Architetture di Database
per la Continuita' Operativa
ed il Disaster Recovery
Il presente documento presenta le architetture e le diverse opzioni
offerti dai principali database relazionali per la realizzazione della
continuita' operativa (Business Continuity: BC) e dei siti di Disaster Recovery (DR)
nelle configurazione in alta affidabilita' (High Availability: HA).
Le problematiche di disponibilita' dei dati e di continuita' operativa sono da sempre un aspetto fondamentale
di tutti i sistemi di gestione delle basi dati (DBMS).
E' quindi naturale che ogni prodotto DBMS consenta un'ampia scelta di possibilita'
per realizzare il livello desiderato di disponibilita' dei servizi e dei dati.
Il documento presenta in dettaglio l'architettura dei principali RDBMS (eg. Oracle, MySQL, PostgreSQL, ...)
e gli strumenti offerti da ciascuno per migliorare la sicurezza dei dati.
Il documento introduce alcuni elementi generali e quindi analizza le soluzioni
tecniche che sono disponibili nelle principali basi.
In particolare:
Oracle,
MySQL,
PostgreSQL,
MS-SQL,
...
Al termine sono discusse le varie alternative confrontandone le
pricincipali caratteristiche in termini di costi e benefici.
Introduzione
Questo e' un documento tecnico che riporta elementi utili per la valutazione
delle diverse soluzioni di continuita' operativa in ambito database.
L'argomento e' molto ampio ed e' quindi necessario limitare il perimetro
per rendere sufficientemente snello il documento.
L'analisi delle diverse alternative tecniche per l'implementazione di una soluzione dei servizi
di IT Service Continuity Management non puo' prescindere da una precedente Business Impact Analysis (BIA)
che analizzi l'impatto sull'ente o azienda dei rischi sui diversi servizi erogati (Risk Assessment).
Elementi fondamentali nella scelta delle soluzioni sono la determinazione
del Recovery Point Objective (RPO) e del Recovery Time Objective (RTO)
su cui si implementa la soluzione
e la sucessiva verifica del Recovery Time Actual (RTA).
Altro elemento fondamentale per l'analisi e' la conoscenza degli SLA
declinati sia per il sistema primario che per il sistema secondario.
Una metrica molto utilizzata per valutare la disponibilita'
degli ambienti 7x24 e' quella che riporta il downtime massimo per mese o per anno:
| HA rating | Downtime/month | Downtime/year
|
| 95% | 1d 12h 53' 00" | 18d 12h 43' 00"
|
| 99% | 7h 18' 00" | 3d 15h 36' 00"
|
| 99.9% | 43' 48" | 8h 45' 00"
|
| 99.99% | 4' 23" | 52' 34"
|
| 99.999% | 26" | 5' 15"
|
E' importante distinguere tra Uptime ed Availability ma la tabella e' la stessa.
In questi tempi vanno anche compresi gli interventi di manutenzione programmata
per gli upgrade di release e gli aggiornamenti di sicurezza.
Per indicare la disponibilita' si usa riportare il numero di nove presenti; ad esempio
5N (Five Nines) indica l'ultima riga.
Questo documento non tratta questi importanti argomenti sull'analisi del rischio e sulla disponibilita' dei servizi
che sono un prerequisito fondamentale ad una completa implementazione di Continuity Management...
ma solo le tecniche di maggior interesse per i database.
Nella scelta della soluzione tecnologicamente piu' adatta vanno valutate
tutte le alternative, che non necessariamente sono funzionalita' specifiche dell'RDBMS.
I sistemi operativi e le infrastrutture di storage offrono infatti molteplici possibilita' per la replicazione di dati.
E' quindi importante segnalare tecnologie quali:
Storage Replication, Failover Cluster, Load Balancer (sia HW che SW), Volume Replication, ...
Ma questo documento non entra nel merito delle soluzioni a livello di sistema operativo, storage, ...
ma riporta solo le principali soluzioni realizzabili come configurazione dell'RDBMS utilizzato.
Una corretta e completa implementazione delle strategie di backup
e' un componente fondamentale di un'infrastruttura IT.
Si tratta di un prerequisito fondamentale di ogni soluzione di continuita' operativa ma,
in questo documento, viene data per scontata
e vengono solo riportati alcuni cenni sulle differenti modalita' di backup presenti nei vari DBMS.
Infine, ma non da ultimo, sono date per scontate anche tutte le funzionalita'
di gestione delle transazioni, warm restart, backu/restore, on-line backup, PITR, ...
che sono presenti in ogni gestore di base dati moderno e che costituiscono un complemento
alla soluzione di BC o ne sono un componente essenziale.
RDBMS
Le problematiche di disponibilita' dei dati e di continuita' operativa
sono da sempre un aspetto fondamentale
di tutti i sistemi di gestione delle basi dati (DBMS).
E' quindi naturale che ogni prodotto DBMS consenta un'ampia scelta di tecnologie
con le quali realizzare il livello desiderato di disponibilita' dei servizi e dei dati.
Nel seguito viene riportato un capitolo per i principali motori di database:
Oracle,
MySQL,
PostgreSQL,
MS-SQL,
...
e le tecnologie utili alla Business Continuity disponibili per ciascuno di essi come:
Oracle RAC, Oracle Data Guard,
Oracle Golden Gate,
MySQL Replication, MySQL NDB Cluster,
Galera Cluster for MySQL,
MySQL InnoDB Cluster,
PostgreSQL Streaming Replication,
MS-SQL Cluster,
...
Si tratta delle tecnologie piu' recenti ed efficaci ma deve essere sottolineato
che le funzionalita' descritte in dettaglio nel seguito sono solo quelle su cui ho
avuto una significativa esperienza diretta.
Oracle
Oracle e' l'DBMS relazionale commerciale piu' diffuso al mondo. I suoi principali punti di forza sono:
- Enorme diffusione, soprattutto come database Enterprise per le piu' importanti aziende del mondo
- Un insieme di funzionalita' talmente ampio da rendere difficile farne un elenco.
Oracle e' leader riconosciuto per l'integrazione dei dati, l'alta affidabilita' e la scalabilita'
- Un ottimo ed esteso SQL utilizzabile direttamente o con i piu' diffusi linguaggi di programmazione.
Disponibilita' nativa nella base dati del PL/SQL e di Java
- Disponibile su tutte le piu' recenti piattaforme HW
- Disponibile in Edition con insiemi di funzionalita' e costi differenti
- Ottime prestazioni ed ottima scalabilita' in particolare con applicazioni complesse e con un elevato carico transazionale
Sull'RDBMS Oracle sono basati altri ambienti distribuiti dalla Oracle Corporation. Tra questi l'ambiente J2EE Oracle Application Server e l'ERP Oracle Enterprise Business Suite.
Funzionalita'
Le funzionalita' offerte dall'RDBMS Oracle sono veramente molte. Nel seguito riportiamo un elenco approssimativo
delle principali raggruppate per finalita':
- Integrazione
Distributed Queries/Transactions; 2PC; Advanced Queuing; Heterogeneous Databases
- Alta affidabilita'
ACID; Total Recall; Active Data Guard; Fail Safe; Flashback Query; Flashback Table, Database and Transaction Query; Server Managed Backup and Recovery (RMAN)
- Scalabilita'
Real Application Cluster (RAC); Real Application Clusters One Node; Integrated Clusterware; Automatic Workload Management; Java, PL/SQL Native Compilation; In-Memory Database Cache
- Sicurezza
Oracle Database Vault; Oracle Audit Vault; Oracle Advanced Security; Oracle Label Security; Secure Application Roles; Virtual Private Database; Fine-Grained Auditing; Proxy Authentication; Data Encryption Toolkit
- Sviluppo applicazioni
PL/SQL and Java, Server Pages; Oracle SQL Developer; Application Express; Java Support; Comprehensive XML Support; Comprehensive Microsoft .Net Support, OLE DB, ODBC
- Gestione
Enterprise Manager; Real Application Testing; Automatic Memory Management; Automatic Storage Management; Automatic Undo Management
- Data Warehousing
Parallel query; Partitioning; Data Mining; Transportable Tablespaces, Including Cross-Platform; Star Query Optimization; Information Lifecycle Management; Summary Management - Materialized View Query Rewrite; Oracle Exadata Storage Server; Oracle Database Machine; Advanced Compression; OLAP
- Gestione dei contenuti
XML DB; Multimedia; Text; Locator; Spatial
Architettura
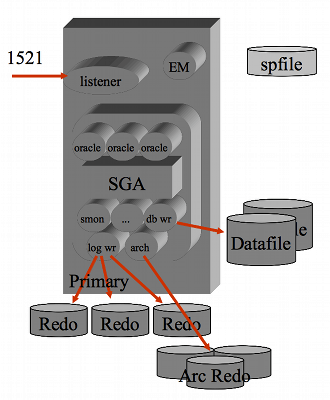 L'architettura dell'RDBMS Oracle presenta una certa complessita': vi sono una serie di processi di sistema che si occupano ciascuno di un compito specifico (eg. la scrittura dei dati, il controllo dei processi, l'esecuzione di job, l'archiviazione, ...). Con il passare delle versioni di Oracle il numero di processi di sistema (background e shadow) e' sempre cresciuto. Con l'ultima versione (11g R2) il numero di processi di sistema di Oracle supera la ventina. Ad ogni connessione utente viene inoltre lanciato un processo dedicato che esegue l'SQL richiesto dall'utente/applicazione. I vari processi condividono un'area di memoria, implementata come Shared Memory, denominata SGA. La SGA (System Global Area) mantiene i buffer dei dati, l'elenco dei lock, la cache delle strutture della base dati, ... Per l'accesso in Client-Server viene utilizzato il processo listener che crea una processo dedicato per ogni Client. Se il numero di Client e' molto elevato e' possibile sfruttare la tecnica dell'MTS (Multi Threaded Server) che sfrutta un pool di processi per le diverse sessioni.
Oracle utilizza una serie di file:
L'architettura dell'RDBMS Oracle presenta una certa complessita': vi sono una serie di processi di sistema che si occupano ciascuno di un compito specifico (eg. la scrittura dei dati, il controllo dei processi, l'esecuzione di job, l'archiviazione, ...). Con il passare delle versioni di Oracle il numero di processi di sistema (background e shadow) e' sempre cresciuto. Con l'ultima versione (11g R2) il numero di processi di sistema di Oracle supera la ventina. Ad ogni connessione utente viene inoltre lanciato un processo dedicato che esegue l'SQL richiesto dall'utente/applicazione. I vari processi condividono un'area di memoria, implementata come Shared Memory, denominata SGA. La SGA (System Global Area) mantiene i buffer dei dati, l'elenco dei lock, la cache delle strutture della base dati, ... Per l'accesso in Client-Server viene utilizzato il processo listener che crea una processo dedicato per ogni Client. Se il numero di Client e' molto elevato e' possibile sfruttare la tecnica dell'MTS (Multi Threaded Server) che sfrutta un pool di processi per le diverse sessioni.
Oracle utilizza una serie di file:
- Control File
I control file contengono le informazioni necessarie al bootstrap di Oracle.
- Data File
Nei data file vengono memorizzati i dati. Sui data file sono quindi memorizzate le tabelle, gli indici, i segmenti di rollback, ...
I datafile sono raggruppati in tablespace. Una tabella puo' essere memorizzata su piu' datafile purche' questi appartengano allo stesso tablespace.
- Redo Log File
Nei log file vengono storicizzate tutte le attivita' di scrittura svolte sui data file.
- init.ora / spfile
Il file init.ora e' un file di testo che contiene i parametri per l'attivazione di Oracle e di tuning. L'spfile e' l'analogo binario dell'init.ora e consente la modifica on-line dei parametri di sistema
Con l'eccezione del file di parametri, le strutture di Oracle possono essere definite sul file system oppure possono essere appoggiate direttamente sui device fisici (raw devices). Con l'ASM (10g) Oracle puo' gestire direttamente lo storage fisico senza necessita' di utilizzo di Volume Manager e/o di File Systems. La struttura interna dei file e' molto complessa poiche' sono molteplici le strutture di memorizzazione che Oracle utilizza.
La gestione delle transazioni e' molto efficiente ed affidabile con l'RDBMS Oracle. Quando deve essere effettuata una modifica su un dato Oracle salva prima il contenuto del blocco che lo contiene su un segmento di rollback, quindi effettua la modifica sul dato. Quando la transazione viene confermata il segmento di rollback viene segnato come libero ed il dato e' definitivamente confermato. I segmenti di rollback sono mantenuti sui datafile. Per migliorare le prestazioni Oracle utilizza una cache in memoria ed effettua in modo periodico (o quando richiesto dal commit di una transazione) l'allineamento sui dischi. Ogni attivita' di scrittura sui dischi e' riportata sui file di log in modo sincrono al commit delle transazioni. I file di log vengono utilizzati in modo circolare, quindi sono periodicamente ricoperti. Per mantenere la "storia" delle transazioni avvenute su un database e' possibile attivare il log archiving. Con il log archiving attivo quando un file di redo log e' stato completato viene salvato. Il log archiving permette il point in time recovery ed il backup a caldo.
Configurazioni complesse
Oracle puo' essere utilizzato in configurazioni complesse che permettono la realizzazione di architetture in alta affidabilita' con la gestione della Business Continuity, adatte a soluzioni di Disaster Recovery, ... Nel seguito vengono dati alcuni cenni sull'utilizzo dei cluster, dei database distribuiti,
della replicazione, del RAC e dell'Active Data Guard.
L'RDBMS Oracle e' facilmente integrato in un failover cluster.
Molti cluster hanno gia' script o agenti ideati per Oracle, su altri integrare Oracle e' comunque molto semplice.
Oracle stessa fornisce i componenti di integrazione su alcuni prodotti di cluster
(eg MS-Windows) oppure ha collaborato con i fornitori per l'ottimizzazione dei loro prodotti (eg. Veritas/Symantec).
Fondamentalmente il database ed il listener sono visti come servizi in grado di migrare
tra i nodi che costituiscono il cluster.
Oracle supporta, in modo completo e senza necessita' di configurazioni specifiche, il protocollo di Two-Phase Commit
che consente le transazioni distribuite. Con trigger, database link, sinonimi, ...
e' possibile costruire una base dati distruibuita in modo trasparente alle applicazioni.
Oggetti quali gli snapshot consentono di realizzare in modo semplice la replicazione di tabelle.
Per i casi piu' complessi l'opzione Advanced Replication permette di impostare replicazioni sincrone/asincrone con multimaster e la risoluzione automatica dei conflitti.
Sono presenti molteplici prodotti che realizzano sincronizzazioni applicative tra basi dati Oracle.
Per diffusione, funzionalita' e livello di integrazione e' sicuramente importante ricordare Golden Gate
(prodotto esterno ma acquisito da Oracle e che ha sostituito l'Advanced Replication nelle versioni piu' recenti).
L'opzione Oracle RAC e' la soluzione per eccellenza per l'alta affidabilita' dei database.
La configurazione Data Guard e' la soluzione per eccellenza per il disaster recovery dei database.
Possono essere realizzate entrambe in diverse combinazioni,
meritano quindi un capitolo ciascuna.
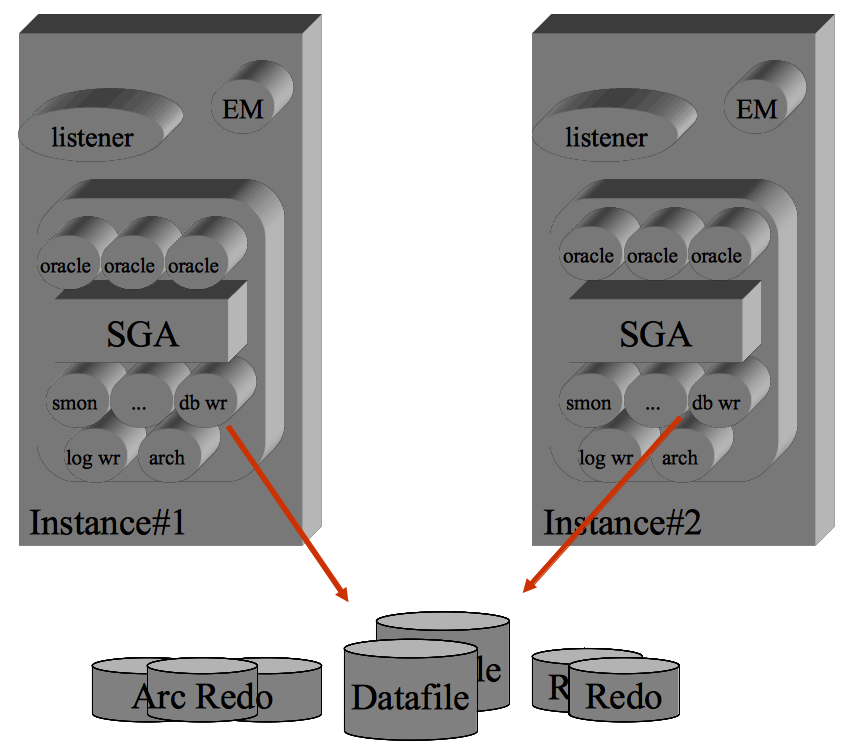
Oracle RAC
L'opzione Oracle RAC (Real Application Cluster) consente la condivisione, da parte di istanze differenti ed attive su macchine distinte, di pool di dischi comuni.
In tal modo sistemi differenti utilizzano le stesse risorse sui dischi. In caso di fault di un sistema,
il secondo sistema puo' immediatamente sostituirsi ad esso.
Si tratta quindi di una configurazione in cluster Active-Active.
Nelle versioni precedenti [NdE molto precedenti ma l'Autore e' molto vecchio]
l'opzione era denominata Oracle Parallel Server.
I nodi comunicano tra loro su una rete privata che deve avere una bassa latenza ed elevata affidabilita'.
La connessione viene utilizzata sia per la gestione del cluster
(come l'heartbeat di un cluster tradizionale) che per lo scambio di dati tra i nodi.
I meccanismi di costituzione e sincronizzazione del cluster sono complessi ed utilizzano sia protocolli di rete
che lo storage (eg. Voting Disk).
Per gli aspetti prestazionali e' pero' piu' importante lo scambio di dati tra i nodi.
Quando e' necessario reperire un dato un'istanza prima lo cerca nella propria cache, quindi effettua una ricerca sulla Global Cache (GC). Se un'altra istanza aveva gia' in memoria lo stesso blocco
questo viene trasferito attraverso la rete di Interconnect senza necessita'
di effettuare una lettura su disco (physical read).
La gestione della GC ovviamente tiene conto di tutte condizioni nella gestione dei blocchi di dati:
solo lettura/modifica, lock, ...
Il protocollo utilizzato per lo scambio dei dati e' leggermente differente nel caso di due nodi (2-way)
rispetto al caso di tre o piu' nodi (3-way).
Con la versione Oracle 11g R2 e' stata introdotto il RAC One Node: simile ad un ambiente di cluster failover introduce alcune possibilita' come l'Omotion (passaggio trasparente della base dati tra i nodi).
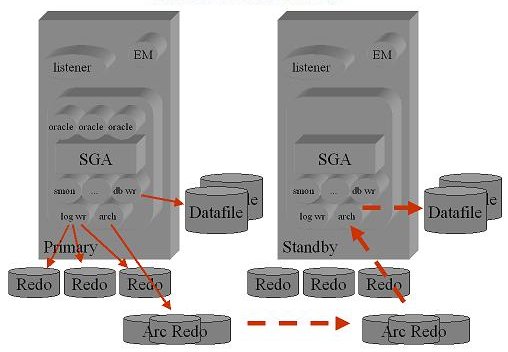
Oracle Data Guard
E' possibile mantenere un'istanza Oracle in stand-by.
In tale modalita' l'istanza non e' attiva ma viene aggiornata continuamente
(passando i file di redo log) rispetto all'istanza di produzione.
Sono disponibili diverse modalita' di aggiornamento a seconda del livello di RPO richiesto.
A differenze dell'opzione RAC la latenza della comunicazione tra le istanze puo' anche essere
elevata e la banda limitata alla sola trasmissione dei redo log.
In caso di fault del database primario l'istanza in stand-by puo' essere attivata in brevissimo tempo.
Un componente opzionale, chiamato Oracle Active Data Guard, consente di aprire la base dati,
anche durante le attivita' di allineamento dei dati,
ed accedervi con applicazioni in sola lettura.
Nelle versioni piu' recenti e' stato introdotto il DG broker che semplifica la gestione
delle istanze.
Oracle GoldenGate
Oracle GoldenGate sfrutta i log del database per individuare i record modificati
e replicarli in modo asincrono su database eterogenei (anche in modo bidirezionale).
La tecnologia utilizzata da Golden Gate ha un impatto minimale sulle prestazioni dei sistemi sorgente
e puo' essere sfruttata in scenari diversi: Disaster Recovery, Data Warehouse, Upgrade/Migration activities, ...
GoldenGate e' nato come prodotto esterno ad Oracle ma e' stato acquisito da Oracle
ed integrato nella suite dei prodotti Oracle.
I processi principali sono l'Extract che analizza i redolog e ne scarica
le informazioni rilevanti sui Trail file; i file vengono trasferiti dal processo Data Pump
ed applicati sulla destinazione dal processo Replicat.
Ulteriori informazioni
Alcune pagine che riportano maggiori dettagli su argomenti inerenti le problematiche di Business Continuity sono:
Oracle: un'introduzione,
Architetture fault tolerant in Oracle,
Oracle RAC,
Oracle Data Guard,
...
Naturalmente il sito ufficiale e' www.oracle.com
che contiene tutta la
documentazione.
Questa tabella riporta le diverse versioni di Oracle,
le principali funzionalita' ed il supporto disponibile.
Le soluzione per la continuita' operativa ed il disaster recovery presentate fino
ad ora non esauriscono le possibilita' disponibili per Oracle...
Si puo' ad esempio riportare che vi sono diverse edizioni
di Oracle e quanto descritto prima vale sopratutto per l'Enterprise Edition,
che e' quella piu' completa e costosa,
ma che esistono prodotti (eg. Dbvisit) e soluzioni (continuous backup, PDB refresh)
che valgono anche per le altre Edition.
MySQL
MySQL e' DBMS relazionale Open Source piu' diffuso al mondo e che non ha nulla da invidiare a sistemi commerciali.
I suoi principali punti di forza sono:
- Free! Gratis per l'utilizzo come Open Source
- Eccezionale diffusione, soprattutto per le applicazioni web
- Un ottimo e completo SQL utilizzabile direttamente o con i piu' diffusi linguaggi di programmazione
- Disponibile anche con una licenza commerciale e supporto
- Leggero e di poco impatto sui server su cui viene installato
- Semplice nell'utilizzo, nella configurazione, nell'amministrazione, ...
- Ottime prestazioni
- Consente l'utilizzo di differenti Storage Engine
Architettura
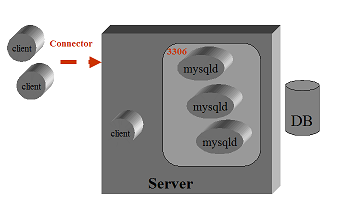 L'architettura di MySQL e' semplicissima: vi e' un solo processo!
Il processo demone MySQL e' in ascolto su una porta socket (la 3306 di default)
e genera un thread ad ogni connessione utente/applicativa.
L'architettura di MySQL e' semplicissima: vi e' un solo processo!
Il processo demone MySQL e' in ascolto su una porta socket (la 3306 di default)
e genera un thread ad ogni connessione utente/applicativa.
La memorizzazione dei dati avviene in modi diversi a seconda dello Storage Engine utilizzato.
La scelta dell'Engine e' molto importante poiche' gli Engine hanno prestazioni e funzionalita'
molto diverse tra loro (eg. MyISAM molto efficiente nelle ricerche ed InnoDB con una gestione completa
delle transazioni).
MySQL puo' essere utilizzato in configurazioni complesse.
Nel seguito vengono dati alcuni cenni sull'utilizzo della replicazione,
del cluster NDB (MySQL) e di un failover cluster del sistema operativo.
La replicazione asincrona presenta diversi vantaggi.
Il carico sulla rete non e' elevato, la rete puo' anche avere un'alta latenza, i server e le connessioni possono essere disattivati e la replicazione riprende automaticamente quando la connessione e' nuovamente possibile. E' quindi possibile utilizzare la replicazione sia per distribuire i dati che per disporre di copie aggiornate dei dati con funzioni di disaster recovery.
Dalla versione 4.1 e' stato introdotto il Data Clustering con lo Storage Engine NDB.
Differenti motori MySQL che operano su server distinti accedono ai dati mantenuti allineati tra i diversi storage dall'NDB. In questo caso la configurazione e' Active-Active ed i diversi server MySQL possono essere acceduti tramite un load balancer con notevoli vantaggi prestazionali. Per maggiori dettagli segui il link Qualcosa di piu' su MySQL.
MySQL puo' essere definito come servizio in un Failover Cluster.
Tale modalita' non e' nativa del DB ma puo' essere implementata in modo semplice
sui piu' diffusi failover cluster Linux (eg. Heartbeat) e su cluster commerciali.
Vengono anche forniti gli Enterprise Agent per Veritas VCS.
Naturalmente la configurazione in cluster richiede l'utilizzo di storage condiviso o replicato tra i nodi.
E' anche possibile una configurazione con minori requisiti HW utilizzando la replicazione dei dati
ed un cluster per la sola definizione dell'IP virtuale per l'accesso al nodo corrente.
Anche se si tratta di una soluzione non completamente sicura puo' essere utilizzata
come alternativa a piu' complesse soluzioni di disaster recovery.
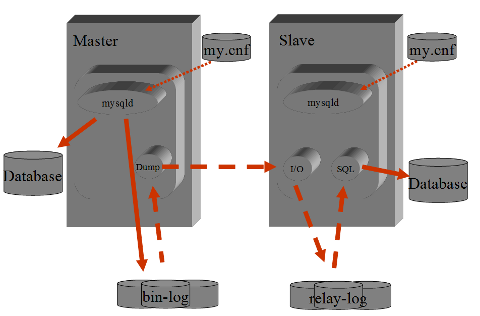
MySQL Replication
La funzionalita' di replica su MySQL e' semplice da configurare, non richiede praticamente manutenzione,
e' molto flessibile, e non aggiunge carico al database Master. E' percio' comprensibile che sia molto utilizzata.
Gli impieghi sono diversi: per disporre di copie di database in HA,
per creare una batteria di database per siti web molto, molto acceduti, per semplificare modalita' e procedure di backup, ...
La replicazione utilizza alcuni processi e file di appoggio.
Il processo mysqld sul Master salva sul file bin-log gli statement di DML e DDL che sono eseguiti sulla base dati.
Lo Slave utilizza piu' thread.
Il primo e' una connessione remota al Master ed ha il compito di raccogliere i dati dal bin-log (BinLog Dump)
ed e' sempre attivo.
Gli altri thread sono locali ed hanno il compito di ricevere il contenuto del bin-log (Slave I/O) e di applicarlo alla base dati (Slave SQL). In caso d'errore nell'inserimento dei dati il thread Slave SQL si interrompe mentre lo Slave I/O continua a raccogliere i dati dal Master. Con show slave status\G si ottiene l'indicazione dell'errore occorso; una volta corretto il problema la replicazione riprende dal punto in cui si era interrotta applicando il relay-log.
Il Master si occupa di loggare su file (il bin-log file) tutti gli statement
che vengono eseguiti sulla base dati e che operano una qualche modifica (DML e DDL).
Lo Slave si collega con un thread al Master, raccoglie il contenuto del bin-log,
lo trasferisce in locale e quindi si occupa di applicarlo alla base dati.
La parte svolta dal Master e' molto semplice, poco onerosa e "stupida".
In pratica ospita una sessione client per ogni Slave configurato.
Tutte le opzioni di configurazione e la gestione ricadono sullo Slave.
E' questo che si occupa della ricezione dei log, del loro allienamento
e della corretta applicazione degli statement SQL sulla base dati.
Sono possibili differenti configurazioni. Un Master puo' servire piu' Slave.
Uno Slave puo' essere a sua volta Master di altri Slave.
Possono essere esclusi/inclusi dalla replicazione database, tabelle, ...
Il Master e gli Slave possono essere differenti praticamente in tutto:
Storage Engine, parametri di configurazione/tuning, versioni, struttura, ...
Oltre che in soluzioni per la continuita' operativa la replicazione MySQL e' impiegata utilmente anche su problematiche di Big Data per separare (sharding) le basi dati ed utilizzare in modo massivo database in sola lettura.
MySQL NDB Cluster
MySQL puo' essere utilizzato in configurazione di cluster con cui i dati vengono partizionati e distribuiti su piu' sistemi permettendo di disporre continuamente delle informazione anche in caso di caduta di un server.
Il cluster e' costituito da nodi che svolgono tra differenti funzioni:
- MySQL deamon: il server MySQL che eseguere i comandi SQL degli utenti e richiede i dati agli Storage Node quando viene utilizzato l'Engine NDB
- Storage Node: mantiene i dati in forma replicata sincronizzandosi con gli altri Storage Node
- Management Node: si occupa della gestione degli Storage Node, mantiene la configurazione
Il Management Node non deve necessariamente essere sempre attivo, e' necessario solo durante le attivita' di configurazione o di rejoin. Ma, anche se e' spento, la continuita' di servizio e' garantita.
Gli Storage Node mantengono i dati allineati tra loro utilizzando un'ampia cache in memoria
e dialogando sulla porta 1186 con il nodo di Management. Il cluster mantiene in memoria l'intero DB.
L'occupazione per ogni singolo nodo e' pari alla dimensione del DB per il numero di repliche (due di default)
diviso il numero di storage node.
Agli Storage Node si connettono i processi mysqld.
Si tratta di processi distinti
che possono essere eseguiti su server differenti:
un insieme di processi realizza lo Storage NDB, i server mysqld sono invece i gestori delle richieste SQL.
I dati vengono mantenuti sul file system. Ogni database corrisponde ad una directory
posta sotto /var/lib/mysql-cluster. All'interno della directory si trovano i file per ogni tabella.
Una configurazione senza single point of failure prevede l'utilizzo di almeno 3 sistemi.
Per disporre di una configurazione fault tolerant sono necessari due server che ospitano MySQL e lo Storage Node,
un terzo server e' utilizzato come stazione di management per l'NDB.
Gli accessi ai server SQL possono essere bilanciati con un load balancer HW o SW, con un DNS in round robin o applicativamente.
E' importante sottolineare che l'Engine NDB e' differente dall'Engine InnoDB
ed ha funzionalita' limitate
rispetto a questo.
La soluzione NDB cluster e' utilizzata quando la base dati ha pochissime variazioni
(mal supporta il DDL) e gli accessi avvengono principalmente per primary key.

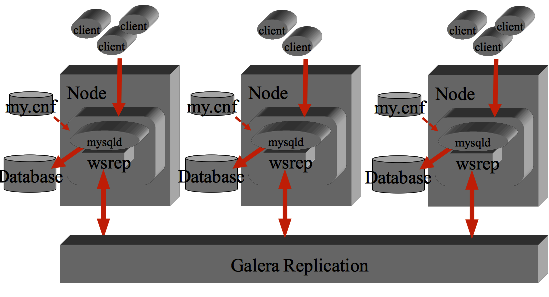
MySQL Galera Cluster
Un'implementazione recente ed interessante basata su MySQL e' Galera Cluster.
Galera Cluster implementa una replica sincrona multimaster basata su una versione modificata
dell'Engine InnoDB.
Il cluster e' costituito da piu' nodi (generalmente tre o piu') tra loro paritetici
che operano ciascuno sulla propria base dati locale.
Galera utilizza una versione MySQL che contiene il Plug-in WSREP
(Write-Set Replication)
La patch modifica la fase di commit che viene inviata su tutti i nodi anziche' solo
in locale.
L'algoritmo utilizzato non e' il two-phase commit (considerato da sempre sicuro ma lento)
ma la replicazione certification-based. Si tratta di un algoritmo ottimistico
che verifica se la transazione puo' essere applicata su tutti i restanti nodi
del cluster senza conflitti al momento del commit.
Se la risposta e' positiva la transazione viene confermata altrimenti
si effettua il rollback locale.
Tipicamente i nodi Galera sono tutti simili tra loro, allocati nello stesso
datacenter con connessioni ad alta velocita'/bassa latenza
ed infine bilanciati esternamente da un load balancer (eg. HAProxy).
In qualche caso e' necessario
modificare le applicazioni che debbono
utilizzare sempre chiavi primarie,
"sopportare" gli eventuali rollback
ed utilizzare writeset di dimensioni ragionevoli.
Per ridurre la frequenza dei conflitti si cerca di indirizzare
le scritture su un solo server, ma possono essere implementate diverse strategie.
Anche se di recente introduzione
la pololarita' di Galera Cluster
sta crescendo anche perche' ben supporta il deployment in Cloud.
MySQL InnoDB Cluster
Un'implementazione ancora piu' recente [NdA disponibile dal 12 aprile 2017]
e' il MySQL InnoDB Cluster.
Ulteriori informazioni
Alcune pagine che riportano maggiori dettagli su argomenti inerenti le problematiche di Business Continuity sono:
Qualcosa in piu' su MySQL,
MySQL Replication,
Scalabilita' e Cloud computing con MySQL,
MySQL Cluster (NDB),
Galera Cluster for MySQL,
MySQL InnoDB Cluster,
...
Naturalmente il sito ufficiale e' www.mysql.com
che contiene tutta la documentazione.
Questa tabella riporta le diverse versioni,
le principali funzionalita' ed il supporto disponibile.
PostgreSQL
PostgreSQL e' considerato il piu' completo e robusto RDBMS disponibile come free software.
Le sue prestazioni ed affidabilita' sono paragonabili a quelle dei piu' diffusi RDBMS commerciali.
I suoi principali punti di forza sono:
- Free! Gratis per tutti gli utilizzi, anche commerciali (Open Source con licenza BSD)
- Gestione completa ed efficiente delle transazioni: ACID properties
- Ottime prestazioni ed affidabilita'
- SQL ricco di funzionalita' tra cui: ANSI-SQL 92/99...2008, trigger, stored functions, subquery,
referential integrity, inheritance, 2PC, ...
- Funzionalita' complete Object-Relational
- Strumenti di amministrazione e gestione completi
- Funzionalita' di replicazione, possibilita' di configurazione in HA, ...
Su un database cluster PostgreSQL vengono creati uno o piu' database;
il database dal nome postgres e' sempre presente.
Ogni database ha un suo catalogo (data dictionary).
All'interno di ogni database vengono creati uno o piu' schema;
lo schema public viene creato per default. All'interno degli schema vengono create le table.
Per identificare una tabella si utilizza la sintassi schema.table.
Su un database cluster PostgreSQL vengono autorizzati piu' utenti e ruoli
(dalla versione 8.1 sono stati unificati).
Un utente puo' lavorare sui diversi database se e' autorizzato,
ma deve scegliere su quale database operare al momento della connessione.
Funzionalita'
PostgreSQL ha un insieme molto ampio di funzionalita' avanzate. Riportarle tutte sarebbe inutilmente lungo, ma cercheremo di dare un accenno alle principali.
PostgreSQL ha un ottimo livello di compatibilita' SQL anche rispetto ai piu' recenti Standard SQL (ANSI/ISO SQL:2008) e supporta da sempre funzionalita' quali: funzioni, viste, subquery, foreign key, constraints, transazioni, locking, stored procedures, trigger, partitioning, ... quindi tutto questo lo diamo per scontato!
PostgreSQL supporta nativamente 4 linguaggi procedurali: PL/PgSQL (il principale), PL/Tcl, PL/Perl e PL/Python (nelle diverse versioni). Oltre a questi sono mantenuti da progetti esterni innumerevoli altri linguaggi procedurali quali: PL/Java, PL/Ruby, PL/PHP, PL/sh, ...
PostgreSQL e' una base dati Object-Relational. La definizione di una tabella che "eredita" caratteristiche da un'altra e' molto semplice e richiede una sola clausola aggiuntiva: INHERITS(object_name). Con la definizione ad oggetti possono essere implementati in modo semplice e chiaro costrutti anche molto complessi (eg. Partitioning).
PostgreSQL permette la definizione di tipi definiti dall'utente, di domini, di funzioni, di operatori, di classi di operatori per gli indici, ...
PosgreSQL ha un supporto molto completo per le diverse tecnologie sugli indici.
Gli indici maggiormente utilizzati sono i B-tree (indici bilanciati),
comuni in effetti su tutte le basi dati relazionali.
Sono ovviamente supportati in PostgreSQL indici univoci e gli indici concatenati su piu' chiavi.
Oltre ai B-tree sono disponibili anche indici Hash, GiST (Generalized Search Tree), GIN (Generalized Inverted Index).
In realta' gli indici GiST e GIN sono "familie" di indici
che possono essere estese per supportare datatype ed operatori anche molto complessi.
PostgreSQL supporta indici parziali, ovvero costruiti solo su una parte della tabella cui fanno riferimento.
PostgreSQL supporta indici su espressioni.
Architettura
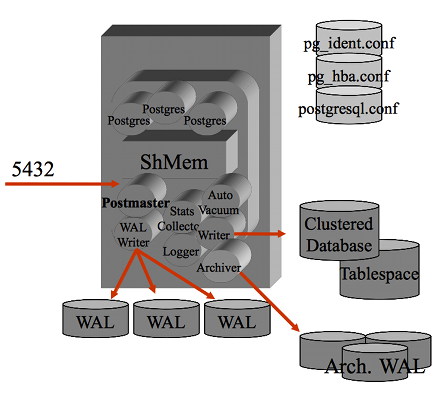 L'architettura di PostgreSQL prevede una serie di processi.
Il primo processo postmaster e' il processo principale che si occupa della gestione delle connessioni (e' in LISTEN sulla porta socket di default 5432) ed e' il "padre" di tutti i processi, sia di sistema (eg. wal writer) sia quelli relativi alle connessione utente. Su ogni processo utente e' riportata l'origine e l'attivita' in corso... molto comodo per il DBA e per il sistemista! Tutti i processi girano come utente postgres ed eseguono un attach al segmento di shared memory su cui vengono mantenuti buffer e lock. Nel tempo l'architettura dei processi si e' matenuta sempre simile anche se nelle versioni piu' recenti sono presenti piu' processi di sistema.
PostgreSQL utilizza i meccanismi di IPC standard su Unix. Vengono utilizzati alcuni semafori ed un segmento shared memory. Naturalmente la dimensione di questo segmento dipende dai parametri utilizzati nella configurazione (eg. shared_buffers).
L'architettura di PostgreSQL prevede una serie di processi.
Il primo processo postmaster e' il processo principale che si occupa della gestione delle connessioni (e' in LISTEN sulla porta socket di default 5432) ed e' il "padre" di tutti i processi, sia di sistema (eg. wal writer) sia quelli relativi alle connessione utente. Su ogni processo utente e' riportata l'origine e l'attivita' in corso... molto comodo per il DBA e per il sistemista! Tutti i processi girano come utente postgres ed eseguono un attach al segmento di shared memory su cui vengono mantenuti buffer e lock. Nel tempo l'architettura dei processi si e' matenuta sempre simile anche se nelle versioni piu' recenti sono presenti piu' processi di sistema.
PostgreSQL utilizza i meccanismi di IPC standard su Unix. Vengono utilizzati alcuni semafori ed un segmento shared memory. Naturalmente la dimensione di questo segmento dipende dai parametri utilizzati nella configurazione (eg. shared_buffers).
La gestione delle transazioni in PostgreSQL avviene con la tecnica del MVCC (Multiversion Concurrency Control) e la consistenza dei dati su disco e' assicurata con il logging (Write-Ahead Logging). L'isolation level di default e' Read Committed, ma sono supportati tutti gli isolation level previsti dallo standard.
In pratica ogni transazione al commit effettua una scrittura sul WAL: in questo modo e' certo che le attivita' confermate alla transazione sono state scritte su disco. La scrittura sul WAL e' sequenziale e molto veloce. La scrittura effettiva sui file delle tabelle e degli indici viene effettuata successivamente ottimizzando le seek e le scritture sul disco.
Il Clustered Database e' la struttura del file system che contiene i dati. All'interno vengono mantenuti i file di configurazione ($PGDATA/*.conf), i log delle transazioni (nella directory $PGDATA/pg_xlog) e le strutture interne della base dati che contengono tabelle ed indici (suddivise per database nella directory $PGDATA/base). Ad ogni oggetto (tabella, indice, ...) corrisponde ad un file (indicato da pg_class.relfilenode), e sono tipicamente presenti file ulteriori per la gestione degli spazi come la free space map (suffisso _fsm) e visibilty map (suffisso _vm).
Di default il blocco ha dimensione 8KB mentre i wal log hanno come dimensione 16MB.
Le dimensioni del blocco possono essere variate ma e' necessario ricompilare PostgreSQL e generalmente tale modifica non presenta vantaggi significativi.
Una tupla deve essere contenuta in un solo blocco. Per la gestione dei datatype di maggiori dimensioni viene utilizzato il TOAST (The Oversized-Attribute Storage Technique) che consente di memorizzare dati fino ad 1GB (230). Sono utilizzabili diverse organizzazioni dei dati come struttura interna per soddisfare i piu' specifici requisiti di memorizzazione. Tutti gli indici sono trattati come indici secondari: hanno quindi una struttura dedicata ciascuno (un file). I tipi di indice disponibili sono: B-tree, Hash, GiST (Generalized Search Tree) e GIN (Generalized Inverted Index).
All'interno di ogni database viene mantenuto un ricco Catalog che consente di controllare con query SQL gli oggetti presenti nella base dati (eg. pg_database, pg_class, pg_tables, ...) e l'andamento delle attivita' (eg. pg_locks, pg_settings, pg_statistic, pg_stats,...).
Quando viene sottomesso uno statement SQL l'ottimizzatore determina il query tree da utilizzare con un algoritmo genetico basato sulle statistiche. PostgreSQL utilizza un ottimizzatore cost-based. L'algoritmo genetico e' utilizzato per ridurre il numero delle combinazioni dei possibili percorsi di ricerca.
Nelle ultime versioni di PostgreSQL l'attivita' di analyze (raccolta delle statistiche necessarie all'ottimizzatore) viene schedulata in automatico.
Replication - Streaming Replication - Hot Standby
PostgreSQL puo' essere utilizzato in configurazioni complesse con diversi livelli di HA (High Availability), DR (Disaster Recovery), replicazione e Load Balancing.
Alcune configurazioni richiedono un hardware (eg. NAS) o un software di base specifico
(eg. fail over cluster: RHCS, VCS), altre utilizzano un software di middleware aggiuntivo (eg. Slony, Bucardo), ...
Nel seguito vengono dati alcuni cenni sulla configurazione di PostgreSQL in Hot Standby con replicazione in streaming.
Si tratta di features introdotte dalla versione 9.0, disponibili nella distribuzione PostgreSQL
e che non richiedono nessun prodotto aggiuntivo o attivita' di integrazione.
La configurazione della replicazione in PostgreSQL e' simile quella del Point In Time Recovery.
La principale differenza e' che il database di partenza non e' stato perduto
ma e' ancora perfettamente attivo sul server Primary.
Sul primario debbono essere presenti parametri analoghi a quelli per il continuos archiving.
Il server secondario o di Warm Standby deve essere installato e configurato come il server primario
(stesse versioni, directory, utenti, ...)
e va allineato inizialmente con un restore di un backup fisico recente del primario.
Sul server secondario il file recovery.conf deve essere adeguatamente configurato.
Attivando il secondario questo entra in stato di recovery ed allinea le transazioni occorse raccogliendo
i WAL file ed applicandoli alla base dati.
La replicazione in PostgreSQL non comporta un rallentamento del Primary
e possono essere utilizzati piu' server di Standby eventualmente distribuiti su rete geografica
in una soluzione di Disaster Recovery.
Per attivare la Streaming Replication va solo aggiunto un parametro sul file recovery.conf.
Tale parametro imposta i parametri di connessione della streaming replication:
i WAL vengono trasmessi in rete immediatamente e non raccolti da file al loro riempimento.
L'utente repl deve essere definito come superuser sul primary server
ed abilitato alla connessione nel file pg_hba.conf indicando come database replication.
Nel caso in cui la connessione verso il Primary non avvenga,
il server in Standby si mantiene comunque allineato applicando i log file.
Con la semplice aggiunta del un parametro il server in Standby diventa utilizzabile in read-only dagli utenti.
In questo caso si definisce server in Hot Standby.
Sul secondario non possono essere effettuate modifiche sulla base dati,
neanche per oggetti temporanei, e le sessioni utente hanno limiti maggiori rispetto al Primary.
Tuttavia in questo modo possono essere svolte sullo Standby report complessi, query pesanti, ...
Ulteriori informazioni
Alcune pagine che riportano maggiori dettagli su argomenti inerenti le problematiche di Business Continuity sono:
PostgreSQL: un'introduzione,
Qualcosa in piu' su PostgreSQL 9.0,
Configurazione della replica in PostgreSQL,
...
Naturalmente il sito ufficiale e' www.postgres.com
che contiene tutta la documentazione.
Questa tabella riporta le diverse versioni,
le principali funzionalita' ed il supporto disponibile.
Microsoft SQL Server
Microsoft SQL Server e' l'RDBMS fornito da Microsoft e nato da una partnership con SYBASE
iniziata alla fine degli anni 80.
Nel 1993 esce la prima versione del DB per windows (SQL Server 4.2);
nel 95 esce la prima versione di SQL Server Pure Microsoft (SQL Server 6.0).
Ma e' con la versione 7 nel 98 che comincia a riscontrare successo grazie ad un interfaccia di gestione totalmente grafica
che ne semplifica notevolmente la gestione, e sopratutto in virtu' dei costi decisamente
interessanti rispetto ai concorrenti, in primis Oracle.
Sono disponibili inoltre versioni gratuite con limitazioni sulla RAM e Spazio disco utilizzato,
MSDE (SQL Server 2000 a 32-bit) e successivamente le versioni Express 2005 e 2008.
Esiste anche una versione SQL Server Mobile e ora SQL Server Compact per gli ambienti Mobile o con poche risorse a disposizione.
Microsoft SQL Server usa una variante del linguaggio SQL chiamata T-SQL (Transact SQL), comunica nella rete grazie ad un protocollo chiamato TDS (Tabular Data Stream) che può essere trasportato da TCP/IP, Named Pipe e Shared Memory, supporta il protocollo ODBC. Il servizio di default risponde sulla porta 1433.
Dalla versione 2005 supporta tutte le principali funzionalità enterprise (ed in particolare XML in forma nativa), ed e' completamente paragonabile ad Oracle DB, in particolare su ambienti windows (SQL Server e' solo disponibile su ambienti MS Windows). Su tale ambiente SQL Server e' generalmente superiore ad Oracle, in quanto a prestazioni.
Principali servizi:
- Service Borker. E' una parte del motore database e gestisce la piattaforma di messaging
e queue con le applicazioni in maniera asincrona in particolare e essenziale per integrazioni con Exchange
- Replication Service. Servizi per replicare e sincronizzare oggetti database od interi database,
in particolare con tre modalità:
- Transaction replication – ogni transazione effettuata nel DB master e' sincronizzata nei DB Subscribed (target) che si aggiornano con la stessa operazione, la replica transazionale sincronizza le banche dati in tempo reale
- Merge Replication – Le modifiche apportate sia al DB Master che ai DB Subscriber sono monitorati e periodicamente le modifiche sono sincronizzate in modalità bi-direzionale
- Snapshot replication - La replica snapshot pubblica una copia istantanea di tutto il DB Master ai DB Subscribed. Ulteriori modifiche non sono gestite.
- Analysis Service. Aggiunge funzionalità OLAP e Data Mining al Database, necessità di IIS
- Reporting Server. Ambiente per la generazione di report sui dati del DB e la loro pubblicazione agli utenti. Necessita di IIS
- Integration Service. Ambiente di sviluppo per costruire servizi di integrazione come trasferimento dati da/a altri DB o invio di mail.
- Full Text Search Service. Servizio di indicizzazione testuale in stile motore di ricerca
E’ possibile effettuare configurazioni di clustering adottando completamente soluzioni Microsoft dalla versione 2000.
Nella versione 2005 non e' supportato il cluster per il servizio di Reporting Server,
a causa di problematiche di sicurezza introdotte da tale versione ma il problema
e' stato superato nella versione 2008.
Ulteriori informazioni
Naturalmente il sito ufficiale e'
www.microsoft.com
che contiene tutta la
documentazione.
Questa tabella riporta le diverse versioni,
le principali funzionalita' ed il supporto disponibile.
Individuazione alternative
Le alternative adatte ad una soluzione di Business Continuity per le basi dati sono molteplici e dipendono in modo significativo dalla tecnologia dell'RDBMS in oggetto. Per tanto per ogni gestore di basi dati vengono analizate le diverse possibilita'.
Le tabelle seguenti riassumono i principali elementi utili all'analisi delle diverse alternative.
Come gia' riportato, anche solo basandosi sulle funzionalita' offerte dagli RDBMS,
le alternative sono molteplici.
Per ragioni tecniche l'elenco seguente e' organizzato in differenti sezioni dedicate a ciascun RDBMS.
- Oracle:
RAC,
Data Guard,
Distribuited Database,
Advanced Replication,
Golden Gate
- MySQL;
Replication,
NDB,
Galera Cluster
- PostgreSQL;
Replication,
Foreign objects
- MS-SQLServer:
Cluster
Alcune tecnologie basate sui sistemi e gli ambienti ospite consentono di avere funzionalita' di Business Continuity anche sulle basi dati ospitate.
- OS clustering: VCS Global Cluster, MS Cluster, ...
- Volume replication: VVR, DRBD, ...
- Storage replication: Hitachi TrueCopy / Universal Replicator (HUR), HP CA, IBM PPR, IBM XRC,
EMC SRDF (Symmetrix Remote Data Facility), EMC VPLEX, ...
- Virtualizzazione: VMWare HA, DRS, SRM, ...
Naturalmente ha molta importanza l'ambiente in cui i database sono ospitati.
Si puo' avere la configurazione piu' sofisticata di cluster tra piu' nodi fisici...
ma se questi sono alimentati con un'unica presa di corrente e' evidente quale sia lo
SPOF (Single Point Of Failure)!
I datacenter vengono classificati (ANSI TIA-942) in quattro livelli TIER I, II, III e IV,
come riassunto in questa tabella:
| Tier | Ridondanza | Disponibilita' | Interruzione massima (ore/anno)
|
| I | Nessuna | 99.67% | 28.8
|
| II | Parziale | 99.75% | 22.0
|
| III | N+1 | 99.982% | 1.6
|
| IV | 2N+1 | 99.995% | 0.8
|
Su un DC Tier IV tutte le alimentazioni, il raffreddamento, le componenti di rete sono ridondati;
i dischi sono sostituibili in modalita' Hot Swap, ...
Caratteristiche ideali sopratutto per le basi dati.
L'AgiID classifica invece le soluzioni tecnologiche di CO/DR in 6 livelli o Tier
[NdA per non confonderli con la precedente classificazione sono indicati con cifre arabe].
La seguente tabella riporta la classificazione raccomandata:
| Tier | RTO max | RPO max | Caratteristiche sito
|
| 1 | >7g | 7g | Sito di DR esistente ma con risorse elaborative reperibili a richiesta
|
| 2 | 7g | 7g | HW disponibile ma con prestazioni ridotte; copia dati su supporti rimovibili
|
| 3 | 3g | 1g | HW disponibile ma con prestazioni ridotte; backup trasmesso elettronicamente
|
| 4 | 3g | 4h | Sito duplicato; aggiornamento asincrono
|
| 5 | 4h | 4' | Aggiornamento sincrono dei dati
|
| 6 | 1h | 0 | Trasferimento automatico del carico di lavoro tra i siti
|
Senza entrare nel dettaglio di ciascuna soluzione tecnologica,
nel seguito verranno riportati gli elementi di maggiore interesse riferiti ai diversi RDBMS.
Valutazione costi e benefici
Per ogni alternativa tecnologica vanno
stimati i costi che debbono tenere conto dell'impegno, delle infrastrutture e delle licenze necessarie.
Di converso i benefici sono la riduzione dei tempi RTO ed RPO, la semplicità realizzativa e gestionale.
La tabella seguente riporta gli elementi di maggior interesse riportando
le indicazioni per la determinazione dei costi e dei benefici di ciascuna alternativa analizzata.
Anche se non sono state analizzate in dettaglio in questo documento vengono prima riportate
le soluzioni a livello di ambiente e sistema operativo che sono
trasversali rispetto ai Database:
| Soluzione tecnologica | Costi | Benefici
|
| OS clustering
| Richiede un'installazione e configurazione specifica sui server ospiti.
Si tratta di una soluzione tipicamente "trasparente" per i gestori di basi dati quindi applicabile nella maggioranza
delle situazioni. Spesso gli ambienti di cluster forniscono plugin specifici per i database (eg. Oracle Agent su VCS).
| E' una delle tecnologie maggiormente utilizzate per le basi dati per la BC.
|
| Volume replication
| Richiede uno specifico software di replicazione che deve garantire il write order. Puo' avere un impatto sulle prestazioni/limiti dei sistemi ospite.
| Si tratta di una soluzione tipicamente "trasparente" per i gestori di basi dati.
|
| Storage replication
| Richiede HW dedicato.
| Si tratta di una soluzione "trasparente" per i gestori di basi dati.
|
| Virtualizzazione
| Richiede una farm con relativo HW e SW. Vi e' un impatto sensibile sulle prestazioni, in particolare sull I/O ed e' quindi adatta a basi dati poco utilizzate e/o di modeste dimensioni, anche se la continua evoluzione tecnologica continua a spostare verso l'alto il perimetro delle basi dati non virtualizzabili. Alcuni RDBMS non sono certificati in ambiente virtualizzato o hanno una politica di licensing non conveniente.
| Le funzionalita' di HA e DRS (in terminologia VMware) consentono un'elevata affidabilita'.
Il vantaggio in flessibilita' e' notevole.
|
Per quanto riguarda le alternative disponibili a livello di database
sono da considerare le seguenti soluzioni tecnologiche:
| Soluzione tecnologica | Costi | Benefici
|
| Oracle RAC
| La configurazione di Oracle in RAC e' piu' complessa, soprattutto nella fase iniziale di analisi e certificazione dell'HW e SW di base su cui le limitazioni sono significative.
I nodi in RAC condividono lo storage che deve avere una bassa latenza. E' quindi fortemente consigliata un'infrastruttura dedicata.
L'utilizzo del RAC porta ad un aumento dei costi di licenza da 50% (da listino).
| Con il RAC le istanze sono in configurazione Active-Active, pertanto in caso di fault di un solo nodo/istanza il servizio non viene interrotto e puo' proseguire sugli altri nodi attivi.
Si tratta della soluzione tecnologicamente piu' affidabile e completa per la BC.
|
| Oracle Data Guard
| L'implementazione di una soluzione con Data Guard non ha particolari impatti rispetto ad una configurazione di produzione. E' necessario che il log archiving sia attivo e, naturalmente, richiede l'HW e l'acquisto delle relative licenze.
| Il vantaggio maggiore della soluzione DG sta nel limitare al massimo l'RTO poiche' l'istanza secondaria e' costantemente aggiornata con l'ambiente di produzione ed e' gia' attiva.
|
| Oracle distributed DB
| Oracle consente la creazione di basi dati distribuite da decenni. Sebbene tale tecnologia sia molto affidabile e diffusa gli impatti sulla logica applicativa sono importanti e quindi non e' adatta come soluzione generalizzata. Non sono richieste licenze o opzioni specifiche. L'utilizzo di transazioni distribuite consente di avere un'aggiornamento coordinato (mediante il protocollo di Two Phase Commit) tra basi dati diverse.
| Le transazioni distribuite non hanno molte applicazioni per la BC o il DR poiche' tutte le basi dati debbono essere sempre attive per effettuare la COMMIT. L'unico vantaggio e' quello della replica dei dati ma sono richieste importanti modifiche applicative per operare in situazione degradata.
|
| Oracle Advanced Replication
| L'Advanced Replication e' un componente opzionale di Oracle che consente la replica sincrona o asincrona di oggetti della base dati. Nel caso in cui un'istanza Oracle non sia raggiungibile l'aggiornamento e' comunque effettuato in modo automatico.
| L'Advanced Replication consente la replicazione automatica di specifici oggetti della base dati. Puo' essere utilizzata per la replica di alcune tabelle ritenute importati per le applicazioni, ma non in modo generalizzato.
|
| Oracle GoldenGate
| Oracle GoldenGate e' un prodotto Oracle che consente la replica
asincrona di oggetti della base dati. Ha un costo di licenza a parte rispetto all'RDBMS e
la sua corretta configurazione richiede esperienza.
| Oracle GoldenGate permette una replica bidirezionale, tra versioni diverse di database e,
seppure con diverse limitazioni e l'uso di componenti addizionali, tra database eterogenei.
|
| MySQL replication
| La configurazione e la gestione della replication con MySQL e' relativamente semplice ed ha modesti requisiti. Trasformare un'instanza "secondaria" in master richiede alcuni comandi manuali.
Di converso pero' non consente una definzione precisa dell'RPO e non ha una gestione automatica.
| Gestione semplice (anche se manuale), aggiornamento asicrono ma molto veloce, impatto nullo sulle applicazioni. E' una soluzione valida per DR, BC ma anche per la scalabilita' orizzontale e per i backup.
|
| MySQL NDB cluster
| La configurazione in cluster di MySQL richiede l'utilizzo di un Engine specifico: NDB.
Le basi dati sono mantenute principalmente in memoria ed i dati sincronizzati in modo automatico tra i server.
I requisiti in termini di memoria ed i limiti dell'Engine utilizzato rendono la soluzione praticabile solo su applicazioni specifiche molto stabili.
| E' una soluzione adatta ad ambienti che debbono dare la massima continuita' di servizio (eg. billing telefonico). Non e' adatta a basi dati generiche con una notevole variabilita' o basi dati di grandi dimensioni.
|
| Galera cluster for MySQL
| Galera Cluster richiede una versione specifica di MySQL con la patch wsrep.
E' di recente introduzione e la sua gestione richiede una competenza specifica.
| E' una soluzione adatta ad applicazioni specifiche e nelle installazioni in Cloud.
|
| MySQL InnoDB Cluster
| Integrato nell'RDBMS MySQL ma solo per l'Engine InnoDB;
di recentissima introduzione. Richiede tre nodi per fornire fault tolerance.
| Applicabile per soluzioni di BC su applicazioni che utilizzano l'Engine InnoDB.
|
| Postgres Hot Standby in Streaming Replication
| L'implementazione di una soluzione con warm/hot standby non ha particolari impatti rispetto ad una configurazione di produzione. E' necessario che sia attivo il continuous archiving che richiede un certo spazio disco ed una gestione. Con la streaming replication il ritardo del server secondario e' tipicamente limitato a pochi secondi.
| Il vantaggio maggiore della soluzione Standby in streaming replication sta nel limitare al massimo l'RTO poiche' l'istanza secondaria e' costantemente aggiornata con l'ambiente di produzione ed e' gia' attiva. La streaming replication e' disponibile dalla versione 9.0, con le versioni precedenti l'RTO puo' essere parametrizzato ma sale tipicamente alle decine di minuti.
|
| MS-SQL Server cluster
| La configurazione in cluster di SQL Server e' strettamente connessa con il cluster nativo Windows la cui installazione/configurazione non e' banale. Vanno acquisite le relative licenze.
| Consente di disporre di una soluzione di alta affidabilita' in ambito locale o campus.
|
Valutazione dei rischi
Un completo disegno di una soluzione di Business Continuity e di Disaster Recovery
non puo' esimersi da una valutazione dei rischi.
Vanno considerati:
- Rischi Tecnologici: tempi di realizzazione, esperienza e formazione richieste,
Ilimpatto connesso all’innovazione tecnologica
- Rischi Organizzativi: inserimento della nuova tecnologia, impatto sull’utilizzatore,
spesso e' sottovalutata la variazione dei processi aziendali
- Rischi Finanziari: durata superiore alla coperture, incertezza sui costi complessivi,
copertura costi di gestione e manutenzione
Un ulteriore punto di attenzione e' quello relativo alla sicurezza.
Infatti la replicazione dei dati, la disponibilita' di nuovi siti attrezzati,
le ulteriori configurazione di rete, l'accessibilita' a procedure ed elenchi, ...
che sono tutti elementi importati di una realizzazione pratica di un DR
hanno significativi impatti sulla sicurezza.
In modo altrettanto attento deve essere valutato il rischio di perdita di dati
o di indisponibilita' del servizio non implementando nulla!
La tabella seguente riporta gli elementi di maggior interesse relativamente ai rischi di ciascuna alternativa analizzata:
| Soluzione tecnologica | Rischi
|
| Oracle RAC
| E' consigliabile l'utilizzo di RAC solo con le versioni piu' recenti (eg. 11gR2).
Oracle RAC e' "LA" soluzione Oracle per la Business Continuity nelle configurazioni in Campus.
Non e' invece adatta per problemi di costi e di vincoli tecnologici al Disaster Recovery.
La gestione di basi dati con RAC richiede specifiche competenze ed introduce una maggiore complessita'.
|
| Oracle Data Guard
| DG e' disponibile (con nomi di prodotto diversi) ed affidabile su tutte le versioni Oracle supportate.
Oracle DG e' "LA" soluzione Oracle per il Disaster Recovery.
L'utilizzo in modalita' Active presenta vantaggi solo in rari casi.
Il maggior costo rispetto ad un "normale" restore su remoto introduce un maggior onere in termini di licenze.
|
| Oracle GoldenGate
| GoldenGate ha funzionalita' molto avanzate quali l'aggiornamento bidirezionale ed il supporto
di database eterogenei.
Richiede una licenza specifica e notevole esperienza per una corretta completa configurazione.
|
| MySQL replication
| Si tratta della soluzione piu' comunemente adottata per MySQL anche per i bassi costi e la semplicita'.
E' utilizzata ampliamente anche su database di dimensioni e con accessi molto elevati per avere una miglior scalabilita' orizzontale (sharding).
La verifica del corretto fuzionamento richiede verifiche da parte dei DBA.
|
| MySQL NDB cluster
| Utilizzabile solo su basi dati con caratteristiche particolari poiche' richiede l'utilizzo di un Engine specifico.
Maggiore complessita' ed impatti applicativi sono i sui limiti maggiori.
|
| Galera cluster for MySQL
| Ha un impatto sulle applicazioni che debbono utilizzare l'Engine InnoDB e gestire
il rollback in caso di deadlock durante la commit.
Piu' adatta ad una soluzione HA che di Disaster Recovery.
|
| MySQL InnoDB cluster
| Le applicazioni che debbono utilizzare l'Engine InnoDB.
Piu' adatta ad una soluzione HA che di Disaster Recovery.
|
| Postgres Hot Standby in Streaming Replication
|
Si tratta della soluzione piu' adatta al disaster recovery fornita direttamente dalla base dati PostgreSQL.
Va gestito il continuous archiving. Necessaria la versione 9.0 o succ.
Il continuous archiving richiede uno spazio disco significativo ed un'attenta gestione nel monitoraggio degli spazi.
|
| MS-SQL Server cluster
| E' la soluzione piu' comunemente utilizzata per l'alta affidabilita' con SQL Server.
Non e' utilizzabile in configurazioni geografiche.
|
Normativa
La trattazione di questo argomento, che non presenta solo aspetti di tipo tecnico,
e' troppo ampia per questa breve pagina di presentazione.
Riportiamo quindi solo alcuni elementi per completezza di visione...
Le soluzioni di Continuita' Operativa sono presenti da moltissimo tempo,
praticamente da sempre nel breve intervallo temporale dell'era informatica.
Per un istituto bancario un DR e' normato da molto tempo
e periodicamente aggiornato
(eg. Linee guida in materia di continuita' operativa)
mentre piu' recenti sono le
Linee guida per il Disaster Recovery della PA,
emesse dall’Agenzia per l’Italia Digitale,
che prevedono l’adozione di un piano di disaster recovery
da parte delle amministrazioni pubbliche...
Mentre per i requisiti di business viene svolta un'analisi dei costi/benefici,
ovviamente quanto previsto dalla normativa invece deve essere garantito in ogni caso.
Le linee guida fornite da
Information Technology Infrastructure Library (ITIL)
forniscono un riferimento preciso basato su Best Pratice
e danno una notevole rilevanza alla
Continuita' Operativa.
La Business Impact Analysis (BIA) e' il punto di partenza
per la progettazione dell'architettura della Business Continuity (BC)
e la sua descrizione nei
piani di continuita' operativa (PCO) e di disaster recovery (PDR).
E' opportuno che i documenti prodotti riportino in modo esplicito i riferimenti
alle norme e disposizioni di cui soddisfano i dettami.
Conclusioni
In questo documento sono state analizzate, in modo sintetico e da diversi punti di vista,
le diverse soluzioni per la continuita' operativa per le basi dati.
L'analisi dettagliata dei requisiti e la conoscenza tecnica di ogni componente dell'architettura HW/SW
guidano l'individuzione della scelta corretta.
Da ultimo ma non per ultimo...
Nella valutazione delle alternative e' fondamentale la conoscenza
degli SLA coniugati all'uso dei dati da parte delle applicazioni/utenti
e l'approccio globale al problema.
Una base dati perfettamente aggiornata ma non raggiungibile
o una pila applicativa non completa
o una procedura di ripristino applicabile da un numero troppo ristretto di tecnici altamente specializzati
...
sono esempi di soluzioni non corrette per la Continuita' Operativa ed il Disaster Recovery.