Le risorse, come tutti gli altri elementi che compongono
un VCS, sono definite con una logica ad oggetti.
Una risorsa viene definita attraverso i sui attributi (attribute).
Gli attributi sono differenti
a seconda del tipo di risorsa.
I tipi di risorse sono parecchi e possono essere arricchiti
con l'installazione di agenti specifici (eg. Oracle Agent, SAP agent, ...).
I tipi piu' comuni sono:
Application
DiskGroup
Volume
Mount
IP
IPMultiNIC
Oracle
Sqlnet ... il cui nome dovrebbe essere indicativo!
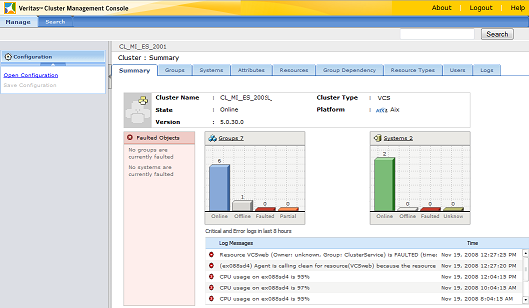
Un'interfaccia simile e' disponibile come
web application (vcs o cmc a seconda delle versioni/opzioni):
Il cluster controlla l'effettivo funzionamento
di ogni systema, di ogni gruppo ed ogni risorsa mediante un
agent specifico che effettua un probe su ogni
risorsa abilitata (stato di enable). Se si verifica un
fault su una risorsa definita critical il cluster cerca di
riattivarla eventualmente effettuando un switch su un differente
system.
Per controllare il corretto funzionamento di VCS
si utilizza il comando:
La situazione riportata indica che il cluster
e' attivo, e' costituito da due sistemi entrambe attivi (RUNNING).
I sistemi possono essere anche in stato UNKNOWN quando,
per esempio, il software di cluster non e' attivo;
in stato di STARTING quando si stanno riattivando;
in stato di REMOTE_BUILD quando si stanno ricostruiendo la
struttura.
Sul cluster sono presenti tre seervizi o, con la terminologia
VCS, tre gruppi: moon01, moon02, moon03.
I gruppi sono attivi (ONLINE)su uno dei due sistemi e, ovviamente
OFFLINE sull'altro.
Un gruppo puo' anche essere in stato PARTIAL quando e' attivo
ma qualche risorsa che gli appartiene, per qualsiasi ragione,
non e' ONLINE.
Nella situazione riportata dal comando non sono visualizzate
le singole risorse poiche' queste sono tutte in stato
di ONLINE o OFFLINE. Nel caso in cui vi fossere risorse
su cui il cluster ha trovato un errore queste vengono
visualizzate con l'indicazione di FAILED.
Nel caso invece in cui le risorse fossere in attivazione/disattivazione
queste vengono riportate con lo stato di W_ONLINE/W_OFFLINE.
I log di tutte le attivita' svolte dal cluster sono mantenute in un file di log
il cui riferimento si ottiene con halog -info
[NdA tipicamente e' il file /var/VRTSvcs/log/engine_A.log].
Per controllare il corretto funzionamento della
connessione in Heartbeat dei sistemi si utilizza il comando:
La situazione riportata indica che il cluster
e' attivo ed e' costituito da due sistemi entrambe attivi.
I comandi seguenti effettuano il
fermo del primo servizio, lo switch del secondo e controllano
la nuova situazione:
La situazione riportata indica che il gruppo moon01 non
e' attivo ed i rimanenti gruppi sono ONLINE su saturno.
A questo punto su giove non vi sono piu' gruppi attivi ed e'
possibile, per esempio, effettuare un intervento sistemistico
sul sistema.
La configurazione di VCS puo' essere effettuata
in tre differenti modi:
Queste sono le modalita' consigliate... ma vi ho detto che erano tre!
La configurazione viene mantenuta anche sul file
/etc/VRTSvcs/conf/config/main.cf
su cui si puo' agire direttamente seguendo le corrette operative.
Tuttavia tale modalita' e' rischiosa e viene quindi adottata solo
in casi particolari.
Maggiori dettagli tecnici
su VCS possono essere trovati sul documento
Amministrazione di Veritas Cluster.
Le risorse sono legate tra loro da vincoli di precedenza
detti link.
Ad esempio non e' possibile montare un file system se
il volume su cui si appoggia non e' stato importato
dal sistema.
Per descrivere questo con VCS e' necessario creare un link
che descriva la
dipendenza tra le due risorse coinvolte (le risorse saranno di tipo
Mount e Volume).
I link tra tutte le risorse e' uno (o piu') grafi orientati.
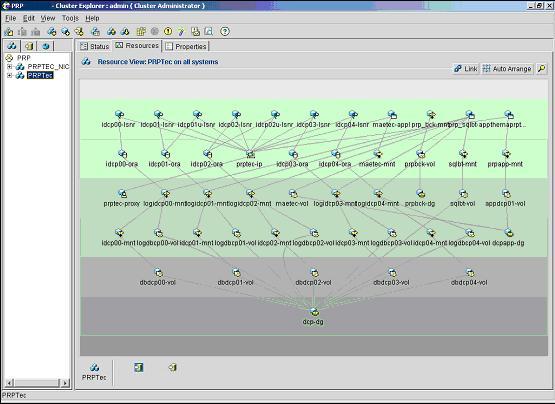
Con il comando hagui o con l'interfaccia grafica
client su PC (ClusterManager)
e' possibile controllare e gestire
tutti i servizi e le risorse del cluster:
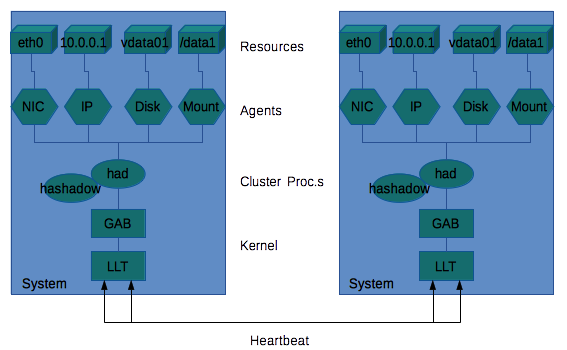
I nodi sono in connessione continua mediante un protocollo
di comunicazione specifico LLT che mantiene la
connessione di Heartbeat.
Nel caso in cui un sistema cada gli altri sistemi ne
prendono in carico i servizi.
# hastatus -sum
-- SYSTEM STATE
-- System State Frozen
A giove RUNNING 0
A saturno RUNNING 0
-- GROUP STATE
-- Group System Probed AutoDisabled State
B moon01 giove Y N ONLINE
B moon01 saturno Y N OFFLINE
B moon02 giove Y N ONLINE
B moon02 saturno Y N OFFLINE
B moon03 giove Y N OFFLINE
B moon03 saturno Y N ONLINE
# lltstat -nvv
LLT node information:
Node State Link Status Address
0 saturno OPEN
lan2 UP 00:33:6A:46:2C:78
lan9 UP 00:33:6A:46:2B:98
* 1 giove OPEN
lan2 UP 00:33:6A:46:1C:A8
lan9 UP 00:33:6A:46:2D:AD
2 CONNWAIT
...
# hagrp -offline moon01 -sys giove
# hagrp -switch moon02 -to saturno
# hastatus -sum
-- SYSTEM STATE
-- System State Frozen
A giove RUNNING 0
A saturno RUNNING 0
-- GROUP STATE
-- Group System Probed AutoDisabled State
B moon01 giove Y N OFFLINE
B moon01 saturno Y N OFFLINE
B moon02 giove Y N OFFLINE
B moon02 saturno Y N ONLINE
B moon03 giove Y N OFFLINE
B moon03 saturno Y N ONLINE
Data: 6 Novembre 2003
Versione: 1.0.6
Autore: mail@meo.bogliolo.name