Controllare la corruzione degli indici su Postgres
La creazione degli indici in un database relazionale e' fondamentale
per ottenere buone prestazioni nelle query.
Nel caso in cui gli indici risultassero corrotti si possono presentare
problemi dal punto di vista prestazionale oppure, cosa molto piu' grave,
si possono corrompere o perdere i dati.
Questa pagina cerca di trattare i principali casi di problemi sugli indici in
PostgreSQL.
Dopo una prima
introduzione,
sono descritti gli indici invalidi
e gli indici corrotti,
l'estensione amcheck
ed uno script per il controllo degli indici corrotti.
Infine sono riportati alcuni interessanti Cold Case!
Ho fretta!
Come controllare la corruzione nascosta degli indici i PostgreSQL?
Dopo aver creato l'extension amcheck, eseguire questo script:
DO
$$DECLARE
ind oid;
msg text;
BEGIN
FOR ind IN
SELECT i.oid
FROM pg_class AS i
JOIN pg_am ON pg_am.oid = i.relam
WHERE pg_am.amname = 'btree'
AND i.relkind = 'i'
ORDER BY relpages desc
LOOP
BEGIN
PERFORM bt_index_check(ind);
EXCEPTION WHEN index_corrupted THEN
GET STACKED DIAGNOSTICS msg = MESSAGE_TEXT;
RAISE WARNING '-- % ; ', msg;
RAISE WARNING 'REINDEX INDEX CONCURRENTLY % ; ', ind::regclass;
END;
END LOOP;
END; $$;
Lo script genera un warning per ogni indice B-tree su cui viene trovata un'anomalia
generando un testo di output che e' facilmente convertibile in comandi SQL
(basta togliere la stringa WARNING) per eseguire le correzioni
necessarie.
Naturalmente e' possibile personalizzare lo script restringendo la ricerca ad uno specifico
schema e visualizzare l'avanzamento dei controlli.
Ma cos'e' un indice B-tree,
cos'e' la clausola CONCURRENTLY, perche' un indice si puo' corrompere,
perche' puo' verificarsi una corruzione nascosta,
cos'e' l'estensione amcheck, ...
Per saperlo, continuate a leggere!
Introduzione
Per rendere efficiente l'accesso ai dati vengono utilizzati gli indici.
Gli indici consentono di reperire i dati cercati nella tabella con un
numero minore di accessi ai blocchi di dati rispetto a scorrere l'intero
contenuto della tabella (Sequential Scan).
I tipi di indice piu' utilizzati sono i B-tree.
 I B-tree sono alberi bilanciati che cercano di mantenere limitato il numero di livelli
per raggiungere i dati finali che sono sulle foglie.
La ricerca parte sempre dal blocco di primo livello dell'indice,
si confronta il valore cercato con quelli presenti nel blocco
ed a seconda del confronto si procede ai livelli sucessivi.
I B-tree sono alberi bilanciati che cercano di mantenere limitato il numero di livelli
per raggiungere i dati finali che sono sulle foglie.
La ricerca parte sempre dal blocco di primo livello dell'indice,
si confronta il valore cercato con quelli presenti nel blocco
ed a seconda del confronto si procede ai livelli sucessivi.
E' possibile utilizzare indici definiti su una sola colonna o su piu' colonne.
Con un indice multicolonna e' come se il contenuto delle diverse colonne
fosse concatenato per ottenere la chiave finale utilizzata dall'indice.
L'ordine delle colonne utilizzato nella creazione di un indice molticolonna e' molto importante.
Un albero B-tree e' bilanciato quindi il numero di livelli e'
mantenuto limitato anche se a volte e' necessario ricostruirlo
per avere le migliori prestazioni.
Qual'e' il vantaggio nell'uso dell'indice? Per la ricerca senza indice e' necessario accedere
a tutti i blocchi della tabella che crescono linearmente con il numero
di record. Quindi la complessita' temporale della ricerca e' O(N).
Per la ricerca con indice e' necessario accedere al numero di livelli
dell'indice piu' un accesso al blocco della tabella;
ma il numero di livelli dell'indice cresce con il logaritmo
(con base il numero di chiavi per blocco).
In questo caso la teoria dice che la complessita' dell'algoritmo e' O(log N):
in pratica i tempi crescono in modo logaritmico, con un logaritmo con base elevata
che dipende dal numero di chiavi che e' possibile memorizzare in un blocco.
Quando utilizza un indice B-tree Postgres?
La ricerca per uguaglianza e' solo una delle possibilita', anche se probabilmente la piu' importante di tutte.
Un indice B-tree puo' essere utilizzato per i seguenti operatori:
= < <= > >= BETWEEN IN() IS NULL IS NOT NULL LIKE ILIKE
Inoltre un indice B-tree puo' essere utilizzato per ordinare i dati, per raggruppare i dati,
per ricercare il min() o il max(), per eseguire il controllo dei constraint, ...
e, non da ultimo, per velocizzare i join (sia con i nested loop che con i merge join).
Creazione e gestione indici
Il comando SQL standard per la creazione degli indici e' lo statement CREATE INDEX.
A differenza di altri database Postgres consente operazioni di DDL
all'interno di una transazione.
Questo vale anche per la creazione degli indici.
La creazione di un indice richiede un lock sulla tabella sottostante.
Il lock consente le letture ma non le scritture.
Nella creazione di un indice e' possibile utilizzare la clausola CONCURRENTLY che consente
anche le attivita' di scrittura sulla tabella [NdA disponibile dalla versione 8.2].
Con l'utilizzo della clausola CONCURRENTLY la creazione di un indice e' piu' lenta
e non puo' essere utilizzata all'interno di una transazione.
L'avanzamento della creazione di un indice puo' essere controllato con
[NdA dalla versione PG12]:
SELECT * FROM pg_stat_progress_create_index;
Il VACUUM agisce anche sugli indici.
La soglia per la cancellazione delle dead tuples negli indici e' piu' elevata
perche' l'elaborazione e' molto piu' pesante rispetto alla pulizia della heap
che e' molto piu' semplice.
Il comando REINDEX consente di ricostruire gli indici
per ribilanciarli quando sono diventati frammentati a causa delle frequenti modifiche alle chiavi.
Anche il comando REINDEX puo' essere lanciato con la clausola CONCURRENTLY
[NdA dalla versione PG12].
La modalita' CONCURRENTLY non utilizza lock che bloccano le scritture ma e' piu' lenta
in modo significativo.
Indici invalidi
Vi sono dei casi in cui la creazione o la reindicizzazione di un indice puo'
andare in errore, in particolare con la modalita' CONCURRENTLY perche' e' asincrona
ed utilizza lock meno aggressivi.
In questi casi l'indice viene segnato come INVALID e non puo' essere utilizzato
dall'ottimizzatore di PostgreSQL.
La verifica degli eventuali indici invalidi si effettua con la query:
SELECT n.nspname as schema, c1.relname as invalid_index, c2.relname as table
FROM pg_class c1, pg_index i, pg_namespace n, pg_class c2
WHERE c1.relnamespace = n.oid
AND i.indexrelid = c1.oid
AND c2.oid = i.indrelid
AND i.indisvalid = false;
Gli indici invalidi non generano errori o risultati sbagliati,
il problema e' solo per le performance perche' non possono essere utilizzati.
Se vi sono indici invalidi debbono essere cancellati e ricreati
oppure reindicizzati con una REINDEX.
Indici corrotti
Un caso molto piu' grave e' quello di un indice la cui struttura e' errata
ma PostgreSQL non e' a conoscenza. In questo caso l'indice risulta valido
ma in realta' e' un indice corrotto.
Non sono molti i casi in cui puo' avvenire, ma si tratta sempre di casi gravi:
errori sui dispositivi fisici, bug del software del database, ...
Tipicamente il sintomo di una corruzione e' un errore inatteso su uno statement SQL.
Data la gravita' questi errori sono sempre riportati nel log di PostgreSQL;
ad esempio:
ERROR: high key invariant violated for index "xxx"
ERROR: item order invariant violated for index "yyy"
I DETAIL riportati nel log consentono di risalire alle righe (ctid) dell'heap
su cui si verifica l'errore.
E' anche possibile che un indice corrotto non venga rilevato, questo puo' portare
anche alla corruzione dei dati (eg. una ricerca per indice non trova la chiave cercata
oppure viene inserita due volte la stessa chiave univoca).
Per questa ragione e' importante eseguire una verifica sugli indici quando vi sono
i primi sintomi di una corruzione.
Ma come fare una verifica sugli indici? Lo vediamo nel prossimo capitolo!
amcheck
La core extension amcheck consente di controllare la correttezza della struttura degli indici,
rilevando eventuali errori.
L'utilizzo va riservato ai soli casi di effettiva necessita' perche' e' particolarmente pesante.
Se si ha il sospetto che vi siano indici corrotti il controllo di dettaglio
si esegue con la funzione bt_index_check(idx.oid) contenuta nell'extension
amcheck.
Poiche' si tratta di una core extension amcheck e' sempre presente con le installazioni
di PostgreSQL e per utilizzarla e' sufficiente crearla con:
CREATE EXTENSION amcheck;
L'estensione fornisce una serie di funzioni che sono utilizzabili per
controllare la correttezza fisica degli indici B-tree.
La funzione principale e' bt_index_check che controlla
la correttezza dell'indice e puo' essere richiamata con ulteriori parametri
per controllare l'univocita' delle chiavi e
che ogni tupla presente nella heap sia stata indicizzata.
Le funzioni bt_index_parent_check e verify_heapam
forniscono ulteriori controlli.
Ogni errore rilevato dalle funzioni e' grave, puo' portare
alla corruzione dei dati e va quindi risolto.
In caso di anomalia su un indice la funzione bt_index_check solleva un eccezione,
quindi un eventuale query per controllare un elenco di indici
si interrompe al primo errore.
Per controllare tutti gli indici e' utile il seguente script
in PL/pgSQL:
DO
$$DECLARE
ind oid;
sche text;
name text;
msg text;
BEGIN
FOR ind, sche, name IN
SELECT i.oid, i.relnamespace::regnamespace::text, i.relname
FROM pg_class AS i
JOIN pg_am am ON am.oid = i.relam
JOIN pg_index ii ON ii.indexrelid = i.oid
WHERE am.amname = 'btree'
AND i.relkind = 'i'
AND i.relpersistence != 't'
AND ii.indisready
AND ii.indisvalid
-- AND i.relnamespace::regnamespace::text IN ('myDB')
ORDER BY relpages -- desc
LOOP
BEGIN
RAISE NOTICE 'Checking %.% %', sche, name, ind;
PERFORM bt_index_check(ind);
EXCEPTION WHEN index_corrupted THEN
GET STACKED DIAGNOSTICS msg = MESSAGE_TEXT;
RAISE WARNING '-- % ; ', msg;
RAISE WARNING 'REINDEX INDEX CONCURRENTLY % ; ', ind::regclass;
END;
END LOOP;
END;
$$;
Lo script controlla tutti gli indici B-tree, escludendo gli indici invalidi, quelli in fase di creazione ed i temporanei
partendo da quelli di minori dimensioni.
Poiche' il controllo viene effettuato tupla per tupla e' particolarmente lento e pesante da punto di vista di I/O.
Naturalmente lo script e' personalizzabile e puo' essere eseguito su un solo schema o sulle tabelle di interesse.
Per indici diversi dai B-tree non vi sono funzioni di controllo
e quindi, in caso d'errore, l'unica soluzione e' eseguire una REINDEX.
Cold case
Vi sono alcuni casi noti in PostgreSQL che possono portare alla corruzione degli indici.
In quest'ultima parte vediamo di riportare i due esempi piu' famigerati.
PG 14.3
La versione PostgreSQL 14.3 (2022-05) ha introdotto un'ottimizzazione
nella creazione degli indici con la clausola CONCURRENTLY...
purtroppo l'ottimizzazione conteneva un bug ed era possibile che
le righe inserite durante la creazione dell'indice non venissero considerate.
La versione 14.4 e' stata pubblicata poco dopo (2022-06), prima del normale aggiornamento trimestrale,
per correggere il problema.
Eventuali indici creati con la versione 14.3 e con la clausola CONCURRENTLY
vanno ricreati senza la clausola o con una versione sucessiva.
glibc
La libreria glibc e' una core library importantissima per i sistemi GNU, tra cui tutti i Linux,
perche' contiene funzioni C fondamentali come: printf, open, read, write, malloc, ...
Tra le funzioni presenti vi sono anche quelle di ordinamento delle stringhe
che tengono conto dei caratteri nazionalizzati ovvero le collation.
In generale la libreria viene aggiornata ogni sei mesi
e, tipicamente molti mesi dopo l'aggiornamento viene raccolto dalle distribuzioni linux.
L'aggiornamento introdotto con la versione 2.28 ha introdotto un cambiamento significativo:
glibc-2.28 (2018-08)
Major new features:
* The localization data for ISO 14651 is updated to match the 2016
Edition 4 release of the standard, this matches data provided by Unicode 9.0.0.
This update introduces significant improvements to the collation of Unicode characters.
...
PostgreSQL utilizza le librerie di sistema per definire l'ordinamento delle stringhe
e l'ordinamento ottenuto con la glibc-2.28 e con una versione precedente sono differenti
in molti casi [NdA non solo nella gestione delle lettere accentate o dei caratteri nazionalizzati
ma anche in presenza di blank o di segni di interpunzione all'interno di strighe].
Un ordinamento differente comporta errori negli algortimi di ricerca
ma anche e sopratutto sulla struttura fisica dell'indice.
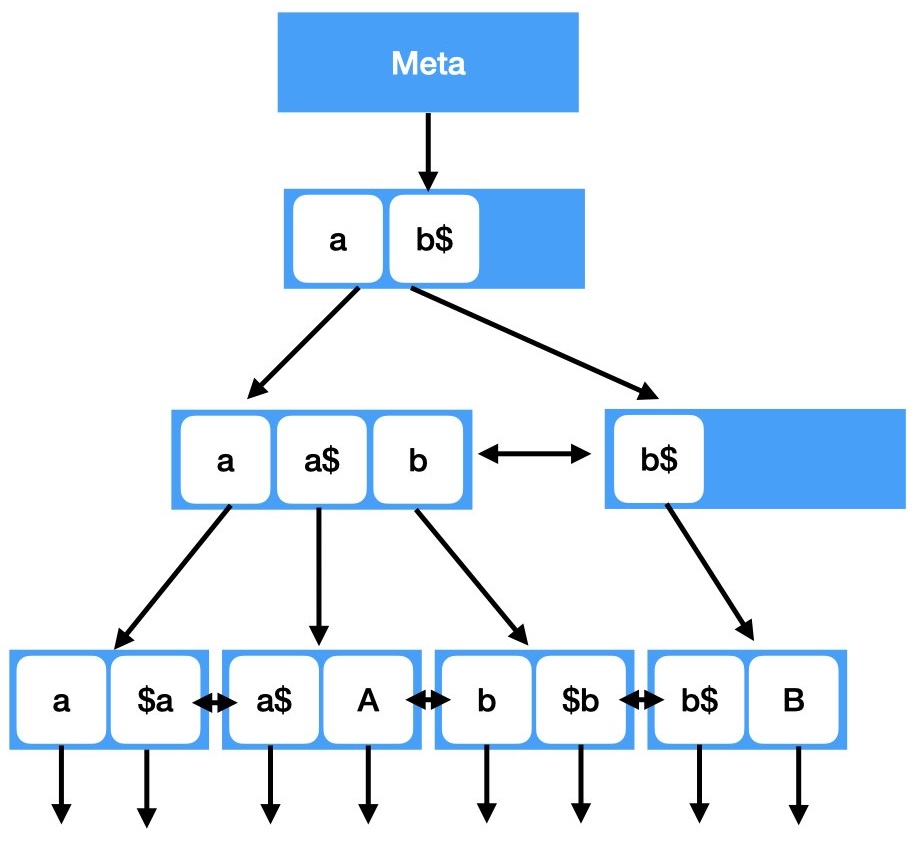
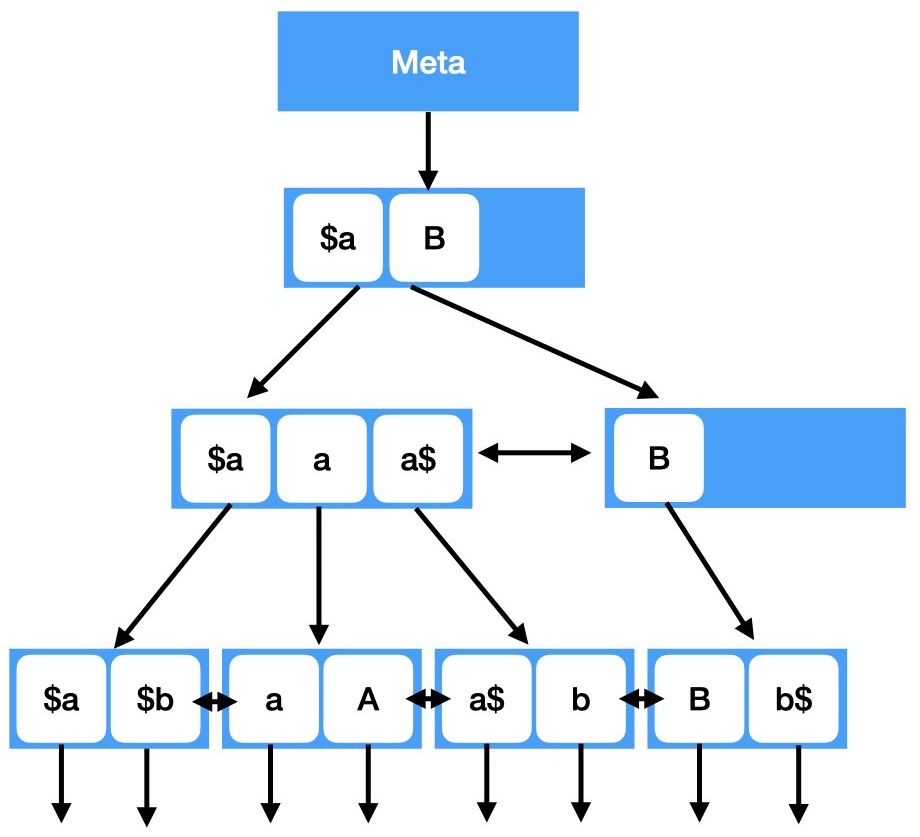
Le due figure ai lati riportano un esempio, ovviamente semplificato,
delle differenze presenti tra due indici creati sugli stessi dati ma con versioni diverse di glibc.
Quindi un indice creato con una versione di glibc precedente non e' compatibile se utilizzato
su un sistema che utilizza una glibc successiva alla 2.28.
L'aggiornamento della libreria glibc puo' portare alla corruzione degli indici B-tree
e la migrazione tra sistemi con glibc differenti non e' supportato.
Per controllare quali indici possano essere coinvolti e' possibile utilizzare questa query
(in pratica tutti gli indici con almeno una colonna con datatype: text, varchar, char con locale di default):
SELECT indrelid::regclass::text, indexrelid::regclass::text, collname, pg_get_indexdef(indexrelid)
FROM (SELECT indexrelid, indrelid, indcollation[i] coll FROM pg_index, generate_subscripts(indcollation, 1) g(i)) s
JOIN pg_collation c ON coll=c.oid
WHERE collprovider IN ('d', 'c') AND collname NOT IN ('C', 'POSIX');
Il problema era gia' noto per altri aggiornamenti della libreria glibc, ben documentato nella
documentazione ufficiale
ed e' stato segnalato piu' volte
(eg. una delle
prime pagine sull'argomento),
ma nonostante questo resta una problematica ricorrente.
Generalmente una distribuzione linux non modifica la versione della glibc con i minor update,
tuttavia in caso di major upgrade del sistema operativo la libreria viene aggiornata.
Per l'adozione della glibc 2.28
sono critici gli upgrade alle versioni riportate in tabella (o sucessive):
E' importante sottolineare che l'incompatibilita' risultante tra versioni di glibc
e' fisica e puo' provocare la corruzione degli indici in diversi casi:
major upgrade del sistema operativo,
streaming replication tra nodi diversi,
restore fisico (eg. pg_basebackup, cp, rsync) su un nuovo sistema, ...
Non presentano invece problemi le migrazioni logiche
utilizzando pg_dump o la logical replication.
Eventuali indici corrotti dall'introduzione di un differente ordinamento vanno ricreati
prima di riaprire il database all'uso.
Varie ed eventuali
Maggiori dettagli sugli indici si trovano in questa pagina
dedicata agli Indici B-tree in PostgreSQL.
Un'estensione utile per controllare il contenuto dei blocchi di heap e degli indici
e' pageinspect.
Ovviamente la documentazione ufficiale e' la fonte piu' completa di informazioni:
indici B-Tree,
struttura pagina fisica,
amcheck,
pageinspect,
...