I prodotti di clustering possono differire parecchio tra loro
ma le caratteristiche ed i concetti di base sono comuni.
Qualche figura...
La prima immagine riporta la tipica configurazione di un sistema
in cluster in cui un'applicazione e' in grado di migrare tra i diversi nodi.
Le figure seguenti riportano invece la parte di accesso allo storage
che puo' essere connesso SCSI in multi-homed o con device "intelligenti".
Una soluzione a basso costo e' possibile con il DRBD
che effettua la sincronizzazione dello storage via rete.
Una volta configurato e certificato, il cluster e' di semplice
utilizzo e puo' essere gestito normalmente da operatori.
Le attivita' piu' comuni sono il controllo dei servizi attivi
e l'eventuale migrazione di questi quando e' necessario
svolgere un'attivita' di manutenzione su un nodo del cluster.
Nel disegno dei sistemi che ospiteranno il cluster
le scelte sul fornitore dell'HW condizionano fortemente
l'architettura. Vi sono tuttavia alcuni elementi di validita'
generale...
Se il cluster e' utilizzato principalmente per aumentare la
disponibilita' dei servizi la scelta piu' comune e' quella
di utilizzare due nodi.
La necessita' di device di I/O utilizzabili in parallelo
dai nodi e' ovvia. Un tempo erano disponibili praticamente
solo Enclosure SCSI dual/multi-homed. Con la diffusione della
tecnologia in fibra e delle SAN (Storage Area Network) le
attuali possibilita' sono molto piu' ampie.
E' importante un accenno all'ambiente del software di base.
Tutto il SW di base e gli ambienti
(directory per i mount point, utenze, permission, ...)
debbono essere identici tra i sistemi posti in cluster.
I sistemi debbono essere adeguatamente sovradimensionati
in modo da poter ospitare un carico maggiore dovuto a servizi ospitati
in caso di fault.
L'utilizzo della tecnologia del cluster offre notevoli vantaggi dal punto di vista di affidabilita' e disponibilita' dei servizi di sistema e delle applicazioni.
Le applicazioni tuttavia debbono soddisfare alcuni requisiti in modo da poter essere inserite nei servizi di un cluster. Anche l'utilizzo dei servizi deve seguire alcune semplici regole per essere efficace. Si tratta, nella maggioranza dei casi, di seguire regole di "buona condotta" nella scrittura ed utilizzo di applicazioni.
Innanzi tutto debbono essere esclusi riferimenti diretti ai sistemi fisici sui cui vengono ospitate le applicazioni. Se e' necessario riportare un indirizzo di rete questo deve essere relativo al servizio cluster e non al sistema ospite e, meglio, sia un nome logico (eg. DNS).
I file system su cui vengono installate le applicazioni debbono essere distinti e legati ai servizi. Non possono essere utilizzati, per lo scambio di dati, aree comuni o di sistema.
Lo scambio di dati tra applicazioni e servizi deve avvenire attraverso canali precisi e catalogati in modo da poter proseguire anche in caso di switch dei servizi su host differenti. Da questo punto di vista l'RDBMS Oracle, sistemi di message queuing sono le tecnologie ideali ma possono ugualmente essere utilizzate funzioni piu' semplici come remsh o ftp.
Le applicazioni "clusterizzabili" sono semplicemente
applicazioni "ben scritte" che possono tranquillamente essere
inserite in sistemi che non forniscono funzionalita' di clustering
o che la forniscono in modo "manuale" (eg. sistemi con dual host).
Il disegno dei servizi e' fondamentale per un cluster.
Una corretta definzione consente di avere un sistema
ben gestibile e flessibile.
In caso contrario si rischia di generare piu' problemi
di quelli che si risolvono!
Nel disegno dei servizi
un obiettivo e' quello di rendere il piu' possibile flessibile
il cluster: dal punto di vista di eventuali attivita' di manutenzione/upgrade;
per l'ottimizzazione delle prestazioni; per evoluzioni future
con un cluster multinodo.
Anche se sono presenti profonde differenze tra i diversi
prodotti di cluster le problematiche sono invece assai simili...
Quindi ritengo che il seguente elenco possa essere utile
per sapere su cosa porre la maggiore attenzione.
Maggiori dettagli si trovano nei documenti specifici:
Unix Clusters,
Veritas ClusterServer,
Amministrare Veritas ClusterServer,
HP ServiceGuard,
HP Available Server Environment.
Testo: Disegno di un Cluster
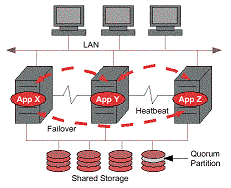
I nodi condividono una serie di risorse che vengono di volta in volta
assegnate al nodo che ospita il servizio che le richiede. Si tratta
generalmente di dischi e volumi in configurazione dual host
o multi homed ovvero
accedibili da piu' server (shared storage).
I servizi sono generalmente associati ad un indirizzo di rete virtuale,
anche questo viene assegnato dinamicamente al nodo che ospita il servizio.
I nodi "parlano" tra loro mediante le connessioni di rete pubblica
ma anche attraverso connessioni dedicate dette HeartBeat.
Tramite queste connessioni il cluster e' sempre in grado di controllare
il corretto funzionamento di tutti i nodi e di tutti i servizi.
Al fine di evitare l'attivazione degli stessi servizi su server
differenti, nel caso di caduta di tutte le connessioni di rete,
vengono utilizzati meccanismi di "maggioranza" (eg. quorum partition).
La stessa politica viene utilizzata al momento del bootstrap
del cluster. Al boot fino a che il quorum non e' stato raggiunto i nodi non
attivano i servizi del cluster.



Mentre le evoluzioni piu' recenti
sono verso i Cluster File Systems;
il concetto non e' nuovo
ed e' gia' stato implementato in diversi ambienti... corsi e ricorsi
dell'informatica!
La configurazione in multinodo, resa molto piu' semplice
dalla diffusione della tecnologia SAN, presenta inoltre
notevoli vantaggi dal punto di vista del bilanciamento del
carico.
In una configurazione con due nodi entrambe i nodi debbono
essere in grado di ospitare tutti i servizi senza difficolta'
(se non un degrado prestazionale).
Questo risulta particolarmente pesante dal punto di vista
del dimensionamento dei sistemi. Oltre ad avere un
numero/potenza adeguata di CPU, la quantita' di memoria e
di swap deve essere in grado di sopportare il carico
di tutti i servizi.
Su un'architettura multinodo questo elemento ha un minor
impatto poiche', in caso di caduta di un nodo, i
servizi verranno migrati su tutti i nodi attivi bilanciando
cosi' il carico.
Una differenza nella configurazione di base puo' rendere
inefficace il cluster impedendo l'erogazione del servizio in caso di switch.
Differenze significative possono rendere completamente inservibile il sistema.
L'attivazione dei diversi servizi DEVE avvenire con i comandi
di gestione del cluster.
In caso contrario sono possibili gravi problemi
fino al blocco completo dei servizi.
Il cluster infatti controlla e gestisce ogni processo presente
e la disattivazione di un servizio puo' essere intepretata
come un fault con le relative conseguenze.
Correttamente configurato e gestito un sistema in cluster facilita notevolmente le operative perche' fornisce un'interfaccia standard e comune per tutti i servizi.
Inoltre vi sono notevoli vantaggi nell'amministrazione. Ad esempio un upgrade del SW di base puo' essere effettuato su un nodo mentre utenti ed applicazioni operano senza alcun disservizio sugli altri nodi del cluster.
La prima decisione e' definire quali servizi clusterizzare!
Non tutte le applicazioni possono essere clusterizzate e
non sempre serve...
E' poi fondamentale definire il livello di granularita'
dei servizi. Una maggior granularita' comporta un
impegno maggiore nella configurazione ed amministrazione
ma consente una flessibilita' maggiore.
Non vi sono regole assolute: il buon senso e l'esperienza
debbono guidare in queste scelte.
Pertanto si cerca in genere di definire servizi
con una granularita' piuttosto elevata.
In tale ottica, per esempio, e' opportuno separare
le parti DB ed application server.
Quando ragioni tecniche (licenze, frammentazione dello spazio disco, ...)
rendono non possibile l'utilizzo di servizi differenti,
si deve cercare di definire servizi che possano facilmente
essere spezzati in un secondo momento.
Il dimensionamento e le capacita' elaborative dei sistemi
in cluster debbono essere adeguate a fare eseguire tutti
i servizi ospitabili. Se, per esempio, vi sono RDBMS Oracle
come servizi, i parametri del kernel relativi alla SGA dovranno
essere dimensionati in modo da poter far ospitare tutte le
istanze.
Le applicazioni inserite in un cluster debbono essere
clusterizzabili!
In realta' non e' un requisito complesso da soddisfare
ma vi sono tante piccole "anomalie" che possono rendere
un applicazione difficilmente clusterizzabile...
riferimenti a path assoluti, a directory di sistema
ad indirizzi fisici sono i piu' comuni.
La definizione della granularita' dei servizi e' molto
importante. Errori comuni sono quelli di fare pochi servizi con piu'
applicazioni oppure spezzare una sola applicazione
in piu' servizi legati tra loro.
Alcuni cluster utilizzano il concetto di risorsa.
Un servizio risulta cosi' composto da una serie di risorse che possono
essere attivate e disattivate singolarmente.
In questo caso i legami tra le diverse risorse debbono
essere individuati e definiti correttamente.
La verifica di compatibilita' di versioni e' sempre molto importante
anche perche' la certificazione del SW per il cluster e' spesso
piu' lenta del normale rilascio di versioni.
Lo stesso avviene per la compatibilita' di patch...
Le politiche di licensing dei prodotti differiscono per ogni prodotto.
Generalmente e' necessario acquistare una licenza per ogni servizio
attivo e non per ogni nodo. Certo non e' un problema tecnico...
ma ha la sua importanza!
Il test di corretto funzionamento di un cluster nelle
principali condizioni di fault e' di notevole importanza
e va eseguito in modo completo prima di inserire in produzione
il sistema. Generalmente viene eseguito un test completo coinvolgendo
il fornitore che rilascia una certificazione del corretto
funzionamento del cluster.
Il cluster va ricertificato ad ogni
modifica di servizi/sistema.
Quando il sistema parte NON deve attivare servizi, oggetti,
risorse, ... che sono in carico al cluster.
Questo vale con tutti i tipi di risorse gestite dal cluster:
non debbono essere montati
i file system, startati i DB, attivati servizi, plumbate le reti, ...
Non sempre i problemi generati da un'attivazione non corretta
sono diagnosticabili in modo semplice anche perch' possono
dipendere da race conditions.
Il takeover dei servizi e' una parte complessa e delicata
del funzionamento di un cluster. I problemi piu' tipici
sono relativi alla rete. Un altro simpatico caso e'
quello dello split brain in cui piu' nodi
cercano di far partire gli stessi servizi!
La gestione dei sistemi con i cluster e' differente da quella
di un normale sistema Unix. Di questo deve essere tenuto conto
e chiunque operi sul sistema (sistemista, DBA,
operatore, fornitore esterno, ...)
deve esserne a conoscenza.
Per esempio lo shutdown di una base dati per normali attivita'
di manutenzione potrebbe far
eseguire uno switch automatico di tutti i servizi su
un altro nodo!
Ad ogni servizio viene associato un IP virtuale.
In questo modo gli utenti fanno riferimento a tale indirizzo
che puo' migrare tra i nodi del cluster.
Un primo problema, banale ma comunissimo, e' che gli utenti e
le applicazioni non utilizzano l'IP virtuale ma gli IP dei nodi
fisici!
Piu' complessi sono i casi di ARP resolution spesso associati
a dispositivi di rete "intelligenti" come bridge, switch e
simili che cercano di separare le tratte...
Oltre alle problematiche di networking, ricordate nel paragrafo
precedente, vi sono anche problematiche piu' "sottili" introdotte
dagli IP virtuali. I sistemi di produzione sono spesso protetti
da Firewall. A seconda dei servizi utilizzati e delle modalita'
di accesso il cluster puo' utilizzare gli indirizzi fisici o
gli indirizzi virtuali. Quindi attenzione alla configurazione dei
Firewall!
Java introduce molteplici possibili architetture del software per i servizi web.
Applet, Servlet, richiami RMI, ... In tutte queste architetture
l'indirizzamento e' un componente fondamentale e va trattato
correttamente nel caso di configurazioni in cluster (eg.
-Djava.rmi.server.hostname=virtual).
Va notato che spesso per i servizi web si utlizzano configurazioni
in Load Balancing... ma questa e' un'altra cosa!
Da ultimo, ma non e' l'ultima cosa:
occhio ai backup ed ai restore sui sistemi in cluster!
Data: 31 Giugno 2004
Versione: 1.0.4 31 Giugno 2004
Autore: mail@meo.bogliolo.name