TimescaleDB
TimescaleDB
e' un Time Series Database Open Source che utilizza l'SQL standard.
Dal punto di vista tecnico TimescaleDB
e' un'estensione di
PostgreSQL
sul quale vengono definite Hypertables partizionate in Chuncks.
Suona strano? Se volete saperne di piu'... continuate a leggere!
Il documento si riferisce alla versione 1.0 di TimescaleDB utilizzabile con le release 9.6 o 10
di PostgreSQL e successive ma i contenuti valgono anche per altre versioni
[NdA i contenuti sono aggiornati fino alla versione 2.0 2021-02].
Questo documento presenta diversi aspetti di TimescaleDB:
Introduzione,
Installazione,
Primi passi,
Query temporali,
Cenni sulle prestazioni,
Data Dictionary,
Versioni ed aggiornamenti,
...
con un approccio pratico con molti esempi di comandi e query SQL.
Su PostgreSQL un documento in italiano
e' Qualcosa in piu' su PostgreSQL,
mentre sul partizionamento
e' presente un capitolo in DIVIDE ET IMPERA !
Introduzione
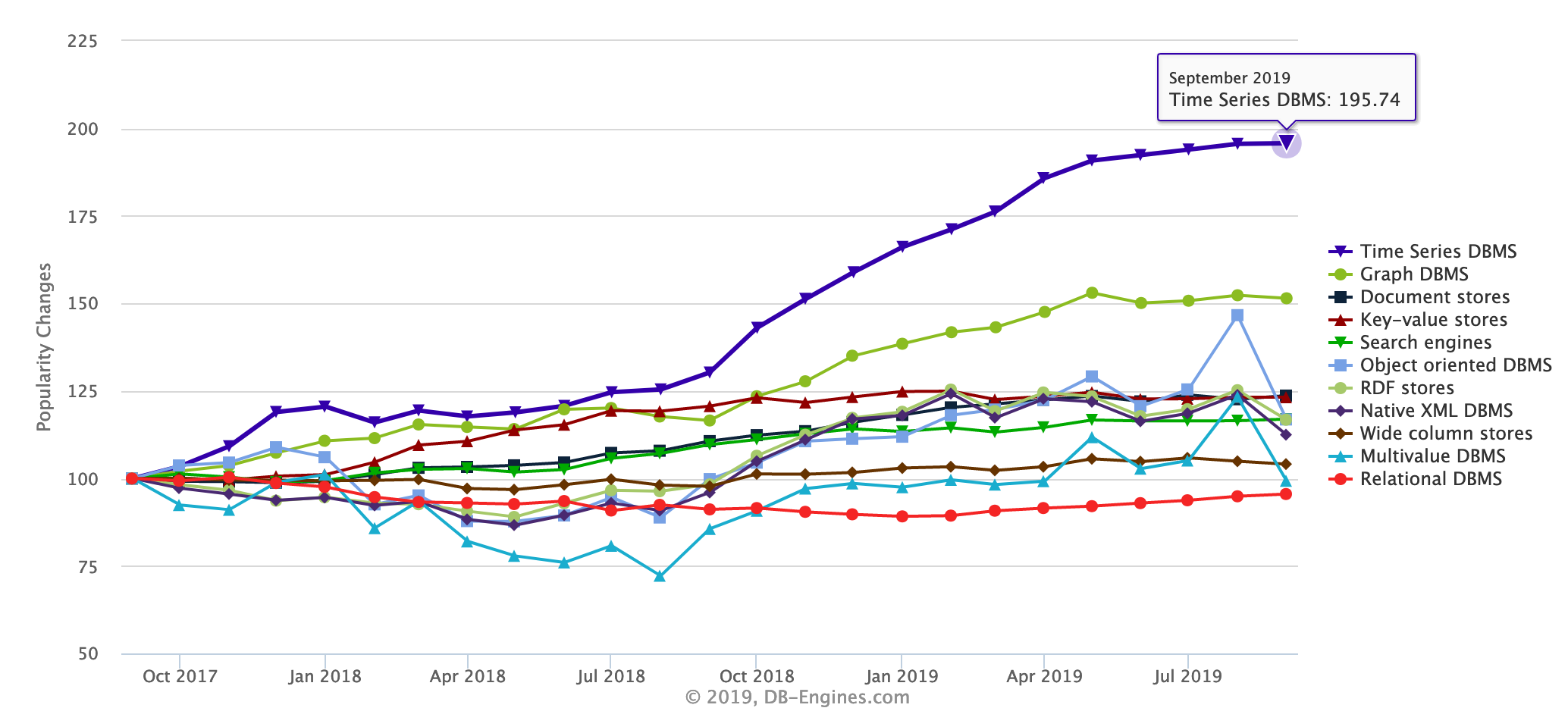 I Time Series Database (TSDB) sono una tecnologia emergente di questi ultimi anni
spinta dalla grande richiesta di memorizzazione delle informazioni per l'IoT
(Internet of Things)
[NdA immagine da db-engines.com].
I Time Series Database (TSDB) sono una tecnologia emergente di questi ultimi anni
spinta dalla grande richiesta di memorizzazione delle informazioni per l'IoT
(Internet of Things)
[NdA immagine da db-engines.com].
Tra i piu' famosi TSDB: InfluxDB, Graphite, Prometheus, KairosDB, ...
Tutti hanno un'architettura ottimizzata per la raccolta massiva di dati in serie
temporali e la loro analisi;
sono database NoSQL con linguaggi di interrogazione specifici.
TimescaleDB ha scelto un approccio differente
perche' nasce come estensione di Postgres
e quindi ne eredita tutte le funzionalita' native:
un completo linguaggio SQL,
una comprovata robustezza,
funzionalita' ed estensioni molto avanzate (eg. PostGIS), ...
Con tabelle di elevate dimensioni gli indici B-Tree utilizzati in PostgreSQL
presentano problemi di scalabilita'.
 Infatti quando gli indici superano la dimensione della memoria disponibile
e' necessario effettuare operazioni di IO per mantenerne la struttura.
Questo rende Postgres, ed in generale i database relazionali,
meno performanti rispetto ad altri database NoSQL
nella gestione dei dati su serie temporali.
Infatti quando gli indici superano la dimensione della memoria disponibile
e' necessario effettuare operazioni di IO per mantenerne la struttura.
Questo rende Postgres, ed in generale i database relazionali,
meno performanti rispetto ad altri database NoSQL
nella gestione dei dati su serie temporali.
TimescaleDB risolve questo problema partizionando le tabelle temporali sul tempo
(ed eventualmente sullo spazio utilizzando le ulteriori dimensioni presenti).
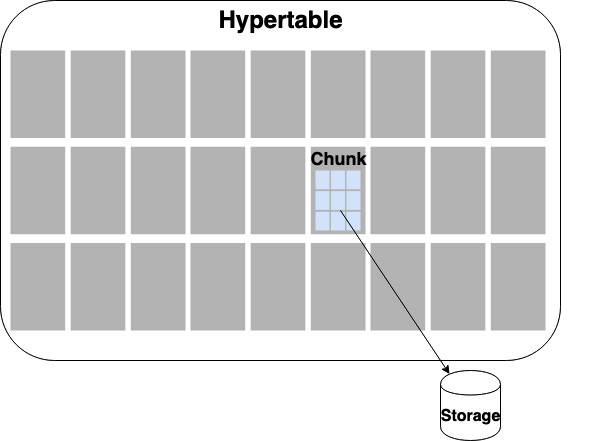
Una tabella o relazione Postgres che contiene Time Series viene trasformata in Hypertable
in TimescaleDB.
Le Hypertables sono utilizzabili dagli utenti senza alcuna differenza rispetto alle altre tabelle
nelle normali clausole SQL.
E' naturalmente possibile avere piu' hypertables nello stesso database
e tutte possono essere accedute in join con le altre normali tabelle.
Dal punto di vista fisico le Hypertable
sono memorizzate in Chunck di dimensioni ottimizzate.
Seplificando molto e' come se dal punto di vista fisico ogni chunk
fosse una relation Postgres.
L'organizzazione in chunk consente di utilizzare indici di dimensione limitata
e di mantenere sempre in memoria i chunk attivi.
L'ottimizzatore sfrutta in modo molto aggressivo il partizionamento
operando in memoria su indici di modeste dimensioni ed allocando
nuovi chunk via via che vengono riempiti di dati.
E' infatti una caratteristica comune delle time series
che le insert avvengano in modo massivo,
che vengano svolti pochissimi update su dati gia' presenti
e che i dati vengano analizzati e confrontati per gruppi temporali.
Oltre al partizionamento
TimescaleDB introduce inoltre una serie di funzioni di analisi dei dati
specifiche per la dimensione temporale.
Installazione
TimescaleDB richiede PostgreSQL 9.6.3+ or 10.2+.
Una volta effettuata l'installazione di Postgres
l'installazione di TimescaleDB e' semplice... soprattutto con gli RPM!
Ad esempio sulla distribuzione CentOS 7.x, trovato l'RPM con
yum search timescaledb lo si installa con
yum install timescaledb_96.
Per utilizzare le versioni piu' aggiornate e' possibile scaricare
le versioni pubblicate su timescalereleases con seguenti comandi:
# PostgreSQL 9.6
### wget https://timescalereleases.blob.core.windows.net/rpm/timescaledb-1.0.0-postgresql-9.6-0.x86_64.rpm
# PostgreSQL 10
wget https://timescalereleases.blob.core.windows.net/rpm/timescaledb-1.0.0-postgresql-10-0.x86_64.rpm
# Installazione
yum install timescaledb
E' richiesta una sola configurazione ulteriore nel file postgres.conf:
shared_preload_libraries = 'timescaledb'
Naturalmente e' necessario riavviare il server per far caricare la libreria.
Ora il server Postgres e' configurato ed e' possibile creare l'extension TimescaleDB
su ogni database su cui e' necessario con:
CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;
...
WELCOME TO
_____ _ _ ____________
|_ _(_) | | | _ \ ___ \
| | _ _ __ ___ ___ ___ ___ __ _| | ___| | | | |_/ /
| | | | _ ` _ \ / _ \/ __|/ __/ _` | |/ _ \ | | | ___ \
| | | | | | | | | __/\__ \ (_| (_| | | __/ |/ /| |_/ /
|_| |_|_| |_| |_|\___||___/\___\__,_|_|\___|___/ \____/
Running version 0.12.0
For more information on TimescaleDB, please visit the following links:
1. Getting started: https://docs.timescale.com/getting-started
2. API reference documentation: https://docs.timescale.com/api
3. How TimescaleDB is designed: https://docs.timescale.com/introduction/architecture
Note: TimescaleDB collects anonymous reports to better understand and assist our users.
For more information and how to disable, please see our docs https://docs.timescaledb.com/using-timescaledb/telemetry.
Ora sono disponibili le nuove funzioni di TimescaleDB!
Come verificare la versione di TimescaleDB installata?
SELECT extname, extversion FROM pg_extension WHERE extname='timescaledb';
SELECT * FROM _timescaledb_internal.get_git_commit();
TimescaleDB e' disponibile anche su altre piattaforme come MS-Windows e su
Mac.
Primi passi
L'utilizzo di TimescaleDB e' semplicemente... una serie di comandi SQL:
CREATE TABLE measurements (
time TIMESTAMPTZ NOT NULL,
device_id TEXT NOT NULL,
temperature DOUBLE PRECISION NULL,
humidity DOUBLE PRECISION NULL
);
SELECT create_hypertable('measurements', 'time');
INSERT INTO measurements(time, device_id, temperature, humidity)
VALUES (NOW(), 'HAL2001', 36.5, 50.0);
SELECT time_bucket('10 seconds', time) AS ten_second,
device_id, avg(temperature) AS "avgT",
min(temperature) AS "minT",
max(temperature) AS "maxT",
last(temperature, time) AS "lastT"
FROM measurements
GROUP BY ten_second, device_id
ORDER BY ten_second DESC LIMIT 20;
A tutti gli effetti non vi sono differenze nell'interrogare
normali tabelle PostgreSQL rispetto ad Hypertable TimescaleDB:
si utilizzano le stesse clausole SQL.
La differenza e' nella struttura dati e nell'ottimizzatore che accede ai chunck.
TimescaleDB introduce alcune funzioni che consentono
di gestire o di interrogare in modo efficiente i dati temporali.
Una funzione l'abbiamo gia' vista: time_bucket()!
Nei prossimi paragrafi approfondiremo con maggior dettaglio quanto visto con semplici esempi.
Query temporali
Un grande vantaggio di TimescaleDB e' che supporta l'SQL di Postgres
in tutte le sue funzionalita': dalle quelle piu' semplici (join, indici secondari, ...)
[NdA disponibili su tutti i relazionali ma assenti su molti database NoSQL]
alle features piu' avanzate
(funzioni statistiche,
CTE,
windows functions,
...)
[NdA disponibili solo sui database relazionali piu' completi ed in PostgreSQL dalla versione 8.4].
Nel seguito vediamo gli aspetti piu' interessanti di TimescaleDB con esempi pratici:
-- Hypertable con 8 hash partitions su device_id, chunck di due settimane (il default e' 1 week) e dati
SELECT create_hypertable('measurements', 'time', 'device_id', 8,
chunk_time_interval => interval '2 weeks' , migrate_data => true);
-- Cancellazione efficiente dei dati piu' vecchi di 6 mesi
SELECT drop_chunks(interval '6 months', 'measurements');
-- Raggruppamento sul timezone locale (senza il cast viene utilizzato UTC)
SELECT time_bucket('1 hour', time::TIMESTAMP) AS one_hour,
device_id, avg(temperature) AS "avgT",
min(temperature) AS "minT",
max(temperature) AS "maxT",
last(temperature, time) AS "lastT"
FROM measurements
GROUP BY one_hour, device_id
ORDER BY one_hour DESC LIMIT 20;
-- Query differenziale (eg. traffico di rete ultimo giorno)
SELECT time, bytes_sent - lag(bytes_sent) OVER w AS bytes
FROM net
WHERE interface = 'eth0'
AND time > NOW() - interval '1 day'
WINDOW w AS (ORDER BY time)
ORDER BY 1;
-- Query con scala logaritimica
SELECT period,
temp / lead(temp) OVER data AS temp_rise_linear,
log(temp / lead(temp) OVER data) AS temp_rise_log
FROM ( SELECT time_bucket('10 seconds', time) AS ten_second,
last(temp, time) AS temp
FROM measurements JOIN devices ON measurements.device_id = devices.id
WHERE devices.type = 'ceiling'
AND measurements.time >= '2018-02-14'
GROUP BY 1
ORDER BY 1 ) sub window data
AS (ORDER BY ten_second asc);
-- Minimi, massimi, prime ed ultime quotazioni per giorno
SELECT time_bucket('1 day', time) AS period, asset_code,
first(price, time) AS opening, last(price, time) AS closing,
max(price) AS high, min(price) AS low
FROM prices
WHERE time > NOW() - interval '7 days'
GROUP BY period, asset_code
ORDER BY period DESC, asset_code;
-- Funzioni di utilita': utilizzo di spazio
SELECT chunk_table, table_size, index_size, toast_size, total_size
FROM chunk_relation_size_pretty('measurements');
SELECT table_size, index_size, toast_size, total_size
FROM hypertable_relation_size_pretty('measurements');
Ulteriori esempi sono riportati nella
documentazione ufficiale.
Continuous Aggregates
I Continuous Aggregates di TimescaleDB sono simili alle
Materiazed Views di PostgreSQL ma i contenuti vengono
aggiornati in modo incrementale.
Dal punto di vista prestazionale i vantaggi sono molto elevati
poiche' l'aggregazione viene eseguita automaticamente
e si accede ai soli dati consolidati.
Vediamo un esempio [NdA sintassi aggiornata alla versione 2.0]:
CREATE MATERIALIZED VIEW measure_1h
WITH (timescaledb.continuous) AS
SELECT time_bucket('1 hour', time::TIMESTAMP) AS one_hour,
device_id, avg(temperature) AS "avgT",
min(temperature) AS "minT",
max(temperature) AS "maxT",
last(temperature, time) AS "lastT"
FROM measurements
GROUP BY one_hour, device_id;
SELECT add_continuous_aggregate_policy('measure_1h',
start_offset => INTERVAL '1 month',
end_offset => INTERVAL '1 h',
schedule_interval => INTERVAL '1 h');
Una volta create i Continuous Aggregates vengono utilizzate nelle SELECT
come normali viste.
E' possibile eseguire manualmente un refresh dei dati con
CALL refresh_continuous_aggregate('measure_1h', '2020-06-01', '2021-01-01');
a differenza di una comune vista materializzata verra' analizzato solo il periodo indicato
e non l'intero contenuto della vista.
Cenni sulle prestazioni
Una volta installato TimescaleDB puo' essere utilizzato immediatamente.
Rispetto ad una configurazione standard PostgreSQL non vi sono parametri
particolari su cui effettuare il tuning.
Naturalmente un processore veloce ed una grande quantita' di memoria
consentono buone prestazioni anche con DB di grandi dimensioni e query complesse.
E' molto importante che gli indici B-Tree dei chunk attivi siano mantenuti i memoria.
Come indicazione di massima gli indici attivi non debbono superare il 25% della memoria del sistema.
Per un sistema Linux con 16GB di RAM dedicato a PostgreSQL una
configurazione iniziale (da impostare nel file postgresql.conf) e' la seguente:
listen_addresses = '*'
max_connections = 200
shared_buffers = 4GB
effective_cache_size = 12GB
maintenance_work_mem = 2GB
checkpoint_completion_target = 0.9
wal_buffers = 16MB
default_statistics_target = 500
random_page_cost = 1.1
effective_io_concurrency = 300
work_mem = 5242kB
min_wal_size = 4GB
max_wal_size = 8GB
max_worker_processes = 8
max_parallel_workers_per_gather = 2
max_parallel_workers = 4
timescaledb.max_background_workers = 4
shared_preload_libraries = 'timescaledb,pg_stat_statements'
### synchronous_commit = 'off'
### max_locks_per_transaction = 2 * num_chunks
### timescaledb.telemetry_level=off
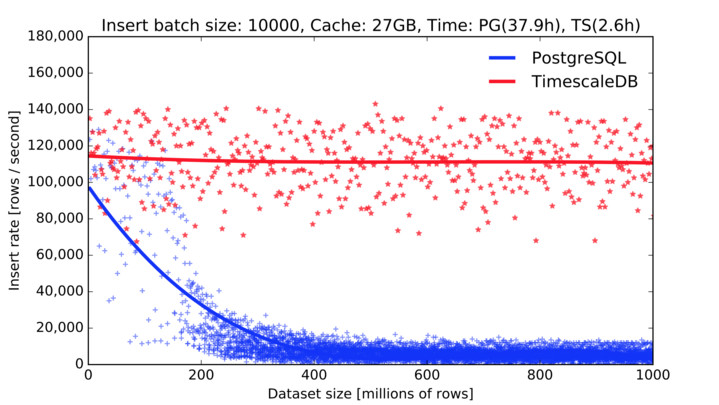
Con questa configurazione le prestazioni di TimescaleDB consentono di effettuare caricamenti
massivi di ordini di grandezza superiori ad un normale PostgreSQL.
Rispetto ad altri database NoSQL l'efficienza e' tale che un solo server TimescaleDB e' sufficiente per
effettuare i tutti i caricamenti e si puo' utilizzare la streaming replication
per scalare anche sulle attivita' in lettura.
Data Dictionary
Oltre al normale ed esaustivo Data Dictionary di PostgreSQL (eg. pg_class)
TimescaleDB mantiene un proprio catalogo con una trentina
di tabelle con tutte le definizioni delle Hypertables.
Ecco le piu' significative:
- _timescaledb_catalog.hypertable
- _timescaledb_catalog.chunk
- _timescaledb_catalog.chunk_index
- _timescaledb_catalog.chunk_constraint
- _timescaledb_catalog.dimension
- _timescaledb_catalog.dimension_slice
Tra le funzioni disponibili sono sicuramente utili: chunk_relation_size() e
chunk_relation_size_pretty() dall'ovvio utilizzo.
Dalla versione 1.1 e' disponibile un utile comando per il tuning delle strutture timescaleDB:
timescaledb-tune --quiet --yes
Teoricamente il comando e' ancora in Beta... pero' sembra funzionare benissimo!
Versioni ed upgrade
Mantenersi aggiornati con le versioni e' sempre importante... [NdE: serve a rimanere giovani e tutto e' piu' veloce :-]
Questo vale anche per TimescaleDB e per il suo ospite: il database PostgreSQL.
La versione di TimescaleDB su cui e' stato prodotto inizialmente questo documento e' la 0.12 [NdA 2018-09]
che introduce la funzionalita' di scheduling.
TimescaleDB 0.x richiede le versioni 9.6.2 o 10.2 di PostgreSQL o successive,
la versione piu' recente e' la 2.0 ed puo' essere utilizzata nelle versioni 11 o 12 di PostgreSQL.
Le versioni di TimescaleDB sono disponibili in linea su
Git.
Nel documento Your Server Stinks
sono mantenute apposite sezioni aggiornate per
PostgreSQL
e TimescaleDB:
(Sources: Git
TimescaleDB)
| Version |
Status |
Features |
Last release |
Date (from) |
Date (last) |
Notes |
| 2.0 | Production |
Elastic clustering, distribuited hypertables, manual refresh on continuos aggregates.
PG11 required. Many entereprise features now free.
| 2.0.0 | 2021-02 | |
|
| 1.0 | Production |
Production release. Bucket time epoch on Monday January 3, 2000.
(1.1 2018-12): several optimizations. Beta support for PG11 and timescale-tune.
(1.2 2019-01): Full support for PG11, time-series analytical functions,
data reordering (reorder_chunk()).
Commercial license: automated data lifecycle management (add_reorder_policy(), add_drop_chunks_policy()).
Deprecation: adaptive chunking.
(1.3 2019-05): continuous aggregates.
(1.4 2019-06): multiple continuous aggregates, ChunkAppend.
(1.5 2019-10): native compression (requires PG10+), data tiering.
(1.6 2020-01): allow drop_chunks while keeping continuous aggregates.
(1.7 2020-04): PG12 support; deprecation for PG9.6, PG10.
| 1.7.4 | 2018-10 | 2020-07 |
|
| 0.x | Production |
First production release. ALTER EXTENSION upgrade.
Requires PostgreSQL 9.6.2 or 10.2.
(0.2.0 2017-07): Trigger support on hypertables.
(0.7.0 2017-11): Postgres 10 support.
(0.8.0 2017-12): Windows support.
(0.9.0 2018-03): Different extension versions on different databases.
(0.11.0 2018-08): Adaptive chunking.
(0.12.0 2018-09): Scheduler, telemetry usage information.
| 0.12.1 | 2017-06 | 2018-09 |
|
| 0.0.x | Development | First releases...
| 0.0.12-beta | 2017-03 | 2017-06 |
|
Alcune funzionalita' di TimescaleDB sono disponibili solo come edizione Enterprise
(eg. Data Retention Policies),
ma la maggioranza dei componenti sono disponibili con le licenze Open Source (Apache 2.0)
o Community.
Varie ed eventuali
TimescaleDB e' supportato da moltissimi strumenti di interrogazione SQL, analisi dati, BI, ...
semplicemente perche' gia' supportano PostgreSQL.
Tra i molti anche Grafana che, dalla
versione 5.3 ha anche uno specifico flag
per richiamarne le funzioni native (eg. time_bucket).
Al momento TimescaleDB opera su un server singolo
(anche se e' ovviamente possibile scalare orizzontalmente in lettura
con la streaming replication di PostgreSQL);
e' previsto in futuro lo scale out su piu' server.
Breaking news: TimescaleDB Cluster,
ora anche in produzione [NdA 2021-02]!