Streaming Replication
Logical Replication
PostgreSQL
e' un potente DBMS relazionale Open Source noto per
la robustezza e la ricchezza di funzionalita'.
Questo documento descrive l'utilizzo e la configurazione in replica logica tra due database PostgreSQL
disponibile dalla versione 10.
La replica logica si differenzia dalla replica tradizionale PostgreSQL sia dal punto di vista tecnico
che funzionale: la replica fisica riguarda l'intero database cluster e garantisce l'HA (High Availability),
mentre la replica logica e' eseguita su tabelle specifiche ed e' orientata alla distribuzione dei dati.
Questo documento non e' introduttivo ed e' consigliato ad un pubblico informaticamente adulto...
Un documento introduttivo su PostgreSQL
e' Introduzione a PostgreSQL,
un documento piu' completo e' Qualcosa in piu' su PostgreSQL
inoltre, prima di leggere questa pagina,
e' sicuramente utile la conoscenza della replica fisica PostgreSQL.
PosgtreSQL fornisce da tempo un'ottima implementazione della replica fisica.
In questo breve documento trattiamo una differente modalita' di replica chiamata
Logical Replication e disponibile a partire dalla versione PG 10.
La Logical Replication utilizza un modello publish / subscribe in cui
un Publisher pubblica uno o piu' oggetti che possono essere raccolti da uno o piu' Subscriber.
I comandi per l'utilizzo della replica logica sono molto semplici e di immediato utilizzo: in pratica un publish richiede semplicemente di elencare le tabelle da replicare ed un subscribe si registra su una delle pubblicazioni disponibili del nodo di upstream.
Con la replica logica vengono replicati solo i dati tra tabelle, le tabelle debbono gia' essere presenti con la stessa struttura su entrambe i nodi. Non e' possibile replicare viste o altri oggetti e non sono replicabili le istruzioni di DDL. Eventuali modifiche delle tabelle pubblicate debbono essere eseguite manualmente sia sul publisher che sul subscriber.
La configurazione della logical replication richiede un'unica impostazione differente dai default del file postgresql.conf: wal_level = logical ; e' necessario il riavvio.
Sul nodo di partenza vengono create le PUBLICATION che sono semplicemente un elenco di tabelle da replicare:
E' possibile scegliere se pubblicare tutte le modifiche oppure una qualsiasi combinazione
tra INSERT, UPDATE e DELETE.
Per poter replicare le UPDATE e DELETE deve essere presente una primary key.
E' anche possibile definire che vanno replicate tutte le tabelle con
CREATE PUBLICATION all_tables FOR ALL TABLES;
Le tabelle vengono replicate con lo stesso nome e nello stesso schema.
I nodi di destinazione sono normali nodi PostgreSQL perfettamente
attivi e funzionanti. Non sono nodi in recovery o accessibili in sola lettura come avviene
con la replica fisica.
Sul nodo di destinazione vengono create le SUBSCRIPTION
che raccolgono i dati dal nodo di publishing.
Una subscription richiede i riferimenti del nodo di partenza
e l'elenco delle PUBLICATION da ricevere.
Le tabelle replicate debbono gia' esistere su entrambe i nodi
con lo stesso nome (sia di schema che di tabella) e con una struttura analoga.
In effetti e' sufficiente che le tabelle abbiano le stesse colonne;
possono essere cambiate l'ordine delle colonne,
la presenza o meno di indici, la presenza o meno del partizionamento,
eventuali viste, ...
I comandi di DDL non vengono replicati ed eventuali variazioni vanno eseguite manualmente su entrambe i nodi. Anche le TRUNCATE non vengono replicate.
Ad una stessa PUBLICATION possono essere agganciate da SUBSCRIPTION su piu' nodi. A sua volta un nodo Subscriber puo' pubblicare oggetti formando catene di distribuzione dei dati; non e' tuttavia ammessa una replica circolare.
Quando viene creata una sottoscrizione il contenuto iniziale delle tabelle viene copiato con un snapshot iniziale. Dopo questa prima fase vengono solo applicate le modifiche occorse sull'upstream e registrate sui WAL. Lo snapshot iniziale e' analogo ad eseguire un comando COPY ma avviene automaticamente.
Se debbono essere modificate le strutture delle tabelle l'operativa corretta e':
disabilitare le sottoscrizioni, effettuare la modifica sull'upstream,
effettare la modifica sul downstream, riabilitare le sottoscrizioni.
E' possibile interrompere la ricezione dei dati di una subscription con:
ALTER SUBSCRIPTION mysub DISABLE;
Se si verifica un errore nell'applicazione dei dati da parte di una sottoscrizione (eg. unique costraint violato) la replica viene interrotta. Per recuperare e' possibile correggere i dati che hanno generato l'errore oppure saltare in avanti con la funzione pg_replication_origin_advance().
Sebbene generalmente non utile e' possibile utilizzare la logical replication anche sullo stesso database cluster. Pero' deve prima essere creato il replication slot sul publisher e quindi creare la subscription con la clausola WITH (create_slot = false). Negli altri casi il replication slot e' creato automaticamente con la sottoscrizione.
Nonostante la profonda differenza funzionale tra la replica logica e la streaming replication, in realta' tecnicamente l'impementazione e' molto simile poiche' e' basata sulla raccolta in linea dei WAL con processi quasi identici. Nella logical replication i WAL vengono analizzati dai subscriber per raccogliere le modifiche relative alle sottoscrizioni e queste vengono quindi applicate sulle tabelle di interesse.
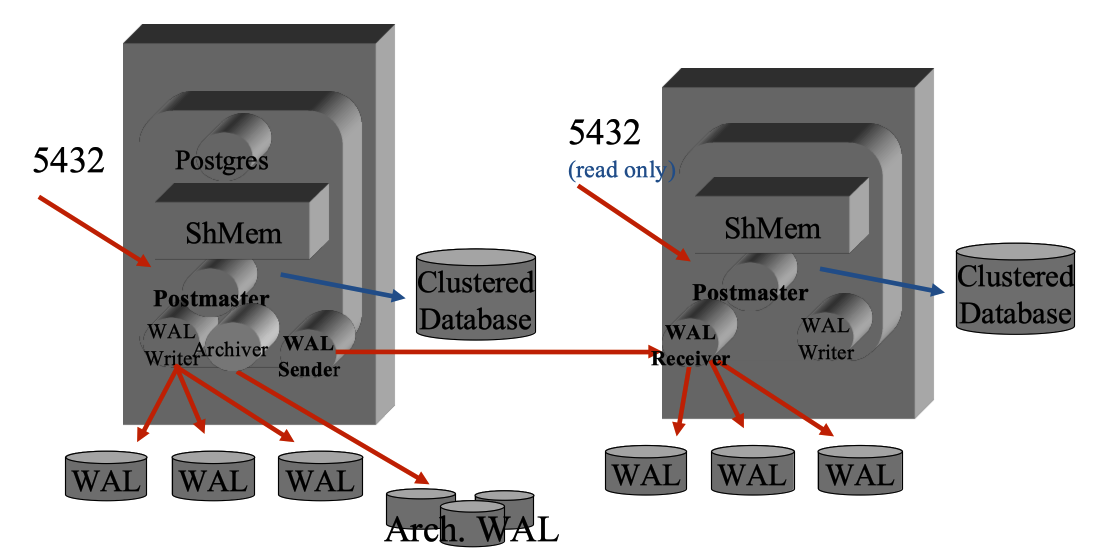
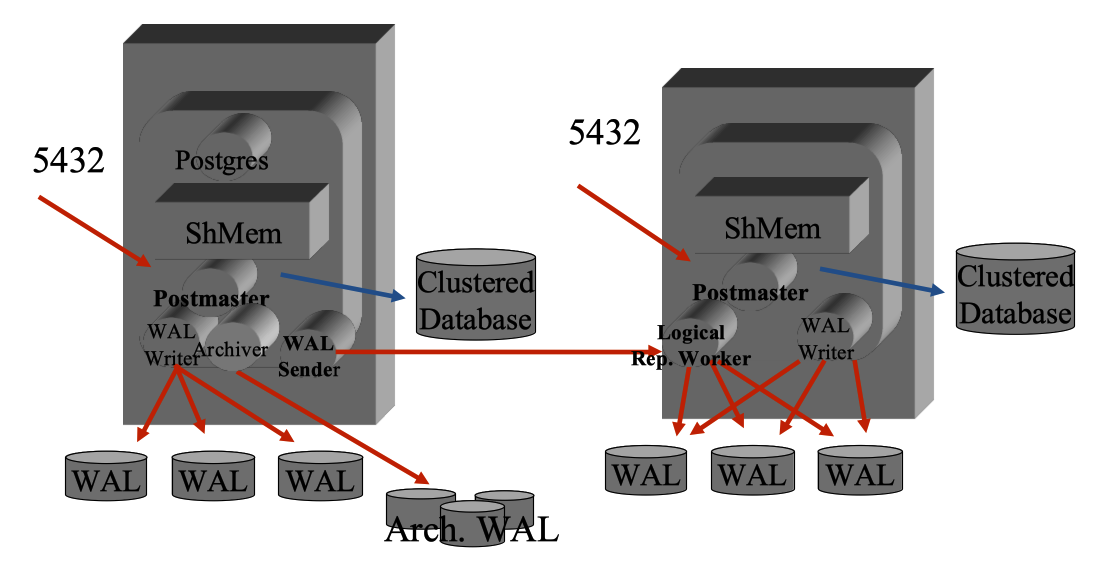
Streaming Replication | Logical Replication |
|
|
|
La configurazione richiede un'unica impostazione
rispetto ai valori di default dei parametri: wal_level = logical
nel file postgresql.conf (richiede il riavvio).
Altri parametri per la logical replication sull'upstream sono:
max_replication_slots,
max_wal_senders,
wal_sender_timeout;
mentre per il downstream sono:
max_replication_slots,
max_logical_replication_workers,
max_worker_processes,
wal_receiver_timeout;
tuttavia con i valori di default la logical replication
opera gia' correttamente.
Per la descrizione di tali parametri si puo' vedere anche
questo documento.
Anche se funzionalamente le differenze tra la streaming replication fisica e la logical replication sono moltissime, in realta' l'architettura per l'implementazione e' quasi la stessa. L'unica differenza e' che ad occuparsi dell'applicazione delle modifiche non e' il WAL Receiver ma il Logical Replication Worker. Quando viene creata una sottoscrizione viene attivato localmente il Logical Replication Worker che si collega all'upstream dove viene creato il WAL Sender che si occupa di inviare al nodo secondario i dati necessari. Per ogni sottoscrizione viene creato un replication slot sul database di pubblishing. In pratica i processi impegnati e le strutture utilizzate sono praticamente gli stessi presenti per la streaming replication:
Nonostante l'implementazione molto simile, le differenze funzionali sono notevoli.
Con la logical replication gli aspetti fondamentali sono:
La logical replication e' quindi adatta alla migrazione/condivisione di dati, mentre la physical streaming replication e' indicata per il DR (Disaster Recovery) o per la scalabilita' in lettura.
Un nodo publisher si comporta come un nodo primary della streaming replication
e lo stato corrente puo' essere
recuperato dalla vista pg_stat_replication.
Il controllo dello stato delle sottoscrizioni si effettua invece sulla vista
pg_stat_subscription.
Vediamo le query piu' utili per il monitoraggio della replica:
La replica logica e' stata introdotta di recente [NdA versione 10] e consente la replica di sole tabelle:
Maggiori dettagli sui limiti della logical replication sono riportati nella documentazione ufficiale.
Aurora PostgreSQL e' un'implementazione di PostgreSQL ottimizzata per il Cloud Amazon.
Aurora Pg consente la creazione di cluster con un DB primario e fino a 15 repliche in sola lettura.
L'implementazione della replica Aurora e' effettuata a livello di storage e nel codice modificato dai tecnici Amazon
partendo dalla versione community di PostgreSQL.
Per tale ragione non ha senso utilizzare la replica fisica PostgreSQL in Aurora PostgreSQL
ed infatti non e' disponibile.
Un discorso diverso vale invece per la replica logica!
Poiche' funzionalmente presenta molte possibilita' utili per la migrazione di dati
la logica replication e' disponibile in AWS su Aurora PostgreSQL
[NdA anche con PostgreSQL RDS che supporta anche la replica fisica].
Per la configurazione e' necessario impostare il parametro rds.logical_replication=1 sul publisher e, naturalmente, che le l'istanza sia raggiungibile dal subscriber. Gli altri parametri di configurazione sono analoghi a quelli della versione Community.
Questo documento ha un taglio pratico e volutamente riassuntivo; per una documentazione completa della teoria si rimanda alla documentazione PostgreSQL ufficiale della replica fisica e della replica logica.
Le funzionalita' della replica logica vengono arricchite in ogni nuova release!
Le fasi principali, con un minimo di storia precedente, sono:
PG 9.0: streaming replication;
PG 9.4: replication slots, logical decoding;
PG 10: logical replication;
PG 11: supporto del truncate, ottimizzazioni;
PG 12: nuova modalita' di configurazione;
PG 13: supporto delle tabelle partizionate, nuovi parametri utili anche per la replica logica;
PG 14: migliori prestazioni con lo streaming;
PG 15: WITH SCHEMA;
PG 16: origin=NONE;
...
Titolo: Logical Replication in PostgreSQL
Livello: Esperto
Data:
1 Gennaio 2018
Versione: 1.0.3 - 14 Febbraio 2024 ❤️ San Valentino
Autore: mail [AT] meo.bogliolo.name