Qualcosa in piu' su PostgreSQL (9.0)
PostgreSQL
e' un potente DBMS relazionale Open Source diffuso e noto per
la sua robustezza e ricchezza di funzionalita'.
Questo documento, rivolto ad un pubblico adulto (scherzo... ma questo documento e' sintetico
e quindi si rivolge ad un lettore esperto) si riferisce alla versione 9.0
di PostgreSQL su Linux (CentOS 5.5) per x86_64 ma e', mutatis mutandis, valido anche per le altre versioni.
Questo documento presenta diversi aspetti di PostgreSQL:
Introduzione,
Installazione,
Configurazione e tuning,
Funzionalita' avanzate,
Architettura,
Amministrazione,
Backup and Recovery,
Replication,
...
Un documento introduttivo su PostgreSQL
e' Introduzione a PostgreSQL mentre sul partizionamento
e' presente un capitolo in DIVIDE ET IMPERA !
Introduzione
PostgreSQL e' un potente object-relational database managment system Open Source
che presenta notevoli vantaggi:
- Free! Gratis per tutti gli utilizzi, anche commerciali.
PostgreSQL viene distribuito completo di
sorgenti con la licenza BSD (che e' molto piu' permissiva della licenza GPL)
- Ottime prestazioni ed affidabilita'
- SQL ricco di funzionalita' tra cui: ANSI-SQL 92/99...2008, trigger, stored functions, subquery, referential
integrity, inheritance, ...
- Gestione completa ed efficiente delle transazioni: ACID properties
- Funzionalita' complete Object-Relational
- Strumenti di amministrazione e gestione completi
(pgAdmin, backup/restore "logico",
on-line backup, recovery point-in-time, ...)
- Architettura completa ed efficiente
- Molteplici interfacce di programmazione:
PL/pgSQL, PL/Tcl, PL/Perl, PL/Phyton (anche nella versione 3 dalla 9.0), JDBC, libpq, Embedded SQL, ...
- Semplicita' nell'installazione e nel tuning.
- Molti tool e funzionalita' accessorie disponibili (eg.
Master-Multi Slave asynchronous replication, Migrazione da altri RDBMS, Bench, ...)
- PostGIS, disponibile come estensione, e' considerato il miglior database cartografico disponibile
Installazione
Sono disponibili i binari per le principali piattaforme.
E' sufficiente scaricare il software corretto dal sito
PostgreSQL
In una configurazione tipica sono necessari i seguenti RPM:
| postgresql90-server-9.0.3-1PGDG.rhel5.x86_64.rpm | Server
|
| postgresql90-9.0.3-1PGDG.rhel5.x86_64.rpm | Client
|
| postgresql90-contrib-9.0.3-1PGDG.rhel5.x86_64.rpm | Moduli aggiuntivi
|
| postgresql90-libs-9.0.3-1PGDG.rhel5.x86_64.rpm | Librerie
|
Scaricato il software, per effettuare l'installazione basta dare i comandi
rpm -il rpm_file1 rpm_file2 ...
Vengono automaticamente creati l'utente unix postgres, lo script di boot /etc/init.d/PostgreSQL-9.0
ed una base dati su /var/lib/postgres/data. Queste impostazioni possono venir facilmente cambiate
agendo sugli script e sul profile.
I repository Yum sono pubblici: in questo recente documento
sono riportati i semplici passi necessari per l'installazione con Yum.
E' disponibile infine anche un'installazione grafica PostgreSQL Plus,
ma ne parliamo in un altro documento.
Utilizzo
Per accedere con l'interprete dei comandi a PostgreSQL il comando e'
psql [db_name]. E' a questo punto possibile utilizzare i
normali comandi SQL. Ogni comando va terminato con un ; e
e per uscire dall'interprete utilizzare il ^D.
Per ottenere l'help sull'SQL: \h,
per ottenere l'help sul psql: \?, per ottenere, ad esempio,
l'elenco delle tabelle: \dt,
la descrizione di una tabella: \d table_name, ...
L'SQL di PostgreSQL e' molto completo ed aderente agli standard (SQL:2008).
E' quindi molto semplice da utilizzare per chiunque conosca l'SQL fornito da un altro
database relazionale.
Configurazione e tuning
Una volta installato PostgreSQL puo' essere utilizzato immediatamente.
Pero' le impostazioni dei parametri di accesso e tuning sono molto limitate.
E' quindi opportuno effettuare una configurazione di base.
Per un sistema Linux con 4GB di RAM dedicato a PostgreSQL una
buona configurazione iniziale e' la seguente:
postgresql.conf
listen_addresses = '*'
max_connections = 100
shared_buffers = 1024MB
work_mem = 2MB
wal_buffers = 16MB
checkpoint_segments = 8
checkpoint_completion_target = 0.9
effective_cache_size = 2048MB
log_destination = 'stderr'
logging_collector = on
log_directory = 'pg_log'
log_filename = 'postgresql-%a.log'
log_truncate_on_rotation = on
log_rotation_age = 1d
log_rotation_size = 0
log_min_duration_statement=5000
log_statement=ddl
datestyle = 'iso, mdy'
lc_messages = 'en_US.UTF-8'
lc_monetary = 'en_US.UTF-8'
lc_numeric = 'en_US.UTF-8'
lc_time = 'en_US.UTF-8'
default_text_search_config = 'pg_catalog.english'
pg_hba.conf
# TYPE DATABASE USER CIDR-ADDRESS METHOD
local all all trust
host all all 127.0.0.1/32 md5
host all all ::1/128 md5
host appl scott 10.11.12.0/24 md5
#host all all 0.0.0.0/0 md5
...
Per effettuare la rilettura dei file di configurazione,
senza riavviare la base dati, il comando e':
pg_ctl reload
E' necessario un periodo di verifica e controllo della
base dati per avere elementi sufficienti per effettuare un tuning efficace.
Su Internet si trovano parecchi documenti e forum su come effettuare il tuning di PostreSQL:
non tutti pero' sono aggiornati.
L'evoluzione di PostgreSQL nel tempo e' stata notevole
e molti dei parametri inizialmente importanti per il tuning sono diventati obsoleti
(sopratutto tra le diverse versioni 8.x).
E' quindi importante fare riferimento alla documentazione relativa alla versione
effettivamente utilizzata. In particolare le ultime versioni di PostgreSQL effettuano
automaticamente il vacuum e l'analize delle tabelle liberando il DBA da tale compito.
Oltre ai parametri gia' indicati precedentemente, che sono i piu' significativi per la versione 9.0,
e' possibile agire anche sui seguenti parametri:
# synchronous_commit = on --> off ## RISK: DATA LOST (on crash)
# wal_sync_method = fdatasync --> open_sync ## RISK: DATA CORRUPTION
# random_page_cost = 4 --> 2 ## RISK: Slower on some queries (alter the optimizer choices)
# autovacuum = on --> off ## RISK: Slower later on (vacuum is important, has several tuning parameters)
Attenzione pero': se volete provare a modificare questi ultimi parametri
fatelo dopo aver effettuato il tuning dei parametri precedenti e
solo se sapete cosa state facendo!
Tutto qui? Certamente no!
I parametri sono centinaia e poi c'e' il sistema operativo, lo storage, i driver,
gli eventuali connection pool, l'infrastruttura di rete, le applicazioni, ...
Una configurazione estrema prevede
l'utilizzo di un tmpfs per il cluster database e dei seguenti parametri nel file postgresql.conf:
fsync=off
synchronous_commit=off
full_page_writes=off
bgwriter_lru_maxpages=0
Si tratta di una configurazione che utilizza una base dati in sola memoria
con perdita di dati in caso di riavvio,
quindi da confrontare con database NoSQL o con memcache...
Funzionalita' avanzate
PostgreSQL ha un insieme molto ampio di funzionalita' avanzate.
Riportarle tutte sarebbe inutilmente lungo, ma cercheremo di dare un accenno alle principali.
PostgreSQL ha un ottimo livello di compatibilita' SQL anche rispetto
ai piu' recenti Standard SQL (ANSI/ISO SQL:2008) e supporta
praticamente da sempre funzionalita' quali: funzioni, viste, subquery, foreign key, constraints,
transazioni, locking, trigger, partitioning, ...
quindi tutto questo lo diamo per scontato!
PostgreSQL supporta nativamente 4 linguaggi procedurali:
PL/pgSQL (il principale), PL/Tcl, PL/Perl e PL/Python (nelle diverse versioni).
Oltre a questi sono mantenuti da progetti esterni innumerevoli altri
linguaggi procedurali quali: PL/Java, PL/Ruby, PL/PHP, PL/sh, ...
Con il PL/pgSQL e' possibile costruire funzioni che contengono all'interno
dichiarazioni di variabili, loop, istruzioni di controllo, ...
Le funzioni realizzate con il PL/pgSQL non possono utilizzare il COMMIT
ma possono modificare dati ed utilizzare lock che vengono rilasciati al termine
della transazione che li contiene.
PostgreSQL e' una base dati Object-Relational.
La definizione di una tabella che "eredita" caratteristiche da un'altra e' molto
semplice e richiede una sola clausola aggiuntiva: INHERITS(object_name).
Con la definizione ad oggetti possono essere implementati in modo semplice e chiaro
costrutti anche molto complessi (eg. Partitioning).
PostgreSQL permette la definizione di tipi definiti dall'utente, di domini, di funzioni, di operatori,
di classi di operatori per gli indici, ...
PostgreSQL permette la creazione di RULE che modificano gli statement
prima di passarli al parser SQL. Con le RULE possono essere implementati comportamenti
anche molto complessi nella base dati, senza alcuna modifica agli statement SQL ed alle
applicazioni. In PostgreSQL le VIEW stesse sono implementate come RULE (e non sono modificabili).
PosgreSQL ha un supporto molto completo per le diverse tecnologie sugli indici.
Gli indici maggiormente utilizzati sono i B-tree (indici bilanciati),
comuni in effetti su tutte le basi dati relazionali.
Sono ovviamente supportati in PostgreSQL indici univoci e gli indici concatenati su piu' chiavi.
Oltre ai B-tree sono disponibili anche indici Hash, GiST (Generalized Search Tree),
GIN (Generalized Inverted Index).
In realta' gli indici GiST e GIN sono "familie" di indici che possono essere estese
per supportare datatype ed operatori anche molto complessi.
PostgreSQL supporta indici parziali, ovvero costruiti solo su una parte della tabella
cui fanno riferimento.
PostgreSQL supporta indici su espressioni.
Oltre alle funzionalita' presenti nel server PostgreSQL
vi sono una cinquantina di diversi moduli aggiuntivi chiamati extensions.
Tra questi sono molto utili: adminpack, dblink, chkpass, pgcrypto, tablefunc, pg_stat_statements, ...
La loro installazione e' banale: tipicamente basta lanciare uno script SQL che crea le funzioni
opzionali su public.
[NdA dalla versione 9.1 l'installazione dei moduli opzionali e' ulteriormente semplificata.
Basta lanciare il comando SQL: CREATE EXTENSION module_name;]
Per PostgreSQL sono disponibili anche una grande quantita' di prodotti e moduli esterni:
PostGIS,
Slony,
Bucardo,
...
Molti pacchetti erano ospitati su pgfoundry
(ora2pg [NDE ora su sf.net],
pgpool [NDE ora su pgpool],
pg_statsinfo [NDE ora su Sourceforge],
...).
L'evoluzione delle diverse versioni di PostgreSQL e le relative funzionalita'
e' riportato su questa pagina web.
Architettura
In questo capitolo cerchiamo di riassumere gli aspetti dell'architettura di PostgreSQL.
La struttura dei processi presenta una serie di processi di background,
tra cui il principale (Postmaster) e gli eventuali processi utente
(Postgres Server):
postgres 30202 1 0 Mar04 ? 00:00:10 /usr/pgsql-9.0/bin/postmaster -p 5432 -D /data/pgsql/9.0/data
postgres 30204 30202 0 Mar04 ? 00:00:30 postgres: logger process
postgres 30206 30202 0 Mar04 ? 00:00:02 postgres: writer process
postgres 30207 30202 0 Mar04 ? 00:00:44 postgres: wal writer process
postgres 30208 30202 0 Mar04 ? 00:00:01 postgres: autovacuum launcher process
postgres 30209 30202 0 Mar04 ? 00:00:01 postgres: archiver process last was 000000010000006900000069
postgres 30210 30202 0 Mar04 ? 00:00:19 postgres: stats collector process
postgres 1918 30202 0 11:59 ? 00:00:00 postgres: postgres postgres 196.102.160.26(57796) idle
postgres 1919 30202 0 11:59 ? 00:00:00 postgres: postgres bench 196.102.160.26(57797) idle
postgres 2263 30202 12 12:32 ? 00:03:02 postgres: bench bench 196.102.160.26(58144) UPDATE
postgres 2264 30202 12 12:32 ? 00:02:59 postgres: bench bench 196.102.160.26(58148) UPDATE
postgres 2266 30202 12 12:32 ? 00:02:59 postgres: bench bench 196.102.160.26(58153) SELECT
postgres 2270 30202 12 12:32 ? 00:02:59 postgres: bench bench 196.102.160.26(58157) idle
postgres 2272 30202 12 12:32 ? 00:02:58 postgres: bench bench 196.102.160.26(58161) idle
postgres 2273 30202 12 12:32 ? 00:02:58 postgres: bench bench 196.102.160.26(58165) idle
postgres 2278 30202 12 12:32 ? 00:02:57 postgres: bench bench 196.102.160.26(58169) BIND
postgres 2280 30202 12 12:32 ? 00:02:55 postgres: bench bench 196.102.160.26(58173) UPDATE
postgres 1893 30202 0 11:37 ? 00:00:00 postgres: kettle_r PGDV 10.102.160.26(52470) idle in transaction
postgres 2296 30202 0 12:31 ? 00:00:00 postgres: kettle_r PGDV 10.102.160.26(56148) LOCK TABLE waiting
Nell'esempio riportato vi sono i processi di sistema ed un processo per ogni connessione utente
(raccolti durante l'esecuzione di un benchmark). Si nota anche una sessione in attesa di un lock.
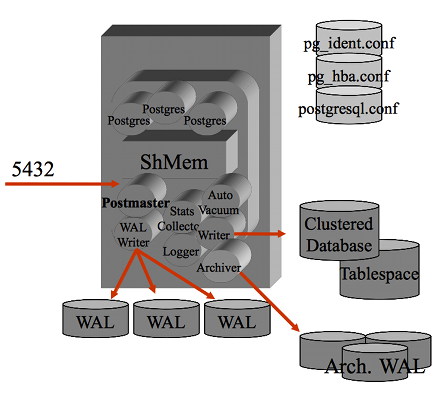 Il processo
postmaster e' il processo principale che si occupa della gestione delle
connessioni (e' in LISTEN sulla porta socket di default 5432)
ed e' il "padre" di tutti i processi, sia di sistema (eg. wal writer)
sia quelli relativi alle connessione utente.
Su ogni processo utente e' riportata l'origine e l'attivita' in corso...
molto comodo per il DBA e per il sistemista!
Tutti i processi girano come utente postgres ed eseguono un attach
al segmento di shared memory su cui vengono mantenuti buffer e lock.
Nel tempo l'architettura dei processi si e' mantenuta sempre simile anche se nelle
versioni piu' recenti sono presenti piu' processi di sistema.
Il processo
postmaster e' il processo principale che si occupa della gestione delle
connessioni (e' in LISTEN sulla porta socket di default 5432)
ed e' il "padre" di tutti i processi, sia di sistema (eg. wal writer)
sia quelli relativi alle connessione utente.
Su ogni processo utente e' riportata l'origine e l'attivita' in corso...
molto comodo per il DBA e per il sistemista!
Tutti i processi girano come utente postgres ed eseguono un attach
al segmento di shared memory su cui vengono mantenuti buffer e lock.
Nel tempo l'architettura dei processi si e' mantenuta sempre simile anche se nelle
versioni piu' recenti sono presenti piu' processi di sistema.
PostgreSQL utilizza i meccanismi di IPC standard su Unix.
Vengono utilizzati alcuni semafori
ed un segmento shared memory
[NdA PostgreSQL utilizza la shared memory di tipo System V fino alla 9.2,
POSIX shared memory dalla 9.3].
Naturalmente la dimensione di questo segmento dipende dai parametri
utilizzati nella configurazione (eg. shared_buffers):
------ Shared Memory Segments --------
key shmid owner perms bytes nattch
0x0052e2c1 3604483 postgres 600 1119281152 16
------ Semaphore Arrays --------
key semid owner perms nsems
0x0052e2c1 9633799 postgres 600 17
0x0052e2c2 9666568 postgres 600 17
0x0052e2c3 9699337 postgres 600 17
0x0052e2c4 9732106 postgres 600 17
0x0052e2c5 9764875 postgres 600 17
0x0052e2c6 9797644 postgres 600 17
0x0052e2c7 9830413 postgres 600 17
La gestione delle transazioni in PostgreSQL avviene con la tecnica del MVCC
(Multiversion Concurrency Control)
e la consistenza dei dati su disco e' assicurata con il logging
(Write-Ahead Logging).
L'isolation level di default e' Read Committed, e' implementato anche il
Serializable e sono teoricamente supportati
tutti gli isolation level previsti dallo standard (eg. Read Uncommitted, Repeteable Read che vengono
mappati sul livello superiore).
In pratica ogni transazione al commit effettua una scrittura
sul WAL (Write-Ahead Log): in questo modo e' certo che le attivita' confermate alla
transazione sono state scritte su disco.
La scrittura sul WAL e' sequenziale e molto veloce.
La scrittura effettiva sui
file delle tabelle e degli indici viene effettuata successivamente
ottimizzando le seek e le scritture sul disco.
Il Clustered Database e' la struttura del file system che contiene i dati.
All'interno vengono mantenuti i file di configurazione ($PGDATA/*.conf),
i log delle transazioni (nella directory $PGDATA/pg_xlog)
e le strutture interne della base dati che contengono
tabelle ed indici (suddivise per database nella directory $PGDATA/base).
Ad ogni oggetto (tabella, indice, ...) corrisponde ad un file
(indicato da pg_class.relfilenode), e sono tipicamente presenti file ulteriori
per la gestione degli spazi come la free space map (suffisso _fsm) e visibilty map
(suffisso _vm).
Di default il blocco ha dimensione 8KB mentre i wal log hanno come dimensione
16MB. Tali dimensioni possono essere variate ma e' necessario ricompilare PostgreSQL
e generalmente tale modifica non presenta vantaggi significativi quindi la la dimensione
e' praticamente fissa.
Le tabelle vengono memorizzate in blocchi ospitati in sequenza (heap) su file.
Una riga o tupla deve essere contenuta in un solo blocco. Per la gestione dei datatype
di maggiori dimensioni viene utilizzato il TOAST (The Oversized-Attribute Storage Technique)
che consente di memorizzare dati fino ad 1GB (230) per riga.
Quando una riga supera una certa dimensione viene divisa in parti (chunk)
e mantenuta sulla tabella TOAST associata alla tabella originale.
Sono disponibili 4 differenti strategie per trattare le colonne:
PLAIN (senza compressione e senza dati esterni, applicabile ai datatype non TOAST-abili
e' il default per molti datatype numerici come int, bigint,...),
MAIN (con compressione ma senza dati esterni se possibile, e' il default per i datatype numeric),
EXTERNAL (con dati esterni ma senza compressione) e
EXTENDED (con compressione e dati esterni, questo e' il default per la maggioranza dei datatype
e' il default per i datatype varchar, text, ...).
Postgres per default cerca di riempire ogni pagina di dati
tuttavia e' possibile riservare una spazio per le sucessive
UPDATE abbassando il valore del parametro di storage fillfactor (default 100).
Sono utilizzabili diverse organizzazioni dei dati come struttura interna
per soddisfare i piu' specifici requisiti di memorizzazione.
Tutti gli indici sono trattati come indici secondari:
hanno quindi una struttura dedicata ciascuno (un file).
I tipi di indice disponibili sono: B-tree, Hash, GiST (Generalized Search Tree) e
GIN (Generalized Inverted Index).
Sono disponibili indici univoci, indici con chiavi multiple, indici invertiti, indici basati su espressioni, ...
La struttura fisica e' degli indici e' simile a quella delle tabelle dove anziche' le tuple
sono memorizzate le chiavi ed i puntatori alle righe (ctid).
All'interno di ogni database viene mantenuto un ricco Catalog
che consente di controllare con query SQL gli oggetti presenti
nella base dati (eg. pg_database, pg_class, pg_tables, ...) e l'andamento delle
attivita' (eg. pg_locks, pg_settings, pg_statistic, pg_stats,...).
Quando viene sottomesso uno statement SQL l'ottimizzatore determina
il query tree da utilizzare con un algoritmo genetico basato sulle
statistiche. PostgreSQL utilizza un ottimizzatore cost-based.
L'algoritmo genetico e' utilizzato per ridurre il numero delle combinazioni
dei possibili percorsi di ricerca.
Nelle ultime versioni di PostgreSQL l'attivita' di analyze e vacuum
(raccolta delle statistiche necessarie
all'ottimizzatore e pulizia delle dead tuples) viene schedulata in automatico.
Amministrazione
 Con le versioni piu' recenti di PostgreSQL alcune delle attivita'
di gestione piu' significative sulla base dati sono effettuate automaticamente
(eg. vacuum, analize). Tra i piu' importanti compiti
che restano al DBA:
Con le versioni piu' recenti di PostgreSQL alcune delle attivita'
di gestione piu' significative sulla base dati sono effettuate automaticamente
(eg. vacuum, analize). Tra i piu' importanti compiti
che restano al DBA:
- Gestione degli utenti.
- Gestione delle strutture del database.
- Controllo attento degli spazi sul file system.
- Controllo dei log e delle attivita' sul sistema.
- Reindex di tabelle con molti movimenti.
Eventuali analyze e vacuum di tabelle che hanno subito forti modifiche.
- Backup e restore.
L'ultimo punto e' fondamentale e gli dedichiamo un intero capitolo.
La maggioranze delle attivita' si possono svolgere con l'interfaccia Client/Server
di pgAdminIII. Qualche volta e' necessario agire sui file di configurazione oppure
lanciare qualche comando in SQL...
Tra le funzioni SQL di amministrazione piu' utilizzate:
pg_cancel_backend(pid) pg_terminate_backend(pid)
pg_reload_conf()
current_setting(setting_name)
set_config(setting_name, new_value, is_local)
pg_switch_xlog() [NdA pg_switch_wal() da PG10]
...
Vi sono alcune utili tabelle che riportano le statistiche di sistema che possono essere
interrogate con normali query SQL: pg_stat_XYZ e pg_statio_XYZ
(eg. pg_stat_activity e pg_stat_database).
Tra le note semplici ma... comunque utili ecco qualche veloce indicazione!
Per impostare un character set in psql: SET client_encoding = 'WIN1252';
Per definire il search path: alter user xyz set search_path=xyz,public;
Gestione utenti
Su PostgreSQL gli utenti (o role) sono gestiti a livello di cluster
e sono quindi creati per tutti i database presenti.
E' possibile definire piu' utenti "amministratori" e gestire le scadenze.
La creazione di un utente consente il login ma non concede alcun GRANT all'utente.
Alle utenze per applicazioni verticali viene spesso assegnata la proprieta' di un intero database
(e di conseguenza tutti i diritti).
Ma per una gestione piu' corretta della sicurezza
le utenze ed i ruoli vanno abilitati con il principio del "minimo privilegio".
Distinti dagli utenti/ruoli sono gli SCHEMA che debbono essere creati a parte.
I GRANT vanno definiti esplicitamente a livello di database, di schema e di singolo oggetto:
CREATE USER xyz WITH LOGIN;
CREATE SCHEMA AUTHORIZATION abc;
ALTER USER xzy PASSWORD 'xyz';
GRANT CONNECT ON DATABASE mydb TO xyz;
GRANT USAGE ON SCHEMA abc TO xyz;
GRANT SELECT ON "MyTable" TO xyz;
Ovviamente il GRANT per oggetto va ripetuto per ogni singolo oggetto...
Puo' quindi essere comodo uno script come:
SELECT 'GRANT SELECT ON ' || relname || ' TO xyz;'
FROM pg_class JOIN pg_namespace ON pg_namespace.oid = pg_class.relnamespace
WHERE nspname = 'public'
AND relkind IN ('r', 'v')
La versione 9 di PostgreSQL ha introdotto alcune novita' per semplificare i GRANT massivi!
GRANT SELECT ON ALL TABLES IN SCHEMA public TO xyz;
Lo statement precedente opera per le tabelle gia' create... per il futuro:
ALTER DEFAULT PRIVILEGES IN SCHEMA public
GRANT SELECT ON TABLES TO xyz;
I superpoteri?
alter user xyz with superuser;
Da ultimo, ma non meno importante, bisogna sempre ricordare il search_path per la sessione
[o per l'utente]!
[alter user xyz] set search_path=xyz,public;
Backup e Restore
Sono disponibili tre differenti tipologie di backup con PostgreSQL:
- Salvataggio logico che deve essere effettuato online con gli appositi comandi
- Salvataggio fisico che puo' essere effettuato solo offline
- Salvataggio online che prevede il salvataggio continuo dei file di log
Salvataggio logico
Il comando per effettuare il backup di un database e':
pg_dump dbname > outfile
L'output e' in SQL. Il comando per effetturare il restore di un database e':
psql dbname < infile
I comandi utilizzano lo standard input/output e quindi possono essere messi
in pipe (eg. effettuare la compressione, crittografare il backup, ribaltare i dati tra due db, ...).
pg_dump salva i soli dati relativi ad un database.
Non salva i ruoli o le tablespace poiche' queste definizioni non sono relative
al database ma al cluster. Il comando per effettuare il salvataggio dell'intero
cluster e':
pg_dumpall > outfile
Il comando per effetturare il restore dell'intero cluster database e':
psql -f infile postgres
La sequenza pg_dumpall > outfile;
psql -d postgres -f infile e' anche quella suggerita per l'upgrade
di PostgreSQL avendo l'avvertenza di utilizzare il comando di pg_dumpall della
versione piu' recente.
Salvataggio fisico
E' possibile utilizzare i comandi di backup del sistema operativo
per effettuare il salvataggio a freddo del cluster database di PosgreSQL,
quindi con il database non attivo.
A differenza di altri database (eg. Oracle), PostgreSQL utilizza file e questi
vengono aperti solo secondo necessita'.
Per diminuire il tempo in cui si deve tenere in down il database
e' possibile utilizzare l'rsync a database attivo, e quindi utilizzare nuovamente
l'rsync a database spento: in questo modo la quantita' di file da aggiornare sara'
minore ed il backup piu' veloce.
E' possibile utilizzare uno snapshot del file system (eg. zfs snapshot tank/home/postgres@today)
se il database e' ospitato su un unico file system. In caso di restore ovviamente PostgreSQL
si comportera' come in un crash recovery ed applichera' il WAL log.
Un backup del sistema operativo e' tipicamente di maggiori dimensioni di quello
ottenuto con pg_dumpall.
Per il restore della base dati e' sufficiente il ripristino con il comando da sistema
operativo ed il normale avvio di PostgreSQL.
Salvataggio online
PostgreSQL registra ogni variazione effettuata sui file del database nei WAL
(mantenuti nella directory pg_xlog). Con l'archiviazione continua dei WAL e' possibile
effettuare backup online su PostgreSQL. Ecco una semplice configurazione di esempio:
wal_level = archive
archive_mode = on
archive_command = 'cp -i %p /mnt/bck/archdir/%f </dev/null'
archive_timeout = 600
Con questa configurazione i WAL file vengono archiviati via via che sono completati
(o quando viene raggiunto il timeout indicato dal parametro archive_timeout).
I passi per effettuare il backup online sono:
- Lanciare il comando SQL: SELECT pg_start_backup('label');
- Effettuare il backup fisico della base dati con tar, cp, cpio, ...
- Lanciare il comando SQL: SELECT pg_stop_backup();
In caso di restore... ovviamente la base dati deve essere spenta,
va ripristinato il backup fisico, cancellato ogni vecchio file presente nella directory pg_xlog
ripristinando gli eventuali ultimi non ancora archiviati
e creato il file recovery.conf nella datadir di PostgreSQL:
restore_command = 'cp /mnt/bck/archdir/%f %p'
# recovery_target_time = '2011-01-01 20:50:00 CET'
Riattivando il database questo riparte in modalita' di recovery ed esegue il restore
con i parametri indicati, arrivando fino all'ultimo WAL o al momento indicato dal PITR
(Point in Time Recovery). Al termine corretto del ripristino il file di parametri
viene rinominato in recovery.done.
Qualche suggerimento aggiuntivo...
Determinare quali WAL tenere e' facile... PostgreSQL crea un file con il nome
dell'ultimo WAL, un valore numerico ed il suffisso .backup;
comunque tenere in linea piu' WAL non e' mai un problema!
Prima di effettuare un restore salvate comunque la base dati ed in particolare gli ultimi WAL.
Fare attenzione ai proprietari dei file ed alle permission.
Fare attenzione allo spazio disco disponibile, una grande quantita' di spazio
su disco e' sicuramente comoda per rendere piu' spedite tutte le operazioni.
Per evitare l'accesso agli utenti durante le operazioni di recovery e' consigliabile
modificare il file pg_hba.conf fino al termine del restore.
Un file recovery.conf.sample si trova tipicamente sotto /share, un esempio
e' allegato e sul GIT ufficiale
si puo' scaricare la versione piu' aggiornata.
In allegato trovate alcuni script di esempio con un salvataggio unico completo,
con un salvataggio per database,
con un salvataggio fisico e dei wal log lanciati dal crontab dell'utente postegres.
Firewall blackout
I Firewall piu' recenti (statefull Firewall) mantengono una cache delle connessioni TCP presenti.
Se una connessione non viene utilizzata per troppo tempo il Firewall effettua un blackout
e non accetta piu' comunicazioni provenienti dal "destinatario"
con il risultato di far cadere la connessione
e restituendo un errore ai client che erano collegati al database PostgreSQL.
Una soluzione e' quella di aumentare la dimensione delle cache sul firewall
impostando un scadenza piu' lunga delle sessioni TCP.
Non e' pero' sempre possibile per problemi di memoria disponibile su Firewall...
PostgreSQL fornisce tre parametri, da impostare nel file postgres.conf,
che consentono di impostare un keepalive a livello di socket:
tcp_keepalives_interval,
tcp_keepalives_count,
tcp_keepalives_idle.
Un risultato analogo si ottiene anche agendo a livello di sistema operativo
modificando il parametro di keepalive del TCP-IP.
Su Linux i parametri del kernel da controllare/modificare sono:
tcp_keepalive_intvl, tcp_keepalive_probes e tcp_keepalive_time.
Per controllare i valori: sysctl -a | grep keepalive .
Di default net.ipv4.tcp_keepalive_time e' impostato a 7200 ovvero a 2 ore.
Per avere un probe ogni 10 minuti basta dare il comando:
echo 600 > /proc/sys/net/ipv4/tcp_keepalive_time
oppure, meglio, configurare nel file /etc/sysctl.conf i valori seguenti e farli rileggere con sysctl -p :
net.ipv4.tcp_keepalive_intvl = 60
net.ipv4.tcp_keepalive_probes = 20
net.ipv4.tcp_keepalive_time = 600
Poiche' agisce a livello di sistema operativo questa ultima
tecnica puo' essere utilizzata con tutti i Database o servizi TCP
e non solo per PostgreSQL.
Replication - Streaming Replication - Hot Standby
PostgreSQL puo' essere utilizzato in configurazioni complesse con diversi livelli
di HA (High Availability), DR (Disaster Recovery), replicazione e Load Balancing.
Alcune configurazioni richiedono un hardware (eg. NAS)
o un software di base specifico (eg. fail over cluster: RHCS, VCS),
altre utilizzano un software di middleware aggiuntivo (eg. Slony,
Bucardo), ...
Nel seguito vengono dati alcuni cenni sulla configurazione di PostgreSQL
in Hot Standby con replicazione in streaming, che sono due features introdotte nella
versione 9.0 e sono disponibili nella distribuzione PostgreSQL.
La configurazione della replicazione e' simile al Point In Time Recovery.
La principale differenza e' che il database di partenza non
e' stato perduto ma e' ancora perfettamente attivo sul server Primary.
Sul primario debbono essere presenti parametri analoghi a quelli gia' visti
per il continuos archiving:
wal_level = archive
archive_mode = on
archive_command = 'cp -i %p /mnt/bck/archdir/%f </dev/null'
archive_timeout = 600
Il server secondario o di Warm Standby deve essere installato e configurato come il
server primario (stesse versioni, directory, utenti, ...)
e va allineato inizialmente con un restore di un backup fisico
recente del primario.
Sul server secondario il file recovery.conf deve contenere i parametri:
standby_mode = 'on'
restore_command = 'cp /mnt/bck/archdir/%f %p'
trigger_file = '/path/to/trigger_file'
archive_cleanup_command = 'pg_archivecleanup /mnt/bck/archdir %r'
Attivando il secondario questo entra in stato di recovery ed
allinea le transazioni occorse raccogliendo i WAL file ed applicandoli alla base dati.
La configurazione della replicazione e' completata!
Il parametro trigger_file definisce il file che fa trasformare il server da
standby a primary. Fino a che tale file non e' presente il server Standby resta sempre
in stato di recovery mantenendosi allineato con il Primary.
La replicazione in PostgreSQL non comporta un rallentamento del Primary e possono
essere utilizzati piu' server di Standby eventualmente distribuiti su rete geografica
in una soluzione di Disaster Recovery.
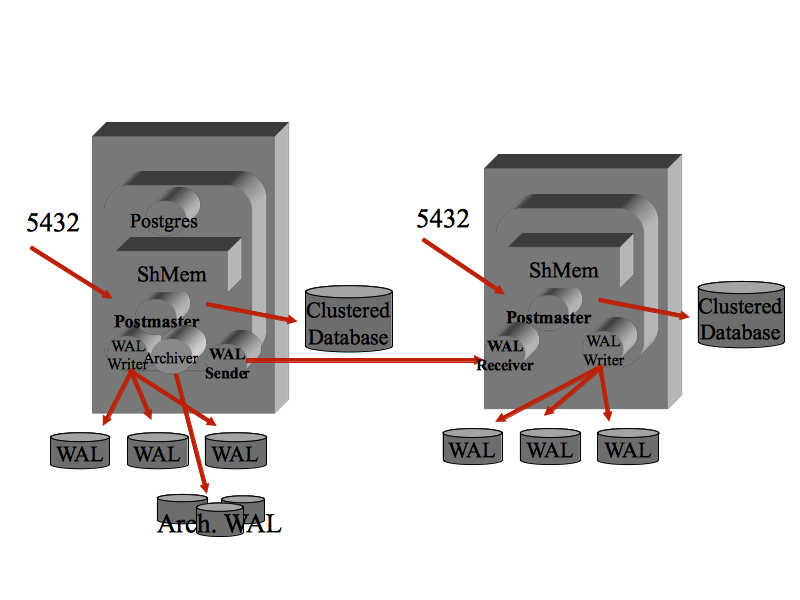
Per attivare la Streaming Replication va aggiunto un parametro sul file recovery.conf:
primary_conninfo = 'host=10.11.12.13 port=5432 user=repl password=replpass'
Tale parametro imposta i parametri di connessione
della streaming replication: i WAL vengono trasmessi
in rete immediatamente e non raccolti da file al loro riempimento.
L'utente repl deve essere definito come superuser sul primary server ed
abilitato alla connessione nel file pg_hba.conf indicando come database replication.
Nel caso in cui la connessione verso il Primary non avvenga, il server in Standby
si mantiene comunque allineato applicando i log file.
Con la semplice aggiunta del un parametro il server in Standby diventa utilizzabile
in read-only dagli utenti:
hot_standby=on
In questo caso si definisce server in Hot Standby.
Sul secondario non possono essere effettuate modifiche sulla
base dati, neanche per oggetti temporanei, e le sessioni utente hanno
limiti maggiori rispetto al Primary. Tuttavia in questo modo
possono lo Standby puo' essere utilizzato in lettura da applicazioni di reporting
e dagli utenti ed e' molto semplice la verifica del suo allineamento con la base
dati Primary.
Le funzionalita' di replica in log shipping fanno parte della release di PostgreSQL
e vengono continuamente aggiornate. Dalla versione 9.2 di PostgreSQL e' disponibile
anche la Cascading replication per gestire in modo ottimale siti
geograficamente distanti in configurazione di Disaster Recovery.