Questo documento presenta diversi esempi di script realizzati con Pig Hadoop.
Apache Hadoop e' un software Open Source per il distributed computing
che consente la gestione quantita' enorme di dati su sistemi a basso costo.
Hadoop fornisce un framework che si occupa di distribuire e replicare i dati
e le elaborazioni. Questo consente di gestire quantita' enormi di dati
(Big Data) senza richiedere HW verticale ma solo una serie di
normali ed economici sistemi industry standard.
I due componenti principali di Hadoop sono l'Hadoop Distributed File System (HDFS)
e l'algoritmo di distribuzione del processing MapReduce
(ottenuto dividendo il carico elaborativo tra tutti i nodi del cluster (Map)
e quindi raggruppando i risultati ottenuti (Reduce)).
Intorno ad Hadoop sono stati sviluppati decine di progetti che costituiscono un intero ecosistema. Per interrogare i dati mantenuti su Hadoop si utilizza Pig che fornisce un linguaggio di interrogazione molto adatto al calcolo parallelo.
Il linguaggio Pig si e' rivelato molto utile per le tipiche elaborazioni su Hadoop
e quindi e' molto diffuso.
Pig e' disponibile direttamente sul sito Apache ed anche in tutte le distribuzioni Hadoop:
Cloudera,
Hortonworks,
MapR.
Pig si lancia da linea di comando ed il prompt e' sgrunt>
I comandi di Pig sono molto differenti dall'SQL sia nella sintassi che nella costruzione del risultato che avviene per fasi (NoSQL) costruendo flussi di dati che via via portano all'informazione desiderata.
Pig dispone dei principali costrutti dell'algebra relazionale e puo' richiamare i comandi Hadoop.
Pig e' interattivo ma quando viene richiesta un'operazione che genera una scrittura
vengono eseguite una serie di passi di complilazione ed ottimizzazione per determinare
i singoli passi da svolgere nel modo piu' efficiente.
Come linguaggio di interrogazione Pig e' simile all'algebra relazionale ma internamente
utilizza MapReduce per eseguire i comandi e sue le "tuple" possono essere molto piu' complesse
di una semplice riga di un relazionale.
Particolarmente potente e' la possibilita' di definire funzioni (UDF) che vengono
aggiunte agli operatori e
funzioni
gia' disponibili (per altro senza alcuna differenza rispetto ai comandi nativi).
Un esempio classico di Pig e' [NdE: source Twitter]:
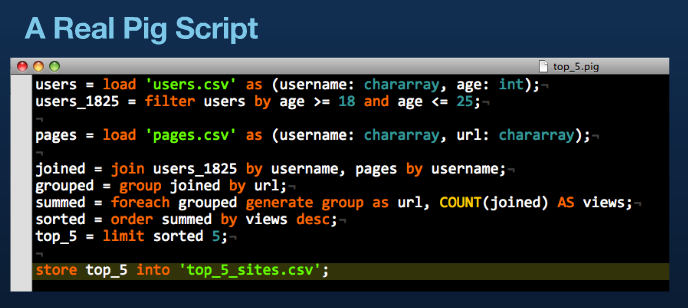
Dovrebbe essere chiaro come vengono trovati i 5 siti piu' acceduti dagli utenti giovani! Ma ora vediamo altri esempi...
Nel seguito vengono presentati diversi esempi pratici.
Gli script sono presentati con difficolta' crescenti in modo che lettura porti
a conoscere meglio lo strumento. Si comincia dai tracciati record piu' facili (un CSV),
per arrivare ai piu' complessi (log Apache);
i primi esempi utilizzano i raggruppamenti piu' semplici per arrivare
a quelli multipli; ...
Tutti gli esempi sono funzionanti con la diffusa distribuzione Cloudera CDH4.
Sembra banale... ma non e' cosi'!
Ci sono infatti piccole differenze tra versioni, negli script hanno importanza le maiuscole,
le regular expression richiedono sempre qualche trucco, ...
sottiliezze che, qualche volta, fanno perdere tempo.
In ogni caso gli esempi possono essere facilmente adattati su qualsiasi configurazione di Hadoop.
Buona lettura!
(10.101.16.76,151) (10.101.16.75,119) ([local],87) (10.102.230.16,85) check: 16.230.102.10.in-addr.arpa name = vm-jbfsan04...
(AUTHPROD,IRIDE,227711) (AUTHPROD,IRIDEV2,40356) (AUTHPROD,SSOBART,12705) (NAOPROD,NAO_RW,12266) (AUTHPROD,RPCOTO,8687) (AUTHPROD,BDA,8604) (NAOPROD,EI,7690) (NAOPROD,CSIMON,7150) (NAOPROD,NAOELE_RW,4582)
(2012-01-01,98,86,12,0) (2012-01-02,1108,263,687,158) (2012-01-03,1409,276,912,221) (2012-01-04,1312,283,797,232) (2012-01-05,1136,237,736,163) (2012-01-06,101,94,6,1) (2012-01-07,260,100,144,16) (2012-01-08,118,112,6,0) (2012-01-09,1678,366,1038,274) (2012-01-10,1803,385,1135,283) (2012-01-11,1712,405,1009,298) (2012-01-12,1611,392,949,270) (2012-01-13,1566,331,970,265) (2012-01-14,182,97,79,6) (2012-01-15,127,123,4,0) (2012-01-16,1786,427,1046,313)
(Mozilla/5.0,997081,1.18837305205E11) (Mozilla/4.0,765449,7.7732727033E10) (Microsoft,13616,2.59377227E8) (Googlebot/2.1,9846,2.385702314E9) (Opera/9.80,2809,3.92158561E8) (SAMSUNG-SGH-E250/1.0,2065,5.90989341E8) (DoCoMo/2.0,1998,1.536554239E9)
Titolo: Pig Samples
Livello: Avanzato
Data:
24 Giugno 2012
Versione: 1.0.3 - 30 Luglio 2012
Autore:
mail [AT] meo.bogliolo.name