Indici B-Tree in PostgreSQL
La creazione degli indici corretti in un database relazionale e' fondamentale
per ottenere buone prestazioni nelle query.
La teoria sull'argomento e' assolutamente consolidata da tempo
e la pratica, ovvero i comandi SQL per la creazione degli indici, quasi elementare.
Quindi questa pagina potrebbe essere inutile perche' ripetera'
concetti e tecniche gia' descritti migliaia di volte.
Tuttavia nella normale attivita' di un DBA
il numero di errori nella creazione di
indici e' talmente elevato che mi sono convinto a scrivere qualcosa
che spero sia utile o almeno interessante.
Questa pagina cerca di trattare in modo semplice ma completo
gli indici B-Tree multicolonna in
PostgreSQL
anche se alcuni concetti sono generali e possono essere applicati
ad altri tipi di indici ed a tutti i database relazionali.
Dopo una prima
introduzione,
sono descritti l'utilizzo degli indici multicolonna,
le diverse opzioni possibili nella definizione degli indici,
i limiti presenti,
l'impatto con la modifica dei dati,
ed infine gli errori piu' comuni,
...
Ho fretta!
La creazione di un indice e' banale:
CREATE INDEX idx_01 ON t (a, b, c);
Questa DDL in Postgres crea un indice sulla tabella t
per le colonne a, b, c rispettivamente.
Si tratta di un indice secondario multicolonna di tipo B-Tree.
Qualche consiglio veloce sugli indici in PostgreSQL:
- Create sempre tutte le Primary Key e gli indici Unique.
- Utilizzate preferibilmente chiavi di tipo numerico.
- Create indici utili alle query che vengono eseguite.
- Create gli indici relativi alle Foreing Key.
- Definite l'indice ordinando le colonne mettendo prima quelle che vengono utilizzate nelle condizioni di query piu' spesso.
- Definite l'indice ordinando le colonne mettendo prima quelle che sono piu' selettive.
- Cercate di inserire nell'indice tutte le colonne utilizzate nelle condizioni di ricerca.
- Cercate di inserire nell'indice tutte le colonne da cui si estraggono i dati.
- Limitate il numero di colonne definite nell'indice.
- Non create indici prestazionali su tabelle con pochi record.
- Non create indici su colonne che non vengono utilizzate nelle condizioni.
- Non create indici su tabelle fortemente modificate.
- Non create indici su colonne poco selettive.
- Non create indici su colonne con molti valori NULL.
- Non create indici su colonne modificate di frequente.
I suggerimenti indicati sopra sembrano in conflitto tra loro... ed in parte lo sono!
Ma le indicazioni hanno ragioni tecniche ben precise,
vi sono diverse eccezioni, ci sono molte opzioni
e vi sono parecchi ulteriori dettagli:
continuate a leggere!
Introduzione
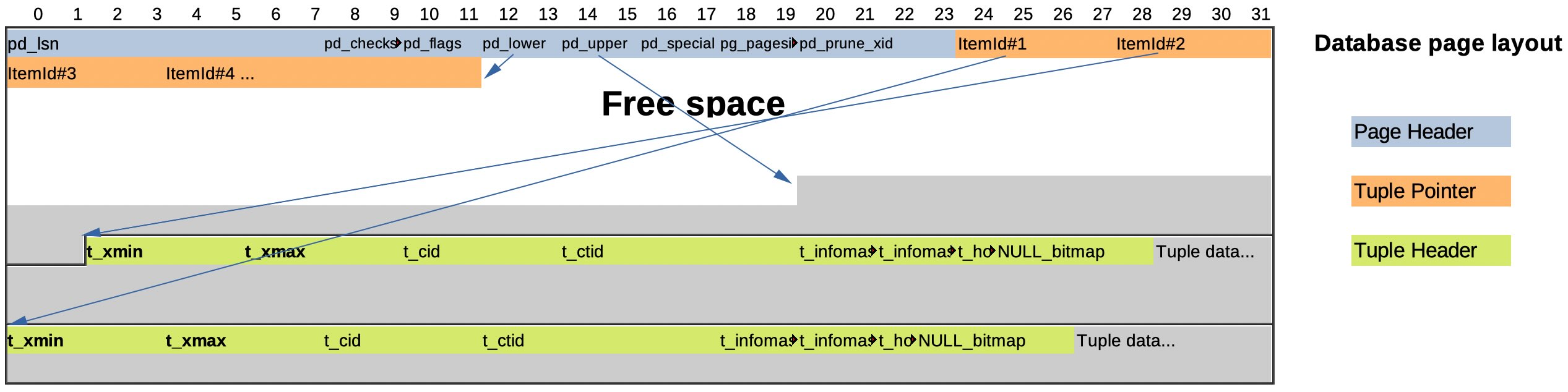 In un database relazionale i dati sono contenuti nelle... relazioni,
in pratica si tratta di tabelle con righe e colonne.
Le tabelle possono essere di grandi dimensioni e sono memorizzate
su data file organizzati in pagine o blocchi.
In un database relazionale i dati sono contenuti nelle... relazioni,
in pratica si tratta di tabelle con righe e colonne.
Le tabelle possono essere di grandi dimensioni e sono memorizzate
su data file organizzati in pagine o blocchi.
Ogni database relazionale ha le sue caratteristiche dal punto di vista
di struttura fisica dei cati.
In PostgreSQL il blocco ha una dimensione fissa di 8KB
[NdA in realta' si puo' modificare ricompilando il codice ma si fa solo in casi particolari].
Ogni blocco contiene una serie di righe, quando il blocco e' pieno
semplicemente si utilizza un nuovo blocco.
All'interno di ciascuna riga la struttura dipende dai datatype utilizzati.
L'insieme dei blocchi che contengono i dati di una tabella Postgres viene chiamato Heap.
Naturalmente tabelle di grosse dimensioni avranno un numero di blocchi molto elevato
ed i file che le contengono saranno di grandi dimensioni.
La lettura di tutti i dati da una tabella di grandi dimensioni richiede
quindi un tempo relativamente elevato.
Per rendere efficiente l'accesso ai dati vengono utilizzati gli indici.
Gli indici consentono di reperire i dati cercati nella tabella con un
numero minore di accessi ai blocchi di dati rispetto a scorrere l'intero
contenuto della tabella (Seq Scan).
I tipi di indice piu' utilizzati sono i B-tree:
 I B-tree sono alberi bilanciati che cercano di mantenere limitato il numero di livelli
per raggiungere i dati finali che sono sulle foglie.
La ricerca parte sempre dal blocco di primo livello dell'indice,
si confronta il valore cercato con quelli presenti nel blocco
ed a seconda del confronto si procede ai livelli sucessivi.
I B-tree sono alberi bilanciati che cercano di mantenere limitato il numero di livelli
per raggiungere i dati finali che sono sulle foglie.
La ricerca parte sempre dal blocco di primo livello dell'indice,
si confronta il valore cercato con quelli presenti nel blocco
ed a seconda del confronto si procede ai livelli sucessivi.
E' possibile utilizzare indici definiti su una sola colonna o su piu' colonne.
Con un indice multicolonna e' come se il contenuto delle diverse colonne
fosse concatenato per ottenere la chiave finale utilizzata dall'indice.
L'ordine delle colonne utilizzato nella creazione di un indice molticolonna e' molto importante.
Un albero B-tree e' bilanciato quindi il numero di livelli e'
mantenuto limitato anche se a volte e' necessario ricostruirlo
per avere le migliori prestazioni.
Qual'e' il vantaggio nell'uso dell'indice? Per la ricerca senza indice e' necessario accedere
a tutti i blocchi della tabella che crescono linearmente con il numero
di record. Quindi la complessita' temporale della ricerca e' O(N).
Per la ricerca con indice e' necessario accedere al numero di livelli
dell'indice piu' un accesso al blocco della tabella;
ma il numero di livelli dell'indice cresce con il logaritmo
(con base il numero di chiavi per blocco).
In questo caso la teoria dice che la complessita' dell'algoritmo e' O(logB N):
in pratica i tempi crescono in modo logaritmico, con un logaritmo con base elevata
che dipende dal numero di chiavi che e' possibile memorizzare in un blocco.
Complessita' temporale?
Facciamo un esempio con i numeri! Abbiamo una tabella da 10.000.000 di record con 100
record per blocco e 256 chiavi per blocco di indice su cui ricercare una riga per chiave univoca.
L'accesso in full scan richiede 100.000 di accessi a disco,
mentre con l'indice bastano 4 accessi: tre sull'indice ed uno alla tabella
(256^3 >16M).
Il numero di chiavi presenti in un blocco di indice e' generalmente dell'ordine delle migliaia
e quindi il vantaggio e' ancora maggiore di questo semplice esempio numerico.
Per questo un Index Scan e' molto piu' veloce di un Sequential Scan
quando si effettua una ricerca per estrarre pochi record.
Le differenze in tempo con tabelle di grandi dimensioni spesso sono di tre o quattro ordini di grandezza:
si puo' passare dalle ore ai secondi creando l'indice corretto.
L'esempio numerico precedente e' stato fatto per una chiave univoca,
ma vale comunque purche' le condizioni siano selettive.
Quindi il forte vantaggio dell'accesso per indice vale per indici univoci, per chiavi duplicate,
per indici su piu' colonne, per condizioni diverse dall'uguaglianza, ...
Un altro aspetto importante e' il numero di chiavi contenute in un blocco di indice:
piu' chiavi e' possibile memorizzare in un blocco minore e' il livello dell'albero di ricerca;
di converso piu' e' complessa e lunga una chiave piu' spazio occupera', minora sara' il numero
di chiavi per blocco e maggiore in numero di livelli dell'indice.
Ma ora che abbiamo visto quanto e' vantaggioso un indice vediamo quando possiamo utilizzarlo.
Utilizzare un indice B-tree multicolonna
Quando si puo' utilizzare un indice?
La ricerca per uguaglianza e' solo una delle possibilita', anche se probabilmente la piu' importante di tutte.
Un indice B-tree puo' essere utilizzato per i seguenti operatori:
= < <= > >= BETWEEN IN() IS NULL IS NOT NULL LIKE ILIKE
Inoltre un indice B-tree puo' essere utilizzato per ordinare i dati nell'ordine delle colonne su cui e' stato definito,
per ricercare il min() o il max(), per raggruppare i dati,
per velocizzare i join, per eseguire il controllo dei constraint, ...
Le ricerche possono sempre essere svolte su tutte colonne definite nell'indice,
perche' in genere e' piu' efficiente che eseguirle sulla heap.
 Pero' le ricerche piu' efficienti sono quelle che limitano la porzione di indice
che deve essere letta.
La regola che debbono soddisfare tali ricerche e'
che vengano utilizzate condizioni di uguaglianza per tutte le colonne piu' a sinistra
ed al massimo una condizione di disuguaglianza per l'ultima colonna usata nella ricerca.
Pero' le ricerche piu' efficienti sono quelle che limitano la porzione di indice
che deve essere letta.
La regola che debbono soddisfare tali ricerche e'
che vengano utilizzate condizioni di uguaglianza per tutte le colonne piu' a sinistra
ed al massimo una condizione di disuguaglianza per l'ultima colonna usata nella ricerca.
Se e' definito un indice per la tabella T sulle colonne A, B, C
nell'ordine, le ricerche possono essere effettuate nel modo seguente:
- WHERE A=$1 AND B=$2 AND C=$3 Utilizzera' le tre condizioni di uguaglianza per estrarre i dati
- WHERE A=$1 AND B=$2 AND C > $3 Utilizzera' le due condizioni di uguaglianza ed un confronto per estrarre i dati
- WHERE A=$1 AND B between $2 AND $3 AND C > $4 Potra' utilizzare una sola condizione di uguaglianza per la prima
colonna, la condizione di disuguaglianza per la seconda colonna e dovra' scandire tutti valori della terza colonna
anche se e' presente la condizione di uguaglianza per C
- ...
- WHERE B=$2 AND C=$3 Mancando la condizione per A dovra' accedere a tutti i blocchi dell'indice
Con un indice su tre colonne i casi possibili (condizione di uguaglianza, condizione di disuguaglianza, nessuna condizione)
sono 27 (3^3), con quattro sono 81, ...
La tabella riportata riporta il grado la selettivita' delle ricerche a seconda delle condizioni utilizzate
rispetto alle colonne definite per un indice multicolonna su tre colonne.
 Un esempio? Interroghiamo i NERI fino alla N:
Un esempio? Interroghiamo i NERI fino alla N:
SELECT *
FROM alunni
WHERE cognome = 'neri'
AND nome <= 'n';
Se e' presente un indice multi colonna su cognome, nome
e' possibile eseguire la ricerca sull'albero dell'indice usando
tutte le condizioni di ricerca.
L'ordine delle colonne in un indice B-tree multicolonna e' molto importante.
La seguente ricerca utilizza lo stesso indice ma puo' sfruttare solo
una condizione di disuguaglianza sulla prima colonna:
SELECT *
FROM alunni
WHERE cognome <= 'n'
AND nome = 'matteo';
Un EXPLAIN riportera' sempre un Index Scan
ma le condizioni usate saranno meno selettive ed il costo piu' elevato.
Riassumendo...
Se nelle condizioni di ricerca sono presenti tutte le colonne dell'indice
l'utilizzo un indice B-tree multicolonna e' tra i piu' efficienti.
E' fondamentale che le colonne usate nelle condizioni vengano messe per prime nell'indice
altrimenti l'indice non puo' essere utilizzato per ridurre la ricerca.
Variazioni sul tema
Le funzionalita' offerte dagli indici in Postgres sono molto ampie e sofisticate,
in questo capitolo cerchiamo di presentare diverse possibilita'
nella definizione e
nell'utilizzo degli indici B-Tree.
Utilizzo di piu' indici (bitmap)
PostgreSQL e' in grado di utilizzare piu' indici (ed anche lo stesso indice in modi diversi)
per selezionare le righe da estrarre da una tabella.
In pratica viene costruita una bitmap in memoria con i riferimenti delle righe estratte
da ogni condizione usando indici diversi. Le bitmap vengono poi confrontate con operatori logici
a seconda delle condizioni di AND OR e NOT presenti nella query ottenendo la lista finale delle righe
da estrarre dalla heap.
L'estrazione dei dati sulla heap avviene alla fine in modo sequenziale accedendo pero'
ai soli blocchi individuati dalle ricerche per indice con un
Bitmap Index Scan.
Se la query contiene condizioni di ricerca su piu' colonne e' piu' efficiente
un indice multicolonna.
Tuttavia se sono presenti diverse tipologie di query con condizioni differenti
un'alternativa e' quella di utilizzare indici su colonne singole
lasciando scegliere all'ottimizzatore quali utilizzare singolarmente
o in combinazione con una bitmap a seconda delle condizioni presenti nella query.
Si potrebbe pensare di definire tutti gli indici possibili e lasciar
decidere all'ottimizzatore la combinazione migliore ogni volta...
ma questo e' sbagliato per le due differenti ragioni
che vedremo nei prossimi capitoli.
Index-Only Scan, Covering Index
Oltre che per eseguire una ricerca o un ordinamento un indice puo' anche essere utilizzato
per ottenere i dati delle colonne senza accedere alla tabella o heap.
Quando il risultato della query puo' essere ottenuto direttamente dall'indice
anziche' un Index Scan viene utilizzato un Index-Only Scan.
Questa tecnica in Postgres puo' essere sfruttata su colonne ulteriori
che non vengono utilizzate come chiavi ma solo per l'estrazione dei dati.
Dalla versione PG 11 sono supportati i covering index con la clausola INCLUDE
definiti come nell'esempio seguente:
CREATE INDEX idx_03 ON t (a, b, c) INCLUDE (d);
La colonna d non viene utilizzata per le ricerche
o come eventuale vincolo di unicita' ma se presente nella clausola SELECT
puo' essere estratta dall'indice senza necessita' di accedere alla tabella.
Index ordering
Come abbiamo visto un indice B-tree puo' essere utilizzato
anche per gli ordinamenti.
Ma se volessimo un elenco decrescente per cognome e crecente per nome?
Nessun problema, dalla versione PG 8.3 sono supportate le opzioni:
ASC DESC NULLS FIRST NULLS LAST
nella creazione indici btree multicolonna.
Partial Index
Molto utili a mio avviso sono i partial index che consentono
di indicizzare solo parte di una tabella. Se viene creato un indice con
CREATE INDEX idx_04 ON fattura (id, cliente) WHERE pagato IS NOT TRUE;
L'indice consentira' di estrarre velocemente le fatture non pagate e sara' di piccole dimensioni
(naturalmente se vi pagano le fatture ;-).
Expression Index
Tra le modalita' piu' potenti per intervenire sulle performance delle query,
sopratutto se non e' possibile correggere il codice SQL, vi sono gli Expression Index
ovvero gli indici basati su espressioni.
La definizione e' molto semplice:
CREATE INDEX idx_05 ON alunni (lower(cognome), lower(nome));
Gli expression index vanno usati in modo limitato poiche' sono piu' pesanti
da creare e da mantenere ma per casi specifici possono essere molto vantaggiosi.
Join
Un'operazione fondamentale nei DB relazionali e' quella del join tra tabelle.
Gli indici sono molto importanti per migliorare le prestazioni dei
join.
Senza entrare in dettaglio sugli algoritmi di join...
un indice B-tree migliora
nettamente le prestazioni del Nested Loop se presente sulla inner table.
Lo stesso algoritmo puo' essere di ordini di grandezza piu' veloce se e' presente l'indice corretto.
E' necessaria la presenza di indici su entrambe le tabelle
per poter eseguire un Merge Join che e' l'algoritmo piu'
efficiente per il join di tabelle di grandi dimensioni.
Tipicamente si tratta della primary key per una tabella e della foreing key
per l'altra, per questo e' importante definire sempre gli indici relativi alle foreing key.
Attenzione: Postgres crea automaticamente gli indici per le primary key e per i constraint unique
ma non crea indici per le foreing key che vanno quindi esplicitamente creati con la relativa DDL.
Ovviamente non vengono utilizzati indici B-Tree per gli Hash Join
ma indici di tipo Hash che PostgreSQL puo' anche creare autonomamente per l'esecuzione di una query
[NdA ma solo se dispone di sufficiente work_mem].
Partitioning
Per le tabelle di grandi dimensioni e' possibile utilizzare il partitioning.
In Postgres sono disponibili due differenti modalita' di partizionamento:
declarative partitioning (range, list, hash) e partitioning using inheritance
[NdA che e' la vecchia modalita' molto meno efficiente ed ora raramente utilizzata].
In questa paginetta non trattiamo in dettaglio il partizionamento perche' l'argomento e' molto
ampio e richiede una trattazione specifica
ma vediamo solo qualche dettaglio relativo agli
indici.
Se una tabella e' partizionata in Postgres gli indici sono sempre partizionati
[NdA su altri RDBMS e' possibile avere indici partizionati e non partizionati, a volte chiamati indici locali e globali].
Gli indici definiti
sulla tabella partizionata vengono creati automaticamente in ogni partizione
presente e futura;
inoltre e' possibile creare indici ulteriori sulle singole partizioni.
Gli indici univoci o le primary key sulle tabelle partizionate
debbono contenere tutti i campi della chiave di partizionamento
e non possono utilizzare espressioni o funzioni.
Se viene definito un indice sulla tabelle partizionata e l'indice non e' presente su tutte le partizioni,
allora risultera' invalido.
Cache
Grazie alla dimensione piu' limitata e per i notevoli vantaggi prestazionali
nelle ricerche sugli indici e molto opportuno che questi vengano mantenuti
in memoria.
Con Postgres per gli indici si cerca sempre di avere un Hit Ratio sulla cache vicino al 100%.
Clustering
In PostgreSQL gli indici sono sempre secondari,
ovvero sono salvati su strutture differenti da quelli della tabella cui
fanno riferimento (chiamata Heap).
E' pero' possibile ordinare il contenuto di una tabella rispetto ad un indice
con il comando CLUSTER per ottenere vantaggi prestazionali su accessi
massivi eseguiti i modo sequenziale.
Le DML successive non mantengono l'ordine ma il comando puo' essere ripetuto.
Gestione
Anche se e' un argomento molto ampio e sarebbe da trattare a parte, cerchiamo di dare qualche
cenno relativo alla gestione degli indici in PostgreSQL.
A differenza di altri DB Postgres consente operazioni di DDL
all'interno di una transazione.
Questo vale anche per la creazione degli indici.
La creazione di un indice richiede un lock sulla tabella che lo riguarda.
Il lock consente le letture (SELECT) ma non le scritture (INSERT, UPDATE, DELETE, MERGE).
Nella creazione di un indice e' possibile utilizzare la clausola CONCURRENTLY che consente
invece le attivita' di scrittura sulla tabella.
L'utilizzo della clausola CONCURRENTLY
rende piu' lenta la creazione dell'indice,
il comando puo' fallire lasciando l'indice in stato INVALID,
puo' essere lanciato un solo REINDEX alla volta,
non puo' essere utilizzato per tabelle partizionate
[NdA ma c'e' il modo per non bloccare le scritture]
e non puo' essere utilizzato all'interno di una transazione;
nonostante questi limiti il grande vantaggio e'
che e' possibile continuare ad eseguire DML sulla tabella.
E' possibile che un indice si corrompa,
se PostgreSQL rileva l'errore l'indice viene segnalato come INVALID.
Il comando REINDEX consente di ricostruire gli indici sia per correggere una corruzione
che per ribilanciarli.
E' possibile controllare l'avanzamento delle attivita' di creazione degli indici con la vista
pg_stat_progress_create_index.
Le procedure di VACUUM operano anche sugli indici.
La soglia per la cancellazione delle dead tuples negli indici e' piu' elevata
perche' l'elaborazione e' molto piu' pensante rispetto alla semplice pulizia della heap.
Limiti sugli indici
I limiti sugli indici B-tree in PostgreSQL sono molto, molto ampi.
Postgres consente di definire tabelle con fino a 1.600 colonne.
Postgres consente di definire indici con fino a 32 colonne.
Postgres non ha nessun limite sul numero di indici definiti per tabella
(anzi un indice sulle stesse colonne puo' essere creato piu' volte).
La ragione per cui non e' ragionevole costruire tutti gli indici multicolonna possibili non e' dovuta ad un limite di Postgres...
Il numero di indici possibili e' pari a tutte le disposizioni semplici delle colonne
(disposizione e' un termine del calcolo combinatorio).
La formula per calcolare il numero di disposizioni semplici e' la seguente:
$$ \sum_{k=1}^{n} \frac {n!} {(n-k)!} $$
Il risultato ottenuto con questa formula e' notevole:
se abbiamo una tabella con 10 colonne il numero di indici senza duplicati e' quasi 10.000.000
[NdA per la precisione sono 9.864.100 indici diversi].
Quindi il numero di indici che e' possibile creare e' enorme.
La maggioranza pero'
sarebbero comunque indici inutili perche la selettivita' dell'indice varierebbe di poco.
In generale non conviene mai superare il numero di tre o quattro colonne per un indice multicolonna
ed
il numero di indici definiti per tabella deve essere ragionevole e
dipendere dal tipo di query presenti sulla base dati e dalla quantita' di DML.
DML e gli indici
Fino ad ora abbiamo visto l'utilita' degli indici nelle ricerche.
In realta' e' anche importante conoscere il costo che comporta
mantenere gli indici in fase modifica dei dati con una istruzione dei DML.
Quando viene eseguita una INSERT Postgres modifica solo l'ultimo blocco della Heap inserendo
la riga nello spazio libero disponibile. Se non c'e' spazio a sufficienza viene semplicemente
allocato un nuovo blocco.
L'istruzione di INSERT e' quindi molto veloce per quanto riguarda l'inserimento del dato nella tabella.
Piu' complesso e' il trattamento degli indici.
Per ciascuno di questi infatti l'inserimento della chiave deve avvenire nei blocchi giusti
che vanno ricercati e quindi riscritti modificando l'ordine di ogni chiave contenuta.
Se non c'e' spazio a sufficienza va allocato un nuovo blocco e le chiavi debbono essere bilanciate
tra i blocchi.
La DELETE ovvero la cancellazione di una riga in PostgreSQL avviene in modo logico impostando il campo XMAX
nella riga da eliminare. E' un'operazione semplice per la heap della tabella:
ci pensera' il VACUUM
poi a ripulire.
Ma il compito piu' gravoso sara' poi correggere tutti gli indici!
In PostgreSQL le UPDATE vengono effettuate con una DELETE logica ed una INSERT fisica
quindi si sommano le operazioni appena descritte.
In realta' c'e' la possibilita' di eseguire una modifica di tipo HOT che e' molto piu'
efficiente ma che richiede che le colonne modificate non facciano parte di nessun indice.
Dovrebbe essere chiaro quindi che gli indici possono migliorare le prestazioni delle SELECT
ma peggiorano sicuramente le INSERT, DELETE ed UPDATE.
Da questo punto di vista meno indici ci sono meglio e' per tutte le attivita' di modifica
dei dati.
L'uso della base dati e' molto importante per definire la strategia di creazione degli indici.
Su un OLTP si creano solo gli indici necessari per le query piu' frequenti,
su un DSS si creano molti piu' indici cercando di migliorare le prestazioni di un piu' ampio numero di query,
per i BATCH spesso gli indici si creano solo al termine del processo di caricamento.
I piu' comuni errori sugli indici
Un errore molto comune e' quello di utilizzare espressioni o funzioni sulle colonne;
in questi casi si rendono inutilizzabili gli indici e quindi le ricerche
diventano molto piu' lente.
Si tratta di un errore da evitare assolutamente e che puo' essere
aggirato solo con la creazione di expression indici
[NdA in breve: utilizzate condizioni su naked columns].
Sempre molto comune e' l'errore di ritenere che un indice multi colonna possa operare
per tutte le colonne su cui e' definito.
Non e' cosi': l'ordine delle colonne nell'indice
e' molto importante: l'indice puo' essere utilizzato solo sulle condizioni presenti
partendo dalle colonne piu' a sinistra.
Meno grave come errore e' quello di utilizzare colonne poco selettive nella creazione dell'indice.
Indici su colonne poco selettive vanno evitati, se sono comunque utili (eg. covering index)
per alcune query allora le colonne meo selettive possono essere riportate come colonne finali nella definizione dell'indice.
L'ottimizzatore utilizza le statistiche per determinare il piano ottimale
per le query. E' importante che le statistiche siano sempre aggiornate.
Teoricamente l'autovacuum effettua il vacuum e l'analyze di tutti gli oggetti
quando necessario ma e' sempre opportuno un ANALYZE manuale dopo un caricamento
pesante o dopo una variazione delle strutture dati.
Troppi indici rallentano!
Se per le query, a meno di casi estremi, troppi indici non sono mai un problema,
per le istruzioni di DML gli indici debbono essere modificati ad ogni operazione.
Il rallentamento e' significativo per le attivita' di caricamento massivo
come i batch. In qualche casi si arriva a cancellare gli indici prima di un batch
ed a ricrearli al termine.
Un altro problema generato dai troppi indici e' quello di impedire
le HOT UPDATE: implementazioni piu' efficiente delle UPDATE che Postgres
puo' utilizzare solo se le colonne modificate non fanno parte di nessun indice.
Un indice B-Tree puo' essere utilizzato per le ricerche testuali con
gli operatori LIKE ed ILIKE ma solo se la prima parte della stringa
ricercata non contiene caratteri jolly.
Varie ed eventuali
In questa pagina abbiamo descritto gli indici
B-Tree che sono i piu' utilizzati perche' i piu' adatti in quasi tutte le condizioni di ricerca.
Ma e' importante riportare tutte le tipologie di indici disponibili in PostgreSQL:
- B-Tree: il tipo di indice piu' utilizzato su tutti i database relazionali.
Puo' essere utilizzato per i confronti
= < <= > >= BETWEEN IN IS NULL IS NOT NULL LIKE ILIKE
- Hash: richiede meno accessi rispetto ad un B-Tree ma puo' essere utilizzato solo con =
(eg. equijoin)
- GIN: e' un generalized inverted index utile quando si hanno piu' valori sulla stessa chiave come
nelle ricerche full-text o con colonne JSONB, ARRAY, ...
- BRIN: e' un block range index piu' leggero e facile da mantenere di un B-tree
quando si usano tabelle di enormi dimensioni che altrimenti avrebbero richiesto il partizionamento.
Lavorando per blocchi e' piu' adatto a colonne correlate con l'ordine fisico dei dati
(eg. creation_date)
- GiST: gli indici Generalized Search Tree
sono utili per i dati di tipo geometrico, le ricerche full-text e quando
i dati sono distribuiti in modo non bilanciato
- SP-GiST: gli indici Space-Partitioned Generalized Search Tree
sono utili per i dati di tipo geometrico, le ricerche full-text e quando
i dati sono distribuiti in modo non bilanciato
Molto particolari sono gli indici IVFFlat e HNSW disponibili con l'estensione
pgvector: sono indici approssimati utilizzati per i confronti
di similitudine tra vettori [NdA le ricerche di similarita' tra Embeddings
sono fondamentali per l'AI (Artificial Intelligence) ed il ML (Machine Learning)].
Altre pagine utili sulle performances sono
Ottimizzazione SQL in PostgreSQL
Tuning PostgreSQL.
Si tratta di documenti piu' completi sull'ottimizzazione in Postgres
ma che sono un poco piu' complessi di questa semplice pagina.
In tali documenti si trovano le query
per controllare la presenza degli indici richiesti dalle foreing key,
per verificare l'Hit Ratio,
per identificare gli indici non utilizzati,
...
L'estensione amcheck consente di controllare la correttezza della struttura degli indici.
Ma l'utilizzo va riservato ai soli casi di effettiva necessita'.
In questo breve e semplice documento non sono stati riportati i dettagli relativi alla struttura fisica
degli indici (eg. indici secondari, clustering, pagine fisiche, duplicati negli indici univoci).
Maggiori informazioni si trovano ovviamente sulla documentazione ufficiale:
limiti Postgres,
indici B-Tree,
indici multicolonna,
metodi di accesso agli indici,
struttura pagina fisica,
Heap-Only Tuples (HOT) Updates,
amcheck,
...