pgBadger
 PostgreSQL
e' un potente DBMS relazionale Open Source noto per
la robustezza e la ricchezza di funzionalita'.
PostgreSQL
e' un potente DBMS relazionale Open Source noto per
la robustezza e la ricchezza di funzionalita'.
In questa paginetta presentiamo
pgBadger
che e' un tool Open Source esterno per
l'analisi dei log di PostgreSQL.
pgBadger e' al tempo stesso facile da configurare e fornisce un'analisi molto completa
e semplice da analizzare dei log di Postgres in formato HTML.
Un documento introduttivo su PostgreSQL
e' Introduzione a PostgreSQL,
puo' anche essere utile leggere il
documento che presenta
Logging ed auditing su PostgreSQL.
Gli esempi contenuti in questa pagina sono stati realizzati con PostgreSQL 14.6, pgBadger 12.0
su MacOS ma sono validi, mutatis mutandis, praticamente per tutte le altre versioni e sistemi operativi.
PostgreSQL
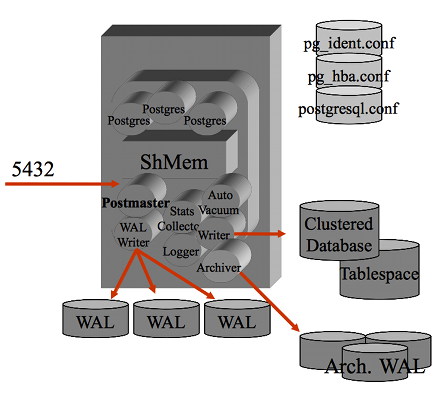 Un breve accenno all'architettura di PostgreSQL puo' essere utile...
Un breve accenno all'architettura di PostgreSQL puo' essere utile...
Il processo
postmaster e' il processo principale che si occupa della gestione delle
connessioni
ed e' il "padre" di tutti i processi, sia di sistema (eg. wal writer)
sia quelli relativi alle connessione utente.
Tutti i processi girano come utente postgres ed eseguono un attach
al segmento di shared memory su cui vengono mantenuti buffer e lock.
Il processo postmaster e' in LISTEN sulla porta socket 5432 (e' il default ma puo' essere cambiata)
e per ogni connessione attiva un processo utente.
I processi utente sono facilmente individuabili (eg. con il comando ps -efa) poiche'
nella command line riportano il database utilizzato, l'IP(porta) del client e lo stato.
Gli altri processi sono quelli di background di postgres.
La configurazione dei parametri di PostgreSQL si effettua modificando il file postgresql.conf
mentre la configurazione degli accessi si effettua nel file pg_hba.conf e quindi a livello
di database con i comandi SQL di GRANT.
Eventuali errori vengono riportati nei file di log ed e' possibile impostare un logging/auditing
molto completo agendo sui molti parametri di configurazione specifici.
Il formato e la collocazione dei file di log dipendende dalla configurazione
ma tipicamente si trovano nella directory $PGDATA/log.
pgBadger
pgBadger effettua l'analisi dei file di log di Postgres ottenendo un file in formato .HTML
con tutte le informazioni utili.
Dal punto di vista tecnico pgBadger e' un programma Perl,
che puo' operare anche in parallelo ed in modalita' incrementale
nell'analisi dei file di log.
pgBadger riconosce in automatico il formato dei file di log
ma, se non vengono riconosciuti, e' possibile indicare la tipologia
(eg. stderr, csv, xml,
jsonlog, pgbouncer, rds) come parametro.
pgBadger analizza il contenuto dei file di log di PostgreSQL ricercando tutte le informazioni presenti.
Nei log di PostgreSQL sono sempre presenti gli errori, le segnalazioni di riavvio, ...
ma anche un'ampia serie di informazioni relativi alle prestazioni,
se queste sono state abilitate nei
parametri di configurazione di PostgreSQL.
Il file HTML ottenuto come risultato e' costituito da diverse pagine con tabelle e grafici.
Anche se molto articolato e dinamico il file e' unico perche' contiene al suo interno tutte
le parti necessarie (eg. jQuery, Font Awesome).
Il menu principale sulla pagina consente di analizzare velocemente i risultati ottenuti:

pgBadger non opera online ma solo sui log, quindi non e' uno strumento di monitoraggio
delle attivita' in corso, ma e' molto utile per analizzare in modo automatico
i contenuti dei log che spesso possono essere di grandi dimensioni e lunghi da controllare
per un DBA.
Ma prima di usare pgBadger e' necessario installarlo!
Installazione
L'installazione su MacOS con HomeBrew e' banale
[NdA ma e' semplice anche sugli altri OS]:
brew install pgbadger
🍺
Gia' fatto!
A questo punto per controllare se funziona basta lanciare pgbadger --help
che riporta un'ampia descrizione dei parametri disponibili:
% pgbadger --help
Usage: pgbadger [options] logfile [...]
PostgreSQL log analyzer with fully detailed reports and graphs.
Arguments:
logfile can be a single log file, a list of files, or a shell command
returning a list of files. If you want to pass log content from stdin
use - as filename. Note that input from stdin will not work with csvlog.
Options:
-a | --average minutes : number of minutes to build the average graphs of
queries and connections. Default 5 minutes.
-A | --histo-average min: number of minutes to build the histogram graphs
of queries. Default 60 minutes.
-b | --begin datetime : start date/time for the data to be parsed in log
(either a timestamp or a time)
-c | --dbclient host : only report on entries for the given client host.
-C | --nocomment : remove comments like /* ... */ from queries.
-d | --dbname database : only report on entries for the given database.
-D | --dns-resolv : client ip addresses are replaced by their DNS name.
Be warned that this can really slow down pgBadger.
-e | --end datetime : end date/time for the data to be parsed in log
(either a timestamp or a time)
-E | --explode : explode the main report by generating one report
per database. Global information not related to a
database is added to the postgres database report.
-f | --format logtype : possible values: syslog, syslog2, stderr, jsonlog,
csv, pgbouncer, logplex, rds and redshift. Use this
option when pgBadger is not able to detect the log
format.
-G | --nograph : disable graphs on HTML output. Enabled by default.
-h | --help : show this message and exit.
-H | --html-outdir path: path to directory where HTML report must be written
in incremental mode, binary files stay on directory
defined with -O, --outdir option.
-i | --ident name : programname used as syslog ident. Default: postgres
-I | --incremental : use incremental mode, reports will be generated by
days in a separate directory, --outdir must be set.
-j | --jobs number : number of jobs to run at same time for a single log
file. Run as single by default or when working with
csvlog format.
-J | --Jobs number : number of log files to parse in parallel. Process
one file at a time by default.
-l | --last-parsed file: allow incremental log parsing by registering the
last datetime and line parsed. Useful if you want
to watch errors since last run or if you want one
report per day with a log rotated each week.
-L | --logfile-list file:file containing a list of log files to parse.
-m | --maxlength size : maximum length of a query, it will be restricted to
the given size. Default truncate size is 100000.
-M | --no-multiline : do not collect multiline statements to avoid garbage
especially on errors that generate a huge report.
-N | --appname name : only report on entries for given application name
-o | --outfile filename: define the filename for the output. Default depends
on the output format: out.html, out.txt, out.bin,
or out.json. This option can be used multiple times
to output several formats. To use json output, the
Perl module JSON::XS must be installed, to dump
output to stdout, use - as filename.
-O | --outdir path : directory where out files must be saved.
-p | --prefix string : the value of your custom log_line_prefix as
defined in your postgresql.conf. Only use it if you
aren't using one of the standard prefixes specified
in the pgBadger documentation, such as if your
prefix includes additional variables like client ip
or application name. See examples below.
-P | --no-prettify : disable SQL queries prettify formatter.
-q | --quiet : don't print anything to stdout, not even a progress
bar.
-Q | --query-numbering : add numbering of queries to the output when using
options --dump-all-queries or --normalized-only.
-r | --remote-host ip : set the host where to execute the cat command on
remote log file to parse the file locally.
-R | --retention N : number of weeks to keep in incremental mode. Defaults
to 0, disabled. Used to set the number of weeks to
keep in output directory. Older weeks and days
directories are automatically removed.
-s | --sample number : number of query samples to store. Default: 3.
-S | --select-only : only report SELECT queries.
-t | --top number : number of queries to store/display. Default: 20.
-T | --title string : change title of the HTML page report.
-u | --dbuser username : only report on entries for the given user.
-U | --exclude-user username : exclude entries for the specified user from
report. Can be used multiple time.
-v | --verbose : enable verbose or debug mode. Disabled by default.
-V | --version : show pgBadger version and exit.
-w | --watch-mode : only report errors just like logwatch could do.
-W | --wide-char : encode html output of queries into UTF8 to avoid
Perl message "Wide character in print".
-x | --extension : output format. Values: text, html, bin or json.
Default: html
-X | --extra-files : in incremental mode allow pgBadger to write CSS and
JS files in the output directory as separate files.
-z | --zcat exec_path : set the full path to the zcat program. Use it if
zcat, bzcat or unzip is not in your path.
-Z | --timezone +/-XX : Set the number of hours from GMT of the timezone.
Use this to adjust date/time in JavaScript graphs.
The value can be an integer, ex.: 2, or a float,
ex.: 2.5.
--pie-limit num : pie data lower than num% will show a sum instead.
--exclude-query regex : any query matching the given regex will be excluded
from the report. For example: "^(VACUUM|COMMIT)"
You can use this option multiple times.
--exclude-file filename: path of the file that contains each regex to use
to exclude queries from the report. One regex per
line.
--include-query regex : any query that does not match the given regex will
be excluded from the report. You can use this
option multiple times. For example: "(tbl1|tbl2)".
--include-file filename: path of the file that contains each regex to the
queries to include from the report. One regex per
line.
--disable-error : do not generate error report.
--disable-hourly : do not generate hourly report.
--disable-type : do not generate report of queries by type, database
or user.
--disable-query : do not generate query reports (slowest, most
frequent, queries by users, by database, ...).
--disable-session : do not generate session report.
--disable-connection : do not generate connection report.
--disable-lock : do not generate lock report.
--disable-temporary : do not generate temporary report.
--disable-checkpoint : do not generate checkpoint/restartpoint report.
--disable-autovacuum : do not generate autovacuum report.
--charset : used to set the HTML charset to be used.
Default: utf-8.
--csv-separator : used to set the CSV field separator, default: ,
--exclude-time regex : any timestamp matching the given regex will be
excluded from the report. Example: "2013-04-12 .*"
You can use this option multiple times.
--include-time regex : only timestamps matching the given regex will be
included in the report. Example: "2013-04-12 .*"
You can use this option multiple times.
--exclude-db name : exclude entries for the specified database from
report. Example: "pg_dump". Can be used multiple
times.
--exclude-appname name : exclude entries for the specified application name
from report. Example: "pg_dump". Can be used
multiple times.
--exclude-line regex : exclude any log entry that will match the given
regex. Can be used multiple times.
--exclude-client name : exclude log entries for the specified client ip.
Can be used multiple times.
--anonymize : obscure all literals in queries, useful to hide
confidential data.
--noreport : no reports will be created in incremental mode.
--log-duration : force pgBadger to associate log entries generated
by both log_duration = on and log_statement = 'all'
--enable-checksum : used to add an md5 sum under each query report.
--journalctl command : command to use to replace PostgreSQL logfile by
a call to journalctl. Basically it might be:
journalctl -u postgresql-9.5
--pid-dir path : set the path where the pid file must be stored.
Default /tmp
--pid-file file : set the name of the pid file to manage concurrent
execution of pgBadger. Default: pgbadger.pid
--rebuild : used to rebuild all html reports in incremental
output directories where there's binary data files.
--pgbouncer-only : only show PgBouncer-related menus in the header.
--start-monday : in incremental mode, calendar weeks start on
Sunday. Use this option to start on a Monday.
--iso-week-number : in incremental mode, calendar weeks start on
Monday and respect the ISO 8601 week number, range
01 to 53, where week 1 is the first week that has
at least 4 days in the new year.
--normalized-only : only dump all normalized queries to out.txt
--log-timezone +/-XX : Set the number of hours from GMT of the timezone
that must be used to adjust date/time read from
log file before beeing parsed. Using this option
makes log search with a date/time more difficult.
The value can be an integer, ex.: 2, or a float,
ex.: 2.5.
--prettify-json : use it if you want json output to be prettified.
--month-report YYYY-MM : create a cumulative HTML report over the specified
month. Requires incremental output directories and
the presence of all necessary binary data files
--day-report YYYY-MM-DD: create an HTML report over the specified day.
Requires incremental output directories and the
presence of all necessary binary data files
--noexplain : do not process lines generated by auto_explain.
--command CMD : command to execute to retrieve log entries on
stdin. pgBadger will open a pipe to the command
and parse log entries generated by the command.
--no-week : inform pgbadger to not build weekly reports in
incremental mode. Useful if it takes too much time.
--explain-url URL : use it to override the url of the graphical explain
tool. Default: http://explain.depesz.com/
--tempdir DIR : set directory where temporary files will be written
Default: File::Spec->tmpdir() || '/tmp'
--no-process-info : disable changing process title to help identify
pgbadger process, some system do not support it.
--dump-all-queries : dump all queries found in the log file replacing
bind parameters included in the queries at their
respective placeholders positions.
--keep-comments : do not remove comments from normalized queries. It
can be useful if you want to distinguish between
same normalized queries.
--no-progressbar : disable progressbar.
pgBadger is able to parse a remote log file using a passwordless ssh connection.
Use -r or --remote-host to set the host IP address or hostname. There are also
some additional options to fully control the ssh connection.
--ssh-program ssh path to the ssh program to use. Default: ssh.
--ssh-port port ssh port to use for the connection. Default: 22.
--ssh-user username connection login name. Defaults to running user.
--ssh-identity file path to the identity file to use.
--ssh-timeout second timeout to ssh connection failure. Default: 10 sec.
--ssh-option options list of -o options to use for the ssh connection.
Options always used:
-o ConnectTimeout=$ssh_timeout
-o PreferredAuthentications=hostbased,publickey
Log file to parse can also be specified using an URI, supported protocols are
http[s] and [s]ftp. The curl command will be used to download the file, and the
file will be parsed during download. The ssh protocol is also supported and will
use the ssh command like with the remote host use. See examples bellow.
Return codes:
0: on success
1: die on error
2: if it has been interrupted using ctr+c for example
3: the pid file already exists or can not be created
4: no log file was given at command line
Examples:
pgbadger /var/log/postgresql.log
pgbadger /var/log/postgres.log.2.gz /var/log/postgres.log.1.gz /var/log/postgres.log
pgbadger /var/log/postgresql/postgresql-2012-05-*
pgbadger --exclude-query="^(COPY|COMMIT)" /var/log/postgresql.log
pgbadger -b "2012-06-25 10:56:11" -e "2012-06-25 10:59:11" /var/log/postgresql.log
cat /var/log/postgres.log | pgbadger -
# Log line prefix with stderr log output
pgbadger --prefix '%t [%p]: user=%u,db=%d,client=%h' /pglog/postgresql-2012-08-21*
pgbadger --prefix '%m %u@%d %p %r %a : ' /pglog/postgresql.log
# Log line prefix with syslog log output
pgbadger --prefix 'user=%u,db=%d,client=%h,appname=%a' /pglog/postgresql-2012-08-21*
# Use my 8 CPUs to parse my 10GB file faster, much faster
pgbadger -j 8 /pglog/postgresql-10.1-main.log
Use URI notation for remote log file:
pgbadger http://172.12.110.1//var/log/postgresql/postgresql-10.1-main.log
pgbadger ftp://username@172.12.110.14/postgresql-10.1-main.log
pgbadger ssh://username@172.12.110.14:2222//var/log/postgresql/postgresql-10.1-main.log*
You can use together a local PostgreSQL log and a remote pgbouncer log file to parse:
pgbadger /var/log/postgresql/postgresql-10.1-main.log ssh://username@172.12.110.14/pgbouncer.log
Reporting errors every week by cron job:
30 23 * * 1 /usr/bin/pgbadger -q -w /var/log/postgresql.log -o /var/reports/pg_errors.html
Generate report every week using incremental behavior:
0 4 * * 1 /usr/bin/pgbadger -q `find /var/log/ -mtime -7 -name "postgresql.log*"` -o /var/reports/pg_errors-`date +\%F`.html -l /var/reports/pgbadger_incremental_file.dat
This supposes that your log file and HTML report are also rotated every week.
Or better, use the auto-generated incremental reports:
0 4 * * * /usr/bin/pgbadger -I -q /var/log/postgresql/postgresql.log.1 -O /var/www/pg_reports/
will generate a report per day and per week.
In incremental mode, you can also specify the number of weeks to keep in the
reports:
/usr/bin/pgbadger --retention 2 -I -q /var/log/postgresql/postgresql.log.1 -O /var/www/pg_reports/
If you have a pg_dump at 23:00 and 13:00 each day during half an hour, you can
use pgBadger as follow to exclude these periods from the report:
pgbadger --exclude-time "2013-09-.* (23|13):.*" postgresql.log
This will help avoid having COPY statements, as generated by pg_dump, on top of
the list of slowest queries. You can also use --exclude-appname "pg_dump" to
solve this problem in a simpler way.
You can also parse journalctl output just as if it was a log file:
pgbadger --journalctl 'journalctl -u postgresql-9.5'
or worst, call it from a remote host:
pgbadger -r 192.168.1.159 --journalctl 'journalctl -u postgresql-9.5'
you don't need to specify any log file at command line, but if you have other
PostgreSQL log files to parse, you can add them as usual.
To rebuild all incremental html reports after, proceed as follow:
rm /path/to/reports/*.js
rm /path/to/reports/*.css
pgbadger -X -I -O /path/to/reports/ --rebuild
it will also update all resource files (JS and CSS). Use -E or --explode
if the reports were built using this option.
pgBadger also supports Heroku PostgreSQL logs using logplex format:
heroku logs -p postgres | pgbadger -f logplex -o heroku.html -
this will stream Heroku PostgreSQL log to pgbadger through stdin.
pgBadger can auto detect RDS and cloudwatch PostgreSQL logs using
rds format:
pgbadger -f rds -o rds_out.html rds.log
Each CloudSQL Postgresql log is a fairly normal PostgreSQL log, but encapsulated
in JSON format. It is autodetected by pgBadger but in case you need to force
the log format use `jsonlog`:
pgbadger -f jsonlog -o cloudsql_out.html cloudsql.log
This is the same as with the jsonlog extension, the json format is different
but pgBadger can parse both formats.
To create a cumulative report over a month use command:
pgbadger --month-report 2919-05 /path/to/incremental/reports/
this will add a link to the month name into the calendar view in
incremental reports to look at report for month 2019 May.
Use -E or --explode if the reports were built using this option.
Per vedere un primo risultato basta spostarsi nella directory $PGDATA/log,
eseguire pgbadger * e nel file out.html avremo il risultato dell'analisi:
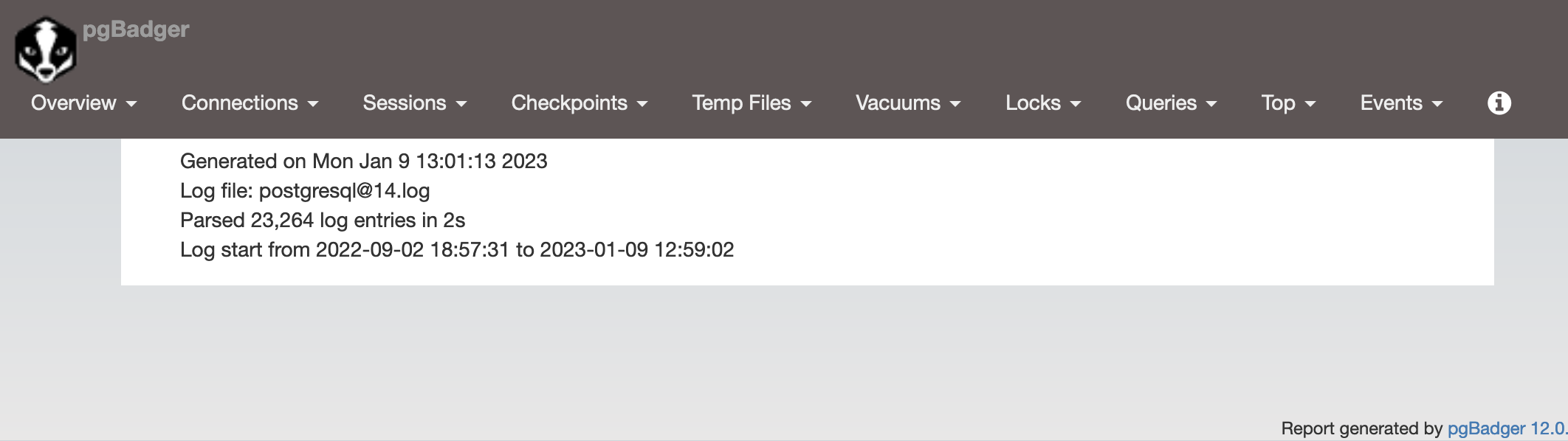
Ma per ottenere qualcosa di significativo e' necessario un minimo di configurazione!
Configurazione
Prima di utilizzare pgBadger il logging di PostgreSQL deve essere configurato
in modo opportuno.
Il file da modificare e' postgresql.conf (in /usr/local/var/postgres se si usa Homebrew's PostgreSQL)
ed e' richiesto un riavvio dopo aver impostato i seguenti parametri:
log_destination = 'stderr'
log_line_prefix = '%t [%p]: [%l-1] user=%u,db=%d,app=%a,client=%h '
log_statement = 'none'
log_duration = off
log_min_duration_statement = 0
log_checkpoints = on
log_connections = on
log_disconnections = on
log_lock_waits = on
log_temp_files = 0
log_autovacuum_min_duration = 0
log_error_verbosity = default
lc_messages = 'C'
Quelli indicati sopra sono i parametri consigliati da pgBadger per ottenere
il massimo delle informazioni dall'analisi dei log.
Un nota importante: con l'impostazione log_min_duration_statement = 0
vengono riportati nel log tutti gli statement eseguiti.
Questo puo' essere molto pesante per database sia in termini di spazio occupato
che dal punto di vista delle prestazioni,
quindi tale impostazione va eseguita solo quando necessario.
Per un database di produzione l'impostazione consigliata
di log_min_duration_statement e' -1 (disabilitato)
oppure 5000 (riporta nel log gli statement di durata superiore ai 5.000 ms).
Naturalmente il report ottenuto con pgBadger riportera' solo quanto presente
nei file di log...
Utilizzo
Dal punto di vista dell'utilizzo l'esecuzione e' molto semplice.
Passando come parametro uno o piu' file di log viene prodotto un
file .HTML
come quello di questo esempio:

I primi parametri da considerare sono quelli relativi al tempo.
pgBadger ha diversi parametri per indicare il periodo di tempo da analizzare:
-b | --begin datetime
-e | --end datetime
--exclude-time regex
--include-time regex
--month-report YYYY-MM
--day-report YYYY-MM-DD
Altri parametri consentono di escludere file di log e/o query specifiche:
--exclude-query regex
--include-query regex
--exclude-file filename
--include-file filename
Il report di pgBadger e' costituito da diverse sezioni che e' possibile
escludere con i parametri:
--disable-error
--disable-hourly
--disable-type
--disable-query
--disable-session
--disable-connection
--disable-lock
--disable-temporary
--disable-checkpoint
--disable-autovacuum
Da ultimo, ma non come importanza perche' e' utilizzato molto spesso,
il parametro -w ovvero --watch-mode che analizza i log solo da punto di vista
degli errori come se fosse un
programma di logwatch:

Con la configurazione di default di Postgres nel log non sono riportati tutti gli statement
SQL eseguiti, anche perche' sarebbe molto pesante; l'utilizzo di pgBadger in
modalita' watch-mode e' pero' utile anche in questi casi.
Varie ed eventuali
pgBagdger e' in grado di trattare anche i log di PgBouncer
che e' un noto Connection Pooler per PostgreSQL.
Gilles Darold, l'autore di pgBadger, e' noto anche per l'ottimo
ora2pg
che e' un tool per la migrazione da Oracle
a PostgreSQL.