Configurazione della replica in PostgreSQL
PostgreSQL
e' un potente DBMS relazionale Open Source noto per
la robustezza e la ricchezza di funzionalita'.
Questo documento descrive la configurazione in replica di due database PostgreSQL.
Questa configurazione e' adatta per garantire la massima disponibilita' dei dati
nelle configurazioni in HA (High Availability) e di DR (Disaster Recovery).
Tra le diverse alternative viene descritta la Streaming Replication
verso database configurati in Hot Standby e con la Cascading Replication.
Questo documento non e' introduttivo ed e' consigliato ad un pubblico informaticamente adulto...
Il documento ha un taglio pratico e, tra le diverse configurazioni possibili,
presenta un'unica soluzione;
per una documentazione completa della teoria e delle molteplici alternative
si rimanda alla
documentazione PostgreSQL ufficiale.
Un documento introduttivo su PostgreSQL
e' Introduzione a PostgreSQL,
un documento piu' completo e' Qualcosa in piu' su PostgreSQL
che contiene uno specifico capitolo sulla replica.
Alcuni importanti elementi sulla continuita' operativa per la basi dati sono riportati in
questo documento.
Introduzione
In questo breve documento una base dati PostgreSQL attiva su un nodo Primary
viene configurata per essere replicata su uno o piu' nodi secondari in Standby.
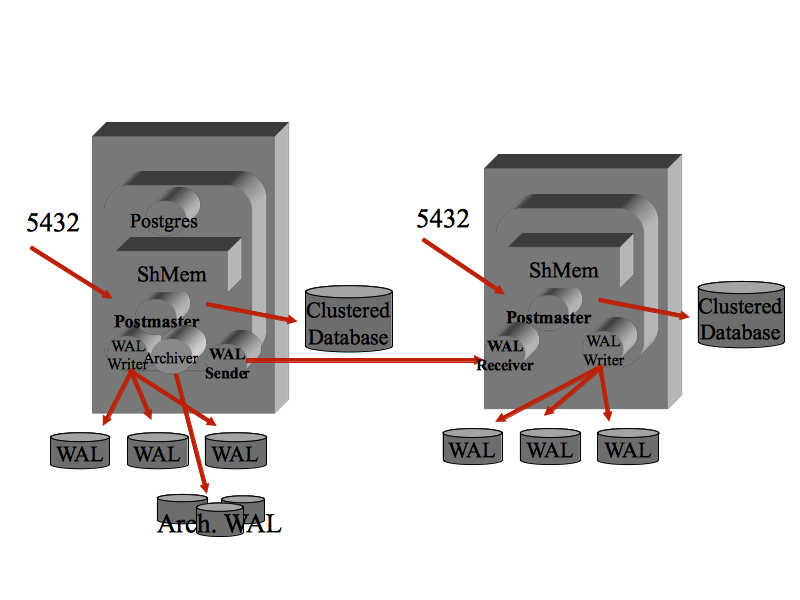 Vengono analizzate sia le configurazioni per
fornire l'alta affidabilita' (HA: High Availability)
con server posti nella stessa rete locale ed RPO e RTO molto bassi;
sia configurazioni addatte a garantire la continuita' operativa in caso di
disastro (DR: Disaster Recovery) con server posti su reti differenti a
distanza geografica. Naturalmente le configurazioni per DR hanno un RTO piu' elevato.
Vengono analizzate sia le configurazioni per
fornire l'alta affidabilita' (HA: High Availability)
con server posti nella stessa rete locale ed RPO e RTO molto bassi;
sia configurazioni addatte a garantire la continuita' operativa in caso di
disastro (DR: Disaster Recovery) con server posti su reti differenti a
distanza geografica. Naturalmente le configurazioni per DR hanno un RTO piu' elevato.
Le configurazioni presentate sono relative a PostgreSQL in versione 9.0 o successiva
ospitate su sistemi Linux Red Hat/CentOS/OEL in versione 5.x o successiva.
La cascading replication e' disponibile dalla versione 9.2
e lo switchover e' disponibile dalla versione 9.3:
e' sempre consigliato utilizzare una versione recente di PostgreSQL.
L'installazione di PostegreSQL e la sua configurazione di base non sono descritte.
I path utilizzati sono quelli di default e le configurazione di rete utilizzano IP privati.
I server utilizzati per la replica debbono avere la stessa versione di PostgreSQL e, possibilimente,
la stessa versione di sistema operativo. E' anche fortemente consigliato che utilizzino
gli stessi path, stessi utenti/gruppi, ...
PostgreSQL
Un breve accenno all'architettura di PostgreSQL puo' essere utile...
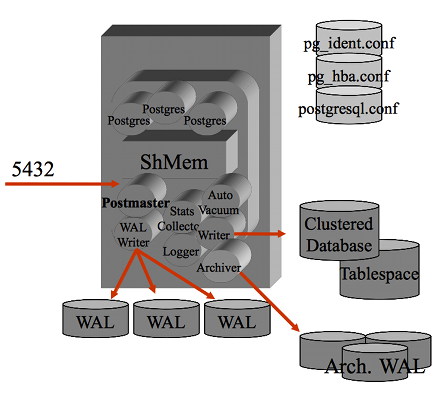 Il processo
postmaster e' il processo principale che si occupa della gestione delle
connessioni (e' in LISTEN sulla porta socket 5432)
ed e' il "padre" di tutti i processi, sia di sistema (eg. wal writer)
sia quelli relativi alle connessione utente.
Tutti i processi girano come utente postgres ed eseguono un attach
al segmento di shared memory su cui vengono mantenuti buffer e lock.
Il processo
postmaster e' il processo principale che si occupa della gestione delle
connessioni (e' in LISTEN sulla porta socket 5432)
ed e' il "padre" di tutti i processi, sia di sistema (eg. wal writer)
sia quelli relativi alle connessione utente.
Tutti i processi girano come utente postgres ed eseguono un attach
al segmento di shared memory su cui vengono mantenuti buffer e lock.
La gestione delle transazioni in PostgreSQL avviene con la tecnica del MVCC
(Multiversion Concurrency Control)
e la consistenza dei dati su disco e' assicurata con il logging
(Write-Ahead Logging).
L'isolation level di default e' Read Committed.
Ogni transazione al commit effettua una scrittura
sul WAL (Write-Ahead Log): in questo modo e' certo che le attivita' confermate alla
transazione sono state scritte su disco.
La scrittura sul WAL e' sequenziale e molto veloce.
La scrittura effettiva sui
file delle tabelle e degli indici viene effettuata successivamente
ottimizzando le scritture sul disco.
I WAL possono essere archiviati e questo consente l'effettuazione
di backup a caldo e il PITR (Point In Time Recovery).
Il Clustered Database e' la struttura del file system che contiene i dati.
All'interno vengono mantenuti i file di configurazione ($PGDATA/*.conf),
i log delle transazioni (nella directory $PGDATA/pg_xlog)
e le strutture interne della base dati che contengono
tabelle ed indici (suddivise per database nella directory $PGDATA/base).
Il blocco ha dimensione 8KB mentre i wal log hanno come dimensione
16MB.
La replica di una base dati PostgreSQL e' basata sulla ricezione e l'applicazione
dei WAL sui sistemi secondari o Standby.
Nelle prime versioni di PostgreSQL era presente la sola modalita' di log shipping
ma le versioni piu' recenti implementano la streaming replication
che ha una latenza molto bassa.
Configurazione Primary
Il sistema Primary o Master e' quello che ospita la base dati in condizioni di
normale operativita'.
Oltre alla normale configurazione che si effettua con il tuning dei parametri
per ottenere prestazioni ottimali con le applicazioni ospitate, vanno impostati
parametri specifici per la replica.
- Configurazione postgresql.conf
Postgres va configurato in modo da accettare connessioni dalla rete,
da salvare i WAL in modalita' hot_standby (la piu' completa) e con alcuni
parametri che definiscono le caratteristiche della replica
[NdE questa configurazione richiede un riavvio per essere attivata]:
$ vi postgres.conf
listen_addresses = '*'
wal_level = hot_standby
max_wal_senders = 5
checkpoint_segments = 8
wal_keep_segments = 8
hot_standby = on
archive_mode = on
archive_command = 'cp %p /home/archive/%f'
NB:
L'impostazione dell'archive e' opzionale, in alternativa puo' essere aumentato il valore dei wal_keep_segments.
Dalla 9.5 non e' piu' presente il parametro checkpoint_segments sostituito da
max_wal_size il cui valore di default generalmente non richiede modifiche.
Dalla 9.6 l'impostazione del wal_level deve essere replica,
dalla 10 tale impostazione e' il default.
Dalla versione 10 l'impostazione di default di max_wal_senders e' 10, in precedenza era 0;
la replica richiede che sia maggiore di 0
[NdE con i valori di default dalla versione 10 non e' necessario alcun riavvio].
- Configurazione pg_hba.conf
Il file di configurazione degli accessi a Postgres deve consentire la replica
[NdE questa configurazione richiede solo un reload per essere attivata]:
$ vi pg_hba.conf
# HA dedicated network
host replication all 10.0.1.0/24 md5
# DR dedicated network
host replication all 192.168.0.0/24 md5
- Utenza di replica
In una configurazione di produzione e' opportuno creare un'utenza dedicata
alla replica e non utilizzare l'utenza superuser
[NdE questa configurazione e' immediatamente attiva]:
$ psql
CREATE ROLE repl_usr REPLICATION LOGIN PASSWORD 'XXX';
^D
- Copia a freddo
Il database Master e' ora pronto per essere replicato.
Deve essere spento e creata una copia fisica di tutto il DB e delle sue configurazioni
(naturalmente il path riportato va impostato a seconda della propria configurazione):
$ pg_ctl stop
$ tar cvf /tmp/full.tar /var/lib/pgsql/9.3/data
NB:
Dalla versione 9.1 e' anche utilizzabile il comando pg_basebackup
in modalita' online:
pg_basebackup -h master_host -D $PGDATA -P -U repl_usr -X stream
Configurazione Standby in alta affidabilita'
Il server di Standby o Slave e' pronto a sostituirsi al Primary in caso di fault.
E' quindi importante fare in modo che gli aggiornamenti abbiano la latenza
minore possibile.
Nella configurazione scelta il server riceve continuamente in streaming gli aggiornamenti
sulle modifiche occorse.
La configurazione e' semplificata ribaltando
le impostazioni gia' effettuate sul Primary ed agendo per differenza.
- Copia DB
Come da titolo! Si copia tutto sullo Standby...
- Configurazione recovery.conf
Questo file attiva la modalita' di recovery sullo standby e ne contiene i parametri:
$ vi recovery.conf
standby_mode = 'on'
primary_conninfo = 'host=p1 port=5432 user=repl_usr password=XXX'
trigger_file = '/tmp/PromoteToMaster'
recovery_target_timeline = 'latest'
- Avvio Standby
Va avviato il Postgres di Standby cosi' si pone in attesa dei dati.
- Avvio Primary
Ora e' possibile avviare il Primary!
Le transazioni applicative verrano immediatamente trasmesse allo standby.
Questi ultimi due passi possono essere invertiti rendendo disponibile prima il servizio
sul Primary, pero' possono presentarsi dei problemi:
questa e' la sequenza consigliata.
Ora sono disponibili ed utilizzabili due basi dati PostgreSQL allineate tra loro
(la seconda in sola lettura).
Configurazione Standby in cascading replication
In una configurazione di DR un requisito e' la distanza e la separazione tra
l'ambiente di produzione ed i server in Standby. Saranno quindi molto piu' alte
le latenze di rete ed l'RPO ottenibile. La configurazione deve essere ottimizzata
per ridurre il traffico di rete.
Un server di Standby non deve necessariamente connettersi direttamente al Primary
ma puo' raccogliere le modifiche da un altro Standby formando cosi' una catena.
Il server piu' vicino al Primary viene chiamato di Upstream mentre quello piu'
lontano viene chiamato Downstream.
Questa configurazione consente di diminuire le connessioni dirette verso il Primary
e di ottimizzare il traffico di rete se piu' server si trovano in una rete diversa
da quella del Primary (situazione tipica per un sito di DR).
Anche in questo caso la configurazione e' semplificata perche' agiremo per differenza
ribaltando le impostazioni gia' effettuate.
Nell'esempio non viene fermato il Primary: se il numero di transazioni eseguite
durante l'attivazione
non e' elevato (meno di 8 WAL con i parametri utilizzati) i database in Standby
recupereranno le transazioni senza interruzioni.
- Copia a freddo dell'Upstream Standby
Il database Upstream deve essere replicato.
Deve essere spento e creata una copia fisica di tutto il DB e delle sue configurazioni.
- Copia DB
Come da titolo! Si copia tutto dall'Upstream al Downstream
- Configurazione recovery.conf
Va modificato un singolo parametro sul Downstream, l'host a cui connettersi:
$ vi recovery.conf
standby_mode = 'on'
primary_conninfo = 'host=S1 port=5432 user=repl_usr password=XXX'
trigger_file = '/tmp/PromoteToMaster'
recovery_target_timeline = 'latest'
- Avvio Standby
Vanno avviati gli standby nell'ordine Downstream ed Upstream.
Ora sono attivi tre database: il Primary cui si collegano utenti ed applicazioni,
uno Standby posto sulla stessa rete locale ed uno standby posto su una rete differente
ed aggiornato in cascata.
Nella figura seguente si utilizza la replica in cascata per mantenere allineati
due CED in una tipica configurazione di Disaster Recovery:
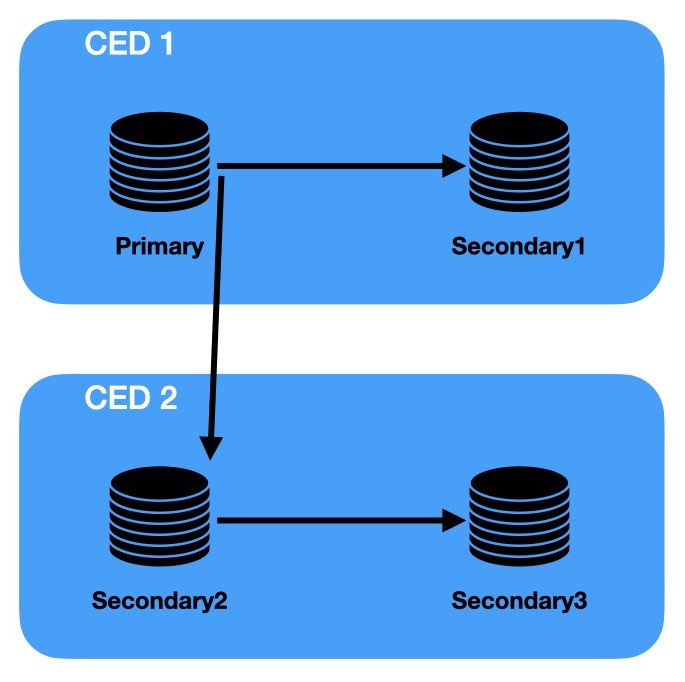
Il traffico di rete e' ottimizzato poiche' e' attiva una sola replica in geografico
tra il Primary e l'Upstream Slave2 mentre la replica verso il Downstream Slave3
avviene su rete locale.
Variazioni sul tema
Una forma piu' semplice di replica e' basata sul log shipping, viene chiamata Warm Standby
ed e' stata la prima storicamente disponibile con PostgreSQL.
La configurazione e' semplice ma e' adatta solo per disporre di un database di backup.
Poiche' la quantita' di transazioni perse in caso di fault e' piu' elevata rispetto
alla tecnica della streaming replication (Hot Standby) viene sempre scelta quest'ultima quando disponibile.
A volte non e' possibile fermare la base dati principale per attivare un nuovo standby.
In questo caso e' possibile utilizzare un backup a caldo [NdE l'operazione va conclusa prima del riciclo dei WAL]:
PGDATA=/var/lib/pgsql/9.3/data/
psql -c "select pg_start_backup('base_backup');"
rsync -va --exclude pg_xlog --exclude postgresql.pid $PGDATA/* 192.168.0.2:$PGDATA/
psql -c "select pg_stop_backup();"
rsync -va $PGDATA/pg_xlog 192.168.0.2:$PGDATA/
Per effettuare un backup a caldo, dalla versione 9.1, e' comunque consigliato
il comando pg_basebackup.
La replica su PostgreSQL per default e' asincrona.
E' possibile configurare la replica sincrona (2-safe replication)
impostanto i parametri synchronous_standby_names e synchronous_commit.
Nella configurazione sincrona le transazioni non vengono chiuse fino a che
non siano state trasferite ad almeno uno standby.
La replica sincrona presenta rallentamenti (per l'attesa della risposta degli standby)
e rischi di blocco (se nessuno standby risponde): pertanto e' utilizzata in pochi specifici casi
quando si hanno a disposizione piu' Standby nello stesso datacenter.
Principali operative
La documentazione della configurazione e delle operative da utilizzare
per una corretta gestione degli ambienti ha un'importanza forse superiore
ad una corretta implementazione!
Altro aspetto elemento importante nella continuita' operativa e'
che vi sono eventi che non possono essere gestiti da automatismi
ma richiedono un intervento manuale ed un'autorizzazione:
anche questi processi debbono essere descritti.
Altrimenti il rischio e' quello di avere una macchina perfetta...
ma senza il pilota.
Failover
L'operazione piu' critica dal punto di vista del RTO (Recovery Time Objective) e'
quando lo Standby deve sostituire il Primary che e' in fault.
Con la configurazione effettuata in precedenza il failover e' molto semplice e veloce:
$ touch /tmp/PromoteToMaster
Appena creato il file di trigger il database in standby
termina l'applicazione dei WAL, attiva i processi necessari
e inizia ad accettere le connessioni utente:
2014-04-01 19:28:58.556 CET >LOG: trovato il file trigger: /tmp/PromoteToMaster
2014-04-01 19:28:58.556 CET >LOG: redo concluso in 0/1C830E70
2014-04-01 19:28:58.556 CET >LOG: l'ultima transazione e' stata completata all'orario di log 2014-04-01 19:27:08.193027+01
2014-04-01 19:28:58.573 CET >LOG: l'ID della nuova timeline selezionata e' 2
2014-04-01 19:28:58.700 CET >LOG: il ripristino dell'archivio e' stato completato
2014-04-01 19:28:58.734 CET >LOG: il database e' pronto ad accettare connessioni
2014-04-01 19:28:58.734 CET >LOG: esecutore di autovacuum avviato
Il failover di PostgreSQL tipicamente richiede un tempo molto limitato (RTO < pochi secondi):
e' sicuramente maggiore il tempo che occorre per prendere la decisione.
Con il failover vengono recuperate tutte le transazioni ricevute dallo Standby,
tuttavia non vi e' certezza che lo Standby abbia ricevuto tutte le transazioni eseguite sul Primary
(RPO > 0).
Al termine del promote il file recovery.conf viene rinominato automaticamente in recovery.done.
Dopo un failover viene creata una nuova timeline:
non e' piu' possibile utilizzare la vecchia base dati del primary che deve essere riallineata.
Switchover
Come attivita' pianificata e se sono rispettati alcuni prerequisiti tecnici
e' possibile effettuare un
passaggio morbido tra il Primary ed il Secondary: lo switchover.
Con lo switchover non si ha mai perdita di transazioni (RPO=0) ed e' possibile
riconfigurare il vecchio Primary come Standby senza effettuare
un backup della base dati.
Per effettuare uno switchover:
Soddisfatti i prerequisiti tecnici indicati l'effettuazione dello switch e' analoga al failover:
$ touch /tmp/PromoteToMaster
Per configurare il vecchio Primary come Standby e' sufficiente creare il file recovery.conf
indicando la connessione al nuovo Primary.
Backup e restore
In questo documento non vi e' stato nessun accenno alle procedure di Backup e Restore...
ma solo perche' sono date per scontate.
Sarebbe assurdo dotarsi di una soluzione di DR, che puo' avere un MTBF di anni,
e non poter correggere fault singoli o errori umani che possono avvenire ogni giorno
[NdA il mio personale MTBF e' di circa 4 ore: in pratica combino un pasticcio due volte al giorno ;-].
Monitoraggio
Oltre a varificare il corretto funzionamento dei sistemi, anche questo dato per scontato,
e' necessario verificare il corretto allineamento delle repliche.
Con la configurazione in Hot Standby la verifica funzionale e' semplice:
basta collegarsi e lanciare una query!
Per controllare lo stato delle repliche e' possibile utilizzare la seguente query sul
DB Primary:
select client_addr, state, sync_state, txid_current_snapshot(),
sent_location, write_location, flush_location, replay_location,
backend_start
from pg_stat_replication;
Sono informazioni analoghe rispetto a queste due query da lanciare rispettivamente sul Master e sullo Slave:
select pg_current_xlog_location();
select pg_last_xlog_receive_location();
Una metrica fondamentale per la replica e' il lag ovvero il ritardo
nell'applicazione delle modifiche sullo slave.
Un modo per valutarlo e':
select case when pg_last_xlog_receive_location() = pg_last_xlog_replay_location()
then 0
else extract(epoch from now() - pg_last_xact_replay_timestamp())::INTEGER
end as LAG_seconds;
Un report completo sulla configurazione di PostgreSQL, con una sezione dedicata alla replica,
si ottiene con
questo script.
Problemi? Parliamone!
Vediamo qualche esempio di errore tipico della streaming replication come riportato nei file di log:
2015-02-14 14:24:16 CETFATAL: could not receive data from WAL stream: ERROR: requested WAL segment 0000000100000069000000AA has already been removed
Fatto partire prima il Primary e poi il Secondary?
I wal sono gia' stati archiviati e vanno ribaltati sul secondario per farlo ripartire.
ERROR: canceling statement due to conflict with recovery
Questo e' un Hard Conflict!
La query dell'utente sullo standby e' entrata in conflitto con l'applicazione di un WAL
ed e' stata abortita.
Le ragioni possono essere molte, VACUUM su righe cancellate, DDL su query in corso, ...
se accadesse sul Primary una transazione aspetterebbe il termine del lock,
ma poiche' la query e' eseguita sul secondary la precedenza e' l'applicazione dei WAL.
Se capita spesso si possono aumentare i due parametri sullo slave: max_standby_archive_delay, max_standby_streaming_delay.
Il numero dei conflitti si puo' monitorare sulla vista pg_stat_database_conflicts [NdA disponibile dalla versione 9.1].
[unknown] repl_usr 2016-02-11 11:35:35 CETERROR: requested WAL segment 00000001000060690000ACCA has already been removed
Il master ha gia' archiviato il WAL in oggetto e lo slave non e' in grado di ripristinare la replica.
Se sono ancora disponibili si copiano, altrimenti e' necessario risincronizzare Primary e Secondary.
Le cause possono essere diverse tra cui il "checkpoints are occurring too frequently";
in questo caso il tuning dei WAL e l'utilizzo degli slot [NdA disponibili dalla 9.4]
sono le azioni consigliate.
Cenni di anatomia comparata
Avete presente le differenze dell'apparato digerente tra i suini e gli ovini?
L'anatomia comparata studia appunto tali differenze da centinaia di anni
ed e' compito dei DBA (Dipartimenti di Biologia Animale?)
raccogliere le conoscenze in questo settore.
[NdE per chi non lo sapesse l'apparato digerente dei suini e' molto simile
a quello degli umani ed, in modo particolare, a quello dell'autore :-]
Dopo tale inutile ed inopportuna premessa passiamo ad analizzare quanto interessa
ai DBA (DataBase Administrator) analizzando le differenze delle tecnologie di replica
tra database differenti...
La replica su PostgreSQL fisica e basata sul log delle transazioni e' ben confrontabile con
Data Guard fornito da Oracle.
La replica su PostgreSQL e' invece tecnicamente molto differente dalla replica Statement Based di MySQL
(ed anche dalle sue evoluzioni Row Based, GTID, InnoDB Cluster, Galera)... quindi vediamo il confronto con
l'apparato di replicazione di Oracle
[NdA si tratta di apparato e non di sistema poiche' gli organi sono connessi].
PostgreSQL
| Oracle
|
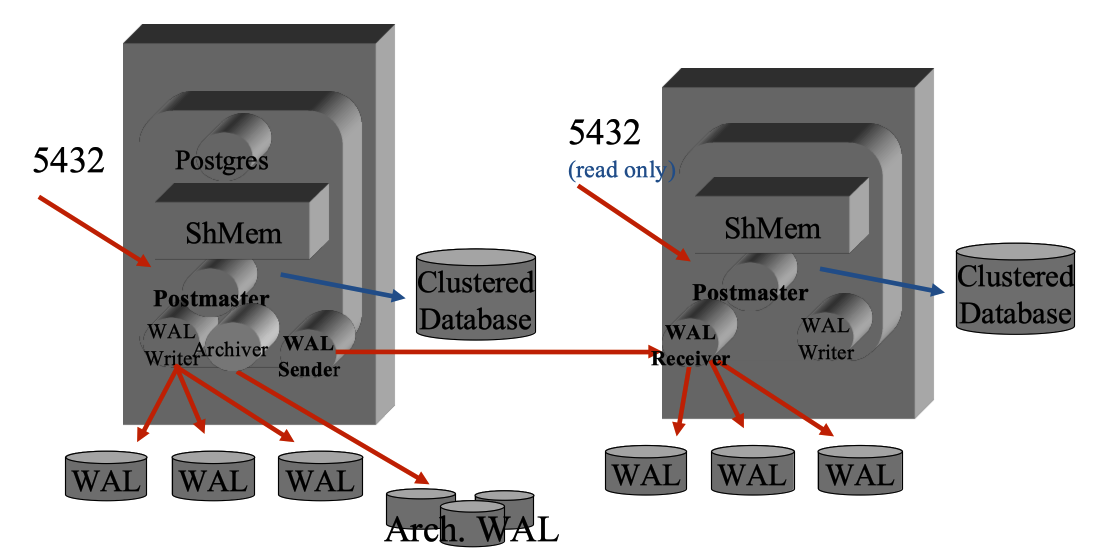
| 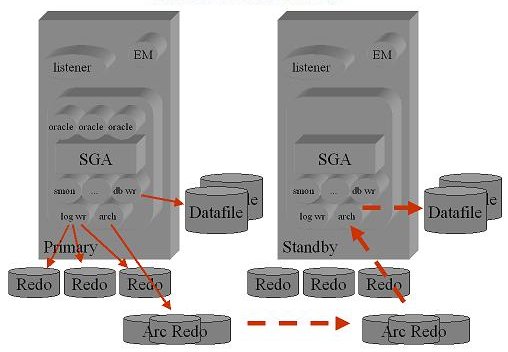
|
Le strutture dei due database sono profondamente diverse ma la modalita'
con cui viene garantita la durabilita' dei dati e' invece simile.
PostgreSQL utilizza i WAL (Write-Ahead Log) su cui indica le modifiche
mentre in Oracle il processo Log Writer riporta sui redo log i blocchi da aggiornare.
Entrambe le repliche sono di tipo fisico e sono basate sulla trasmissione dei log.
Sia con Postgres che con Oracle la modalita' di trasmissione dei log
avviene in streaming fornendo un RPO molto piu' breve
[NdA nelle versioni piu' recenti, ma comunque ormai da un decennio].
La configurazione in Hot Standby di PostgreSQL consente di accedere
al database secondario in modalita' di lettura.
Analogamente avviene su Oracle con l'Active Data Guard Option.
L'utilizzo di tale modalita' aumenta in modo significativo
le funzionalita' della replica dati sia dal punto di vista di
continuita' operativa (per la verifica della replica, per la verifica dei lag, ...)
che di bilanciamento del carico (spostando sul secondario report, analisi dati, ...).
Con Oracle e' possibile impostare tre differenti protection mode:
MAXIMIZE {AVAILABILITY | PERFORMANCE | PROTECTION}
ed ha una varieta' di configurazione molto ampia.
Postgres consente invece la scelta tra la modalita' asincrona e quella sincrona.
Ma le modalita' di default di entrambe le basi dati sono praticamente analoghe
(privilegiando le performance e la disponibilita' del servizio rispetto ad un applicazione
sincrona dei risultati).
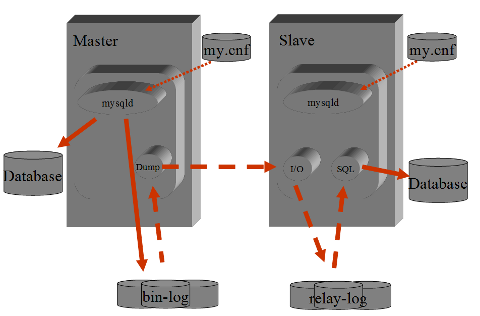 Molto lontana e' invece dal punto di vista tecnico e' la
Replication di MySQL.
La replica MySQL e' statement/row based e non tutti gli Engine MySQL supportano
le transazioni.
Anche dal punto di vista anatomico le due implementazioni PostgreSQL e MySQL sono completamente differenti.
Molto lontana e' invece dal punto di vista tecnico e' la
Replication di MySQL.
La replica MySQL e' statement/row based e non tutti gli Engine MySQL supportano
le transazioni.
Anche dal punto di vista anatomico le due implementazioni PostgreSQL e MySQL sono completamente differenti.
Dal punto di vista funzionale sono presenti diverse analogie (eg. cascading replication)
ma, come sanno tutti gli esperti di anatomia comparata,
si tratta di un classico esempio di organo analogo e di convergenza evolutiva.
Amazon fornisce come servizi Cloud PostgreSQL RDS ed Aurora PostgreSQL.
PostgreSQL RDS e' un servizio Cloud basato sulla versione community
in cui sono state modificate le parti di gestione per renderle adatte al cloud.
Il servizio di replica su Amazon PostgreSQL RDS e' la streaming replication
esattamente come e' stata descritta.
Aurora PostgreSQL e' un servizio Cloud fornito da Amazon che offre un DB compatibile a PostgreSQL
ottimizzato sull'infrastruttura AWS (eg. tutto lo storage e' su SSD) ed orientato all'HA.
Con Aurora e' possibile definire fino a 15 repliche che possono essere distribuite
su diverse Availability Zone.
Oltre che per failover le repliche sono utilizzate per scalare le prestazioni in lettura.
Dal punto di vista tecnico la replica Aurora
si basa sulla replica degli storage
e' quindi realizzata in modo completamente diverso
dalla replica PostgreSQL.
Evoluzione
Le funzionalita' della replication in PostgreSQL hanno avuto un'importante evoluzione
nel tempo. Ecco le tappe principali:
- 7.1: Introduzione dei WAL (write-ahead log).
L'introduzione dei WAL permette di evitare fsync ad ogni commit su tutti i dati
e mantiene una traccia delle transazioni.
- 8.0: Implementazione del PITR (point-in-time recovery).
Tassello fondamentale per la replica (che puo' essere implementata con script ad hoc):
la possibilita' di copiare e di applicare i WAL.
Il file recovery.conf viene introdotto appunto in questa versione.
- 8.3: pg_standby.
Anche se tecnicamente era gia' possibile prima con script e configurazioni manuali,
la versione 8.3 introduce il comando pg_standby che mantiene un server secondario
in replica (tecnicamente e' in stato permanente di restore).
- 9.0: hot standby, streaming replication.
La replica diventa parte integrante della distribuzione PostgreSQL.
L'Hot Standby consente di aprire in lettura il DB secondario
mentre la streaming replication invia gli aggiornamenti appena occorsi sul DB primario.
- 9.1: pg_basebackup, synchronous replication.
Con la replica sincrona si attende la ricezione della transazione sul DB secondario.
- 9.2: cascading replication.
Utilizzando nodi geograficamente distanti diventa significativa la banda disponibile
il cui utilizzo puo' essere ridotto con la replica in cascata.
- 9.3: timeline switch support per gli standby.
Ogni recovery genera una nuova timeline come orizzonte degli eventi
(non e' esattamente cosi'... ma orizzonte degli eventi mi piaceva scriverlo e comunque
rende un po' l'idea di futuri alternativi).
- 9.4: replication slots, logical decoding [NdA pg_logical_slot_get_changes()].
Con la gestione dei replication slot si impedisce la cancellazione dei WAL
necessari ai DB secondari in modo piu' efficiente che con l'impostazione del wal_keep_segments.
- 9.5: pg_rewind.
L'utility pg_rewind rende piu' semplice il reintegro di un Master come Slave dopo un failover...
eseguendo un ritorno al futuro!
- 9.6: multiple simultaneous synchronous standby servers, remote_apply.
Con la replica sincrona multipla si puo' aumentare il numero di DB secondari
da mantenere allineati accrescendo ulteriormente l'affidabilita' dei dati.
Nuove viste per il monitoraggio (eg. pg_stat_wal_receiver).
- 10.0: logical replication, quorum commit in synchronous replication.
La logical replication e' la grande novita' della 10.
L'utilizzo e' particolarmente semplice e si basa sul modello publisher/subscriber.
Con la versione 10 hanno cambiato nome alcune funzioni per il controllo dei WAL.
Ad esempio:
pg_last_xlog_receive_location() --> pg_last_wal_receive_lsn(),
pg_last_xlog_replay_location() --> pg_last_wal_replay_lsn(),
pg_current_xlog_flush_location() --> pg_current_wal_flush_lsn(),
...
Non da ultimo le funzioni pg_wal_replay_pause() e pg_wal_replay_resume()
utili per evitare eventuali conflitti nelle query sullo slave
che hanno sostituito le pg_xlog_replay_pause() e pg_xlog_replay_resume()
disponibili dalla 9.1.
- 11.0: pg_replication_slot_advance(), TRUNCATE with logical replication.
Ottimizzazioni sia per la streaming replication che per la logical replication.
- 12.0: standby.signal, recovery.signal.
E' cambiata completamente la modalita' di configurazione, non esiste piu'
il recovery.conf e tutti i parametri vengono configurati nel postgresql.conf.
Cambiano le operative... sara' meglio scrivere un nuovo documento!
- 13.0: online changes, many new parameters.
Ora e' possibile cambiare i primary_conninfo e primary_slot_name con un reload anziche' riavviare il secondary.
Molteplici nuove funzionalita' e parametri di controllo:
wal_receiver_create_temp_slot, max_slot_wal_keep_size, ignore_invalid_pages, ...
- 14.0: streaming logical replication.
Lo streaming nella logical replication presenta vantaggi su transazioni di grandi dimensioni.
- La storia continua sul nuovo documento!