TimescaleDB Cluster
TimescaleDB
e' un Time Series Database Open Source basato su
PostgreSQL.
In questa pagina vediamo un'importante nuova funzionalita' di TimescaleDB
che consente di creare un cluster di nodi per scalare orrizzontalmente al
crescere dei dati raccolti.
In pratica con TimescaleDB 2.0 e' possibile definire hypertable distribuite su piu' nodi.
Questo documento presenta diversi aspetti di TimescaleDB Cluster:
Architettura,
Installazione,
Creazione Cluster ed utilizzo,
Cenni sulle prestazioni,
Varie ed eventuali,
...
con un approccio pratico con esempi di comandi e query SQL.
Il documento e' stato preparato con la versione Private Beta di TimescaleDB Clustering
utilizzabile con le release 11
di PostgreSQL, ma i contenuti valgono anche per le future versioni
[NdE la versione 2.0 di TimescaleDB disponibile in produzione dal 2021-02
contiene la funzionalita' di distribuited hypertable come descritta in questa pagina].
Architettura
I Time Series Database (TSDB) sono una tecnologia emergente di questi ultimi anni
spinta dalla grande richiesta di memorizzazione delle informazioni per l'IoT.
 TimescaleDB nasce come estensione di Postgres
e quindi ne eredita tutte le funzionalita' native:
un completo linguaggio SQL,
una comprovata robustezza,
funzionalita' ed estensioni molto avanzate (eg. PostGIS), ...
TimescaleDB nasce come estensione di Postgres
e quindi ne eredita tutte le funzionalita' native:
un completo linguaggio SQL,
una comprovata robustezza,
funzionalita' ed estensioni molto avanzate (eg. PostGIS), ...
TimescaleDB rende molto piu' efficienti che in PostgreSQL le tabelle Time-Series
creando delle partizioni basate sul tempo ed eventualmente anche su altre colonne.
Una tabella o relazione Postgres che contiene una colonna temporale
viene trasformata in Hypertable con la funzione create_hypertable() di TimescaleDB.
Le Hypertables sono utilizzabili dagli utenti senza alcuna differenza rispetto alle altre tabelle
nelle normali clausole SQL.
E' naturalmente possibile avere piu' hypertables nello stesso database
e tutte possono essere accedute in join con le altre normali tabelle.
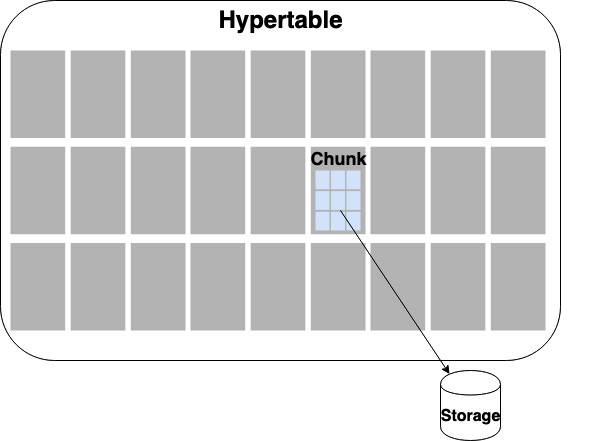
Dal punto di vista fisico le Hypertable
sono memorizzate in Chunck di dimensioni ottimizzate
e gestite in modo automatico.
 Con la versione Clustering il concetto di Hypertable e di Chunk
viene esteso distribuendo i Chunk su piu' nodi in modo elastico.
Con la versione Clustering il concetto di Hypertable e di Chunk
viene esteso distribuendo i Chunk su piu' nodi in modo elastico.
L'architettura e' semplice e prevede due tipi di nodi:
- Access Node: e' il nodo cui si collegano gli utenti e che conosce
come sono distribuiti i dati. Puo' ospitare normali tabelle PostgreSQL
ed Hypertable locali oltre alle Hypertable distribuite.
- Data Node: sono i nodi su cui vengono memorizzati i dati.
I Data Node ospitano i Chunk delle Hypertables e non possono essere utilizzati
direttamente dagli utenti poiche' darebbero risultati incompleti o inconsistenti.
In un cluster sono necessari almeno un Access Node ed un Data Node;
tipicamente sono pero' presenti piu' Data Node.
Tutti i nodi indistintamente utilizzano un DB PostgreSQL con l'estension TimescaleDB.
Le Distribuited Hypertables vengono create dal punto di vista logico sull'Access Node
e vengono ospitate sui Data Node; per accedere ai dati si utilizza il
Foreign Data Wrapper timescaledb_fdw.
Gli utenti si collegano solo all'Access Node e tutte le query debbono eseguite dall'Access Node.
Non e' corretto eseguire query sui Data Node. I risultati possono essere parziali o non consistenti.
Dal punto di vista funzionale non vi sono differenze di rilievo tra le normali Hypertables
ospitate sull'Access Node e le Distribuited Hypertable...
la principale differenza e' che i dati delle Distribuited Hypertable sono memorizzati
in remoto sui Data Node.
Il Cluster TimescaleDB e' elastico: se vengono aggiunti nuovi Data Node i chunk
di nuova creazione
verranno distruibuiti su tutti i nodi disponibili scalando quindi immediatamente
le attivita' in scrittura.
Installazione
 TimescaleDB Clustering attualmente dispone di due modalita' di installazione:
TimescaleDB Clustering attualmente dispone di due modalita' di installazione:
- Binary Packages (for Linux)
- Helm Charts (for Kubernetes)
Per Linux i requisiti minimi sono
PostgreSQL 11 come DB e RHEL/CentOS 7, Debian 9/10 o Ubuntu 18.04 come OS.
Ad esempio il file di repository per la ricerca degli RPM in CentOS e':
[timescale_timescaledb-exp]
name=timescale_timescaledb-exp
baseurl=https://packagecloud.io/timescale/timescaledb-exp/el/7/\$basearch
repo_gpgcheck=1
gpgcheck=0
enabled=1
gpgkey=https://packagecloud.io/timescale/timescaledb-exp/gpgkey
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
metadata_expire=300
Sicuramente interessante e' anche l'installazione con K8s.
Sono richiesti AWS EKS, GKE o Minikube.
Per default vengono installati un Access Node e tre pod con i Data Node,
ma ovviamente e' possibile modificare facilmente la configurazione del file .yaml.

Vediamo in dettaglio i passi dell'installazione su Mac con minikube:
brew install ... helm init --wait
timescaledb-multinode me$ minikube start
😄 minikube v1.5.0 on Darwin 10.14.6
💡 Tip: Use 'minikube start -p ' to create a new cluster, or 'minikube delete' to delete...
🏃 Using the running hyperkit "minikube" VM ...
⌛ Waiting for the host to be provisioned ...
🐳 Preparing Kubernetes v1.16.2 on Docker 18.09.9 ...
🔄 Relaunching Kubernetes using kubeadm ...
⌛ Waiting for: apiserver proxy etcd scheduler controller dns
🏄 Done! kubectl is now configured to use "minikube"
timescaledb-multinode me$ helm install --name my-tsdbclu .
Immagine da GitHub
I valori di default sono limitati, anche per consentire un deploy anche su minikube,
ma e' possibile personalizzarli nel file values.yaml.
Ecco un esempio con alcuni parametri evidenziati:
dataNodes: 3
...
postgresql:
databases:
- postgres
- example
parameters:
max_connections: 100
max_prepared_transactions: 150
shared_buffers: 300MB
work_mem: 16MB
timescaledb.passfile: '../.pgpass'
log_connections: 'on'
log_line_prefix: "%t [%p]: [%c-%l] %u@%d,app=%a [%e] "
log_min_duration_statement: '1s'
log_statement: ddl
log_checkpoints: 'on'
log_lock_waits: 'on'
min_wal_size: 256MB
max_wal_size: 512MB
temp_file_limit: 1GB
Quando funziona tutto:
NAME: my-tsdbclu
LAST DEPLOYED: Sun Oct 23 17:13:69 2019
NAMESPACE: default
STATUS: DEPLOYED
RESOURCES:
==> v1/Job
NAME COMPLETIONS DURATION AGE
attachdn-my-tsdbclu-db0-data0 0/1 2s 2s
attachdn-my-tsdbclu-db0-data1 0/1 2s 2s
attachdn-my-tsdbclu-db0-data2 0/1 2s 2s
attachdn-my-tsdbclu-db1-data0 0/1 2s 2s
attachdn-my-tsdbclu-db1-data1 0/1 2s 2s
attachdn-my-tsdbclu-db1-data2 0/1 2s 2s
createdb-my-tsdbclu-db0 0/1 2s 2s
createdb-my-tsdbclu-db1 0/1 2s 2s
==> v1/Pod(related)
NAME READY STATUS RESTARTS AGE
attachdn-my-tsdbclu-db0-data0-6gtc8 0/1 Pending 0 2s
attachdn-my-tsdbclu-db0-data1-bzrzd 0/1 ContainerCreating 0 2s
attachdn-my-tsdbclu-db0-data2-kbdw6 0/1 ContainerCreating 0 2s
attachdn-my-tsdbclu-db1-data0-g2pvh 0/1 ContainerCreating 0 2s
attachdn-my-tsdbclu-db1-data1-rzqcm 0/1 ContainerCreating 0 2s
attachdn-my-tsdbclu-db1-data2-wztb9 0/1 ContainerCreating 0 2s
createdb-my-tsdbclu-db0-lwgws 0/1 ContainerCreating 0 2s
createdb-my-tsdbclu-db1-x8wdj 0/1 ContainerCreating 0 2s
my-tsdbclu-timescaledb-access-0 0/1 Pending 0 2s
my-tsdbclu-timescaledb-data-0 0/1 Pending 0 2s
==> v1/Secret
NAME TYPE DATA AGE
my-tsdbclu-timescaledb-access Opaque 1 2s
my-tsdbclu-timescaledb-data Opaque 1 2s
==> v1/Service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-tsdbclu-timescaledb LoadBalancer 5432:30917/TCP 2s
my-tsdbclu-timescaledb-data ClusterIP None 5432/TCP 2s
==> v1/ServiceAccount
NAME SECRETS AGE
my-tsdbclu-timescaledb 1 2s
==> v1/StatefulSet
NAME READY AGE
my-tsdbclu-timescaledb-access 0/1 2s
my-tsdbclu-timescaledb-data 0/3 2s
Una volta installato TimescaleDB su tutti i nodi e' possibile
creare il cluster partendo dall'Access Node.
Creazione cluster ed utilizzo
Una volta installato TimescaleDB su tutti i nodi e' possibile
creare il cluster partendo dall'Access Node
[NdA con l'installazione da K8s un cluster in realta' e' gia' disponibile nel database example]:
SELECT add_data_node('data_node1', host => 'tsdb-dn1.xenialab.it');
SELECT add_data_node('data_node2', host => 'tsdb-dn2.xenialab.it');
Ora che il cluster e' costituito e' gia' possibile utilizzarlo creando un hypertable
in modo analogo a come si fa su un nodo singolo.
A differenza della configurazione con un singolo nodo conviene tuttavia
almeno un'altra chiave di partizionamento:
CREATE TABLE measurements (
time TIMESTAMPTZ NOT NULL,
device_id TEXT NOT NULL,
location TEXT NOT NULL,
temperature DOUBLE PRECISION NULL,
humidity DOUBLE PRECISION NULL
);
SELECT create_distributed_hypertable('measurements', 'time', 'location');
INSERT INTO measurements(time, device_id, location, temperature, humidity)
VALUES (NOW(), 'HAL2001', 'TORINO', 37.5, 69.0);
INSERT INTO measurements(time, device_id, location, temperature, humidity)
VALUES (NOW(), 'BOL6969', 'ACQUI', 74.5, 100);
SELECT time_bucket('10 seconds', time) AS ten_second,
device_id, avg(temperature) AS "avgT",
min(temperature) AS "minT",
max(temperature) AS "maxT",
last(temperature, time) AS "lastT"
FROM measurements
GROUP BY ten_second, device_id
ORDER BY ten_second DESC LIMIT 20;
Aggiungendo un nuovo nodo al cluster questi verra' utilizzato
per le nuove distributed hypertables ma non viene automaticamente
usato su quelle esistenti, se non richiesto esplicitamente come nell'esempio:
SELECT add_data_node('data_node3', host => 'tsdb-dn3.xenialab.it');
SELECT attach_data_node('data_node3', hypertable => 'measurements');
add_data_node effettua anche il Bootstrap del nodo ospite...
vi sono parametri per modificarne il comportamento ma
generalmente non serve modificare il default.
Con la stessa sintassi sono disponibili anche le funzioni
detach_data_node(), block_new_chunks(), allow_new_chunks() e delete_data_node().
Un Data Node puo' essere cancellato solo se non contiene piu' alcun dato
delle distributed hypertables.
Dal punto di vista di utilizzo non vi sono particolari
differenze rispetto alle normali
Hypertables con le Hypertables distribuite.
Le informazioni sullo stato del cluster sono mantenute nella vista
timescaledb_information.data_node.
La vista timescaledb_information.hypertable riporta le caratteristiche
di tutte le hypertables; per le hypertables distribuite vengono sommati
i valori di tutti i Data Node.
Cenni sulle prestazioni
L'ottimizzatore sfrutta in modo molto aggressivo il partizionamento
operando in memoria su indici di modeste dimensioni ed allocando
nuovi chunk via via che vengono riempiti di dati.
E' infatti una caratteristica comune delle time series
che le insert avvengano in modo massivo,
che vengano svolti pochissimi update su dati gia' presenti
e che i dati vengano analizzati e confrontati per gruppi temporali.
L'architettura in cluster permette lo scale-out quando una sola istanza
non e' piu' in grado di mantenere il carico richiesto.
Utilizzare un cluster quando e' ancora possibile scalare verticalmente
non e' conveniente dal punto di vista prestazionale.
Per le prestazioni sul cluster
e' molto importante che le Hypertable vengano partizionate anche su
una o piu' dimensioni spaziali.
Solo in questo modo la fase di INSERT risulta distribuita su chunk differenti.
In caso contrario verrebbe indirizzato un solo Data Node alla volta
[NdA non e' necessariamente sbagliato: un cluster puo' essere usato anche solo
per scalare come quantita' di spazio disponibile].
Per le partizioni spaziali TimescaleDB utilizza l'hashing.
Sulle query complesse o le INSERT massive
le prestazioni del Cluster TimescaleDB
scalano a seconda del numero di Data Node presenti
in modo quasi lineare.
Generalmente un solo Access Node e' sufficiente.
Varie ed eventuali
La versione utilizzata inizialmente in questo documento non era disponibile in produzione!
Prevista fin dall'inizio, annunciata
da qualche tempo
la versione 2.0 che contiene l'importante funzionalita' del Cluster
e' infatti stata disponibile come private beta [NdA 2019-10-23] per i primi test.
Mantenersi aggiornati con le versioni e' sempre importante...
[NdE: serve a rimanere giovani e tutto e' piu' veloce :-]
Questo vale anche per TimescaleDB e per il suo ospite PostgreSQL.
In attesa che la versione 2.0 sia disponibile
la versione ufficiale piu' recente di TimescaleDB e' la 1.4.2 [NdA 2019-10].
Dal 2021-01 la versione 2.0 di TimescaleDB e' disponibile in produzione per PostgreSQL 11 e 12.
Nel documento Your Server Stinks
sono mantenute apposite sezioni aggiornate per
PostgreSQL
e TimescaleDB.
Come tutti i database distribuiti anche il Cluster TimescaleDB
deve sottostare al teorema di CAP...
Il progetto ha deciso di limitare la A (availability):
in condizioni di rete degradata le funzionalita' non saranno disponibili.