La sempre maggiore dei sistemi aperti e l'evoluzione tecnologica hanno portato alla possibilita' di offrire su Unix, con costi contenuti e prestazioni altissime, applicazioni e servizi di livello enterprise per le aziende. Tali applicazioni richiedono pero' un'affidabilita' molto elevata, superiore a quella dell'HW utilizzato. Il fault di una scheda di rete, di un disco o di un intero sistema non possono compromettere le attivita' aziendali. Per tale ragione sono stati sviluppati software che consentono di aumentare l'affidabilita' dei componenti che gestiscono i diversi tipi di fault possibili. Tra questi i Failover Cluster sono naturalmente i piu' importanti per garantire l'alta affidabilita' (HA: High Availability).
Un cluster e' un'infrastruttura che consente fornire servizi
in condizioni di alta affidabilita'. Fanno parte del cluster una
serie di sistemi, generalmente detti nodi, che ospitano applicazioni
generalmente dette servizi. In caso di fault i servizi sono in grado
di migrare ed essere eseguiti su un nodo differente (failover).
Naturalmente tutte
le connessioni al servizio vengono perdute al momento del fault, ma queste
possono riprendere non appena il servizio viene riprestinato sul
nodo alternativo. Questo generalmente avviene in pochi secondi o alcuni
minuti a seconda della complessita' del servizio.
I prodotti di clustering possono differire parecchio tra loro
ma le caratteristiche ed i concetti di base sono comuni.
Le figure seguenti riportano invece la parte di accesso allo storage
che puo' essere connesso SCSI in multi-homed o con device "intelligenti".
La configurazione in SAN con fibra, attualmente la piu' diffusa,
o in iSCSI sono analoghe.
Perdonate: ho rubato un paio di figure... ma non sono riuscito a farne di migliori!
Una volta configurato e certificato, cosa che richiede competenze tecniche specifiche
ed esperienza, un cluster e' di semplice
utilizzo e puo' essere gestito normalmente da operatori.
Le attivita' piu' comuni sono il controllo dei servizi attivi
e l'eventuale migrazione di questi quando e' necessario
svolgere un'attivita' di manutenzione su un nodo del cluster.
Sul mercato sono disponibili diverse soluzioni cluster.
Tra le principali ricordiamo:
Altre soluzioni, tecnicamente differenti, ma con alcune funzionalita' simili
a quelle dei failover cluster sono:
VMware HA, Oracle VM,
...
Non potevo esimermi dal compilare una lista pratica di comandi!
srvctl status asm
srvctl config asm
Altre tabelle:
Cheat Sheet in verticale e
in PDF
Le configurazioni in cluster sono complesse... meglio affrontarle con un buon bagaglio di esperienza.
Per questo possono essere utili alcuni suggerimenti!
Test e certificazione cluster sono fondamentali per verificare effettivamente il corretto
comportamento del sistema. Ovviamente debbono essere svolti in modo esaustivo e prima di
ospitare ambienti di produzione. Nella mia esperienza non ho mai eseguito un test che
non abbia trovato almeno un problema (anche se non grave) e molte, molte volte ho
trovato configurazioni di cluster "in produzione" che non sarebbero stati in grado
di superare anche i test piu' banali.
Aggiornamento e patching sono importanti ma vanno effettuati con notevole attenzione.
In particolare e' opportuno partire da una configurazione completamente certificata
ed il piu' possibile aggiornata. Gli upgrade successivi vanno invece pianificati ed
effettuati solo se effettivamente necessari.
Sono da verificare con attenzione eventuali conflitti tra i servizi.
Per esempio le basi dati sono spesso in ascolto su una specifica porta TCP.
Con un cluster vanno utilizzate porte differenti per servizio.
Le configurazioni in cluster funzionano benissimo con i Firewall.
Pero' la configurazione deve essere quella corretta.
L'accesso SSH ad un servizio funziona benissimo ma...
nel caso di switch del servizio ovviamente cambia il server e l'SSH si accorge della differenza
(e blocca l'accesso per evitare il Man-in-the-meddle).
Testo: Unix Clusters
I nodi condividono una serie di risorse che vengono di volta in volta
assegnate al nodo che ospita il servizio che le richiede. Si tratta
generalmente di dischi e volumi in configurazione dual host
o multi homed ovvero
accedibili da piu' server (shared storage).
I servizi sono generalmente associati ad un indirizzo di rete virtuale,
anche questo viene assegnato dinamicamente al nodo che ospita il servizio.
I nodi "parlano" tra loro mediante le connessioni di rete pubblica
ma anche attraverso connessioni dedicate dette HeartBeat.
Tramite queste connessioni il cluster e' sempre in grado di controllare
il corretto funzionamento di tutti i nodi e di tutti i servizi.
Al fine di evitare l'attivazione degli stessi servizi su server
differenti, nel caso di caduta di tutte le connessioni di rete,
vengono utilizzati meccanismi di "maggioranza" (eg. quorum partition).
Particolarmente grave e' infatti la situazione di split brain
che occorre quando viene partizionato il cluster e che puo'
portare alla corruzione di dati.
La prima immagine riporta la tipica configurazione di un sistema
in cluster in cui un'applicazione e' in grado di migrare tra i diversi nodi.

Nelle configurazioni di maggiori dimensioni e con piu' nodi
la soluzione preferita e' l'utilizzo di storage in SAN.
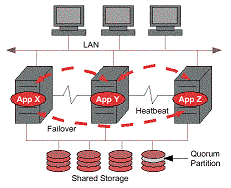


Quando sono presenti piu' nodi e servizi un soluzione in cluster e' molto
efficace per bilanciare il carico delle applicazioni.
 Veritas ClusterServer
La caratteristica principale del Veritas ClusterServer (VCS)
e' quella di poter operare su piattaforme differenti (eg. HP,
IBM, SUN, Linux, MS-WinXX, ...). Sono supportate configurazioni multinodo (fino a 32 da v5.0).
La configurazione e' semplice e viene effettuata
con un'interfaccia grafica. E' possibile definire risorse con
un notevole livello di dettaglio.
La gestione e' molto semplice e ricca di features
che rendono meno probabili errori nell'amministrazione dei servizi.
Veritas ClusterServer
La caratteristica principale del Veritas ClusterServer (VCS)
e' quella di poter operare su piattaforme differenti (eg. HP,
IBM, SUN, Linux, MS-WinXX, ...). Sono supportate configurazioni multinodo (fino a 32 da v5.0).
La configurazione e' semplice e viene effettuata
con un'interfaccia grafica. E' possibile definire risorse con
un notevole livello di dettaglio.
La gestione e' molto semplice e ricca di features
che rendono meno probabili errori nell'amministrazione dei servizi.
L'ultima versione e' la 5.1 SP1 ma sono ancora molto diffuse le
precedenti versioni 3.5 e 4.0.
Maggiori dettagli si trovano sul documento
Veritas ClusterServer
oppure sul
sito web.
 HP ServiceGuard
Il prodotto di clustering ServiceGuard e' il prodotto di elezione
nella configurazione in cluster di sistemi HP.
Si tratta di un prodotto assai stabile che si configura facilmente
agendo su script.
HP ServiceGuard
Il prodotto di clustering ServiceGuard e' il prodotto di elezione
nella configurazione in cluster di sistemi HP.
Si tratta di un prodotto assai stabile che si configura facilmente
agendo su script.
Maggiori dettagli si trovano sul documento
HP ServiceGuard
oppure sul
sito web.
 IBM PowerHA
Il prodotto PowerHA for AIX e' il prodotto di elezione
nella configurazione in cluster di sistemi Unix IBM.
IBM PowerHA
Il prodotto PowerHA for AIX e' il prodotto di elezione
nella configurazione in cluster di sistemi Unix IBM.
La versione attualmente disponibile di PowerHA e' distribuita con il sistema operativo AIX 7.1.
La precedente versione, molto diffusa, era conosciuta come HACMP
(High Availability Cluster Multi-Processing).
Maggiori dettagli si trovano sul
sito web.
 SUN Cluster
Il prodotto SUN Cluster
e' il prodotto di elezione
nella configurazione in cluster di sistemi Unix SUN.
SUN Cluster
Il prodotto SUN Cluster
e' il prodotto di elezione
nella configurazione in cluster di sistemi Unix SUN.
La versione attualmente disponibile e' Oracle Solaris Cluster 3.3.
Maggiori dettagli si trovano sul
sito web.
 Red Hat Cluster Suite
Red Hat e' solo una delle distribuzioni Linux ma
le sue versioni AS ed ES hanno reso la soluzione HA
un pacchetto completo facilmente gestibile ed amministrabile
con una semplice interfaccia grafica.
E' stato inserito di recente il GFS (Global File System) come
componente incluso nella Cluster Suite.
Red Hat Cluster Suite
Red Hat e' solo una delle distribuzioni Linux ma
le sue versioni AS ed ES hanno reso la soluzione HA
un pacchetto completo facilmente gestibile ed amministrabile
con una semplice interfaccia grafica.
E' stato inserito di recente il GFS (Global File System) come
componente incluso nella Cluster Suite.
Maggiori dettagli si trovano sul documento
RedHat Cluster Suite
oppure sui siti ufficiali:
On-line Manual, previuos release
White Paper e
On-line manual

 Linux-HA
Il progetto Linux-HA fornisce le funzionalita' fondamentali di
un ambiente di clustering (HeartBeating, IP takeover, ...) e
conta gia' migliaia di installazioni in ambienti di
produzione. Il progetto e' nato con questo goal dichiatato:
Provide a high-availability (clustering) solution for Linux
which promotes reliability, availability, and serviceability
(RAS) through a community development effort.
L'ottima versione 1 ha il pregio della grande affidabilita' e
della semplicita' di configurazione (che comunque richiede un
buono skill Linux come base). La versione 2 aggiunge il supporto
di configurazioni multinodo.
Linux-HA e' un software free come pure i componenti sui cui
si basano le sue implementazioni (eg. DRBD).
Maggiori dettagli si trovano sul sito
Linux-HA.
Linux-HA
Il progetto Linux-HA fornisce le funzionalita' fondamentali di
un ambiente di clustering (HeartBeating, IP takeover, ...) e
conta gia' migliaia di installazioni in ambienti di
produzione. Il progetto e' nato con questo goal dichiatato:
Provide a high-availability (clustering) solution for Linux
which promotes reliability, availability, and serviceability
(RAS) through a community development effort.
L'ottima versione 1 ha il pregio della grande affidabilita' e
della semplicita' di configurazione (che comunque richiede un
buono skill Linux come base). La versione 2 aggiunge il supporto
di configurazioni multinodo.
Linux-HA e' un software free come pure i componenti sui cui
si basano le sue implementazioni (eg. DRBD).
Maggiori dettagli si trovano sul sito
Linux-HA.
 Pacemaker
Il progetto Open Source Pacemaker e' l'evoluzione piu' recente dei cluster Open Source.
Lo stack piu' utilizzato comprende Corosync e Pacemaker ed e' considerato tra le soluzioni
piu' robuste ed affidabili su Linux.
Maggiori dettagli si trovano sul sito
ClusterLabs.
Tru64 CAA
Il prodotto di clustering CAA (Cluster Application Availability)
e' il prodotto di elezione
nella configurazione in cluster di Alpha Server con Tru64.
Il prodotto e' disponibile a partire dalla versione 5 del sistema operativo.
Caratteristica peculiare e' il file system condiviso da tutti i nodi
del cluster.
Pacemaker
Il progetto Open Source Pacemaker e' l'evoluzione piu' recente dei cluster Open Source.
Lo stack piu' utilizzato comprende Corosync e Pacemaker ed e' considerato tra le soluzioni
piu' robuste ed affidabili su Linux.
Maggiori dettagli si trovano sul sito
ClusterLabs.
Tru64 CAA
Il prodotto di clustering CAA (Cluster Application Availability)
e' il prodotto di elezione
nella configurazione in cluster di Alpha Server con Tru64.
Il prodotto e' disponibile a partire dalla versione 5 del sistema operativo.
Caratteristica peculiare e' il file system condiviso da tutti i nodi
del cluster.
La versione precedente e' ASE (Available Server Environment),
maggiori dettagli si trovano sul documento
Tru64 ASE
Oracle Clusterware
Nato come un componente di Oracle RAC il componente Clusterware di Oracle Grid Infrastructure
implementa in modo completo (dalla versione 11g R2) le funzionalita' di un ambiente di fail-over cluster.
Da linea di comando vengono utilizzate le Server Control Utility che, praticamente, corrispondono al comando
srvctl. E' anche possibile un'ambiente di gestione con interfaccia grafica web: l'Enterprise Manager.
Ogni cluster ha una sua terminologia... ne ho adottato una
comune che utilizza i termini node e serv.
Stato cluster
Start di un servizio
Stop di un servizio
Switch di un servizio
Stop del cluster e dei servizi
Dettaglio configurazione
File di configurazione
VCS
hastatus -sum
hagrp -online serv -sys node
hagrp -offline serv -sys node
hagrp -switch serv -to node
hastop -all
hasys -display
hagrp -display
hares -display
/etc/VRTSvcs/conf/config/main.cf
ServiceGuard
cmviewcl
cmrunpkg [-n node] serv
cmhaltpkg [-n node] serv
cmhaltcl
cmviewcl -v
/etc/cmcluster/cluster.ascii
/etc/cmcluster/serv/serv.ascii
HACMP/PowerHA
clstat -a
cldare -M serv:node
cldare -M serv:stop
cldare -M serv:node
clstop -y -N -g
cllsgrp
clshowres
/usr/es/sbin/cluster/
SUN Cluster
scstat -p
scswitch -Z -g serv
scswitch -F -g serv
scshutdown
scrgadm -p; scconf -p
/etc/clusters
RH Cluster Suite
clustat
clusvcadm -e serv
clusvcadm -d serv
clusvcadm -r serv
service cman stop
/etc/cluster/cluster.conf
HA 1.2
heartbeat status
/etc/rc.d/init.d/serv start
/etc/rc.d/init.d/serv stop
/etc/rc.d/init.d/heartbeat stop
/etc/ha.d/ha.cf
/etc/ha.d/haresources
Pacemaker
heartbeat status
/etc/rc.d/init.d/serv start
/etc/rc.d/init.d/serv stop
/etc/rc.d/init.d/heartbeat stop
/etc/ha.d/ha.cf
/etc/ha.d/haresources
Tru64 CAA
caa_stat -t -v
caa_start serv
caa_stop serv
caa_relocate serv -c node
caa_stat -f
/var/cluster/caa/profile
/var/cluster/caa/script/*
Tru64 ASE
asemgr -d
asemgr -s serv [node]
asemgr -x serv
asemgr -r serv [node]
asemgr -d
/usr/var/ase/config
Oracle Grid
srvctl status database -d dbname
srvctl start database -d dbname
srvctl stop database -d dbname
srvctl config

In particolare per accedere dall'esterno ad un servizio (eg. un MySQL) andra' abilitata in ingresso
la porta 3306 sull'IP del servizio.
Se invece da un servizio cluster si accede ad un DB esterno andranno abilitati tutti gli IP dei nodi
poiche' la richiesta potrebbe provenire da ciascuno di questi.
ssh -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no myUser@myHost.MyDomain
Data: 1 Novembre 2003
Versione: 1.0.16 - 14 Febbraio 2013 ❤️ San Valentino
Autore: mail@meo.bogliolo.name