Pgpool-II
 PostgreSQL
e' un potente DBMS relazionale Open Source noto per
la robustezza e la ricchezza di funzionalita'.
PostgreSQL
e' un potente DBMS relazionale Open Source noto per
la robustezza e la ricchezza di funzionalita'.
Pgpool-II
e' uno strumento Open Source che fornisce funzioni
di alta affidabilita', bilanciamento di carico, pooling delle connessioni,
cache delle query, ... in modo trasparente alle applicazioni che
utilizzano PostgreSQL.
Configurato correttamente Pgpool-II e' un ottimo proxy che opera in modo trasparente
tra le applicazioni ed i database PostgreSQL facendo in modo che ogni connessione
ed ogni statement siano indirizzati al nodo corretto.
Questa pagina descrive le principali modalita' di configurazione ed utilizzo
di Pgpool-II con PostgreSQL.
E' opportuna una conoscenza di base su Postgres;
un documento introduttivo su PostgreSQL
e' Introduzione a PostgreSQL,
mentre un documento piu' completo e' Qualcosa in piu' su PostgreSQL.
Importante e' anche conoscere la
Streaming replication PostgreSQL.
PostgreSQL
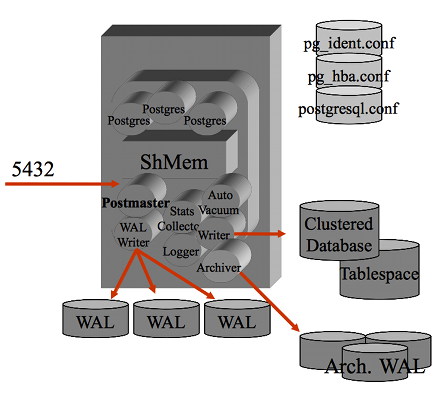 Un breve accenno all'architettura di PostgreSQL puo' essere utile...
Un breve accenno all'architettura di PostgreSQL puo' essere utile...
Il processo
postmaster e' il processo principale che si occupa della gestione delle
connessioni
ed e' il "padre" di tutti i processi, sia di sistema (eg. wal writer)
sia quelli relativi alle connessione utente.
Tutti i processi girano come utente postgres ed eseguono un attach
al segmento di shared memory su cui vengono mantenuti buffer e lock.
I processi utente sono facilmente individuabili (eg. con il comando ps -efa) poiche'
nella command line riportano il database utilizzato, l'IP(porta) del client e lo stato.
Gli altri processi sono quelli di background di postgres.
La configurazione dei parametri di PostgreSQL si effettua modificando il file postgresql.conf
mentre la configurazione degli accessi si effettua nel file pg_hba.conf e quindi a livello
di database con i comandi SQL di GRANT.
 Il processo postmaster e' in LISTEN sulla porta socket 5432 (e' il default ma puo' essere cambiata)
e per ogni connessione attiva un processo utente.
Quando il numero di connessioni e' elevato il carico sulla memoria del sistema ospite puo' essere
significativo.
Il processo postmaster e' in LISTEN sulla porta socket 5432 (e' il default ma puo' essere cambiata)
e per ogni connessione attiva un processo utente.
Quando il numero di connessioni e' elevato il carico sulla memoria del sistema ospite puo' essere
significativo.
Nella fase iniziale della connessione di un client vengono scambiati gli
hash delle password
(in modo crittografato se indicato nel file pg_hba) ma tutta la successiva trasmissione
dati avviene in chiaro con il protocollo TCP.
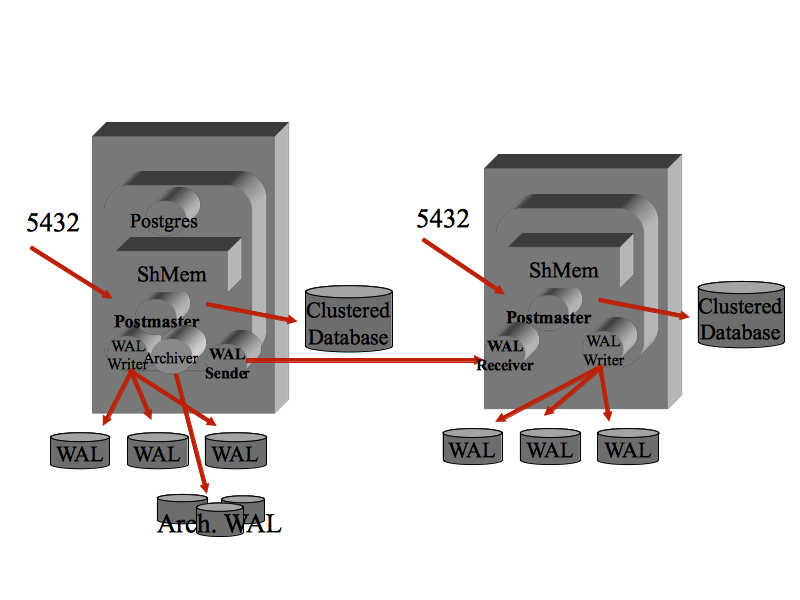
E' possibile replicare i dati su un'ulteriore istanza PostgreSQL mediante
la Streaming replication.
La replica di una base dati PostgreSQL e' basata sulla ricezione e l'applicazione dei WAL sui sistemi secondari o Standby.
Nelle prime versioni di PostgreSQL era presente la sola modalita' di log shipping
ma le versioni piu' recenti implementano la streaming replication che ha una latenza molto bassa
poiche' le modifiche vengono inviate in modo asincrono appena eseguite sul primary.
La configurazione si effettua sui file postgresql.conf e standby.signal.
La replica e' uno ottimo strumento di Disaster Recovery: caso di failover il server secondario viene promosso a primario
con RPO ed RTO molto bassi.
Il nodo secondario e' tipicamente aperto in lettura (Hot Standby) e puo' essere utilizzato per
eseguire i backup o da applicazioni client in Read-Only.
E' compito del client collegarsi al nodo primario o al secondario a seconda
del loro stato e delle necessita' applicative.
Pgpool-II
Pgpool-II viene posto davanti ad uno o ad una serie di DB PostgreSQL per fornire alcune funzionalita'
che non sono disponibili con un'installazione singola di PostgreSQL:
- High Availability
Pgpool-II fornisce l'alta affidabilita' (HA: High Availability)
su una gruppo di database PostgreSQL e su se stesso rimuovendo
dal pool i DB che non rispondono.
Per fare questo Pgpool-II utilizza controlli sul DB,
un sofisticato algoritmo di quorum
ed un processo di Watchdog (per se stesso) per evitare falsi positivi e split brain.
- Load balancing
Pgpool-II distribuisce le query sui server disponibili bilanciando il carico.
Pgpool-II distingue nelle query tra SELECT e DML inviando le modifiche al primary
o a tutti i nodi a seconda della configurazione.
- Connection Pooling
Pgpool-II mantiene attive le connessioni al DB e le riutilizza quando richieste dai client.
Questo riduce in modo significativo il carico dovuto all'apertura di nuove connessioni.
- Online Recovery
Pgpool-II puo' lanciare comandi di recovery e riagganciare nodi di standby o nuovi nodi PostgreSQL.
- Limiting Exceeding Connections
PostgreSQL ha un numero massimo di connessioni che non puo' essere superato.
Anche Pgpool-II ha un numero massimo di connesioni ma anziche' restituire un errore immediatamente
accoda le richieste consentendo di superare eventuali picchi di accesso.
- In Memory Query Cache
Pgpool-II puo' salvare i risultati delle query e restituirli nuovamente
se vengono richiesti da query identiche.
Poiche' non viene eseguito nessun accesso alla base dati
l'utilizzo di una cache e' estremamente veloce e vantaggioso anche
se si tratta di query semplici.
Solo alcuni tipi di applicazioni pero' effettuano questo tipo di accessi.
Pgpool-II utilizza il protocollo di rete PostgreSQL
e quindi le applicazioni accedono a Pgpool-II senza necessita' di modifiche.
Architettura
Nella configurazione piu' semplice Pgpool-II e' posto davanti ad un DB PostgreSQL.
Per default Pgpool-II attiva 32 processi pronti ad accettare le connessioni dall'esterno
ed a reindirizzarle verso il database PostgreSQL.
Ciascun processo figlio gestisce un pool di connessioni.
Tuttavia le funzionalita' di HA di Pgpool-II si sfruttano mettendo in cluster due o piu' PostgreSQL
configurati in replica.
Vi sono sei differenti modalita' di cluster supportate da Pgpool-II:
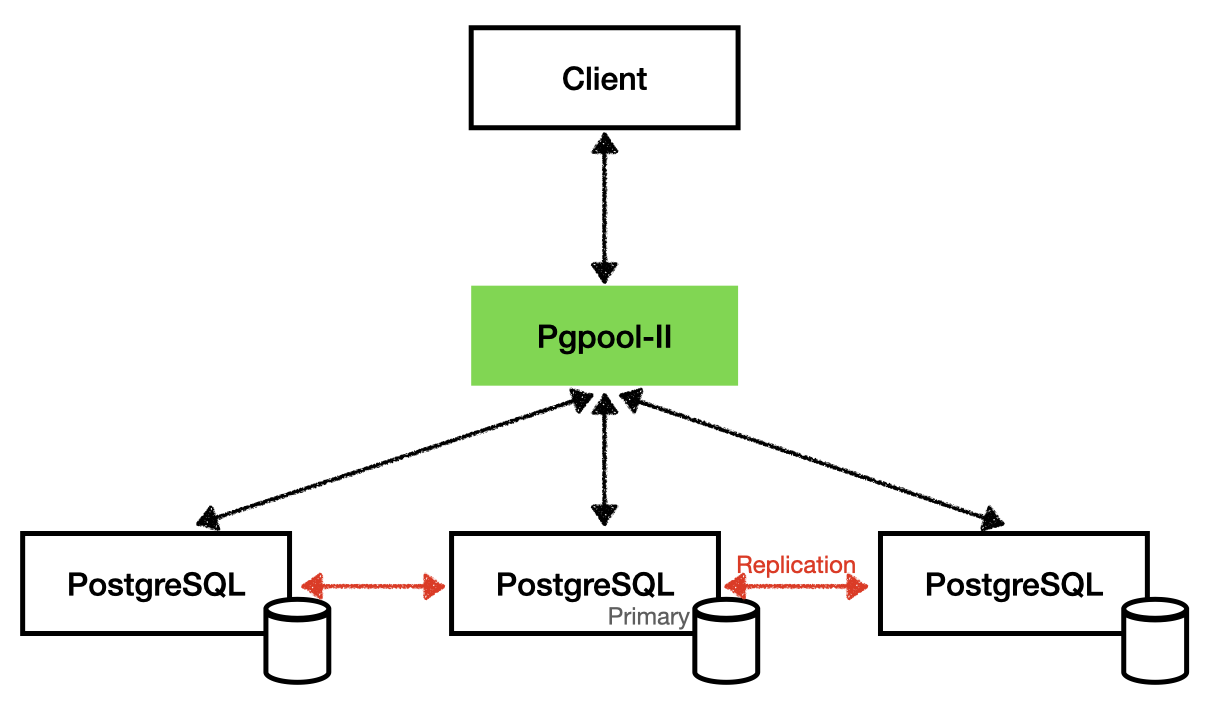
- streaming replication mode
La modalita' consigliata e' quella in cui la
streaming replication PostgreSQL
si occupa della sincronizzazione dei DB.
In questa modalita' e' disponibile il Load Balancing.
Non e' sempre garantita la consistenza tra i nodi (potrebbero essere in ritardo nell'applicazione
degli statement DML).
- snapshot isolation mode
In questa modalita' Pgpool-II si occupa di sincronizzare i database.
Con questa configurazione la presenza di piu' istanze di database e' resa completamente
trasparente alle applicazioni.
Vi sono alcune avvertenze. Le basi dati PostgreSQL vanno configurate con default_transaction_isolation = 'repeatable read'.
Vi e' un impatto prestazionale per il maggior impegno richiesto per mantenere le transazioni consistenti.
- native replication mode
Anche in questa modalita' Pgpool-II si occupa di sincronizzare i database.
La differenza rispetto alla modalita' precedente e' che non e' richiesto l'isolation mode repeatable read;
tuttavia in questo caso non puo' essere garantita la consistenza in lettura.
- logical replication mode
E' possibile configurare i database in replica logica.
Poiche' la replica logica potrebbe sincronizzare solo alcune tabelle
e Pgpool-II effettua comunque il load balancing di tutte le tabelle
e' possibile ricevere dati diversi sui subscriber.
- main replica mode
La main replica mode, o slony mode, viene utilizzata con database PostgreSQL che utilizzano Slony.
E' Slony mantiene sincroni i database. Da quando e' stata introdotta la streaming replication
Slony-I e' molto meno utilizzato e si consiglia questa modalita' solo in presenza di una precedente
configurazione con Slony.
- raw mode
In questa modalita' Pgpool-II non verifica la sincronizzazione dei database.
E' compito dell'applicazione fare in modo che i dati siano significativi ed acceduti in modo corretto.
In ogni modalita' Pgpool-II fornisce connection pooling e automatic fail over.
L'online recovery e' disponibile solo con streaming replication mode, snapshot isolation mode e native replication mode.
Oltre alla consistenza dei dati sui database Pgpool-II fornisce anche l'alta affidabilita' su se stesso
utilizzando un processo di Watchdog.
Vanno attivate piu' istanze di Pgpool-II su server diversi,
per l'HA e' necessario un numero dispari ed un minimo di 3 istanze.
All'avvio un'istanza di Pgpool-II diventa leader e prende il VIP del servizio.
Un ultimo punto importante riguardo all'architettura e' quello relativo al deploy di Pgpool-II
ovvero dove installarlo.
Sui web/application server oppure sui nodi che ospitano la base dati oppure su server/VM/container dedicati?
La prima scelta e' la meno utilizzata per Pgpool-II
e si preferiscono piu' nodi dedicati
ma in realta' ogni soluzione presenta vantaggi e svantaggi:
la scelta migliore dipende dall'architettura complessiva del sistema
e spesso e' opportuno eseguire un benchmark per validare la soluzione scelta.
Installazione
E' possibile installare Pgpool-II partendo dai sorgenti,
ma e' molto piu' semplice installare il software utilizzando il repository
http://www.pgpool.net/yum con
yum install pgpool-II-pg14
Quindi i comandi per attivare il servizio sono:
systemctl enable pgpool.service
systemctl start pgpool.service
Attenzione: prima di attivare il servizio pgpool vanno attivati i DB PostgreSQL
e viceversa in fase di spegnimenti prima va disattivato pgpool e poi i database.
Configurazione
Il file principale di configurazione e' pgpool.conf
nella directory /etc/pgpool-II e viene tipicamente creato
il file pgpool.conf.sample durante l'installazione che e' possibile copiare
come versione iniziale della configurazione.
La configurazione dipende dall'architettura finale che si desidera avere:
e' possibile avere uno o piu' DB PostgreSQL con configurazioni di replica differenti,
uno o piu' servizi pgpool installati sugli stessi nodi o su altri, ...
Vediamo quindi alcuni dei parametri piu' significativi:
listen_addresses = '*'
port = 9999
pcp_listen_addresses = '*'
port = 9898
backend_clustering_mode = 'streaming_replication'
num_init_children = 32
backend_hostname0 = 'pg1'
backend_port0 = 5432
backend_weight0 = 1
backend_data_directory0 = '/var/lib/pgsql/14/data'
backend_flag0 = 'ALLOW_TO_FAILOVER'
backend_hostname1 = 'pg2'
backend_port1 = 5432
backend_weight1 = 1
backend_data_directory1 = '/var/lib/pgsql/14/data'
backend_flag1 = 'ALLOW_TO_FAILOVER'
memory_cache_enabled = off
Pgpool-II fornisce un'interfaccia di amministrazione che risponde alla porta di defaul 9898.
La configurazione delle utenze si esegue nel file pcp.conf inserendo righe con il formato
user:md5_password. Per ottenere le password si utilizza il comando pg_md5.
Il file pool_hba.conf e' l'analogo del file pg_hba.conf e puo' essere configurato
per l'autenticazione delle sessioni utente.
Le possibilita' di configurazione sono molto ampie ed includono la parte relativa ai controlli della replica,
all'eventuale query cache, ...
Un esempio completo, e complesso, di configurazione si trova sulla
documentazione ufficiale.
Utilizzo
Dal punto di vista dell'utilizzo applicativo accedere direttamente ad un database PostgreSQL
o attraverso Pgpool-II e' indifferente.
Tipicamente la porta socket in ascolto di PostgreSQL e' la 5432 mentre quella Pgpool-II
e' la 9999, ma sono entrambe valori che possono essere cambiati.
I comandi amministrativi vengono invece rivolti al processo PCP sulla porta di default 9898.
Tra i comandi utili:
pcp_node_info -p 9898 -a;
pcp_health_check_stats -h localhost -p 9898 0;
pcp_watchdog_info -h localhost -p 9898 -U pgpool -v;
...
Versioni
La versione piu' recente e' consigliata di Pgpool-II e' la 4.4.0.
Pgpool-II e' disponibile su Unix/Linux e supporta le versioni di PostgreSQL dalla 7.4;
e' molto opportuno che le major version dei PostgreSQL gestiti siano le stesse,
eventuali differenze sulle minor version di solito non danno problemi.
Sul
sito ufficiale
sono riportate
la roadmap
e le versioni
di Pgpool-II.
(Sources:
History
Version EOF
Version EOF
)
| Version |
Status |
Features |
Last release |
Date (from) |
Date (to) |
Notes |
| 4 | Production | (4.1 2019-10). (4.2 2020-11). (4.3 2021-12). (4.4 2022-12).
| 4.3.3
4.4.2 | 2018-10 | 2027-11 |
|
| 3 | Production | (3.2): watchdog. (3.5): watchdog quorum, external mode. (3.7 2017-11): quorum failover
| 3.7.25 | 2016-07 | 2022-12 |
|
| 2 | EOF |
| 2 | | |
|
| 1 | EOF | Public project renamed as pgpool-II. More than two server support, parallel query mode, PCP commands.
| 1 | 2006 | |
|
| pgpool 2.0 | EOF | Load balancing, PG protocol 3 support. (2005): automated fail over, master slave mode.
| 2 | 2004 | |
|
| pgpool 1.0 | EOF | Native replication (SQL statement based replication).
| 1 | 2004 | |
|
| pgpool | EOF | Personal project by Tatsuo Ishii for connection pooling.
| 0 | 2003 | |
|
Varie ed eventuali
Quando il numero di connessioni a PostgreSQL e' elevato e' sempre opportuno utilizzare
un connection pooling.
In molti casi si utilizzano connection pool applicativi
ma e' anche possibile utilizzare tool esterni.
Un altro importante tool per gestire le connessioni a Postgres
e' PgBouncer.
Entrambe sono ottimi strumenti Open Source ed hanno alcune funzionalita' equivalenti.
Ma vi sono anche importanti differenze che li rendono indicati a casi d'uso differenti:
PgBouncer e' piu' efficiente ed ha piu' possibilita' di configurazione dei connection pool,
Pgpool-II e' un proxy completo e fornisce funzionalita' di alta affidabilita' e di bilanciamento di carico.
Infatti in qualche caso possono essere utili entrambe gli strumenti nella stessa architettura:
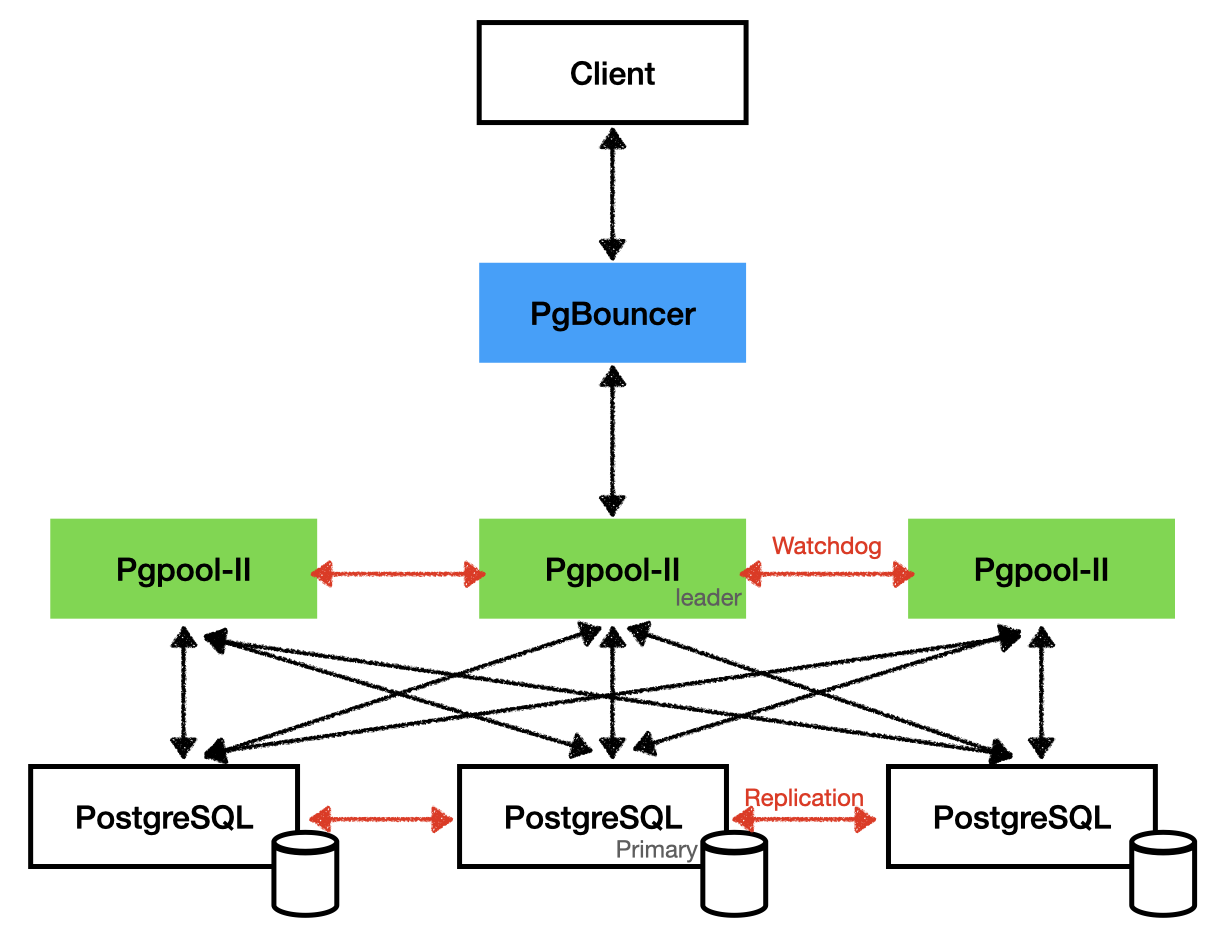
Nella figura di esempio PgBouncer e' utilizzato per il connection pooling mentre
Pgpool-II e' utilizzato per l'HA ed il load balancing di tre database PostgreSQL
in streaming replication.