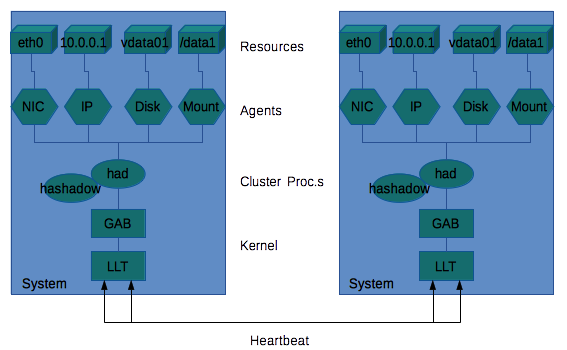
Veritas ClusterServer (VCS) e' il prodotto di clustering realizzato da Veritas (NdE acquisita a sua volta Symantec).
In questo documento vengono riportati elementi relativi
alla configurazione ed all'amministrazione di VCS.
Un documento introduttivo su VCS e'
Veritas Cluster,
in generale sulla tecnologia cluster e' invece
possibile leggere Unix Clusters.
Un cluster VCS e' composto da una serie di system su cui vengono ospitati i servizi applicativi. I servizi prendono il nome di resource group o, in forma abbreviata semplicemente group, poiche' sono costituiti da una serie di resource.
Le risorse, come tutti gli altri elementi che compongono un VCS, sono definite con una logica ad oggetti. Una risorsa viene definita attraverso i suoi attributi (attribute). Gli attributi sono differenti a seconda del tipo di risorsa. I tipi piu' comuni sono:
I tipi di risorse sono parecchi e possono essere arricchiti con l'installazione di agenti specifici (eg. Oracle Agent, SAP Agent, ...). I nuovi tipi di risorse vengono definiti con uno specifico linguaggio che definisce le caratteristiche di ogni oggetto. Ad esempio:
Le risorse sono legate tra loro da vincoli di dipendenza detti link. Ad esempio non e' possibile montare un file system se il volume ed il Disk Group su cui si appoggia non e' stato importato dal sistema. Per descrivere questo con VCS e' necessario creare un link che descriva la dipendenza tra le due risorse coinvolte (le risorse saranno di tipo Mount, Volume e Disk Group). I link tra le risorse sono grafi orientati.
Il cluster controlla l'effettivo funzionamento
di ogni systema, di ogni servizio (Resource Group) ed ogni risorsa mediante un
agent specifico che effettua un probe su ogni
risorsa abilitata (stato di enable). Se si verifica un
fault su una risorsa il cluster cerca di
riattivarla eventualmente (se definita critical) effettuando uno switch su un differente
sistema.
I nodi sono in dialogo tra loro mediante una conessione
di controllo detta
Heartbeat.
Nel caso in cui un sistema cada, gli altri sistemi ne
prendono in carico i servizi effettuando il failover.
La configurazione dei servizi con il VCS puo' essere effettuata in tre differenti modi:
Naturalmente, qualunque sia la modalita' operativa utilizzata,
la logica che guida nella configurazione e' sempre la stessa.
L'analisi dei servizi applicativi forniti dal cluster ed
i relativi livelli di servizio e' quella che richiede la
maggiore esperienza.
Una volta terminata tale fase, l'implementazione della configurazione
richiede una conoscenza tecnica del prodotto e delle sue possibilita'
ma e' lineare.
La prima fase e' quella della costruzione dei Resource Group: uno per ogni servizio del cluster. Ogni servizio applicativo corrispondera' ad un Resource Group che e' l'unita' logica che puo' migrare da un nodo all'altro. Ogni servizio puo' essere fatto partire in automatico su uno o piu' nodi ed ha un ordine preferenziale per l'attivazione.
Definito il servizio si inseriscono tutte le risorse relative.
Naturalmente per ogni risorsa debbono essere definiti tutti gli attributi...
Gli attributi presenti dipendono dal tipo di risorsa.
Ad esempio per una risorsa di tipo File System saranno da definire
il mount point, lo special file, ... per un'istanza Oracle il SID,
l'Oracle Home, ...
Vi sono alcuni attributi presenti per ogni tipo di risorsa.
Tra questi sono fondamentali gli attribuiti:
Un tipo particolare di risorse e' quello di tipo Application.
In questo caso non gli agent del VCS a controllare le risorse,
a seconda dei parametri definiti nei singoli attributi, ma
sono script che debbono essere scritti ad hoc.
Tipicamente si configurano le risorse, quindi, effettuati tutti i controlli
del caso, si mettono in enable.
Se una risorsa va in errore il cluster cerca di
riattivarla (per il numero di volte definito in RestartLimit)
e, se questa non si riavvia ed e' definita Critical, effettua uno switch del servizio.
Percio' e' importante controllare con attenzione tutti i parametri di una risorsa
prima di farla gestire dal cluster.
Se una risorsa deve essere disattivata (eg. per effettuare un backup)
e' necessario utilizzare uno script di disable.
Infine si definiscono i collegamenti tra le risorse. I collegamenti definiscono l'ordine in cui le risorse verranno attivate/disattivate in corrispondenza dell'attivazione/disattivazione dei servizi.
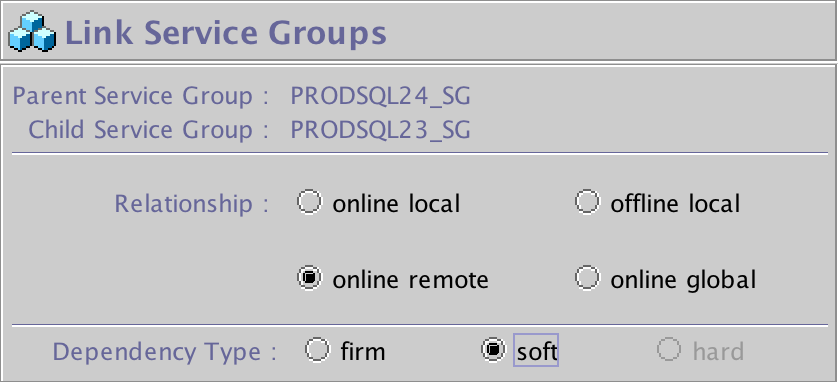 I Resource group possono essere legati tra loro con alcuni vincoli.
Il legame e' di dipendenza di un servizio su un altro
(parent group/child group padre/figlio).
In questo modo si possono far attivare servizi tra loro legati
sullo stesso nodo, oppure su nodi differenti, ovvero pilotare lo switch
dei servizi, ... I legami possono essere:
I Resource group possono essere legati tra loro con alcuni vincoli.
Il legame e' di dipendenza di un servizio su un altro
(parent group/child group padre/figlio).
In questo modo si possono far attivare servizi tra loro legati
sullo stesso nodo, oppure su nodi differenti, ovvero pilotare lo switch
dei servizi, ... I legami possono essere:
Questi legami possono essere di tipo Firm o Soft.
Un link Firm indica che, in caso di caduta del figlio (lower service),
deve essere disattivato anche il padre (upper service);
se il figlio riesce ad effettuare lo switch, lo fa anche il padre.
Un link Soft indica che se il figlio muore viene tentato lo switch;
se lo switch avviene allora anche il padre viene spostato di nodo;
se lo switch non avviene per il figlio, il padre resta comunque attivo.
Per entrambe le modalita' e' necessario mandare in offline prima il
padre, poi il figlio.
Lo switch del servizio (il comando hagrp -switch)
puo' essere effettuato solo sul
servizio figlio quando il padre non e' attivo.
Una nota importante. Il cluster non deve essere interrotto durante una modifica della configurazione. In caso contrario entra nello stato di STALE_ADMIN_WAIT. E' percio' molto opportuno ricordarsi di chiudere e salvare sempre la configurazione!
La situazione di ogni componente del cluster e' rappresentata da uno stato. Ogni tipo di componente ha un diagramma di stati piuttosto complesso che ne descrive il funzionamento.
I sistemi sono generalmente in stato di RUNNING. Sono in stato UNKNOWN quando non sono connessi al cluster ed in stato di FAULTED quando vanno in errore. Il tipico flusso di inizializzazione e connessiona al cluster di un sistema e' INITING -> CURRENT_DISCOVER_WAIT -> REMOTE_BUILD -> RUNNING.
I resource group sono in stato di ONLINE quando tutte le loro risorce sono attive,
PARTIAL se alcune risorse non sono attive ed OFFLINE quando non attivi.
L'elenco (non completo) dei possibili stati di un resource group e':
OFFLINE - Tutte le risorse non-persistent sono offline.
ONLINE - Tutte le risorse con AutoStart=1 sono online.
FAULTED - Almeno una risorsa critical e' in fault.
PARTIAL - Almeno una risorsa con AutoStart=1 e' online (ma non tutte altrimenti e' in ONLINE).
STARTING - Il gruppo sta andando in online.
STOPPING - Il gruppo sta andando offline.
W_ONLINE_REVERSE_PROPAGATE - Il gruppo aspetta che le risorse vadano in online
Gli stati possono essere anche multipli (eg. OFFLINE|FAULTED).
Le sigole risorse sono tipicamente in stato di ONLINE o OFFLINE.
In caso di errore sono in stato di FAILED.
Nel caso invece in cui le risorse fossere
in attivazione/disattivazione queste vengono riportate
con lo stato di W_ONLINE/W_OFFLINE.
L'elenco (non completo) dei possibili stati di una risorsa e':
ONLINE
OFFLINE
FAILED
W_ONLINE
W_CHILDREN_ONLINE
W_OFFLINE
W_OFFLINE_PROPAGATE
W_OFFLINE_PATH
W_OFFLINE_REVERSE
W_ONLINE_REVERSE
W_ONLINE_REVERSE_PROPAGATE
W_ONLINE_REVERSE_PATH
VCS utilizza algoritmi piuttosto complessi per la gestione dei service group e delle risorse poiche'
i passaggi di stato dipendono
dai molti parametri di queste ultime
(eg. Enable, Critical, AutoStart, MonitorOnly, IState, SecondLevelTimeout, AutoTakeover, ...).
Solo a titolo di esempio... se un nodo del cluster viene disattivato i service group che
possono essere ospitati su tale nodo vegono posti in stato di autodisable poiche' VCS non
e' certo dell'ultimo stato definito sul nodo. E' ovviamente possibile riabilitare i servizi
con un comando: hagrp -autoenable servizio -sys nodo
I log di tutte le attivita' svolte dal cluster sono mantenute in un file di log
il cui riferimento si ottiene con halog -info
[NdA tipicamente e' il file /var/VRTSvcs/log/engine_A.log].
Ecco un esempio:
2017/04/01 18:28:59 VCS INFO V-16-1-10196 Cluster logger started 2017/04/01 18:28:59 VCS NOTICE V-16-1-11022 VCS engine (had) started ... 2017/04/01 18:28:59 VCS INFO V-16-1-53504 VCS Engine Alive message!! 2017/04/01 18:29:03 VCS INFO V-16-1-10077 Received new cluster membership 2017/04/01 18:29:03 VCS NOTICE V-16-1-10112 System (prod-farm03) - Membership: 0x7ff, DDNA: 0x1801 2017/04/01 18:29:03 VCS NOTICE V-16-1-10322 System (Node '0') changed state from UNKNOWN to INITING ... 2017/10/31 06:08:53 VCS NOTICE V-16-1-10300 Initiating Offline of Resource ora_db01 (Owner: Unspecified, Group: ORA01_SG) on System prod-farm02 2017/10/31 06:08:58 VCS WARNING V-16-2-13011 (prod-farm09) Resource(ora_db07): offline procedure did not complete within the expected time. 2017/10/31 06:08:58 VCS ERROR V-16-2-13063 (prod-farm09) Agent is calling clean for resource(ora_db07) because offline did not complete within the expected time. ...
I messaggi possono essere di livello diverso (eg. NOTICE, WARNING, ERROR) e sono gli stessi che si possono selezionare sull'interfaccia grafica [NdA ma il log mantiene tutta la storia].
L'interfaccia grafica e' di semplice comprensione ed utilizzo. Non e' velocissima e richiede un po' di attenzione nelle operative: e' possibile fare danni con un semplice click!
Generalmente si procede creando una catena di risorse (eg. dal Volume Group
all'Application) e quindi si procede con Copy&Paste creando cosi'
l'intero gruppo.
Attenzione agli attibuti da definire per ogni risorsa:
se una risorsa e' definita CRITICAL puo' generare uno switch
del cluster!
Generalmente si definiscono CRITICAL solo le risorse principali (eg.
disk group, volumi, mount point, NIC, IP)
mentre si lasciano NOT CRITICAL le risorse
applicative o soggette a cadute che il cluster non deve gestire
(eg. servizi applicativi).
Quando una risorsa viene posta in stato di ENABLE questa viene
controllata (PROBE) e gestita dal cluster.
Le risorse in OFFLINE sono riportate in grigio mentre
quelle ONLINE vengono colorate, le risorse in FAILED
vengono riportate con una croce rossa.
Quando l'interfaccia grafica presenta un punto interrogativo
significa che gli agent non riescono controllare la risorsa...
probabilmente c'e' un errore nella configurazione!
Facile vero?
Diamo qualche esempio di comando utilizzabile in linea.
Per controllare lo stato di ogni singola risorsa:
Per ottenere il dettaglio degli attributi di ogni singola risorsa il comando e':
E' anche possibile agire sulla configurazione del cluster e di ogni singola risorsa modificandone i valori come nell'esempio seguente:
I comandi sono ricchi di opzioni ed e' possibile ottenere tutte le informazioni sui dettagli della configurazione...
# Ricerca sul DNS degli IP definiti nella configurazione del cluster
for i in `hares -display -attribute Address | grep -v ^#Resource | awk '{ print $4}' `; do echo IP2Name $i; nslookup $i; done | grep -i name
# Verifica configurazione sistema: controllo della presenza di tutti i mount point
for i in `hares -display -attribute MountPoint -type Mount | grep -v ^#Resource | awk '{ print $4}' `; do ls $i >/dev/null; done
# Verifica configurazione sistema: controllo della presenza nel file di password degli utenti owner di Oracle
for i in `hares -display -attribute Owner -type Oracle | grep -v ^#Resource | awk '{ print $4}' `; do \
grep $i /etc/passwd>/dev/null || echo Undefined user: $i; done
Dagli esempi e' chiaro che il livello di flessibilita' e' molto elevato in quanto e' possibile "programmare" comportamenti differenti a fronte di condizioni o errori [NdA manca la gestione dell'header... lo so, ma cosi' gli esempi sono piu' semplici: basta mettere tail +2 su Solaris o tail -n +2 su Linux].
Per agire con competenza sul cluster e' necessario avere buone competenze sul sistema operativo ospite.
Questo e' particolarmente importante sulle attivita' amministrative di configurazione e di problem solving.
VCS gestisce direttamente le risorse.
Se le gestiamo manualmente queste possono andare in errore ed il cluster prende provvedimenti
eventualmente smontando un file system, migrando un servizio, ...
Primo consiglio: usare i comandi del cluster. Secondo consiglio: mettere in freeze i servizi
Ci sono casi in cui il cluster non riesce comunque a risolvere un problema ed e' necessario
agire direttamente sul sistema operativo: non fatelo se non sapete cosa state facendo (eg.
fsadm -o mntunlock=VCS /FS_bloccato;
fsadm -o mntlock=VCS /FS_bloccato;
/opt/VRTS/bin/umount -o mntunlock=VCS /FS_bloccato)!
Non basta? Facciamo danni! [NdA a volte il cluster non riesce a sboccare risorse in W_OFFLINE]
L'architettura VCS prevede un cluster costituito da una
serie di sistemi (fino a 32) connessi ad uno o piu'
sistemi di storage condiviso.
I sistemi debbono essere connessi tra loro su una rete privata.
Tipicamente si utilizzano semplici ed affidabili cavi incrociati o, se i nodi
sono piu' di due, un hub dedicato.
Tale connessione, detta Heartbeat, deve essere ridondata per
evitare SPoF (Single Point of Failure).
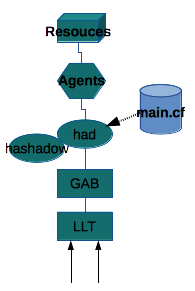
I processi relativi al cluster sono due: ha ed hashadow.
In realta' solo uno funziona, il secondo controlla
che l'altro processo sia attivo e, nel caso, ne effettua
la ripartenza.
Il processo del cluster si occupa della sincronizzazione
di tutti i nodi e della gestione delle risorse presenti sul
nodo.
Quando un nodo risulta in errore i processi di gestione del cluster
si occupano di effettuare la ripartenza di tutti i servizi
(resoruce group) ospitati sul nodo in fault.
Quando lo stato di un resource group non puo' essere
determinato con certezza questo entra nello stato di autodisable
I principali comandi per la gestione dei Service Group sono
gia' stati presentati nel documento introduttivo (eg.
hagrp -offline moon01 -sys giove;
hagrp -switch moon02 -to saturno;
hastatus -sum), oltre a questi e' importante ricordare
l'opzione di -freeze che consente di disattivare
le attivita' di switch del cluster per un gruppo.
Tale opzione e' molto comoda quando debbono essere svolte
attivita' sistemistiche che coinvolgono alcuni servizi.
Anche le singole risorse di un gruppo possono essere attivate (online) o
disattivate (offline). Se una risorsa va in offline
in modo non coordinato dal cluster, il probe ne
controlla lo stato e la pone in stato di faulted.
Da tale stato e' possibile riportare in online la risorsa
solo dopo aver effettuato un clear.
Naturalmente se la risorsa e' di tipo critical
il cluster si occupa di effettuare tutte le azioni
per ripristinarla: anche effettuare lo switch della risorsa se necessario.
Attraverso i moduli del kernel LLT (Low Latency Transport protocol)
e GAB (Global Atomic Broadcast) il SW di cluster controlla
il corretto collegamento e funzionamento con tutti i sistemi
che compongono il cluster.
Il protocollo di comunicazione LLT utilizzato e' proprietario Veritas.
L'LLT utilizza direttamente i MAC delle schede e deve essere utilizzato
solo su connessioni dirette o private. E' possibile attivarlo,
con una modalita' specifica, anche su una rete pubblica come backup.
Il GAB e' il protocollo logico che si appoggia sull'LLT come
trasmissione.
Il GAB controlla la presenza dei nodi e mantiene allineata la configurazione
dei servizi.
Il controllo che tutte le risorse siano attive avviene con agent specifici che effettuano il probe. Il tipo di controllo dipende dalla tipologia di oggetto. Molti degli script utilizzati dagli agent sono realizzati in perl. Per le risorse di tipo Application il probe viene effettuato con lo script di monitor che deve essere fornito al momento di definizione dell'oggetto.
L'installazione di VCS e' piuttosto semplice. Il prodotto distribuito (ovviamente su CD) contiene uno script che effettua l'installazione in modo automatico. Ma vediamo i passi in maggior dettaglio...
I sistemi che debbono ospitare il cluster debbono essere correttamente
configurati e disponibili in rete. Debbono essere definite e funzionanti
le connessioni di Heartbeat.
L'installazione dei pacchetti avviene in modo differente a seconda del tipo di sistema
(eg. pkginstall, swinstall, ...). Deve essere installato il SW vcs e
gli eventuali agenti opzionali (eg. per Oracle).
Ora si puo' lanciare il menu installer che consente
di scegliere i diversi pacchetti da installare oppure
eseguire singolarmente i vari passi.
Il primo e' installare la licenza con
licensevcs.
Quindi si effettua la configurazione di base lanciando lo
script installvcs.
Lo script effettua la configurazione in parallelo su tutti i
nodi del cluster,
purche' sia possibile utilizzare ssh o rsh
(opzione -rsh).
Naturalmente bisogna essere pronti a rispondere alle domande...
si tratta delle solite cose: nomi dei server, indirizzi, schede
di rete, ...
La configurazione di base carica anche sul sistema i due moduli LLT e
GAB che sono kernel loadable modules.
L'attivazione di VCS avviene generalmente al boot del sistema ed analogamente avviene allo shutdown. La procedura di installazione pone nelle directory corrette tutti gli script necessari. Naturalmente i nomi degli script e le le directory dipendono dal sistema operativo... (eg. su HP-UX saranno i link /sbin/rc3.d/S680llt /sbin/rc3.d/S920gab /sbin/rc3.d/S990vcs).
Terminata l'installazione non sono generalmente necessarie ulteriori configurazioni. Ma se dovesse essere necessario... leggete il prossimo capitolo!
Se e' necessario variare la configurazione del cluster e'
necessario effettuarne la disattivazione.
Il comando per terminare il VCS server e' hastop.
Il comando ha diverse opzioni tra cui -all che indica
che debbono essere fermati tutti i nodi, -force che indica
di mantenere i service group comunque attivi o -evacuate
per forzare la migrazione dei service group su un altro sistema
attivo sul cluster.
Quando lo stato delle risorse non e' corretto su un solo nodo e'
possibile chiudere il cluster con hastop -local.
La ripartenza del cluster si effettua, terminate le configurarioni e
corretti tutti gli errori,
con il comando hastart.
Se viene modificata la configurazione del cluster in modo significativo
e' generalmente necessario anche interrompere il flusso
sulle connessioni HeartBeat. In questo caso i comandi sono
gabconfig -U e lltconfig -U che effettuano anche l'unload
dei kernel modules relativi.
A questo punto si puo' variare la configurazione del cluster!
Il file /etc/gabtab contiene i comandi per l'attivazione del GAB:
/sbin/gabconfig -c -f 30000 -n2
Nell'esempio viene settato il timeout di IOFENCE a 30 secondi
ed impostato il numero minimo di server per il seeding a due.
E' anche possibile utilizzare un disco creato con
gabdiskconf
ed aggiungerlo alle connessioni di heartbeat con
gabdiskhb
(GAB disk).
Altre configurazioni possibili riguardano
il comportamento del cluster in caso di disconnessioni o errori
(eg. mandare in PANIC il sistema se avviene un rejoin e si e'
determinato uno split brain), ma sono meno comuni...
Per controllare la configurazione del gab si utilizza il comando
gabconfig -l mentre con gabconfig -a si controllano
le porte connesse.
Il file /etc/llthosts contiene i nodi definiti sul cluster la configurazione dell'LLT:
0 saturno 1 giove
Il file /etc/llttab contiene la configurazione dell'LLT:
set-node giove set-cluster 99 link lan2 /dev/lan:2 - ether - - link lan9 /dev/lan:9 - ether - - link-lowpri lan1 /dev/lan:1 - ether - - start
Nell'esempio sono utilizzate due connessioni HeartBeat di tipo
normale ed una terza su una scheda attestata sulla rete pubblica.
Come gia' riportato nel documento introduttivo,
per controllare il corretto funzionamento della
connessione in Heartbeat dei sistemi si utilizza il comando:
La situazione riportata indica che il cluster e' attivo ed e' costituito da due sistemi entrambe funzionanti.
VCS supporta fino a 32 nodi su un singolo cluster.
E' quindi possibile avere configurazioni complesse in cui
i nodi vengono aggiunti in fasi sucessive.
Prima di effettuare l'inserimento di un nuovo nodo nel cluster
e' necessario preparare il sistema come gia' descritto per
l'installazione: prerequisiti, connessioni di heartbeat,
installazione SW, ...
Debbono essere quindi configurati i file
/etc/llthosts /etc/llttab e verificata la directory
/opt/etc/VRTSvcs/conf (eg. il file
/etc/VRTSvcs/conf/sysname contiene il nome del nodo).
Facendo partire llt e gab il cluster aggiorna in automatico
la configurazione (attenzione aggiorna solo la configurazione dei servizi
del cluster, non gli eventuali script di controllo delle applicazioni che debbono
essere mantenuti allineati tra i nodi).
E' quindi possibile inserire i nuovi nodi nella configurazione
dei servizi. Puo' essere fatto da interfaccia grafica o con
gli analoghi comandi in linea:
La configurazione del nuovo nodo e' terminata. Con hastart puo' essere fatto partire il cluster anche sul nuovo nodo.
Una configurazione particolare e' quella di cluster differenti ed indipendenti su cui i servizi possono essere attivati in modo alternativo. Veritas Cluster Server offre un'opzione specifica denominata Global Cluster Option (GCO). Si tratta di una configurazione utilizzata nei siti di disaster recovery o per garantire un elevato grado di business continuity.
Quando e' attiva la GCO sono presenti alcune opzioni in piu' ai comandi di gestione che consentono di effettuare uno switch di un servizio anche verso un cluster remoto e la visualizzazione dello stato dei diversi cluster.

L'opzione GCO e' spesso utilizzata in modo integrato con meccanismi di replicazione dei dati come il VVR o la sincronizzazione tra Storage.
E' opportuno documentare la configurazione del cluster e dei relativi servizi e mantenere aggiornata tale documentazione. Puo' essere utile uno schema come il seguente:
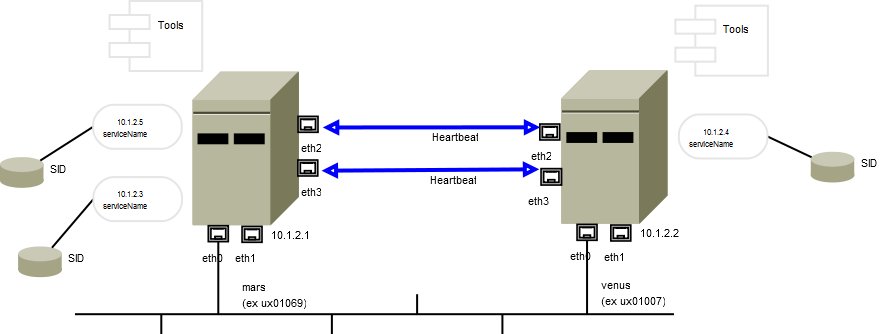
Nello schema sono riportate le interfacce di rete, gli indirizzi fisici, gli indirizzi dei servizi, le basi dati, le connessioni di heartbeat, le applicazioni ospitate, ... E' quindi orientato ai tecnici.
Piu' vicino alla gestione dei servizi e' invece uno schema come:
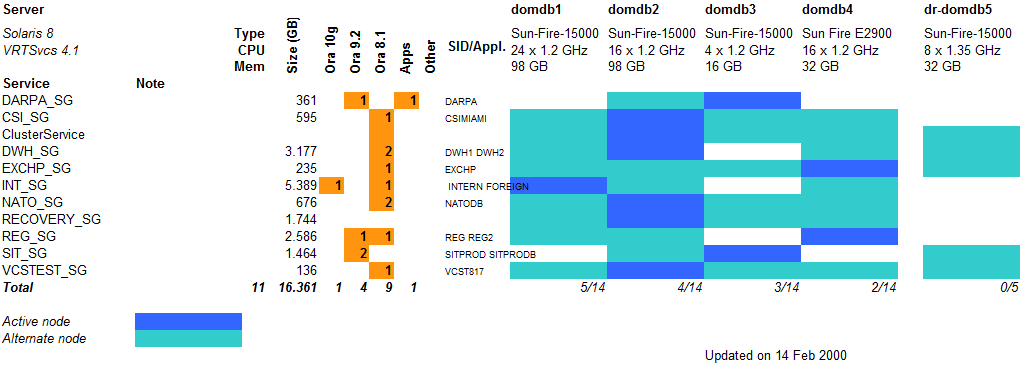
In questo caso sono evidenziati i servizi applicativi, le dimensioni dei volumi, i software utilizzati, i preferred server, ...
La configurazione del cluster e' contenuta nel file
/etc/VRTSvcs/conf/config/main.cf.
Il file contiene la definizione di ogni singola risorsa.
Il file e' facilmente comprensibile poiche' vengono
riportati solo i valori non di default che sono tipicamente
quelli significativi.
Nell'esempio che segue si trova una configurazione tipica:
include "types.cf"
include "OracleTypes.cf"
cluster Solar (
UserNames = { admin = "asdfTasdHpzS." }
Administrators = { admin }
CounterInterval = 5
)
system giove (
)
system saturno (
)
group moon01 (
SystemList = { giove = 1, saturno = 2 }
AutoStartList = { giove , saturno }
)
Application app001-appl (
Critical = 0
StartProgram = "/usr/local/VCS/script/app001/start"
StopProgram = "/usr/local/VCS/script/app001/stop"
CleanProgram = "/usr/local/VCS/script/app001/clean"
MonitorProgram = "/usr/local/VCS/script/app001/monitor"
)
DiskGroup appDB0-dg (
DiskGroup = appDB0
)
DiskGroup appDB0-dg (
DiskGroup = appDB0
)
IPMultiNIC callio-ip (
Address = "192.168.6.220"
NetMask = "255.255.254.0"
MultiNICResName = M_callio-nic
)
Mount appDB0-mnt (
MountPoint = "/db/appDB0"
BlockDevice = "/dev/vx/dsk/appDB0/appDB0"
FSType = vxfs
FsckOpt = "-y"
)
IP callio-ip (
Critical = 0
Device = lan1
Address = "192.168.6.220"
NetMask = "255.255.254.0"
)
Oracle appDB0-ora (
Critical = 0
Sid = appDB0
Owner = oracle
Home = "/swbase/app/oracle/product/9.2.0"
Pfile = "/swbase/app/oracle/product/9.2.0/dbs/initappDB0.ora"
)
Sqlnet appDB0-lsnr (
Critical = 0
Owner = oracle
Home = "/swbase/app/oracle/product/9.2.0"
TnsAdmin = "/swbase/app/oracle/product/9.2.0/network/admin"
Listener = lsnr_appDB0
)
Volume appDB0-vol (
Volume = appDB0
DiskGroup = appDB0
)
appDB0-vol requires appDB0-dg
appDB0-lsnr requires appDB0-ora
Titolo: Amministrazione di Veritas ClusterServer
Livello: Esperto
Data:
1 Novembre 2000
Versione: 1.0.26 - 14 Febbraio 2018
Autore: mail [AT] meo.bogliolo.name