati nel log. L'impostazione puo' essere: none (off), ddl, mod e all (all statements).
Premesso che il livello di logging dipende molto dall'ambiente (eg. sviluppo o produzione?)
e dal tipo di controlli necessari
(eg. avvio nuova applicazione, problemi di performance, ambiente consolidato)...
nel paragrafo precedente ho indicato in neretto le configurazioni consigliate.
I parametri di logging possono anche essere impostati a livello di sessione o di utente:
ALTER ROLE utente_pericoloso SET log_statement=all;
Maggiori dettagli sulla configurazione del logging si trovano sulla
documentazione ufficiale.
I file di log possono naturalmente essere letti con un qualsiasi editor...
ma per un analisi tipicamente si usano tool come pgFouine o pgBadger.
Inoltre PostgreSQL permette il tracing di tutte le attivita' con DTrace.
Maggiori dettagli sulla configurazione del tracing si trovano sulla
documentazione ufficiale.
Monitoraggio sul sistema operativo
Un database PostgreSQL e' ospitato su un sistema operativo ed e' quindi dal sistema operativo che
e' possibile raccogliere informazioni sulle risorse utilizzate. Con PostgreSQL e' particolarmente semplice
poiche' utilizza un'architettura basata su processi ed un banale ps -efa consente di ottenere gia' un'idea
molto precisa delle attivita' in corso, delle utenze connesse, ...
Infatti per ogni sessione e' presente un processo che presenta come argv[]:
postgres: utente database host(porta) comandoSQL
postgres 1918 30202 0 11:59 ? 00:00:00 postgres: postgres postgres 196.102.160.26(57796) idle
postgres 1919 30202 0 11:59 ? 00:00:00 postgres: postgres bench 196.102.160.26(57797) idle
postgres 2263 30202 12 12:32 ? 00:03:02 postgres: bench bench 196.102.160.26(58144) UPDATE
postgres 2264 30202 12 12:32 ? 00:02:59 postgres: bench bench 196.102.160.26(58148) UPDATE
postgres 2266 30202 12 12:32 ? 00:02:59 postgres: bench bench 196.102.160.26(58153) SELECT
postgres 2270 30202 12 12:32 ? 00:02:59 postgres: bench bench 196.102.160.26(58157) idle
postgres 2272 30202 12 12:32 ? 00:02:58 postgres: bench bench 196.102.160.26(58161) idle
postgres 2273 30202 12 12:32 ? 00:02:58 postgres: bench bench 196.102.160.26(58165) idle
postgres 2278 30202 12 12:32 ? 00:02:57 postgres: bench bench 196.102.160.26(58169) BIND
postgres 2280 30202 12 12:32 ? 00:02:55 postgres: bench bench 196.102.160.26(58173) UPDATE
Anche il controllo degli spazi e' banale: un df -H riporta, in modo facilmente
intepretabile anche a noi umani, lo spazio occupato e quello libero per file system montati.
Un elenco dei comandi Unix/Linux piu' utili per il monitoraggio e':
ps top vmstat iostat sar ipcs strace ls df du free
pg_stat_statements
Un potente modulo di PostgreSQL e'
pg_stat_statements
che consente di monitorare gli statement SQL piu' significativi eseguiti sulla base dati.
Il dettaglio delle informazioni ottenute e' notevole ed e' quindi molto opportuno
configurarlo sugli tutti gli ambienti che abbiano un uso significativo di postgreSQL.
Si tratta di un modulo aggiuntivo, non abilitato di default, poiche' ha un peso nell'esecuzione
degli statement che, in alcune condizioni non frequenti, puo' essere significativo.
La configurazione deve essere effettuata nel file postgresql.conf e richiede un riavvio
(poiche' deve caricare una shared library).
In particolare essere aggiunto il parametro pg_stat_statements
all'impostazione shared_preload_libraries in postgresql.conf.
E' possibile specificare altri parametri (eg. pg_stat_statements.max) anche se i valori di default sono
generalmente adatti per una normale installazione.
Il modulo e la libreria pg_stat_statements.so fanno parte dell'RPM postgresXX-contrib.
Ecco un esempio di configurazione completo:
shared_preload_libraries = 'pg_stat_statements' # (change requires restart)
pg_stat_statements.max = 10000
pg_stat_statements.track = all
pg_stat_statements.save = off
## custom_variable_classes = 'pg_stat_statements' # list of custom variable class names (versioni <= 9.1)
Effettuato il riavvio della base dati
e' infine necessario creare le viste di sistema per poter visualizzare i dati raccolti
con:
create extension pg_stat_statements;
Naturalmente il comando va eseguito su tutti i database da cui si vuole interrogare
la statistica.
Nelle versioni precedenti alla 9.1 non erano disponibili le extensions e'
quindi necessario lanciare manualmente uno script, anche questo su tutti i database:
postgres-# \i /usr/pgsql-9.0/share/contrib/pg_stat_statements.sql
SET
CREATE FUNCTION
CREATE FUNCTION
CREATE VIEW
GRANT
REVOKE
Le statistiche raccolte dal modulo vengono riportate nella system view pg_stat_statements,
nello schema public,
che puo' essere normalmente interrogata con una select SQL.
Ad esempio per ottenere le 10 query di maggior durata:
SELECT query, calls, total_time, rows,
100.0*shared_blks_hit/nullif(shared_blks_hit + shared_blks_read, 0) AS hit_ratio
FROM pg_stat_statements
ORDER BY total_time DESC
LIMIT 10;
Se e' attivo il parametro track_io_timing le statistiche raccolte riportano anche
i tempi di accesso all'I/O (il default di track_io_timing e' false anche perche' ha un costo prestazionale).
Il comando per azzerare i dati raccolti, eseguibile solo da un superuser, e':
SELECT pg_stat_statements_reset();
Le statistiche persistono al riavvio del DB (se e' impostato il pg_stat_statements.save=on come per default).
La configurazione iniziale richiede il riavvio del DB
perche' deve allocare la memoria necessaria caricando shared_preload_libraries,
ma alcuni parametri di pg_stat_statements possono essere modificati dinamicamente. Ad esempio:
ALTER SYSTEM SET pg_stat_statements.track = all;
SELECT pg_reload_conf();
L'estensione pg_stat_statements e' stata introdotta con la 8.4 (2009)
ed e' sempre stata aggiornata ed estesa ad ogni nuova release di PostgreSQL.
Alcuni degli ultimi aggiornamenti:
dalla versione 12 la funzione di reset puo' essere selettiva (userid, dbid, queryid)
e puo' essere concessa in GRANT agli utenti non superuser;
dalla versione 13 sono disponibili anche i tempi di plan [NdA attenzione: sono state aggiunte nuove colonne
ed altre sono state rinominate (eg. al posto di total_time va utilizzato total_exec_time)];
nella versione 14 e' stata aggiunta la vista pg_stat_statements_info con ulteriori informazioni
come stats_reset [NdA finalmente!!!],
nella versione 15 sono state aggiunte nuove colonne relative al JIT ed ai temporary,
...
Maggiori dettagli si trovano nella
documentazione ufficiale
[NdA ed anche sull'utilissima
pgPedia].
Interessante sembra anche essere
pg_stat_monitor
che puo' essere considerato un'evoluzione di pg_stat_statements.
Buffer Cache
PostgreSQL dispone di parecchie altre estension oltre alla pg_stat_statements,
alcune delle quali forniscono informazioni utili per le prestazioni.
Per controllare il contenuto della buffer cache e' disponibile un'estensione da caricare con:
create extension pg_buffercache;
Ecco una semplice query per controllare il contenuto della cache:
SELECT c.relname, count(*) AS buffers
FROM pg_buffercache b
INNER JOIN pg_class c
ON b.relfilenode = pg_relation_filenode(c.oid)
AND b.reldatabase IN (0, (SELECT oid FROM pg_database
WHERE datname = current_database()))
GROUP BY c.relname
ORDER BY 2 desc
LIMIT 10;
pgstattuple
La vista pg_stat_all_tables fornisce gia' molti dettagli sull'utilizzo e
sull'occupazione di spazio delle tabelle.
Tuttavia l'extension pgstattuple consente di ottenere maggiori dettagli
sullo spazio disponibile e sulle dead tuple.
PostgreSQL utilizza l'MVCC per garantire la consistenza fornendo
un'elevata concorrenza negli accessi.
Le versioni dei dati delle precedenti transazioni non vengono cancellate subito
ma trattate dai thread dell'autoVACUUM.
In qualche caso puo' essere utile analizzare lo spazio libero e la presenza
di parti non cancellate.
Con la funzione pgstattuple() si ottengono tutti i dettagli:
DBTEST=# create extension pgstattuple;
CREATE EXTENSION
DBTEST=# SELECT * FROM pgstattuple('demo.t_log_msgs');
table_len | tuple_count | tuple_len | tuple_percent | dead_tuple_count | dead_tuple_len | dead_tuple_percent | free_space | free_percent
-----------+-------------+-----------+---------------+------------------+----------------+--------------------+------------+--------------
821837824 | 685970 | 744046403 | 90.53 | 6419 | 2397744 | 0.29 | 65701168 | 7.99
(1 row)
DBTEST=# vacuum analyze demo.t_log_msgs;
VACUUM
DBTEST=# SELECT * FROM pgstattuple('demo.t_log_msgs');
table_len | tuple_count | tuple_len | tuple_percent | dead_tuple_count | dead_tuple_len | dead_tuple_percent | free_space | free_percent
-----------+-------------+-----------+---------------+------------------+----------------+--------------------+------------+--------------
821854208 | 686215 | 744381134 | 90.57 | 1108 | 385728 | 0.05 | 67415192 | 8.2
PostgreSQL Statspack
E' stato sviluppato per PostgreSQL uno strumento che consente
l'esecuzione di snapshot delle statistiche della base dati ed
il loro confronto:
pgStatsPack.
La funzionalita' e' simile a quella di utility Oracle come lo Statspack,
introdotto dalla versione 8.1.6,
o l'AWR (Automatic Workload Repository).
Maggiori dettagli sono riportati in questo documento.
PostgreSQL 10
L'evoluzione di PostgreSQL e' costante e continua (cfr.
Your PostgreSQL stinks)
Nella versione 10 vi sono alcune interessanti novita'
ed variazioni: Monitoraggio con PostgreSQL v.10.