Oracle RAC
 Oracle RAC e' la configurazione dell'RDBMS Oracle
che consente di implementare servizi in alta affidabilita'.
Oracle RAC e' la configurazione dell'RDBMS Oracle
che consente di implementare servizi in alta affidabilita'.
Un cluster RAC utilizza nodi ed istanze in configurazione
Active-Active garantento il massimo dell'affidabilita' e della
scalabilita' per il database Oracle.
In questo documento ne vengono descritti i principali concetti
ed indicazioni pratiche per la configurazione ed il tuning.
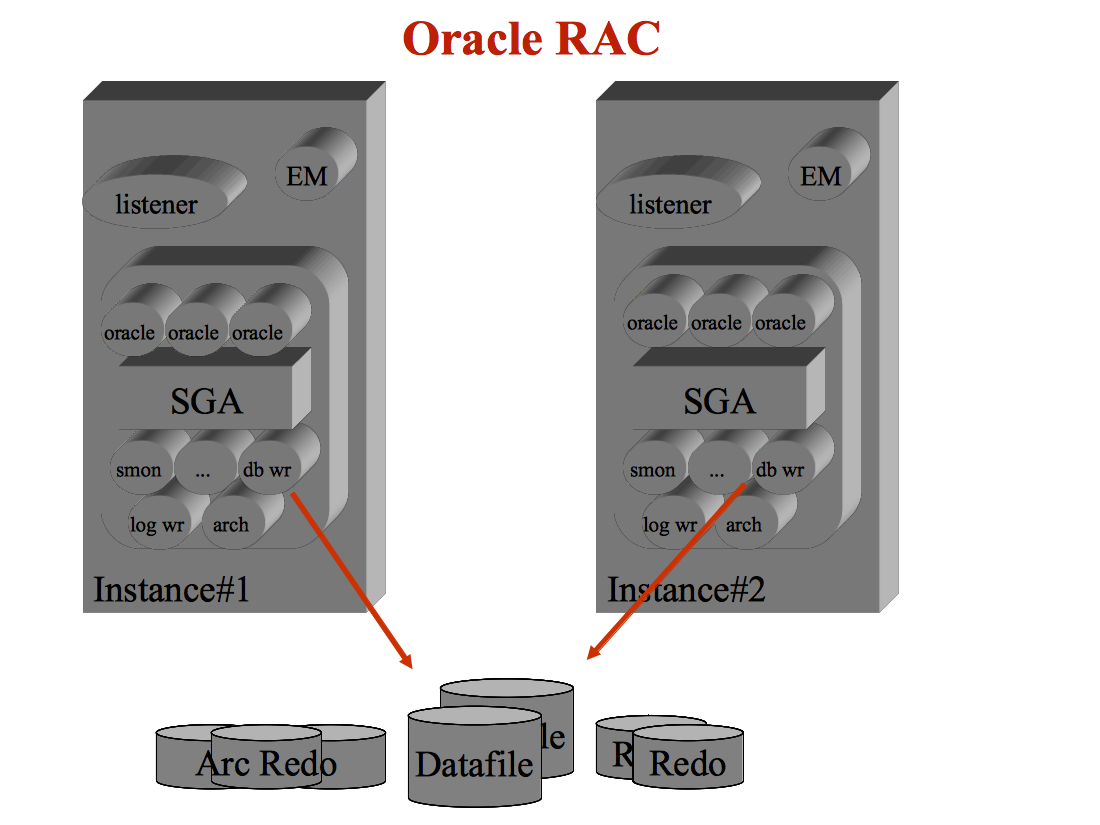
RAC prevede la presenza di due o piu' istanze su server distinti
che accedono allo stesso storage.
Tutte le istanze sono contemporaneamente sempre attive,
in caso di caduta di un server le istanze ospitate sugli altri
nodi proseguono senza disservizi per gli utenti.
La figura precedente riporta una semplice configurazione con due nodi
ma il numero di nodi puo' essere molto piu' elevato ed i nodi possono
avere caratteristiche differenti.
L'installazione e la gestione di un Oracle RAC richiedono competenze
specifiche, questo documento e' indirizzato a chi gia' conosce l'architettura Oracle.
La versione di riferimento utilizzata in questo documento e' la 11g R2 ma sono
citate le principali differenze rispetto ad altre versioni di Oracle.
Le possibilita' di configurazione di RAC sono molteplici,
nel seguito sono riportate le possibilita' principali.
Per maggiori dettagli e' necessario fare riferimento all'ampia documentazione ufficiale.
Architettura
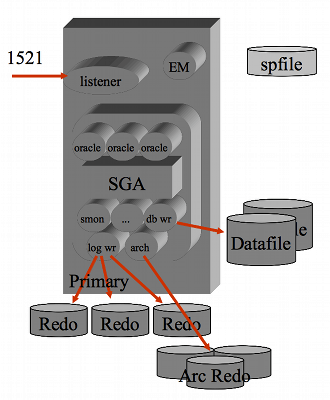 Per comprendere l'architettura di Oracle RAC e' necessario conoscere
l'architettura Oracle in configurazione Single Instance...
in questo documento la diamo per scontata!
Utili sono anche i concetti di base di un Failover Cluster
e dell'ASM.
Per comprendere l'architettura di Oracle RAC e' necessario conoscere
l'architettura Oracle in configurazione Single Instance...
in questo documento la diamo per scontata!
Utili sono anche i concetti di base di un Failover Cluster
e dell'ASM.
Con il RAC si fa riferimento ad un unico database (eg. MYCLU).
Ogni nodo ospita un'istanza del database in RAC
con SID differente (eg. MYCLU1, MYCLU2, MYCLU3).
Ogni istanza ha una propria SGA, un proprio set di processi, ... come se si trattase di istanze singole distinte.
In realta' le istanze del RAC comunicano tra loro e condividono le cache nella Global Cache (GC).
In una tipica configurazione RAC si utilizzano gli SPFILE e l'ASM, che in una configurazione
Single Instance spesso non vengono utilizzati. Le basi dati sono tipicamente in log archiving ed i backup
realizzati a caldo con RMAN.
Ogni nodo ha un'istanza ASM, che serve tutte le istanze presenti sul nodo anche se di database RAC differenti.
I data file sono comuni e condivisi.
I datafile vengono acceduti in parallelo da tutte le istanze, ovviamente
in modo coordinato.
Alcune strutture dati sono dedicate ad una singola istanza per ragioni di efficienza.
Il tablespace temporaneo e' unico ma i datafile sono multipli ed ogni istanza utilizza il proprio.
E' presente un tablespace di UNDO per ogni istanza.
Ogni istanza utilizza differenti gruppi di REDO LOG organizzati in thread.
In realta' le strutture dati descritte sopra non sono mai dedicate alle istanze.
Le altre istanze possono utilizzarle in lettura (eg. UNDO per MVCC) oppure addirittura
in scrittura in condizioni particolari (eg. node failure).
Il data dictionary del RAC non presenta differenze rispetto ad una Single Instance.
Anche le viste prestazionali vengono mantenute con il RAC (eg. V$SESSION)
ma a queste sono affiancate una serie di viste globali che riportano
lo stato di tutte le istanze (eg. GV$SESSION).
I nodi comunicano tra loro su una rete privata che deve avere una bassa latenza
ed elevata affidabilita'. La connessione viene utilizzata sia per la gestione
del cluster (come l'heartbeat di un cluster tradizionale) che per lo scambio
di dati tra i nodi.
I meccanismi di costituzione e sincronizzazione del cluster sono complessi ed
utilizzano sia protocolli di rete che lo storage (eg. Voting Disk).
Per gli aspetti prestazionali e' pero' piu' importante lo scambio di dati tra i nodi.
Quando e' necessario reperire un dato
un'istanza prima lo cerca nella propria cache, quindi effettua una ricerca sulla GC.
Se un'altra istanza aveva gia' in memoria lo stesso blocco questo viene trasferito
attraverso la rete di Interconnect senza necessita' di effettuare una lettura su disco
(physical read).
La gestione della GC ovviamente tiene conto di tutte condizioni nella gestione
dei blocchi di dati: solo lettura/modifica, lock, ...
i dettagli sono po' troppo complessi per questa semplice introduzione,
li lascio alla vostra immaginazione!
 Il protocollo utilizzato per lo scambio dei dati e' leggermente differente
nel caso di due nodi (2-way) rispetto al caso di tre o piu' nodi (3-way).
Nel caso di tre o piu' nodi ha una complessita' leggermente maggiore
e vengono quindi usati eventi distinti.
Il protocollo utilizzato per lo scambio dei dati e' leggermente differente
nel caso di due nodi (2-way) rispetto al caso di tre o piu' nodi (3-way).
Nel caso di tre o piu' nodi ha una complessita' leggermente maggiore
e vengono quindi usati eventi distinti.
I parametri di configurazione delle istanze RAC sono in generale identici,
pero' vi sono eccezioni significative.
Alcuni parametri DEBBONO essere identici (eg. SPFILE),
altri DEBBONO essere differenti (eg. LOCAL_LISTENER),
altri non ha senso siano differenti...
E' possibile che le istanze siano ospitate su nodi con
potenzialita' differenti (eg. memoria), in questo caso e'
necessaria una parametrizzazione che ne tenga dovuto conto.
Dal punto di vista prestazionale i sistemi in RAC presentano una buona scalabilita'
con prestazioni compessive che crescono linearmente all'aumentare del numero di nodi.
Debbono pero' essere tenuti in considerazioni gli aspetto relativi al parallelismo ed
al locking. L'architettura RAC condivide tutto lo storage con i relativi vantaggi e problemi.
Tipicamente si cerca di mantenere lo stesso carico tra tutti i nodi
utilizzando una tecnica di bilanciamento.
In alcuni casi e' pero' vantaggioso il Functional Load Balancing.
Con il Functional Load Balancing si utilizzano in modo preferenziale
nodi diversi per applicazioni diverse. In questo modo il carico risulta
meno bilanciato ma e' possibile ridurre le contese sulla GC.
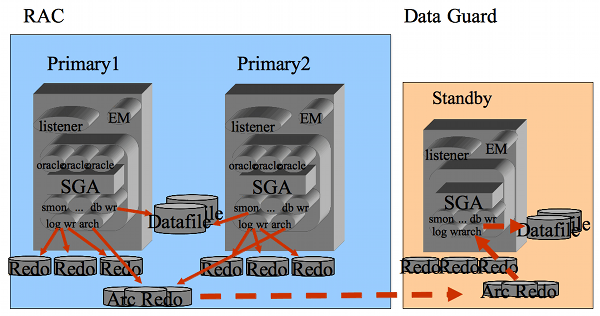
L'architettura del RAC si complementa con quella di
Data Guard che fornisce le funzionalita' di DR (Disaster Recovery).
Nella figura seguente sono riportate le principali interazioni tra le istanze
RAC e l'istanza secondaria DG. Le istanze RAC condividono lo storage ed accedono
agli stessi data file. Le istanze RAC sono connesse con una rete privata ad alta velocita'
e bassa latenza mentre le istanze DG possono essere connesse con reti geografiche anche
ad alta latenza. La soluzione RAC+DG e' quella che ottimizza gli RPO ed RTO
fornendo un'architettura in HA ed altamente scalabile.
Tutto chiaro? Davvero?? Complimenti!
Installazione
L'installazione di RAC richiede l'installazione di
due componenti differenti che utilizzano
utenze ed ORACLE_HOME differenti:
- Grid Infrastructure
- Database
L'installazione delle due componenti deve essere eseguita nell'ordine.
Prima e' necessario
installare Oracle Grid Infrastructure
che e' necessaria per la componente Clusterware e per l'ASM.
Rispetto a quanto descritto nel documento
va scelta l'opzione "Install and Configure Grid Infrastructure for a Cluster"
che richiede la definizione degli indirizzi dei nodi del RAC.
Quando si utilizza la Grid Infrastructure il listener utilizzato e' quello
dell'utente grid.
Poiche' vi sono aspetti legati sia all'installazione che all'utilizzo
abbiamo raccolto tutti gli elementi in un capitolo apposito.
L'installazione di Oracle RDBMS e' invece
molto simile a quella di una single instance: basta scegliere le opzioni corrette.
Gestione
Dal punto di vista del DBA applicativo (GRANT, DDL, ...) non sono presenti
differenze significative nell'uso di un'instanza RAC.
Un RAC generalmente si comporta
molto bene rispetto ad un'istanza singola con un overhead basso (<10%)
ed un'ottima scalabilita'.
Nel controllare le utenze e le sessioni e' importante ricordare che
i client si collegano su nodi diversi e quindi vanno utilizzate le viste GV$.
Dal punto vista di gestione i comandi per l'avvio dei database, dei listener, ...
invece sono diversi da quelli tipicamente utilizzati nel caso di single instance:
va utilizzato il comando srvctl.
Il lato positivo e' che si tratta di un solo comando semplice e potente:
srvctl start database -d myRac
srvctl stop instance -d myRac -i myRac2
srvctl stop database -d myRac -o immediate
srvctl status listener
Usage: srvctl command object [options]
commands: enable|disable|start|stop|relocate|status|add|remove|modify|getenv|setenv|unsetenv|config|convert|upgrade
objects: database|instance|service|nodeapps|vip|network|asm|diskgroup|listener|srvpool|server|scan|scan_listener|oc4j|home|filesystem|gns|cvu
Con lo stesso comando si attivano listener, database ed istanze.
Le opzioni sono di facile comprensione (eg. -d database -i instance)...
Con comandi simili si gestiscono i componenti del cluster:
# Controllo cluster
crsctl stat res -t
crsctl config has
crsctl check crs
# Blocco cluster
crsctl stop cluster -all
# Avvio cluster
crsctl start crs # parte TUTTO
crsctl start cluster # parte TUTTO eccetto OHASD (HA Service Daemon)
Sono gli stessi comandi del Clusterware Control
tranne piccole differenze su alcuni servizi (eg. il crs e' solo per il RAC).
Nella versione 12c e' cambiata nuovamente la sintassi:
srvctl stop instance -db myRac -instance "myRac2,myRac3" -stopoption immediate
Insomma tra versioni, comandi deprecati/desupportati, comandi Oracle RAC/Restart
c'e' un po' il rischio di confondersi... pero' la sintassi e' molto semplice!
Networking
Gli aspetti di comunicazione sono particolamente importanti per il RAC
e quindi meritano un capitolo a parte
[NdA inoltre un po' di cose sono cambiate nel tempo e bisognava descriverle].
In una configurazione RAC vengono utilizzati i seguenti indirizzi:
- IP pubblico per ogni nodo (definito sul DNS). Corrisponde tipicamente all'hostname.
- IP su rete privata per ogni nodo. Serve per l'Heartbeat.
- VIP sulla rete pubblica per ogni nodo (definito sul DNS). VIP sta per Virtual IP (non per Very Important Person ;)
- 3 IP SCAN sulla rete pubblica (definiti sul DNS in round robin). Lo SCAN e' stato introdotto dalla versione 11g R2.
I nodi comunicano tra loro su una rete privata che deve avere una bassa latenza,
elevata affidabilita' ed essere dedicata.
La connessione viene utilizzata sia per la gestione
del cluster che per lo scambio di dati tra i nodi.
Tutti gli indirizzi della rete pubblica debbono essere sulla stessa subnet.
La rete privata non ha bisogno (e non deve) essere in routing.
Possono essere utilizzate schede fisiche in teaming.
Il protocollo utilizzato per lo scambio dei dati e' leggermente differente
nel caso di due nodi (2-way) rispetto al caso di tre o piu' nodi (3-way).
Nel caso di tre o piu' nodi ha una complessita' leggermente maggiore
e vengono quindi usati eventi distinti.
Vengono utilizzati anche messaggi broadcast e multicast,
vengono utilizzati diversi protocolli sia TCP che UDP,
non debbono essere presenti firewall o altri blocchi tra le interfacce di rete.
Perche' sono importanti la velocita' e la bassa latenza della rete privata?
Perche' la Global Cache (GC) del RAC e' costituita dalle singole cache di memoria
dei nodi sincronizzate con messaggi sulla rete privata.
I client accedono alle basi dati utilizzando gli IP sulla rete pubblica.
Nella versione 11g R2 e' stato introdotto lo SCAN (Oracle Single Client Access Name)
listener. Visto che e' molto piu' semplice descriviamo questo!
Lo SCAN listener ascolta su indirizzi bilanciati dal DNS ed inoltra
le richieste di connessione ai listener tradizionali garantendo bilanciamento
e failover.
Dal punto di vista dei client la semplificazione e' notevole poiche' e'
possibile utilizzare una stringa di connesione identica a quella
utilizzata con le Single Instance:
(DESCRIPTION=
(ADDRESS=(PROTOCOL=TCP)(HOST=scan-ip) (PORT=1521))
(CONNECT_DATA=(SERVICE_NAME=service)))
Per un'istanza e' possibile utilizzare la registrazione statica sul listener o quella
dinamica. Con il RAC si utilizza la registrazione dinamica mediante
l'impostazione dei parametri local_listener e remote_listener.
Il local_listener si registra sul listener del nodo mentre il remote_listener
utilizza lo SCAN listener. Il pmon aggiorna lo stato sul listener all'avvio dell'istanza
ed ogni minuto. Per registrare immediatamente l'istanza si utilizza un ALTER SYSTEM.
Ecco i comandi:
alter system set local_listener='host1-vip:1521' scope=both sid='SID_NODE1';
alter system set local_listener='host1-vip:1521' scope=both sid='SID_NODE2';
alter system set remote_listener='scan-ip:1521' scope=both sid='*';
alter system register;
Tipicamente si cerca di mantenere lo stesso carico tra tutti i nodi
utilizzando una tecnica di bilanciamento.
In alcuni casi e' pero' vantaggioso il Functional Load Balancing.
Con il Functional Load Balancing si utilizzano in modo preferenziale
nodi diversi per applicazioni diverse. In questo modo il carico risulta
meno bilanciato ma e' possibile ridurre le contese sulla GC.
L'impostazione del bilanciamento applicativo e' a carico del client
che utilizza i VIP dei nodi per indirizzare la base dati.
E' necessario utilizzare la vecchia e complessa stringa di connessione al RAC:
(DESCRIPTION=(LOAD_BALANCE=off)
(ADDRESS=(PROTOCOL=TCP)(HOST=host1-vip) (PORT=1521))
(ADDRESS=(PROTOCOL=TCP)(HOST=host2-vip) (PORT=1521))
(CONNECT_DATA=(SERVICE_NAME=service)
(FAILOVER_MODE =
(TYPE = SELECT) (METHOD = BASIC) (RETRIES = 180) (DELAY = 5))))
Statistiche RAC
Ci sono alcune query interessanti quando si utilizza il RAC...
Per estrarre la configurazione:
SELECT INST_ID, name, ip_address, is_public pub, source
FROM gv$configured_interconnects ORDER BY inst_id,name;
Per estrarre analizzare la Global Cache latency e l'overhead del cluster:
SELECT event, SUM(total_waits) total_waits, ROUND(SUM(time_waited_micro) / 1000000, 2) time_waited_secs, ROUND(SUM(time_waited_micro)/1000 / SUM(total_waits), 2) avg_ms FROM gv$system_event WHERE wait_class <> 'Idle' AND( event LIKE 'gc%block%way' OR event LIKE 'gc%multi%' OR event like 'gc%grant%' OR event = 'db file sequential read') GROUP BY event HAVING SUM(total_waits) > 0 ORDER BY event;
SELECT wait_class time_category ,ROUND ( (time_secs), 2) time_secs, ROUND ( (time_secs) * 100 / SUM (time_secs) OVER (), 2) pctFROM (SELECT wait_class wait_class, sum(time_waited_micro) / 1000000 time_secs FROM gv$system_event WHERE wait_class <> 'Idle' AND time_waited > 0 GROUP BY wait_class UNION SELECT 'CPU', ROUND ((SUM(VALUE) / 1000000), 2) time_secs FROM gv$sys_time_model WHERE stat_name IN ('background cpu time', 'DB CPU'))ORDER BY time_secs DESC;
Per verificare il bilanciamento (CPU, Global Cache, TEMP):
WITH sys_time AS ( SELECT inst_id, SUM(CASE stat_name WHEN 'DB time' THEN VALUE END) db_time, SUM(CASE WHEN stat_name IN ('DB CPU', 'background cpu time') THEN VALUE END) cpu_time FROM gv$sys_time_model GROUP BY inst_id ) SELECT instance_name, ROUND(db_time/1000000,2) db_time_secs, ROUND(db_time*100/SUM(db_time) over(),2) db_time_pct, ROUND(cpu_time/1000000,2) cpu_time_secs, ROUND(cpu_time*100/SUM(cpu_time) over(),2) cpu_time_pct FROM sys_time JOIN gv$instance USING (inst_id);
WITH sysstats AS ( SELECT inst_id, SUM(CASE WHEN name LIKE 'gc%received' THEN VALUE END) gc_blocks_recieved, SUM(CASE WHEN name = 'session logical reads' THEN VALUE END) logical_reads, SUM(CASE WHEN name = 'physical reads' THEN VALUE END) physical_reads FROM gv$sysstat GROUP BY inst_id) SELECT instance_name, logical_reads, gc_blocks_recieved, physical_reads, ROUND(physical_reads*100/logical_reads,2) phys_to_logical_pct, ROUND(gc_blocks_recieved*100/logical_reads,2) gc_to_logical_pct FROM sysstats
JOIN gv$instance USING (inst_id);
select inst_id, tablespace_name, segment_file, total_blocks, used_blocks, free_blocks, max_used_blocks, max_sort_blocks
from gv$sort_segment;
select inst_id, tablespace_name, blocks_used extent_block_used, blocks_cached
from gv$temp_extent_pool;
Un SQL sbagliato e' pesante se eseguito su un'istanza singola;
se eseguito su RAC diventa molto pesante.
Il RAC non e' adatto agli ambienti di sviluppo ed alle run-away query.
Il tuning degli statement SQL non presenta differenze rispetto ad una Single Instance:
il punto di partenza e' sempre un EXPLAIN PLAN.
Versioni
Oracle RAC e' disponibile da molti anni su diverse
versioni Oracle ed il suo utilizzo e' ben consolidato ed affidabile.
Nelle prime versioni di Oracle era disponibile un prodotto analogo chiamato Parallel Server
[NdA disponibile dalla versione 6.2],
pero' l'installazione era oggettivamente complessa e presentava problemi di affidabilita' e di prestazioni.
L'Oracle RAC introdotto con la versione 9 [NdA 2001] di Oracle e' molto affidabile
e fornisce prestazioni nettamente migliori.
Non si tratta quindi di una scelta tecnologicamente rischiosa:
Oracle RAC puo' essere tranquillamente utilizzato su ambienti di produzione
che richiedono un'elevata sicurezza dati ed hanno SLA elevati.
Oracle RAC e' la scelta migliore per disporre di un database Oracle in HA (alta affidabilita').
La stabilita' in una configurazione RAC e' fondamentale.
La versione di Oracle va quindi scelta con attenzione e,
anche se e' possibile utilizzare le rolling upgrade,
va mantenuta ed aggiornata con cautela.
Le funzionalita' introdotte per il RAC dalla 10g R2 di Oracle sono notevoli
in particolare dal punto di vista delle prestazioni.
E' quindi consigliato utilizzare una versione 10g R2 o successiva
[NdE ora (2014) e' ovviamente consigliata la versione 11g R2]
[NdE ora (2106) e' ovviamente consigliata la versione 12c]
[NdA va utilizzata solo la
versione Oracle piu' recente (appena diventa affidabile)].
La funzionalita' RAC e' disponibile dalla versione Oracle 9 nella edizione Enterprise come Option
(con il relativo costo di opzione aggiuntiva).
Dalla 10g R2 il RAC e' disponibile nella Standard Edition senza costi aggiuntivi
ma con il limite di due socket totali;
il RAC non e' invece disponibile nelle Edition Personal ed Express.
Con la versione Oracle 11g (sia R1 che R2) sono molte le nuove funzionalita'
introdotte in RAC. Tra le tante: RAC One node, CVU, Grid Plug&Play, OCR and Voting on ASM,
SCAN listener, PARALLEL_FORCE_LOCAL, ...
Con la versione 12c sono molteplici le innovazioni sull'architettura di base.
In particolare con il Flex ASM,
e le evoluzione del ACFS.
Importanti per il RAC sono anche il supporto di IPv6 e la possibilita' di definire
ulteriori SCAN su subnet differenti.
La versione 12c R2 introduce:
Oracle Clusterware Resource Groups,
Reasoned What-If, ... insomma parecchie novita'!
Dalla 19c, che e' una versione importante poiche' e' una LTS [NdA anche se tecnicamente e' una 12.2],
cambia il licensing ed il RAC non e' piu' disponibile con la SE2 (Standard Edition 2)
ma solo come Option sulla versione Enterprise Edition
(cfr. documentazione Oracle)
[NdA ma, dalla 19.7, e' disponibile la SEHA (Standard Edition High Availability)
che utilizza la componente clusterware con una configurazione in failover].
Per la 23c... aspettiamo la disponibilita' on premises per riportare le novita'!
Varie ed eventuali
Qual'e' la mia configurazione? Ecco uno script abbastanza completo che riporta
i principali elementi della configurazione:
su - grid
echo Cluster Name:
cemutlo -n
echo Cluster Nodes:
olsnodes -n
echo Node Apps:
srvctl config nodeapps
srvctl status nodeapps
echo ASM:
srvctl config asm
srvctl status asm
echo Listener:
srvctl status listener
echo Databases:
for i in `srvctl config database` ; do echo $i; srvctl status database -d $i; srvctl getenv database -d $i; echo; done
Cambiare il TZ non e' immediato come con una Single Instance: va impostato giusto altrimenti...
# Solo su un DB:
srvctl setenv database -d AAA -T TZ=UTC
# Per l'intero CRS:
/etc/init.d/ohasd stop
su - grid
cd $ORACLE_HOME/crs/install
vi s_crsconfig_´hostname´_env.txt
~#TZ=GMT+02:00
~TZ=MET
/etc/init.d/ohasd start
Persa la configurazione dell'EM? Con il RAC il comando per riconfigurare l'EM e' un poco piu' lungo del solito:
emca -config dbcontrol db -silent -cluster -ASM_USER_ROLE SYSDBA -ASM_USER_NAME ASMSNMP -CLUSTER_NAME xxxcluster -LOG_FILE/home/oracle/emConfig_feb14_2012.log -DBSNMP_PWD DBSNMP -SYS_PWD oracle -ASM_USER_PWD oracle -SID ADMIN -ASM_SID +ASM1 -DB_UNIQUE_NAME ORCL -EM_HOME /u01/app/oracle/product/11.2.0/dbhome_1 -SYSMAN_PWD SYSMAN -SERVICE_NAME ADMIN -ASM_PORT 1521 -PORT 1521 -LISTENER_OH /u01/app/11.2.0/grid -LISTENER LISTENER -ORACLE_HOME /u01/app/oracle/product/11.2.0/dbhome_1 -HOST node1 -ASM_OH /u01/app/11.2.0/grid
Auguri!