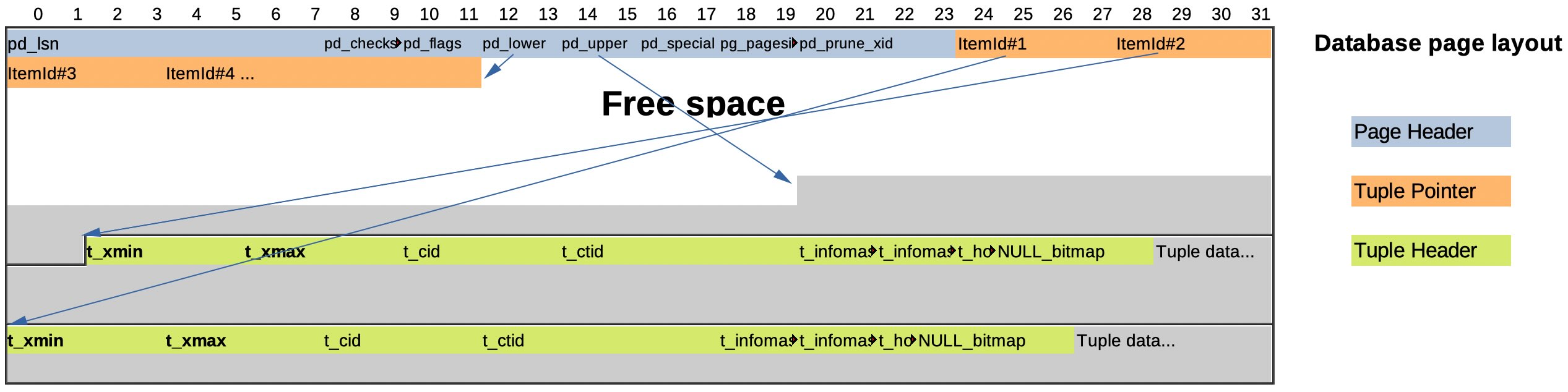
La figura seguente riporta la struttura di un blocco dati in PostgreSQL ma su altri RDBMS la struttura, come riportano i testi di anatomia comparata, e' molto simile:
L'ottimizzazione delle query SQL e' molto importante in tutti i database
relazionali.
Questo documento descrive le principali tecniche utilizzate
per organizzare i dati in modo efficiente in un database relazionale
ed i principali algoritmi utilizzati per eseguire in modo efficiente gli statement SQL.
Molti concetti di base ed algoritmi sono comuni a tutti i database relazionali
ma vengono qui riportati in dettaglio i comandi e gli strumenti
per l'ottimizzazione dell'SQL in
PostgreSQL.
Dopo una prima breve introduzione i primi paragrafi sono un poco teorici e noiosi ma servono come base per gli argomenti successivi: rappresentazione dati ed algoritmi (tabelle, indici, tipi di indici, JOIN, ...), ottimizzatore, explain. Quindi il documento riporta una serie di indicazioni pratiche sull'ottimizzazione dell'SQL mediante: indici, statistiche (ANALYZE), scrittura query, parametri ottimizzatore, altre indicazioni, ...
Altri documenti utili sull'argomento sono: Tuning in PostgreSQL e Statistiche prestazionali in PostgreSQL perche' trattano argomenti complementari all'ottimizzazione SQL non descritti in questa pagina.
Le attivita' di ottimizzazione e tuning di database sono complesse e richiedono esperienze specifiche. Entrambe sono rivolte al miglioramento delle prestazioni. L'attivita' di ottimizzazione viene svolta in fase di progettazione e di sviluppo (eg. scrittura degli statement SQL). Con il tuning invece si cerca di trovare il compresso migliore tra tutti gli elementi configurabili del sistema.
E' possibile intervenire a diversi livelli: dall'architettura del sistema al sizing del sistema ospite, dal disegno logico e fisico del database al tuning del database, ... Per motivi di spazio nel seguito ci limiteremo solo agli aspetti di ottimizzazione dell'SQL senza analizzare gli altri importanti elementi. Inoltre, anche se molti elementi sono comuni a tutti i database relazionali utilizzeremo i termini ed i comandi tipici di PostgreSQL. Ma per farlo e' necessario conoscere qualche concetto di base.
In un database relazionale i dati sono contenuti nelle... relazioni. In pratica si tratta di tabelle con righe e colonne. Le tabelle possono essere di grandi dimensioni e quindi essere memorizzate su disco (anche se le piu' recenti tecnologie prevedono l'uso degli SSD restano comunque accessi piu' lenti rispetto alla RAM).
Per capire come ottimizzare l'SQL e' necessario conoscere le strutture dati e gli algoritmi utilizzati.
I dati contenuti nelle tabelle sono mantenuti su data file organizzati
in pagine o blocchi di dimensione fissa.
Ogni blocco contiene una serie di righe, quando il blocco e' pieno
semplicemente si utilizza un nuovo blocco.
All'interno di ciascuna riga la struttura dipende dai datatype utilizzati.
L'insieme dei blocchi che contengono i dati di una tabella postgres viene chiamato Heap.
La figura seguente riporta la struttura di un
blocco dati in PostgreSQL
ma su altri RDBMS la struttura, come riportano i testi di
anatomia comparata,
e' molto simile:
Naturalmente tabelle di grosse dimensioni avranno un numero di blocchi molto elevato ed i file che le contengono saranno di grandi dimensioni. La lettura di tutti i dati da una tabella di grandi dimensioni richiede quindi un tempo relativamente elevato.
Per rendere efficiente l'accesso ai dati vengono utilizzati gli indici.
Gli indici consentono di reperire i dati cercati nella tabella con un
numero minore di accessi ai blocchi di dati rispetto a scorrere l'intero
contenuto della tabella (full table scan).
I tipi di indice piu' utilizzati sono i Balanced Tree.
I B-tree sono alberi bilanciati che cercano di mantenere basso il numero di livelli
per raggiungere i dati finali che sono sulle foglie
[NdA in informatica gli alberi si disegnano con la radice in alto e le foglie in basso].
La ricerca parte sempre dal blocco di primo livello dell'indice,
si confronta il valore cercato con quelli presenti nel blocco
ed a seconda del confronto si procede ai livelli sucessivi.
Con un esempio e' facile compredere l'algoritmo di ricerca:
 Se cerchiamo la chiave 59 al primo livello di indice vediamo che si trova tra
31 e 61 quindi seguiamo il puntatore intermedio, quindi al secondo livello
e' un valore piu' alto e troviamo cosi' il dato al terzo livello che contiene le foglie.
Se cerchiamo la chiave 59 al primo livello di indice vediamo che si trova tra
31 e 61 quindi seguiamo il puntatore intermedio, quindi al secondo livello
e' un valore piu' alto e troviamo cosi' il dato al terzo livello che contiene le foglie.
Un albero B-tree e' bilanciato quindi il numero di livelli e'
mantenuto limitato anche se a volte e' necessario ricostruirlo
per avere le migliori prestazioni.
Qual'e' il vantaggio nell'uso dell'indice? Per la ricerca senza indice e' necessario accedere
a tutti i blocchi della tabella che crescono linearmente con il numero
di record.
Per la ricerca con indice e' necessario accedere al numero di livelli
dell'indice piu' un accesso al blocco della tabella;
ma il numero di livelli dell'indice cresce con il logaritmo
(con base il numero di chiavi per blocco).
Facciamo un esempio numerico? Tabella da 10.000.000 di record con 100
record per blocco e 256 chiavi per blocco di indice.
L'accesso in full scan richiede 100.000 di accessi a disco,
mentre con l'indice bastano 4 accessi: tre sull'indice ed uno alla tabella
(256^3>16M). Per questo un Index Scan e' molto piu' veloce di un Sequential Scan
quando si cerca un solo record.
Se i dati richiesti dalla query riguardano solo le colonne chiave dell'indice
non e' neanche necessario l'accesso al blocco di dati della tabella risparmiando
l'accesso alla heap (Index Only Scan)
[NdA Postgres consente di inserire ulteriori colonne ad un indice con la clausola INCLUDE
che possono essere ottenute con Index Only Scan].
Un'ulteriore vantaggio e' che i blocchi di indice possono facimente essere mantenuti in una
cache, ma questo lo vedremo piu' avanti.
Mentre uno svantaggio dell'accesso con indice e' che richiede un accesso random al disco
che e' tipicamente piu' lento di un accesso sequenziale (anche se con gli SSD non e' piu' cosi').
Quando debbono essere scaricati molti record l'Index Scan effettua molti seek passando
da indice a tabella in modo disordinato.
Per raggruppare gli accessi a disco si utilizza un altro algoritmo
chiamato Bitmap Scan con cui
prima si raccolgono i puntatori alle pagine dei dati creando una bitmap
e poi si accede effettivamente alle
pagine dei dati richiesti in modo sequenziale
[NdA l'algoritmo Bitmap Scan non va confuso con gli indici bitmap che sono una cosa differente
e sono utili nelle query dei DSS].
Gli indici B-tree possono anche essere utilizzati per effettuare ricerche con disuguaglianze (eg. >, <, BETWEEN), per confrontare stringhe (eg. LIKE, ILIKE) e per ordinare i dati.
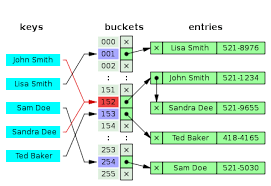 Una struttura alternativa all'indice B-tree e' una tabella di hash.
Una tabella di hash si basa su una funziona matematica in grado di trasformare
la chiave in un indirizzo.
La funzione di hash deve distribuire a caso nel
modo piu' uniforme possibile le chiavi sul dominio degli indirizzi
ed il numero di chiavi utilizzate deve essere significativamente
piu' basso delle posizioni disponibili per evitare collisioni.
L'hash e' molto efficiente (in pratica richiede un solo accesso)
ma puo' essere utilizzato solo con un numero di chiavi limitato
e disponendo di sufficiente memoria.
Una struttura alternativa all'indice B-tree e' una tabella di hash.
Una tabella di hash si basa su una funziona matematica in grado di trasformare
la chiave in un indirizzo.
La funzione di hash deve distribuire a caso nel
modo piu' uniforme possibile le chiavi sul dominio degli indirizzi
ed il numero di chiavi utilizzate deve essere significativamente
piu' basso delle posizioni disponibili per evitare collisioni.
L'hash e' molto efficiente (in pratica richiede un solo accesso)
ma puo' essere utilizzato solo con un numero di chiavi limitato
e disponendo di sufficiente memoria.
Le tabelle di hash possono essere mantenute per alcune strutture oppure
possono essere costruite al volo come avviene con alcuni tipi di Join.
Le strutture descritte sono le stesse praticamente su tutti i database relazionali:
Oracle, MySQL, SQL-Server, DB2, ... e PostgreSQL utilizzano tutti gli indici per ottimizzare
le prestazioni dell'SQL
[NdA quelle riportate non sono le uniche rappresentazioni utili,
vi sono rappresentazioni differenti per i database colonnari, per i TSDB, ...
ma non li vedremo in questa pagina].
Ci sono molti altri aspetti che andrebbero descritti:
chiavi univoche, chiavi duplicate, chiavi multiple, chiavi su funzioni,
partitioning, clustering, ...
su questo ci sono alcune differenze maggiori tra RDBMS
ma i meccanismi di base sono gli stessi.
Riassumendo PostgreSQL supporta i seguenti metodi per raccogliere i dati da una tabella:
Qual'e' l'algoritmo migliore?
Tutti sono ugualmente validi!
La scelta dipende dal tipo di ricerca,
dalla dimensione della tabella,
dagli indici presenti,
dalla selettivita' degli indici,
...
l'ottimizzatore valuta tutti questi aspetti e sceglie l'algoritmo migliore
per ottenere i dati.
Per esempio se le condizioni di ricerca sono molto ampie (o non ci sono)
si utilizzera' un Sequential Scan per raccogliere tutti i dati dalla tabella.
Se invece si utilizza una condizione per chiave o almeno per una buona parte di
essa il metodo di accesso piu' efficiente e' un Index Scan.
Infine se il numero di record che si vuole ottenere e' ampio
il doppio accesso all'indice ed alla tabella per ogni record eseguito dall'Index Scan
non e' efficiente: viene quindi utilizzato il metodo del Bitmap Index Scan
determinando prima tutte le pagine e solo in seguito accedendo alle righe della tabella.
Il TID scan e' specifico di PostgreSQL ed utilizza il Tuple IDentifier
che e' un indirizzo composto da 6 byte: 4 per identificare la pagina
e 2 come indice all'interno della pagina
[NdE Il TID di PostgreSQL e' analogo al ROWID di Oracle;
per entrambe i DB l'accesso ai dati con questo indirizzo e' molto efficiente].
Per visualizzare il TID in PostgreSQL basta accedere alla colonna virtuale ctid
selezionandola o impostandola in una ricerca come:
WHERE ctid = '(0,1)';
Nel capitolo precedente abbiamo velocemente descritto gli indici B-tree, in realta' vi sono molteplici tipi di indice supportati da PostgreSQL:
Come gia' riportato gli indici possono essere univoci o non univoci.
Possono essere costituiti da piu' colonne (indici composti);
l'ordine delle colonne e' molto
importante perche' gli indici possono essere anche utilizzati con chiavi parziali.
Dal punto di vista fisico gli indici in postgres sono sempre indici secondari
ovvero distinti dalla heap della tabella.
Le possibilita' di impostazione degli indici sono molto piu' ampie di quanto
brevemente descritto fino ad ora,
ad esempio:
e' possibile definire indici discendenti,
e' possibile definire la posizione dei NULL,
e' possibile definire indici su espressioni,
e possibile clusterizzare il contenuto di una tabella su un indice,
...
Nella maggior parte dei casi si usano semplicemente gli indici B-tree. Alcune estensioni di Postgres fanno un uso significativo di indici non B-tree (eg. PostGIS) ed altre estensioni sono utili con il text search (eg. pg_trgm).
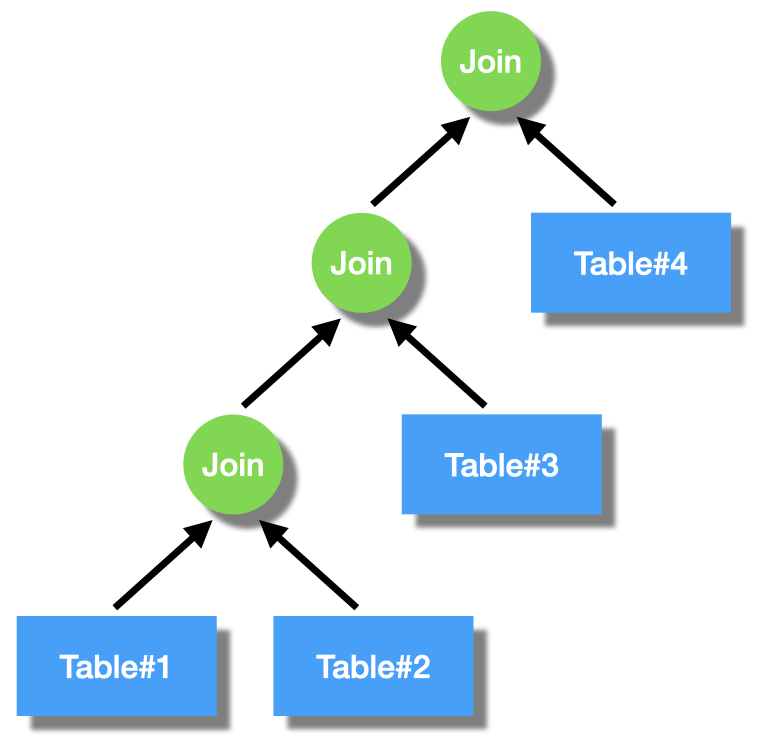
Oltre che ad ottenere i dati da una singola tabella con SQL la richiesta piu' tipica e' quella di mettere in relazione due o piu' tabelle con un join.
PostgreSQL utilizza principalmente tre algoritmi per effettuare i join:
Le caratteristiche degli algoritmi di join sono riassunti in questa tabella:
| Nested Loop Join | Merge Join | Hash Join | |
| Algoritmo | For each outer relation row, scan the inner relation | Sort both relations and merge rows | Build a hash for the inner relation, scan the outer relation probing the hash |
| Descrizione | Vengono eseguiti due loop in ciclo annidato. L'outer table viene acceduta con una scansione sequenziale. L'inner table viene utilizzata per la ricerca tante volte quanti sono gli elementi dell'outer table. | Utilizza il merge di due set ordinati. Le due sequenze vengono scorse in parallelo individuando le corrispondenze. | Prima viene costruita una hash table, poi eseguito un ciclo sull'altra relazione. L'hash table viene costruita sulla inner table, quindi si esegue una scansione sequenziale dell'outer table utilizzando l'hash per la ricerca sulla inner table. |
| Indici? | Se presente si usa l'indice sulla chiave della inner relation | Per fare il merge le tabelle debbono essere ordinate
Sono necessari gli indici sulla colonna di join per entrambe le tabelle | Nessuno: lo crea lui! |
| Ottimo? | Quando la outer table e' piccola e' abbastanza veloce. E' l'ultima spiaggia perche' funziona sempre ma e' l'algoritmo piu' lento | Con tabelle di grandi dimensioni ed indici presenti su entrambe e' molto efficiente perche' esegue due scan in parallelo | Se la tabella di hash sta in memoria (cfr. work_mem) e' molto veloce perche' effettua un solo scan |
Il doppio loop del nested join e' l'algoritmo piu' pesante... ma funziona con tutti i tipi di join,
in assenza di indici ed anche con un prodotto cartesiano.
Se e' presente un indice sulla inner table le prestazioni del nested loop migliorano nettamente;
con un equi-join
l'indice puo' essere di qualsiasi tipo: B-tree (il piu' utilizzato), hash, brin, ....
Il nested loop e' comunque il piu' lento di tutti gli algoritmi di join.
Il merge join e' un algoritmo piu' efficiente per il join di due tabelle di grandi dimensioni,
ma richiede che le due relazioni
da mettere in join siano ordinate ovvero che sia presente un indice su entrambe le tabelle.
Per tale ragione e' importante che tutte le tabelle con referential constraints
abbiano un indice sulla foreign key
[NdA l'indice deve essere di tipo ordinato: benissimo un B-tree ma non va bene un hash index].
Nelle versioni piu' recenti l'ottimizzatore di PostgreSQL puo' effettuare l'ordinamento
dei dati in mancanza di indici ed utilizzare comunque un Merge Join.
Puo' essere utilizzato per piu' condizioni di join.
L'hash join risolve il caso di assenza di indice... creando una hash table che lo sostituisce.
Questa tecnica e' la piu' veloce ma richiede che la tabella di hash venga mantenuta in memoria.
Puo' essere utilizzato solo con gli equijoin e quando la hash table ha dimensioni limitate.
Per meglio comprendere come funziona vediamo in dettaglio l'implementazione di ogni algoritmo. Anziche' con uno pseudo-codice ecco gli algoritmi di join con un esempio sintetico ma funzionante in Python:
### Sample Join Algorithms in Python ###
# Sample data
t1=[[1, 'Walt', 'Disney', 'Chicago', 1901], [2, 'Stan', 'Lee', 'New York', 1922],
[5, 'Milo', 'Manara', 'Luson', 1945], [3, 'Hugo', 'Pratt', 'Rimini', 1927],
[4, 'Richard', 'Felton', 'Lancaster', 1863], [6, 'Osamu', 'Tezuka', 'Toyonaka', 1928],
[8, 'Moebius', 'Gir', 'Nogent-sur-Marne', 1938]]
t2=[[3, 1, 'Corto Maltese'], [1, 2, 'Micky Mouse'], [1, 3, 'Donald Duck'], [1, 5, 'Minnie'], [5, 6, 'Miele'], [4, 7, 'Yellow kid'],
[2, 8, 'Hulk'], [2, 9, 'Spiderman'], [2, 10, 'Torcia'], [6, 12, 'Kimba'], [6, 17, 'Astro Boy'], [8, 19, 'Blueberry']]
### Nested loop join
# Nested loop has no prerequisite
for x in t1:
for y in t2:
if x[0] == y[0]:
print(x[1], x[2], " joins with ", y[2])
### Merge join
# Merge needs sorting... or an index on both relations
t1.sort()
t2.sort()
# Merge join
y=0
for x in t1:
while t2[y][0] <= x[0]:
if x[0] == t2[y][0]:
print(x[1], x[2], " joins with ", t2[y][2])
y = y + 1
if y>=len(t2):
break
### Hash join
# Hash join needs an hash table on inner relation
# Hash (a tricky hash function)
def myHash(i):
if i == 5:
return 2
elif i == 3:
return 3
elif i == 4:
return 4
elif i == 8:
return 6
else:
return i-1
# Hash join
for y in t2:
if y[0] == t1[ myHash(y[0]) ][0]:
print(t1[myHash(y[0])][1], t1[myHash(y[0])][2], " joins with ", y[2])
# Output (order can vary)
Walt Disney joins with Micky Mouse
Walt Disney joins with Donald Duck
Walt Disney joins with Minnie
Stan Lee joins with Hulk
Stan Lee joins with Spiderman
Stan Lee joins with Torcia
Milo Manara joins with Miele
Hugo Pratt joins with Corto Maltese
Richard Felton joins with Yellow kid
Osamu Tezuka joins with Kimba
Osamu Tezuka joins with Astro Boy
Moebius Gir joins with Blueberry
Con due tabelle possiamo usare tre algoritmi diversi, invertire l'ordine delle tabella ed utilizzare o meno gli indici. Nei casi normali ci sono 7 differenti possibilita'. Quando le tabelle sono tre si applica nuovamente il join tra il risultato del join tra le prime due tabelle e la terza tabella. Sono possibili tutte le variazioni: ordinare le tabelle in tutti i modi, utilizzare i diversi algoritmi, crescendo il numero delle tabelle il numero di combinazioni cresce in modo fattoriale!
Anche per i join la scelta dell'algoritmo ottimale dipende dal tipo di ricerca, dalla dimensione delle tabelle, dagli indici presenti, dalla selettivita' degli indici, ... naturalmente per ogni combinazione delle tabelle utilizzate. L'ottimizzatore quindi ha un compito molto importante nel scegliere il migliore Execution Plan.
Il linguaggio SQL e' apparentemente molto semplice, tuttavia per sfruttare appieno le possibilita' che offre e' necessario conoscerne le particolarita' e gli elementi specifici che ogni diversa implementazione presenta. PostgreSQL offre diverse estensioni del linguaggio SQL che comprendono nuove clausole, funzioni di utilita' ed un forte orientamento agli oggetti.
 Il processo di analisi ed esecuzione di uno statement SQL e' piuttosto complesso.
Il processo di analisi ed esecuzione di uno statement SQL e' piuttosto complesso.
La prima fase e' quella di parsing che ha un analizzatore sintattico
che riconosce gli identificatori (scan.l) ed ha una serie di regole (gram.y) di trattamento.
A questo punto i passi possono essere molto diversi a seconda che si tratti di semplici comandi
o istruzioni SQL complesse che richiedono ulteriori analisi e riscritture.
Inoltre una query identica puo' essere gia' stata eseguita di recente
ed in questo caso non e' piu' necessario analizzare tutti i dettagli
per ottimizzare la query (soft parse).
PostgreSQL utilizza un ottimizzatore cost-based.
Quando viene sottomesso un nuovo statement SQL l'ottimizzatore determina
il query tree da utilizzare con un algoritmo genetico basato sulle statistiche.
 Per ogni statement vengono analizzati tutti i percorsi possibili per
ottenere il risultato finale calcolando la complessita' di ciascuno
basandosi sui parametri che definiscono il costo di ogni metodo
di accesso e sulle statistiche raccolte dall'ANALYZE.
L'algoritmo genetico e' utilizzato per ridurre il numero delle combinazioni
dei possibili percorsi di ricerca quando il numero di join e' troppo
elevato per l'algoritmo deterministico;
e' infatti possibile utilizzare qualsiasi combinazione di join per ottenere
il risultato finale con una crescita esponenziale del numero di plan.
Per ogni statement vengono analizzati tutti i percorsi possibili per
ottenere il risultato finale calcolando la complessita' di ciascuno
basandosi sui parametri che definiscono il costo di ogni metodo
di accesso e sulle statistiche raccolte dall'ANALYZE.
L'algoritmo genetico e' utilizzato per ridurre il numero delle combinazioni
dei possibili percorsi di ricerca quando il numero di join e' troppo
elevato per l'algoritmo deterministico;
e' infatti possibile utilizzare qualsiasi combinazione di join per ottenere
il risultato finale con una crescita esponenziale del numero di plan.
Per gli statement gia' in memoria la fase di ottimizzazione non viene ripetuta (soft parse)
mentre e' necessaria per i nuovi statement (hard parse).
E' naturalmente molto importante che le statistiche su cui si basa l'ottimizzatore siano aggiornate. Altrimenti l'ottimizzatore non avra' elemente per effettuare le scelte corrette. PostgreSQL esegue in automatico le attivita' di analyze (raccolta delle statistiche necessarie all'ottimizzatore) e di vacuum (cancellazione dei blocchi non piu' necessari al MVCC) con il processo autovacuum launcher [NdA nelle release piu' recenti la raccolta delle statistiche ed l'AUTOVACUUM avvengono in modo sempre piu' completo e sofisticato] [NdE le tabelle temporary non vengono analizzate dall'AUTOVACUUM perche' sono visibili solo per la sessione che le genera, nel caso sia opportuno e' possibile utilizzare un ANALYZE manuale].
Il livello di dettaglio dell'analyze e' determinato dal parametro default_statistics_target
(default: 100).
E' possibile cambiare il default a livello di database con:
ALTER DATABASE mydb SET default_statistics_target = 200;
Per tabelle e colonne con distribuzioni di dati particolari tale valore puo' essere modificato
per singola colonna.
Le statistiche vengono raccolte nel catalogo Postgres;
una prima informazione sono il numero di righe e di pagine utilizzate da ogni tabella
[NdA le statistiche per le colonne degli indici sono molto piu' dettagliate e
utilizzano gli istogrammi dei valori]:
SELECT relname, relkind, reltuples, relpages FROM pg_class;
L'ottimizzatore puo' essere parametrizzato con una serie di
impostazioni
nel file postgresql.conf.
Vi sono parecchi parametri relativi al solo ottimizzatore che possono essere impostati.
I parametri dell'ottimizzatore sono divisi in gruppi:
alcuni definiscono i costi dei vari accessi ai dati,
altri abilitano/disabilitano particolari algoritmi/metodi di accesso,
altri configurano l'algoritmo genetico di riduzione del numero di piani di esecuzione analizzati, ...
Nella versione 14 di PostgreSQL i parametri di configurazione dell'ottimizzatore,
che sono i piu' significativi per il tuning SQL, sono 47 rispetto al totale di circa 350 parametri di configurazione presenti
[NdA nella versione 15 e' stata aggiunta un'impostazione ulteriore: recursive_worktable_factor ed i parametri di configurazione dell'ottimizzatore sono 48].
L'elenco si ottiene con:
select name, context, setting, unit, min_val, max_val, source, category
from pg_settings
where category like 'Query Tuning%'
order by category, name;
name | context | setting | unit | min_val | max_val | source | category
--------------------------------+---------+-----------+------+---------+--------------+---------+---------------------------------------------
geqo | user | on | | | | default | Query Tuning / Genetic Query Optimizer
geqo_effort | user | 5 | | 1 | 10 | default | Query Tuning / Genetic Query Optimizer
geqo_generations | user | 0 | | 0 | 2147483647 | default | Query Tuning / Genetic Query Optimizer
geqo_pool_size | user | 0 | | 0 | 2147483647 | default | Query Tuning / Genetic Query Optimizer
geqo_seed | user | 0 | | 0 | 1 | default | Query Tuning / Genetic Query Optimizer
geqo_selection_bias | user | 2 | | 1.5 | 2 | default | Query Tuning / Genetic Query Optimizer
geqo_threshold | user | 12 | | 2 | 2147483647 | default | Query Tuning / Genetic Query Optimizer
constraint_exclusion | user | partition | | | | default | Query Tuning / Other Planner Options
cursor_tuple_fraction | user | 0.1 | | 0 | 1 | default | Query Tuning / Other Planner Options
default_statistics_target | user | 100 | | 1 | 10000 | default | Query Tuning / Other Planner Options
from_collapse_limit | user | 8 | | 1 | 2147483647 | default | Query Tuning / Other Planner Options
jit | user | on | | | | default | Query Tuning / Other Planner Options
join_collapse_limit | user | 8 | | 1 | 2147483647 | default | Query Tuning / Other Planner Options
plan_cache_mode | user | auto | | | | default | Query Tuning / Other Planner Options
recursive_worktable_factor | user | 10 | | 0.001 | 1e+06 | default | Query Tuning / Other Planner Options
cpu_index_tuple_cost | user | 0.005 | | 0 | 1.79769e+308 | default | Query Tuning / Planner Cost Constants
cpu_operator_cost | user | 0.0025 | | 0 | 1.79769e+308 | default | Query Tuning / Planner Cost Constants
cpu_tuple_cost | user | 0.01 | | 0 | 1.79769e+308 | default | Query Tuning / Planner Cost Constants
effective_cache_size | user | 524288 | 8kB | 1 | 2147483647 | default | Query Tuning / Planner Cost Constants
jit_above_cost | user | 100000 | | -1 | 1.79769e+308 | default | Query Tuning / Planner Cost Constants
jit_inline_above_cost | user | 500000 | | -1 | 1.79769e+308 | default | Query Tuning / Planner Cost Constants
jit_optimize_above_cost | user | 500000 | | -1 | 1.79769e+308 | default | Query Tuning / Planner Cost Constants
min_parallel_index_scan_size | user | 64 | 8kB | 0 | 715827882 | default | Query Tuning / Planner Cost Constants
min_parallel_table_scan_size | user | 1024 | 8kB | 0 | 715827882 | default | Query Tuning / Planner Cost Constants
parallel_setup_cost | user | 1000 | | 0 | 1.79769e+308 | default | Query Tuning / Planner Cost Constants
parallel_tuple_cost | user | 0.1 | | 0 | 1.79769e+308 | default | Query Tuning / Planner Cost Constants
random_page_cost | user | 4 | | 0 | 1.79769e+308 | default | Query Tuning / Planner Cost Constants
seq_page_cost | user | 1 | | 0 | 1.79769e+308 | default | Query Tuning / Planner Cost Constants
enable_async_append | user | on | | | | default | Query Tuning / Planner Method Configuration
enable_bitmapscan | user | on | | | | default | Query Tuning / Planner Method Configuration
enable_gathermerge | user | on | | | | default | Query Tuning / Planner Method Configuration
enable_hashagg | user | on | | | | default | Query Tuning / Planner Method Configuration
enable_hashjoin | user | on | | | | default | Query Tuning / Planner Method Configuration
enable_incremental_sort | user | on | | | | default | Query Tuning / Planner Method Configuration
enable_indexonlyscan | user | on | | | | default | Query Tuning / Planner Method Configuration
enable_indexscan | user | on | | | | default | Query Tuning / Planner Method Configuration
enable_material | user | on | | | | default | Query Tuning / Planner Method Configuration
enable_memoize | user | on | | | | default | Query Tuning / Planner Method Configuration
enable_mergejoin | user | on | | | | default | Query Tuning / Planner Method Configuration
enable_nestloop | user | on | | | | default | Query Tuning / Planner Method Configuration
enable_parallel_append | user | on | | | | default | Query Tuning / Planner Method Configuration
enable_parallel_hash | user | on | | | | default | Query Tuning / Planner Method Configuration
enable_partition_pruning | user | on | | | | default | Query Tuning / Planner Method Configuration
enable_partitionwise_aggregate | user | off | | | | default | Query Tuning / Planner Method Configuration
enable_partitionwise_join | user | off | | | | default | Query Tuning / Planner Method Configuration
enable_seqscan | user | on | | | | default | Query Tuning / Planner Method Configuration
enable_sort | user | on | | | | default | Query Tuning / Planner Method Configuration
enable_tidscan | user | on | | | | default | Query Tuning / Planner Method Configuration
(48 rows)
Tutti i parametri hanno un valore di default ma possono essere cambiati in momenti diversi a seconda del livello (context).
Come vedremo non sono gli unici parametri utilizzabili per il tuning SQL, ma sono tra i piu' importanti.
Tutti i parametri dell'ottimizzatore hanno come categoria generale Query Tuning
e sono impostabili anche per una singola query (context=user).
PostgreSQL ha centinaia di parametri di configurazione. Oltre a quelli specifici dell'ottimizzatore ve ne sono molti altri importanti per il tuning del database e l'ottimizzazione dell'SQL. Ad esempio le cache in memoria dei blocchi dei dati e' uno dei principali parametri di tuning per tutti i database relazionali; in PostgreSQL viene configurato impostando il valore di shared_buffers. Nel seguito sono riportati i principali senza entrare in dettaglio sulla loro corretta impostazione:
Other important settings for PostgreSQL Optimization and Tuning
name | context | setting | unit | min_val | max_val | source | category
--------------------------------+---------+-----------+------+---------+--------------+---------+---------------------------------------------
work_mem | user | 4096 | kB | 64 | 2147483647 | default | Resource Usage / Memory
synchronous_commit | user | on | | | | default | Write-Ahead Log / Settings
max_connections | postm. | 100 | | 1 | 262143 | config. | Connections and Authentication / Connection Settings
backend_flush_after | user | 0 | 8kB | 0 | 256 | default | Resource Usage / Asynchronous Behavior
effective_io_concurrency | user | 0 | | 0 | 1000 | default | Resource Usage / Asynchronous Behavior
max_parallel_workers | user | 8 | | 0 | 1024 | default | Resource Usage / Asynchronous Behavior
max_parallel_workers_per_gather| user | 2 | | 0 | 1024 | default | Resource Usage / Asynchronous Behavior
max_worker_processes | postm. | 8 | | 0 | 262143 | default | Resource Usage / Asynchronous Behavior
hash_mem_multiplier | user | 1 | | 1 | 1000 | default | Resource Usage / Memory
shared_buffers | postm. | 16384 | 8kB | 16 | 1073741823 | config. | Resource Usage / Memory
temp_buffers | user | 1024 | 8kB | 100 | 1073741823 | default | Resource Usage / Memory
maintenance_work_mem | user | 65536 | kB | 1024 | 2147483647 | default | Resource Usage / Memory
wal_buffers | postm. | 512 | 8kB | -1 | 262143 | override| Write-Ahead Log / Settings
checkpoint_completion_target | sighup | 0.9 | | 0 | 1 | default | Write-Ahead Log / Checkpoints
max_wal_size | sighup | 1024 | MB | 2 | 2147483647 | config. | Write-Ahead Log / Checkpoints
min_wal_size | sighup | 80 | MB | 2 | 2147483647 | config. | Write-Ahead Log / Checkpoints
commit_delay | super. | 0 | | 0 | 100000 | default | Write-Ahead Log / Settings
autovacuum_analyze_scale_factor| sighup | 0.1 | | 0 | 100 | default | Autovacuum
autovacuum_analyze_threshold | sighup | 50 | | 0 | 2147483647 | default | Autovacuum
autovacuum_vacuum_cost_limit | sighup | -1 | | -1 | 10000 | default | Autovacuum
autovacuum_vacuum_scale_factor | sighup | 0.2 | | 0 | 100 | default | Autovacuum
log_min_duration_statement | super. | -1 | ms | -1 | 2147483647 | default | Reporting and Logging / When to Log
log_statement | super. | none | | | | default | Reporting and Logging / What to Log
shared_preload_libraries | postm. | pg_stat_statements | | config. | Client Connection Defaults / Shared Library Preloading
idle_session_timeout | user | 0 | ms | 0 | 2147483647 | default | Client Connection Defaults / Statement Behavior
statement_timeout | user | 0 | ms | 0 | 2147483647 | default | Client Connection Defaults / Statement Behavior
pg_stat_statements.max | postm. | 5000 | | 100 | 1073741823 | default | Customized Options
pg_stat_statements.track | super. | top | | none | all | default | Customized Options
auto_explain.log_min_duration | super. | -1 | ms | -1 | 2147483647 | default | Customized Options
auto_explain.log_nested_statements| super.| off | | | | default | Customized Options
auto_explain.log_settings | super. | off | | | | default | Customized Options
track_functions | super. | none | | | | default | Statistics / Query and Index Statistics Collector
track_io_timing | super. | off | | | | default | Statistics / Query and Index Statistics Collector
...
In precedenza abbiamo visto tutti gli algoritmi utilizzati per leggere i dati dalle tabelle ed eseguire i join... in realta' non erano affatto tutti perche' abbiamo semplificato un poco! Questa tabella riporta un elenco piu' completo:
| Node | Description |
| LIMIT | Returns a specified number of rows from a record set |
| SORT | Sorts a record set based on the specified sort key |
| NESTED LOOP | Merges two record sets by looping through every record in the first set and trying to find a match in the second set. All matching records are returned |
| MERGE JOIN | Merges two record sets by first sorting them on a join key |
| HASH JOIN | Joins two record sets by hashing one of them (using a Hash Scan) |
| HASH | generates a hash table from the records in the input recordset. Hash is used by Hash Join |
| AGGREGATE | Groups records together based on a GROUP BY or aggregate function (like sum()) |
| HASHAGGREGATE | Groups records together based on a GROUP BY or aggregate function (like sum()). Hash Aggregate uses a hash to first organize the records by a key |
| SEQ SCAN | Finds relevant records by sequentially scanning the input record set. When reading from a table, Seq Scans (unlike Index Scans) perform a single read operation (only the table is read) |
| INDEX SCAN | Finds relevant records based on an Index. Index Scans perform 2 read operations: one to read the index and another to read the actual value from the table |
| INDEX ONLY SCAN | Finds relevant records based on an Index. Index Only Scans perform a single read operation from the index and do not read from the corresponding table |
| BITMAP HEAP SCAN | Searches through the pages returned by the Bitmap Index Scan for relevant rows |
| BITMAP INDEX SCAN | Uses a Bitmap Index (index which uses 1 bit per page) to find all relevant pages. Results of this node are fed to the Bitmap Heap Scan |
| CTE SCAN | Performs a sequential scan of Common Table Expression (CTE) query results. Note that results of a CTE are materialized (calculated and temporarily stored) |
| MEMOIZE | Is used to cache the results of the inner side of a nested loop. It avoids executing underlying nodes when the results for the current parameters are already in the cache |
| GATHER | The portion of the plan will run in parallel |
| GATHER MERGE | The portion of the plan will run in parallel merging the results at the end preserving the order |
[NdA In realta' l'elenco sarebbe molto piu' lungo... nel codice ne ho contati circa 60]
La tabella riporta i principali passi di esecuzione che vengono utilizzati da Postgres e che possono essere visualizzati con EXPLAIN: continuate a leggere!
 Per verificare i tempi di esecuzione di uno statement SQL da psql
basta utilizzare il comando \timing.
Molte GUI per l'interrogazione dei DB forniscono la stessa informazione.
Ma questo riporta soltanto i tempi di esecuzione...
sebbene sia un'indicazione importante non e' sufficiente
per comprendere la reale esecuzione del piano di lavoro.
Per verificare i tempi di esecuzione di uno statement SQL da psql
basta utilizzare il comando \timing.
Molte GUI per l'interrogazione dei DB forniscono la stessa informazione.
Ma questo riporta soltanto i tempi di esecuzione...
sebbene sia un'indicazione importante non e' sufficiente
per comprendere la reale esecuzione del piano di lavoro.
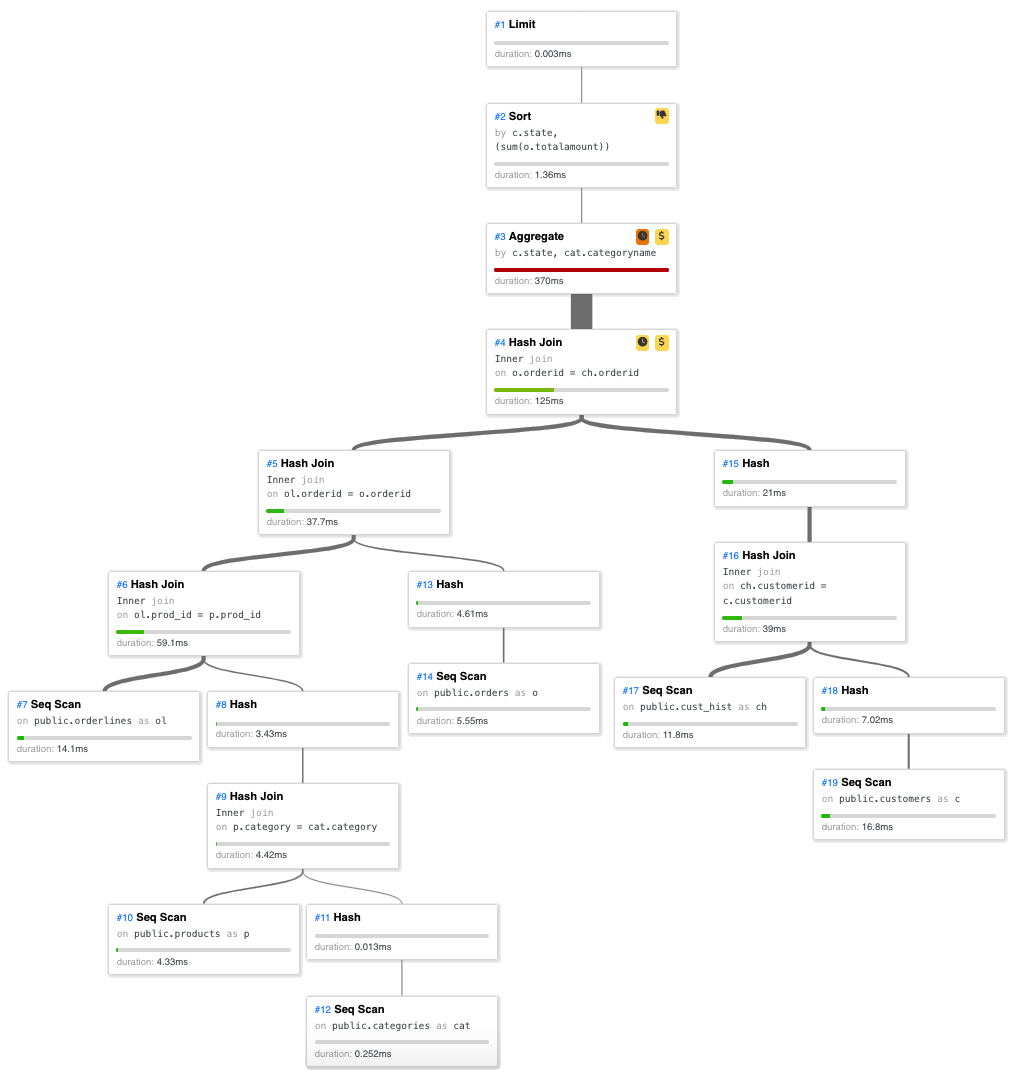
Un execution plan e' un grafo composto da tutti i passi necessari per ottenere il risultato della query. Naturalmente i passi sono gli algoritmi che abbiamo gia' visto nei paragrafi precedenti oltre a quelli necessari per verificare le condizioni, ordinare ed aggregare i dati, limitare il numero di righe: Seq Scan, Index Scan, Index Cond, Index Only Scan, Bitmap Scan, Nested Loop, Merge Join, Hash, Hash Join, Filter, Limit, Sort, ... Nelle versioni piu' recenti alcuni passi possono essere eseguiti in parallelo [NdA il Parallel Seq Scan e' stato introdotto nella 9.6 e tutte le versioni sucessive hanno aggiunto ed ottimizzato ulteriori algoritmi].
Per ottenere i dettagli su come l'ottimizzatore ha pianificato l'esecuzione di una query si utilizza la clausola EXPLAIN:
Con l'explain vengono visualizzati gli algormitmi di accesso ai dati scelti dall'ottimizzatore per eseguire la query. Oltre alle tabelle interessate sono riportati gli eventuali indici: fondamentali per un accesso efficiente.
Con EXPLAIN ANALYZE la query viene anche eseguita e quindi riportati i dettagli sui tempi effettivamente impegnati da ogni passo scelto dall'ottimizzatore. E' possibile utilizzare l'EXPLAIN su tutti gli statement SQL e non solo sulle SELECT; per non modificare dati utilizzando l'opzione ANALYZE e' possibile utilizzare una transazione [NdA ovviamente l'EXPLAIN ANALYZE e' piu' pesante di una semplice EXPLAIN sopratutto eseguendo un rollback]:
BEGIN; EXPLAIN ANALYZE DML_Statement; ROLLBACK;
In realta' le opzioni dell'EXPLAIN sono parecchie compresa la possibilita' di ottenere
l'execution plan in formato JSON con
EXPLAIN (ANALYZE, COSTS, VERBOSE, BUFFERS, FORMAT JSON).
Mentre da plsq risulta piu' leggibile EXPLAIN (ANALYZE, COSTS, VERBOSE, BUFFERS)...
I plan, su query reali, possono diventare parecchio complessi.
Tra i molti strumenti per
visualizzare gli execution plan,
sicuramente e' molto interessante il tool PEV2
che puo' essere scaricato o utilizzato direttamente da
web.
Ora che abbiamo visto come sono fisicamente rappresentati i dati, quali algoritmi puo' utilizzare l'ottimizzatore e come possiamo vedere con l'explain i piani di esecuzione dell'SQL passiamo ad una parte piu' pratica.
Come possiamo rende piu' performanti le nostre query?
Con l'ottimizzazione SQL!
I prossimi paragrafi cercheranno di fornire tutte le indicazioni per ottimizzare l'SQL con Postgres [NdA tutte e' impossibile... ma saranno comunque molte e, a mio avviso, le piu' importanti]. Per rendere piu' strutturati i suggerimenti sono stati suddivisi in gruppi:
Naturalmente un corretto disegno logico e disegno fisico della base dati sono fondamentali perche' gli statement SQL possano essere eseguiti con buone prestazioni. In particolare la presenza degli indici, che sono considerati la componente principale del disegno fisico nei database relazionali, e' fondamentale per una corretta esecuzione delle query. Per le letture piu' indici ci sono meglio e', al limite c'e' un costo iniziale leggermente piu' alto per l'ottimizzatore. In realta', oltre ad evitare lo spreco dovuto al maggiore utilizzo di spazio, e' in genere opportuno definire i soli indici necessari per non rallentare le esecuzioni degli statement di DML.
Il disegno di una base dati puo' essere molto differente a seconda del tipo di utilizzo. Con un OLTP il disegno e' normalizzato, se necessario overnormalizzato, e sono presenti i soli indici necessari; per un DWH il disegno e' fortemente denormalizzato, sono tipicamente presenti tabelle/viste aggregate e molteplici indici di ricerca. Con un disegno logico/fisico opportuno Postgres e' in grado di ospitare entrambe le tipologie di database anche se e' tecnicamente piu' adatto ad un uso OLTP [NdE citazione storica: "One Size Fits All": An Idea Whose Time Has Come and Gone].
PostgreSQL supporta indici univoci, indici multicolonna, indici su espressioni, indici parziali e le query su covering index. Dal punto divista fisico tutti gli indici in Postgres sono indici secondari nel senso che sono mantenuti separatamente dai dati della tabella di riferimento (heap) [NdA sono indici primari ad esempio la primary key dell'Engine InnoDB di MySQL e gli indici dei Table Cluster di Oracle]. Anche in PostgreSQL e' disponibile il comando CLUSTER ma introduce solo un ordinamento dei dati nelle tabelle.
PostgreSQL crea automaticamente l'indice per la primary key e quando viene definito un constraint unique. Attenzione: gli indici per le foreign key debbono invece essere creati esplicitamente in Postgres.
In generale si mettono sempre tutte le Primary Key e Unique Key
(in questi casi la creazione dell'indice e' automatica in Postgres),
tutte le Foreign Key (in questi casi la creazione dell'indice *non* e' automatica in Postgres),
e gli indici composti delle condizioni utilizzate nelle query piu' frequenti partendo dalla colonna piu' selettiva.
Gli indici composti "valgono" anche come indici meno selettivi usando solo alcune delle colonne partendo da sinistra.
Gli indici possibili su una tabella di 10 colonne, considerando tutte le disposizioni, sono quasi 10 milioni:
vanno definiti solo gli indici necessari!
PostgreSQL consente la creazione di indici basati su espressioni o su funzioni
(purche' dichiarate IMMUTABLE);
vanno usati con cautela ma possono consentire un accesso molto efficiente
se i richiami nelle applicazioni utilizzano in tal modo le ricerche.
Un esempio?
CREATE INDEX test1_lower_idx ON members (lower(surname));
In caso di caricamento massivo dei dati su una relazione e' conveniente non avere gli indici ma crearli solo alla fine. Per creare un indice o ricostruirlo in Postgres e' disponibile la clausola CONCURRENTLY che non utilizza lock e quindi la creazione puo' essere eseguita in parallelo con altre attivita' [NdA ma l'operazione richiede piu' tempo, alloca piu' spazio durante la costruzione e puo' lasciare un'indice in stato invalid].
Un indice BTREE non puo' essere utilizzato con l'operatore LIKE
quando il collate e' diverso da "C".
Per utilizzare l'indice anche con altri collate e'
necessario crearlo con uno specifico operator class
(text_pattern_ops, varchar_pattern_ops e bpchar_pattern_ops per i tipi text, varchar e char rispettivamente) :
CREATE INDEX emp_surname ON scott.emp (surname bpchar_pattern_ops);
In realta' sono disponibili in Postgres decine di operator class per tutte le tipologie di indice che consentono di trattare in modo dinamico il comportamento degli ordinamenti, dei confronti, ... Nella maggior parte dei casi si utilizzano i default, ma non mancano i casi in cui e' opportuno utilizzarli.
Per controllare la presenza di tutti gli indici e' possibile utilizzare questa semplice query:
WITH fk_actions ( code, action ) AS (
VALUES ( 'a', 'error' ),
( 'r', 'restrict' ),
( 'c', 'cascade' ),
( 'n', 'set null' ),
( 'd', 'set default' )
),
fk_list AS (
SELECT pg_constraint.oid as fkoid, conrelid, confrelid as parentid,
conname, relname, nspname,
fk_actions_update.action as update_action,
fk_actions_delete.action as delete_action,
conkey as key_cols
FROM pg_constraint
JOIN pg_class ON conrelid = pg_class.oid
JOIN pg_namespace ON pg_class.relnamespace = pg_namespace.oid
JOIN fk_actions AS fk_actions_update ON confupdtype = fk_actions_update.code
JOIN fk_actions AS fk_actions_delete ON confdeltype = fk_actions_delete.code
WHERE contype = 'f'
),
fk_attributes AS (
SELECT fkoid, conrelid, attname, attnum
FROM fk_list
JOIN pg_attribute
ON conrelid = attrelid
AND attnum = ANY( key_cols )
ORDER BY fkoid, attnum
),
fk_cols_list AS (
SELECT fkoid, array_agg(attname) as cols_list
FROM fk_attributes
GROUP BY fkoid
),
index_list AS (
SELECT indexrelid as indexid,
pg_class.relname as indexname,
indrelid,
indkey,
indpred is not null as has_predicate,
pg_get_indexdef(indexrelid) as indexdef
FROM pg_index
JOIN pg_class ON indexrelid = pg_class.oid
WHERE indisvalid
),
fk_index_match AS (
SELECT fk_list.*,
indexid,
indexname,
indkey::int[] as indexatts,
has_predicate,
indexdef,
array_length(key_cols, 1) as fk_colcount,
array_length(indkey,1) as index_colcount,
round(pg_relation_size(conrelid)/(1024^2)::numeric) as table_mb,
cols_list
FROM fk_list
JOIN fk_cols_list USING (fkoid)
LEFT OUTER JOIN index_list
ON conrelid = indrelid
AND (indkey::int2[])[0:(array_length(key_cols,1) -1)] @> key_cols
),
fk_perfect_match AS (
SELECT fkoid
FROM fk_index_match
WHERE (index_colcount - 1) <= fk_colcount
AND NOT has_predicate
AND indexdef LIKE '%USING btree%'
),
fk_index_check AS (
SELECT 'no index' as issue, *, 1 as issue_sort
FROM fk_index_match
WHERE indexid IS NULL
UNION ALL
SELECT 'questionable index' as issue, *, 2
FROM fk_index_match
WHERE indexid IS NOT NULL
AND fkoid NOT IN (
SELECT fkoid
FROM fk_perfect_match)
),
parent_table_stats AS (
SELECT fkoid, tabstats.relname as parent_name,
(n_tup_ins + n_tup_upd + n_tup_del + n_tup_hot_upd) as parent_writes,
round(pg_relation_size(parentid)/(1024^2)::numeric) as parent_mb
FROM pg_stat_user_tables AS tabstats
JOIN fk_list
ON relid = parentid
),
fk_table_stats AS (
SELECT fkoid,
(n_tup_ins + n_tup_upd + n_tup_del + n_tup_hot_upd) as writes,
seq_scan as table_scans
FROM pg_stat_user_tables AS tabstats
JOIN fk_list
ON relid = conrelid
)
SELECT nspname as schema,
relname as table,
conname as fk_name,
issue,
table_scans,
parent_name,
cols_list
FROM fk_index_check
JOIN parent_table_stats USING (fkoid)
JOIN fk_table_stats USING (fkoid)
WHERE table_mb > 5
AND ( writes > 1000
OR parent_writes > 1000
OR parent_mb > 10 )
ORDER BY table_scans DESC, table_mb DESC, table_name, fk_name;
E' evidente che la clausola di WHERE indicata nella query precedente puo' anche essere eliminata controllando cosi' anche le tabelle di minori dimensioni o non aggiornate.
Al contrario puo' essere utile trovare gli indici che non sono mai stati utilizzati, in questo caso la query e' piu' semplice:
select indexrelid::regclass as index, relid::regclass as table from pg_stat_user_indexes join pg_index using (indexrelid) where idx_scan = 0 and indisunique is false;
Naturalmente in questo caso e' importante che la base dati sia stata attiva da un certo tempo con il normale carico di applicazioni ed utenti finali altrimenti gli indici risulteranno non utilizzati.
In qualche caso la presenza di alcuni indici puo' indurre in errore l'ottimizzatore... per verificarlo e' possibile analizzare il plan eliminando l'indice solo per la transazione di prova con:
In qualche caso e' possibile che un indice risulti invalido in Postgres: e' possibile controllare la validita' degli indici visualizzando la colonna indisvalid della tabella del data dictionary pg_index. E' anche possibile sfruttare questo flag come un trucco per disabilitare un indice con:
Per PostgreSQL, come per tutti i database relazionali,
la corretta creazione degli indici e' di fondamentale importanza per le performance.
Anche se l'ottimizzatore PostgreSQL e' in qualche caso in grado di creare indici
per migliorare i tempi di risposta di una query (eg. Hash index),
la creazione degli indici e' il primo importante passo per ottimizzare le query.
L'abbiamo gia' detto: un corretto disegno logico e disegno fisico della base dati sono fondamentali perche' gli statement SQL possano essere eseguiti con buone prestazioni.
Per il disegno fisico e' fondamentale la corretta definizione degli indici
e l'abbiamo riportato come primo punto perche' e' quello generalmente
piu' importante per ottenere buone prestazioni da una base dati relazionale.
Pero' anche la fase di disegno logico e' molto importante per le prestazioni.
Generalmente in questa fase si commettono meno errori
e PostgreSQL ha una serie di funzionalita' (eg. storage mode)
che risolvono automaticamente una carenza di disegno logico.
La teoria del disegno delle basi dati e' molto ricca e ben definita: forme normali, overnormalizzazione, denormalizzazione, entity-relationship, constraints, ... Nella pratica quando uno statement SQL e' troppo complesso o troppo lento una ragione possibile e' un disegno di database non adeguato.
In generale un disegno con tabelle normalizzate, un'eventuale overnormalizzazione
di attributi particolarmente pesanti e meno acceduti ed una completa
definizione dei constraint e delle foreign key e' un buon punto di partenza
come disegno logico per un OLPT su ogni database relazionale e questo vale anche per Postgres.
Spesso infine ai requisiti iniziali se ne aggiungono altri non previsti,
cambiano le dimensioni e la distribuzione dei dati, ...
in questi casi spesso il disegno originale non e' piu' adeguato
ed occorre intervenire.
La raccolta delle statistiche necessarie all'ottimizzatore in PostgreSQL e' automatica e solo in qualche caso e' necessaria un'attivita' manuale. Le statistiche vengono raccolte nelle viste pg_class e pg_stats [NdA in realta' la tabella utilizzata e' pg_statistics ma e' riservata ai DBA ed un po' complicata... tipicamente si usa appunto la vista pg_stats]. La profondita' dell'analisi statistica e' definita dal parametro default_statistics_target [NdA il valore di default e' stato aumentato da 10 a 100 a partire dalla versione PG 8.4]. L'ANALYZE raccoglie le dimensioni ed il numero di record delle tabelle, degli indici e gli istogrammi con la distribuzione dei dati delle colonne. Questo consente poi all'ottimizzatore di calcolare il costo di ogni accesso in fase di parsing dello statement SQL.
select relnamespace::regnamespace::text||'.'||relname as tname, relkind, relpages, reltuples
from pg_class
where relnamespace::regnamespace::text not in ('pg_catalog', 'information_schema')
-- and relname like 'pgbench%'
order by 1;
select schemaname||'.'||tablename as tname, attname as cname, avg_width, array_dims(most_common_vals),
substr(unnest(most_common_vals::text::text[]), 1,20) val,
unnest(most_common_freqs::text::text[]) freq
from pg_stats
where schemaname not in ('pg_catalog', 'information_schema')
-- and tablename like 'pgbench%'
-- and attname like 'ab%'
order by 1, 2, 6 desc;
Quindi non c'e' altro da fare per ottimizzare l'SQL? No, in PostgreSQL ci sono possibilita' di agire per migliorare ulteriormente i piani di esecuzione dell'SQL con ANALYZE personalizzati!
Innanzi tutto occorre controllare che le ANALYZE vengano eseguite
[NdA la verifica si effettua nella tabella pg_stat_all_tables].
Per default vengono eseguite automaticamente dal processo
di autovacuum ed in condizioni normali non e' necessario
alcun intervento. Se necessario, ad esempio dopo un caricamento significativo di dati,
e' possibile eseguire l'ANALYZE manualmente sulla tabella t1 con il comando:
ANALYZE t1;
[NdA generalmente si preferisce lanciare un VACUUM ANALYZE perche' libera anche
l'eventuale spazio inutilmente allocato, ma e' un argomento trattato su un altro
documento].
La profondita' dell'analisi statistica di default e' 100,
se una tabella ha una o piu' colonne che richiedono un livello di analisi
superiore e' possibile utilizzare il comando:
ALTER TABLE t1 ALTER COLUMN c1 SET STATISTICS 1000;
ANALYZE t1;
Postgres analizza automaticamente tutte le tabelle e tutte le colonne
che hanno un indice. Non vengono pero' calcolate in automatico statistiche
correlate (anche perche' le possibili correlazioni dipendono dal numero di colonne
in fattoriale).
Dalla versione 10 e' possibile creare statistiche estese con:
CREATE STATISTICS s1 (dependencies) ON c1, c2 FROM t1;
CREATE STATISTICS s2 (ndistinct) ON c1, c2 FROM t1;
ANALYZE t1;
I dati raccolti con le statistiche estese sono riportate nella tabella
di sistema pg_statistic_ext
[NdA dalla versione 12 e' stato aggiunto l'ulteriore tipo di statistica estesa mcv: most-common values].
Per calcolare il numero di record
che soddisfano ad una serie di condizioni l'ottimizzatore
utilizza la probabilita' composta considerando indipendenti i valori delle colonne.
Questo puo' portare a stime non corrette e quindi far scegliere piani non ottimali.
Le statistiche estese tengono conto delle eventuali dipendenze dei valori
tra colonne e possono correggere le stime dell'ottimizzatore quando
analizza le condizioni delle query o le clausole di GROUP BY.
Riassumendo...
nella maggioranza dei casi le impostazioni di default delle statistiche sono
sufficienti per l'ottimizzazione delle query;
se vi e' una query particolare che non viene risolta nel modo migliore
si cerca far analizzare meglio le colonne coinvolte per far calcolare
esattamente il costo della query.
Questa e' la modalita' consigliata per agire su PostgreSQL:
fare in modo che le statistiche su cui l'ottimizzatore effettua le scelte siano corrette, complete ed aggiornate.
Ma se non basta... continuate a leggere!
L'ottimizzatore di PostgreSQL e' statistico e non sintattico (come i primi ottimizzatori), quindi il modo in cui una query e' scritta teoricamente non e' importante... ma in realta' non e' sempre cosi!
Innanzi tutto bisogna evitare di commettere errori!
Un errore molto comune e' quello di utilizzare espressioni o funzioni sulle colonne;
in questi casi si rendono inutilizzabili gli indici e quindi le ricerche
diventano molto piu' lente.
Piu' difficile da riconoscere, ma analogo come effetto,
il binding di valori con datatype errati.
Si tratta di errori da evitare assolutamente e che possono essere
aggirati con la creazione di
expression index
ma in pratica il consiglio e': utilizzate sempre condizioni su naked columns!
Altro errore frequente sono i join o prodotti cartesiani, non sempre riconoscibili
da numero di record restituiti perche' possono essere filtrati con LIMIT o con raggruppamenti.
Meglio eseguire una query con mille risultati o mille query con un singolo risultato ciascuna?
Nella maggior parte dei casi la prima scelta e' quella corretta
ed e' un errore eseguire piu' query in sucessione con parametri
leggermente diversi
ma vi sono anche casi in cui la scelta piu' efficiente e' la seconda.
Nella scrittura di una join possono essere utilizzate diverse sintassi equivalenti in termini di risultato finale:
SELECT * FROM a, b, c WHERE a.id = b.id AND b.ref = c.id; SELECT * FROM a CROSS JOIN b CROSS JOIN c WHERE a.id = b.id AND b.ref = c.id; SELECT * FROM a JOIN (b JOIN c ON (b.ref = c.id)) ON (a.id = b.id);
Queste diverse forme sintattiche sono generalmente equivalenti anche come prestazioni,
con le impostazioni di default, perche' l'ottimizzatore ha la
liberta' di riscriverle in tutte forme equivalenti e di scegliere
comunque quella con il costo minore.
Questo avviene, anche se con qualche limite in piu', anche utilizzando
le subquery [NdA a meno di non utilizzare il trucco dell'OFFSET 0].
Tuttavia se si vuole indirizzare l'ottimizzatore nella scelta dell'ordine
dei join con cui eseguire la query e' possibile impostare il
parametro join_collapse_limit = 1 (ed il corrispondente parametro from_collapse_limit per le subquery).
Con tale impostazione il piano generato dall'ottimizzatore seguira' l'ordine dei JOIN indicato
nella clausola FROM
[NdA va indicato il
JOIN in modo esplicito].
L'utilizzo di sintassi equivalenti per i join vale anche per le istruzioni di DML come le UPDATE e le DELETE. Postgres dispone della clauola USING per effettuare i JOIN nelle DELETE mentre nelle UPDATE puo' essere utilizzata la normale clausola FROM [NdA nella FROM non deve essere ripetuta la base table]; in questo modo possono essere evitate subquery che possono risultare meno efficienti.
Le condizioni in NOT ed in OR costringono l'ottimizzatore ad un uso non efficiente degli indici ma spesso possono essere riscritte in modo differente (eg. con una UNION o, meglio, una UNION ALL; applicando De Morgan; utilizzando un outer join; ...). Particolarmente pesante risulta l'utilizzo di OR con condizioni basate su tabelle diverse poste in join (cfr. the "ugly" OR): in questi casi e' fortemente consigliabile riscrivere la query con una UNION.
Spesso si leggono query generate da codice in cui sono presenti lunghissime liste di valori confrontate con IN... Non sempre questo e' il modo piu' efficiente di scriverle e possono invece essere utilizzati la clausola VALUES ed i JOIN oppure le TEMPORARY TABLES come descritto in questa paginetta. Altro caso simile e' il NOT IN (subquery) le alternative possibili sono molte, ad esempio:
SELECT l.*
FROM t_left l
WHERE l.value NOT IN
(SELECT value
FROM t_right r);
-- Anti-join better alternatives
SELECT l.*
FROM t_left l
WHERE NOT EXISTS
(SELECT NULL
FROM t_right r
WHERE r.value = l.value);
SELECT l.*
FROM t_left l
LEFT JOIN t_right r ON r.value = l.value
WHERE r.value IS NULL;
Utilizzando le CTE (Common Table Expression), ovvero la clausola WITH,
e' possibile guidare la sequenza di esecuzione delle query parziali.
Nota importante:
le CTE forzano l'esecuzione anticipata dello statement nella WITH fino alla versione 12:
PostgreSQL elabora prima le query definite nella clausola WITH e quindi la SELECT finale.
Nelle versioni successive l'ottimizzatore modifica l'ordine di esecuzione anche in presenza di una CTE,
di solito e' un vantaggio ma non e' sempre cosi'.
Pero' dalla versione 12 e' anche possibile utilizzare la clausola
AS MATERIALIZED
per forzare l'ordine di esecuzione
ed eseguire comunque prima le SELECT presenti nella clausola WITH.
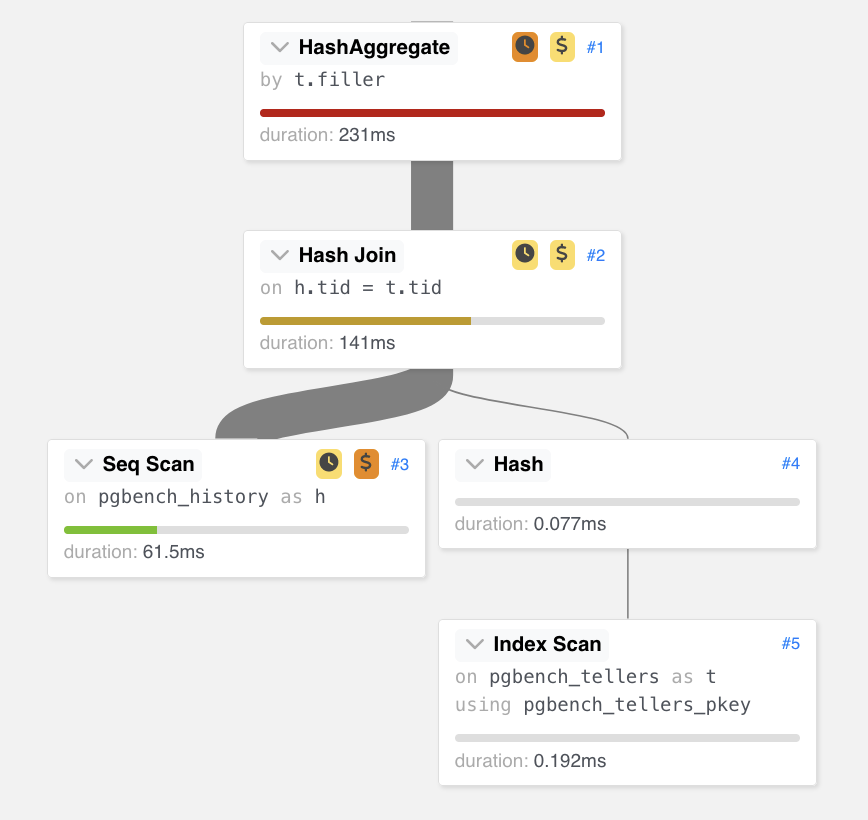
SELECT t.filler, count(*) as res FROM pgbench_history AS h, pgbench_tellers AS t WHERE h.tid = t.tid GROUP BY t.filler; |
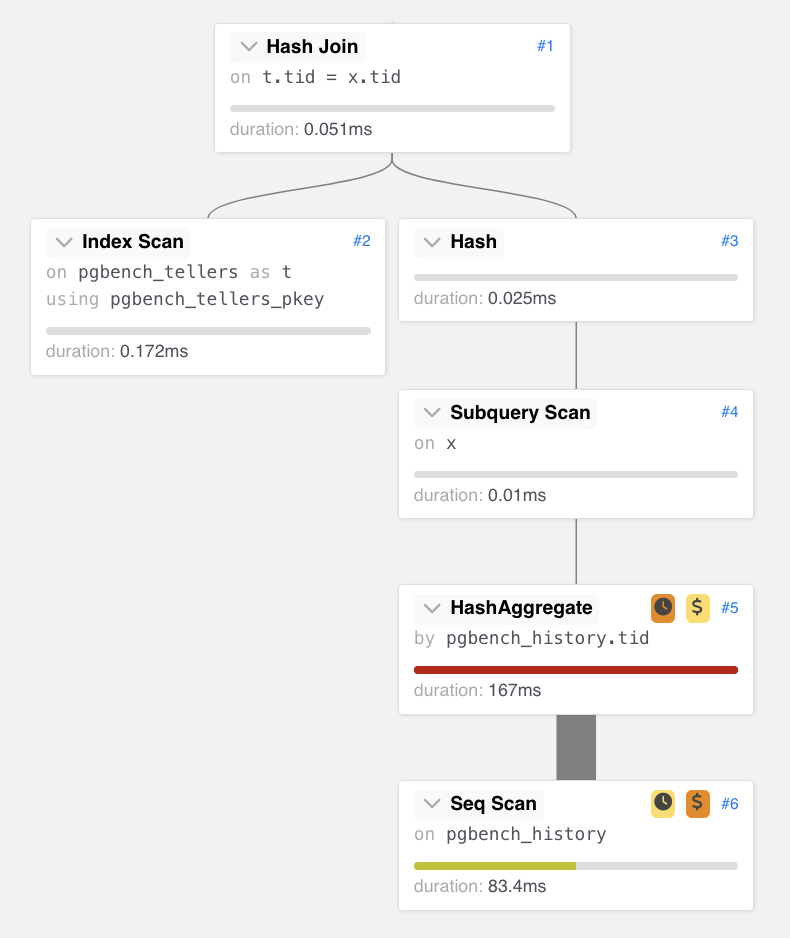
WITH x AS ( select tid, count(*) as res from pgbench_history group by tid ) SELECT t.filler, res FROM x, pgbench_tellers AS t WHERE x.tid = t.tid; |
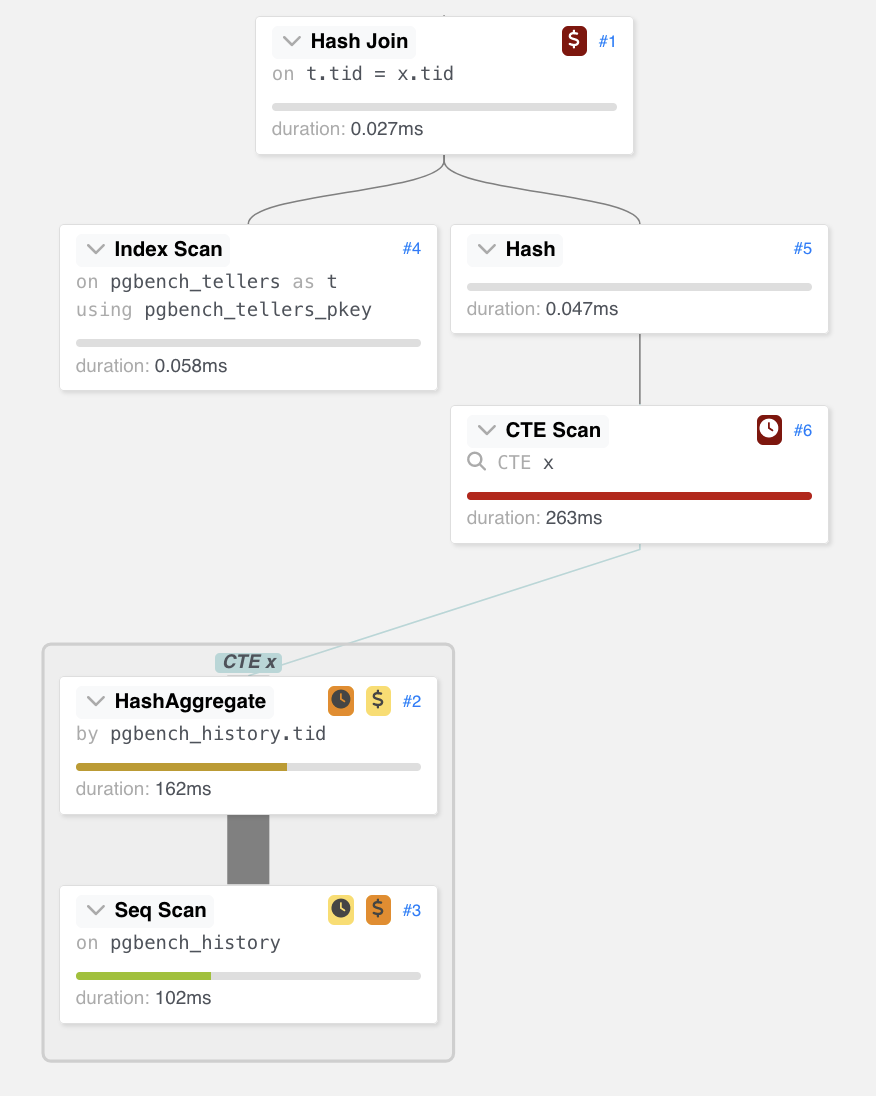
WITH x AS MATERIALIZED ( select tid, count(*) as res from pgbench_history group by tid ) SELECT t.filler, res FROM x, pgbench_tellers AS t WHERE x.tid = t.tid; |
| 
| 
|
L'esempio utilizza le classiche tabelle del pgbench [NdA i dettagli sono nel Page Source]. In questo caso l'idea della CTE e' quella di evitare di fare il join per ogni riga pgbench_history ma, poiche' ci interessa il dato aggregato, eseguire il join solo alla fine su un numero piu' limitato di record... Nell'esempio il guadagno tra le tre differenti scritture della stessa query e' del 40%, ma le CTE si possono applicare in moltissimi casi con vantaggi prestazionali a volte molto elevati!
Alternative alle CTE sono le TEMPORARY TABLE o le MATERIALIZED VIEW. Hanno caratteristiche diverse ma possono dare grandi vantaggi sopratutto se l'elaborazione iniziale non deve essere ripetuta ma puo' essere sfruttata piu' volte.
E' molto importante che sul DB ospite sia stato svolto un tuning sull'istanza.
Le impostazioni di default di alcuni parametri in PostgreSQL sono molto conservative
(eg. effective_cache_size) e possono ingannare l'ottimizzatore.
Su una base dati correttamente configurata e' possibile operare con ulteriori
parametri di configurazione dell'ottimizzatore di PostgreSQL per le query SQL che risultassero ancora lente.
Naturalmente i parametri piu' importanti in questo caso sono quelli del
Query Tuning.
E' possibile modificare i parametri dell'ottimizzatore
nella sessione prima di lanciare lo statement SQL
ed analizzare le eventuali differenze sul query plan come nell'esempio seguente:
E' possibile variare interattivamente qualsiasi parametro PostgreSQL con context user,
le combinazioni possibili sono innumerevoli ma...
gli esempi scelti sono indicativi dei parametri piu' efficaci.
L'impostazione puo' essere eseguita per la sessione corrente oppure,
con il parametro LOCAL, per la transazione corrente.
Naturalmente si modifica un parametro alla volta: non ha senso disabilitare contemporaneamente tutti
gli algoritmi di join!
[NdA vi sono diversi altri algoritmi che possono essere abilitati/disabilitati a seconda dei casi
(eg. enable_bitmapscan, enable_gathermerge, ...);
e' anche possibile confrontare gli execution plan e vedere cosa viene utilizzato nelle query non efficienti]
Come abbiamo visto la scansione sequenziale e' pesante se una tabella e' di grandi dimensioni,
l'ottimizzatore potrebbe scegliere tale strategia se pensasse che il numero di record e'
da estrarre e' limitato: per provare a fargli cambiare idea e' necessario che l'ottimizzatore
comprenda correttamente la selettivita' delle varie condizioni della query.
Gli algoritmi per effettuare un join sono diversi, con l'impostazione dei parametri
possiamo escludere un'algoritmo come il Nested Loop Join o gli altri.
Il costo di accesso alle pagine su disco e' differente se si utilizza una scansione sequenziale
o un accesso random; pero' questo non e' piu' vero se di utilizzano dischi SSD:
con l'impostazione di random_page_cost=1.5 abbassiamo il costo dell'accesso random al disco.
Per effettuare gli ordinamenti, i raggruppamenti e creare le hash tables serve
spazio in memoria; ad ogni sessione e' riservata una memoria di lavoro
che puo' essere impostata con il parametro work_mem.
Il parametro work_mem e' molto importante perche' influisce pesantemente
sulle scelte dell'ottimizzatore.
Pero' non deve essere alzato troppo a livello di configurazione di database perche' viene
applicato ad ogni sessione
[NdA per essere precisi ad operazione di sort o hash table delle query attive]:
il rischio e' di terminare la memoria a disposizione
del server con gravi conseguenze prestazionali e sul servizio (eg. OOM killer).
Quindi la cosa migliore e' impostarlo solo sugli utenti per le sessioni
o per le query che ne hanno effettivamente necessita'.
Naturalmente aumentare il parametro work_mem oltre un certo limite non porta piu' benefici,
ma le impostazioni di default o quelle di sistema, per i motivi gia' spiegati,
sono generalmente molto basse
[NdA dalla versione 13 e' disponibile hash_mem_multiplier che consente di aumentare
il limite della work_mem per i soli hash join].
Un parametro simile a work_mem e' temp_buffers poiche' viene applicato anch'esso per
ogni sessione utente. Il suo valore indica la quantita' di memoria massima utilizzabile
per le aree temporanee; se la query ne richiede uno spazio maggiore allora viene allocato
come file su disco.
L'EXPLAIN ANALYZE riporta in dettaglio la quantita' di spazio richiesta per le aree temporanee
ed e' quindi semplice eseguire un tuning specifico per la singola query SQL.
Sono relativi a casi particolari ma a volte sono molto utili altri parametri dell'ottimizzatore quali: geqo_threshold, geqo_effort, join_collapse_limit, from_collapse_limit, effective-io-concurrency, plan_cache_mode, max_parallel_workers_per_gather, jit, ...
Non esiste una soluzione unica valida in ogni caso ma molte scelte tattiche.
Premesso che su tutte le tabelle debbono essere stato eseguito un VACUUM ANALYZE recente,
vediamo qualche esempio concreto.
L'ottimizzatore non scegliere un hash join perche' i record sono troppi?
Aumentate la work_mem!
Dall'explain analyze risultano sort su disco?
Aumentate la work_mem!
L'algoritmo di join scelto non vi sembra quello ottimale? Disabilitatelo!
Aggiungendo la tredicesima tabella l'ottimizzatore sbarella? Aumentate geqo_threshold!
Volete disattivare il parallelismo? Impostate il max_parallel_workers_per_gather a 0!
Dopo le prime esecuzioni di un prepared statement i piani non sono piu' ottimali?
SET plan_cache_mode=force_custom_plan;
Anche se vi sono parecchie differenze, l'impostazione dei parametri dell'ottimizzatore e' quella piu' vicina alla tecnica degli HINT che viene utilizzata in altri database e che consente di suggerire all'ottimizzatore un execution plan differente. In PostgreSQL infatti non esistono gli HINT pero' l'impostazione dei parametri dell'ottimizzatore e' molto efficace e puo' essere effettuata per una singola query, per un utente, per un database, ...
L'apertura di nuove sessioni in PostgreSQL ha un peso e richiede un certo tempo... per questo sono molto utilizzati i connection pool. Un corretto dimensionamento dei pool e' molto importante per le prestazioni. E' anche possibile utilizzare strumenti esterni per effettuare il caching delle sessioni. Nel vasto ecosistema Postgres gli strumenti piu' noti sono PgBouncer e PgPool ma altrettanto diffusi sono quelli utilizzabili a livello applicativo.
Sara' banale ma su PostgreSQL e' ancora piu' rilevante che su altri database [NdA come piu' ampiamente descritto nella paginetta sul VACUUM]: se si debbono cancellare tutti i record di una tabella una TRUNCATE (DDL) e terribilmente piu' efficiente di una DELETE (DML).
Utilizzare le Stored Functions consente spesso buoni vantaggi prestazionali
evitando traffico ed accessi al DB.
PostgreSQL consente di scrivere Stored Functions [NdA anche Stored Procedures dalla versione 11]
in diversi linguaggi, naturalmente il piu' utilizzato e' il PL/pgSQL.
Le statistiche sull'utilizzo e la durata delle Stored Functions sono riportate
nella vista pg_stat_user_functions [NdA che viene popolata impostando il parametro track_functions
= none | all | pl ].
Fondamentale per l'analisi degli SQL e' la statistica dell'estensione pg_stat_statements
[NdA il dettaglio viene scelto con
pg_stat_statements.track = top | none | all].
Le funzioni possono essere dichiarate STABLE (il risultato non cambia nella stessa transazione)
o IMMUTABLE (il risultato non cambia a fronte degli stessi parametri);
queste due impostazioni possono far risparmiare richiami rispetto al default VOLATILE
che richiede che lo statement sia rieseguito ogni volta.
Quando e' possibile e' meglio utilizzare il linguaggio SQL anziche' il PL/pgSQL nelle stored functions:
l'overhead e' minore e l'impatto puo' diventare sensibile quando il numero di chiamate e' elevato.
Nei casi delle funzioni piu' semplici, se realizzate in SQL, le Stored Functions
possono essere inserite inline nell'SQL chiamante e non vengono neanche
tracciate dalla vista pg_stat_user_functions perche' l'ottimizzatore le trasforma
in clausole della query.
Per le tabelle di grandi dimensioni e' possibile utilizzare il partitioning. In Postgres sono disponibili due differenti modalita' di partizionamento: declarative partitioning (range, list, hash) e partitioning using inheritance. In questa paginetta non ne abbiamo parlato perche' l'argomento e' molto ampio e richiede una trattazione specifica. Dal punto di vista prestazionale il partizionamento dichiarativo (o nativo) e' quello che offre migliori prestazioni su tabelle di grandi dimensioni.
Le versioni piu' recenti di Postgres possono eseguire la compilazione JIT. I parametri per l'attivazione da parte dell'ottimizzatore sono piuttosto elevati ma, per query molto pesanti dopo un opportuno test, e' possibile ridurli ottenendo in qualche caso un notevole miglioramento delle prestazioni. Tipicamente la compilazione e' vantaggiosa solo nel caso di query analitiche [NdA l'LLVM ed il JIT sono stati introdotti in PG11, i default sono cambiati in PG12, per query di breve durata il JIT e' svantaggioso].
Per le attivita' batch puo' essere vantaggioso rilassare le attivita' di scrittura sul disco impostando:
SET LOCAL synchronous_commit = 'off';
Si tratta di un parametro che consente di ridurre il carico sull'I/O e rende piu' veloci
le attivita' batch. Attenzione: non va utilizzato sulle attivita' OLTP ma e' un parametro sicuro.
Altri dettagli sul tuning si trovano nel documento Tuning Postgres
ma e' sicuramente importante ricordare i parametri shared_buffers e max_wal_size.
Vi sono ulteriori parametri che sono teoricamente utilizzabili per rendere piu' veloci le scritture
ma, poiche' rischiano di corrompere la base dati, non sono volutamente riportati in questa pagina.
Come gia' riportato, in caso di caricamento massivo dei dati e' conveniente non avere indici e crearli solo alla fine. Volendo riassumere le principali indicazioni applicabili in caso di caricamento massivo di dati: rimozione degli indici, rimozione dei constraint, rimozione dei trigger, utilizzare il comando COPY anziche' la INSERT, utilizzare il comando INSERT con valori multipli [NdA si puo' utilizzare il comando INSERT multiplo direttamente da SQL o utilizzando il parametro di connessione reWriteBatchedInserts del JDBC], eseguire il commit su un numero elevato e configurabile di record, evitare UPDATE successive dei dati ma se necessario eseguire UPDATE di tipo HOT, nel caso di colonne di grandi dimensioni valutare modifiche dei parametri di storage, utilizzare tabelle TEMPORARY (eg. CREATE TEMPORARY TABLE mytable ...), impostare la modalita' UNLOGGED (eg. ALTER TABLE mytable SET UNLOGGED;), disabilitare il synchronous_commit, sfruttare il parallelismo. Non tutte le indicazioni riportate sono applicabili in tutti casi e vanno utilizzate con attenzione. Se non si e’ certi della qualita’ dei dati caricati eliminare gli indici univoci o i constraint comporta un rischio: in questo caso conviene eseguire il drop dei soli indici prestazionali. Ovviamente le tabelle temporanee non vengono salvate (inoltre non vengono eseguiti in modo automatico VACUUM ed ANALYZE anche se possono essere effettuati da SQL) e spariscono al termine della sessione. Ancora maggiore e’ il rischio nell’utilizzo di tabelle UNLOGGED che non vengono protette dalla scrittura dei WAL, non vengono replicate e, in caso di riavvio con errore della base dati restano come struttura ma vengono troncate. I vantaggi prestazionali che si possono ottenere sono molto variabili e vanno giudicati caso per caso. Naturalmente al termine dell'attivita' di caricamento vanno ricreati indici, constraint, ... e sara' opportuno eseguire un ANALYZE; infine nel caso siano stati effettuati degli update, sara' opportuno anche un VACUUM.
PostgreSQL e PgJDBC supportano i prepared statement sia client-side che server-side.
Questo comporta vantaggi perche' gli oggetti java non debbono essere creati ogni volta
ma e' sufficiente il bind dei nuovi valori; con i prepared statement client-side
Postgres riceve comunque una nuova richiesta per ogni esecuzione.
Il vantaggio dei prepared statement server-side e' ancora superiore perche'
in questo caso viene ridotta la parte di parsing.
Dalla versione 12 e' disponibile il parametro plan_cache_mode per controllare
la generazione dei piani di esecuzione per i server-side prepare statement.
I prepared statement possono essere utilizzati anche con i normali client SQL:
Un'ultima importante segnalazione: le applicazioni debbono sempre chiudere le transazioni effettuando il commit! Se non vengono effettuati i commit i lock non vengono rilasciati e, se questo avviene per un lungo periodo, i processi di autovacuum non possono liberare spazio [NdA in questo caso neanche i VACUUM o i VACUUM FULL riescono a liberare lo spazio delle dead rows finche' non terminano le transazioni precedenti al loro xmax]. Determinare le sessioni che non hanno eseguito il commit e' molto semplice perche' sono in stato "Idle in Transaction" anziche' "Idle".
Abbiamo dato molte indicazioni su come ottimizzare gli statement SQL, tra gli altri: creare indici, creare indici multicolonna, eseguire l'ANALYZE, aumentare gli istogrammi, sfruttare le statistiche estese, utilizzare le CTE, creare le tabelle come UNLOGGED, cancellare indici/trigger/constraint, impostare i parametri dell'ottimizzatore, eseguire COMMIT frequenti, partizionare le tabelle, ...
L'ultima indicazione e'... non applicatele!
O meglio, non applicate questi suggerimenti se non sapete cosa state facendo.
Ciascuna indicazione ha un'applicazione precisa e puo' essere molto vantaggiosa solo se e' utilizzata in modo corretto e nei casi in cui e' richiesta. Sopratutto se operate su un database di produzione bisogna prima capire, misurare, misurare, provare, riprovare, ... e solo a questo punto si puo' applicare la correzione individuata e... nuovamente misurare!
Nella distribuzione community di PostgreSQL gli HINT, per scelta, non esistono!
Vi sono una serie di estensioni, non comprese in PostgreSQL community, che forniscono ulteriori indicazioni sul query planner o abilitano nuove funzionalita'. Alcune sono effettivamente molto interessanti.
Il primo esempio da riportare e' sicuramente l'ottimo pg_hint_plan, che fornisce il supporto per gli HINT. Con un esempio e' molto semplice comprendere la sua sintassi:
/*+ HashJoin(a b) SeqScan(a) */ EXPLAIN SELECT * FROM pgbench_branches b JOIN pgbench_accounts a ON b.bid = a.bid ORDER BY a.aid;
Gli hint utilizzabili sono
parecchi
e possono essere combinati tra loro per indicare un completo execution plan.
E' anche possibile assegnare un hint ad un queryid inserendo una riga nella tabella hint_plan.hints.
pg_hint_plan non fa parte delle estensioni distribuite con la versione community per le installazioni on-premises
ma e' semplice aggiungerlo.
La maggioranza dei cloud provider ha aggiunto pg_hint_plan all'elenco delle estensioni disponibili per i servizi PostgreSQL
e relativi fork
(eg. Amazon RDS, Amazon Aurora PostgreSQL, Google Cloud SQL, Azure Database for PostgreSQL, YugabyteDB, ...).
Con Postgres EDB Advanced Server sono disponibili gli HINT e l'optimizer mode con una sintassi simile a quella del database Oracle.
In Aurora PostgreSQL e' disponibile il Query Plan Management (QPM) che consente di scegliere gli execution plan da utilizzare.
Alcune estensioni ed alcuni fork di PostgreSQL utilizzano strutture dati differenti ottimizzate per applicazioni particolari (eg. TimescaleDB e' un'estensione di PostgreSQL per la gestione di dati Time Series).
In questa paginetta sono stati riportati elementi utili per l'ottimizzazione SQL. Altri punti di vista sono riportati nei documenti Statistiche prestazionali in PostgreSQL (in particolare l'estensione pg_stat_statements) e Tuning PostgreSQL.
Auguri!
Titolo: Ottimizzazione SQL in PostgreSQL
Livello: Esperto
Data:
14 Febbraio 2021 ❤️
Versione: 1.0.4 - 31 Ottobre 2024 🎃
Autore: mail [AT] meo.bogliolo.name