Cloudera Hadoop
In questo documento viene descritto, in forma molto pratica,
l'utilizzo della distribuzione CDH
(Cloudera
Distribution for
Apache Hadoop).
Hadoop e' una piattaforma di storage e di capacita' di calcolo
in grado di scalare in modo quasi lineare su migliaia di server e
con dati superiori ai Peta (non e' una parolaccia: sono 1024 Tera).
CDH e' la distribuzione di Hadoop maggiormente diffusa e
comprende un'ampia serie di tool Open Source per la gestione dei Big Data.
Cloudera chi era costui?
Una breve introduzione e' necessaria per non fare confusione...
 Apache Hadoop e' un software Open Source per il distributed computing
che consente la gestione quantita' enorme di dati su sistemi a basso costo.
L'idea di base e' quella di aumentare la capacita' computazionale di
un sistema aggiungendo server a basso costo (scalabilita' orizzontale)
mediante un framework che si occupa di distribuire e replicare i dati
e le elaborazioni. Questo consente di gestire quantita' enormi di dati
(Big Data) senza richiedere HW apposito dedicato
(come avviene con la scalabilita' verticale).
Apache Hadoop e' un software Open Source per il distributed computing
che consente la gestione quantita' enorme di dati su sistemi a basso costo.
L'idea di base e' quella di aumentare la capacita' computazionale di
un sistema aggiungendo server a basso costo (scalabilita' orizzontale)
mediante un framework che si occupa di distribuire e replicare i dati
e le elaborazioni. Questo consente di gestire quantita' enormi di dati
(Big Data) senza richiedere HW apposito dedicato
(come avviene con la scalabilita' verticale).
I due componenti principali di Hadoop sono l'Hadoop Distributed File System (HDFS)
e l'algoritmo di distribuzione del processing MapReduce
[NdE basato sulle ricerche pubblicate da Google nel 2004].
Utilizzano Hadoop come base o si interfacciano ad esso molti altri progetti Apache come:
Cassandra (database multi-master senza SPOF),
HBase (database distribuito per large tables),
Hive (infrastruttura data warehouse),
Pig (linguaggio di interrogazione adatto al calcolo parallelo),
ZooKeeper (l'ecosistema di Hadoop e' variegato come uno zoo, per gestire le configurazioni dei programmi...
c'e' un programma apposta ;-), ...
Si tratta della frontiera piu' avanzata sulla gestione dei dati
che ha avuto un forte impulso con i siti dei motori di ricerca e dei social network.
La grande quantita' di dati ed il forte numero di accessi di questi
siti ha presentato
una sfida che non trovava una risposta con le tecnologie tradizionali:
sono nati cosi' nuovi strumenti e prodotti.
Ci sarebbe molto altro da dire sia come prodotti
che come teoria (teorema di CAP, sharding, latenza, 2PC, memcache, ...)
ma basta cosi!
L'importante e' sottolineare che raggruppati con nomi simili (Big Data, NoSQL)
sono etichettati ambienti tra loro molto diversi, che risolvono problemi diversi
e che quindi vanno utilizzati per scopi diversi.
Hadoop e' ottimo per gestire quantita' enormi di dati
dividendo il carico elaborativo tra tutti i nodi del cluster (Map)
e quindi raggruppando i risultati ottenuti (Reduce).
Hadoop e' utilizzato efficacemente in configurazioni con decine o centinaia
di nodi che ospitano applicazioni batch che non potrebbero essere elaborate
su architetture differenti.
Naturalmente gestire i nodi di Hadoop richiede un impegno significativo...
ed anche solo capire quali sono i componenti necessari ed installarli
correttamente non e' facile!
Cloudera ha inserito Hadoop e tutti i componenti piu'
utili in una distribuzione chiamata CDH (Cloudera Distribution for Apache Hadoop)
ed ha realizzato un
manager per la gestione (gratuito sino a 50 nodi).
Ecco quello di cui parleremo in questa pagina!
Questa pagina contiene esempi (basati su CDH4 2Q 2012):
Hadoop,
Pig,
Utilizzo del Manager Cloudera,
Installazione Cloudera,
Pentaho,
...
Hadoop
Hadoop e' composto da piu' elementi: un filesystem... la teoria la lascio ad altri documenti: qui solo esempi!
su - hdfs
hadoop fs -mkdir /emp7
hadoop fs -chmod 777 /emp7
hadoop fs -put /tmp/emp.csv /emp7
hadoop fs -ls /emp7
Found 1 item
-rw-r--r-- 3 hdfs supergroup 253 2012-06-21 13:13 /emp7/emp.csv
hadoop fs -cp /emp7/emp7.csv /emp7/pippo
hadoop fs -cat /emp7/pippo | wc -l
hadoop fs -fs hdfs://bigdata7.xenialab.it:8020 -ls /emp7
Found 2 items
-rw-r--r-- 3 hdfs supergroup 253 2012-06-21 13:13 /emp7/emp.csv
-rw-r--r-- 3 hdfs supergroup 253 2012-06-29 17:17 /emp7/pippo
Dovrebbe essere chiaro l'utilizzo di HDFS come FS distribuito!
I comandi di base di hadoop ricordano quelli classici Unix: rm cat chmod ls ...
e possono essere messi in pipe, rediretti, ...
La cosa importante di Hadoop e' che serve quando le dimensioni sono enormi.
Comincia ad essere efficare quando si lavora con i Terabyte,
se le dimensioni sono inferiori la latenza iniziale lo rende piu'
lento dei FS tradizionali.
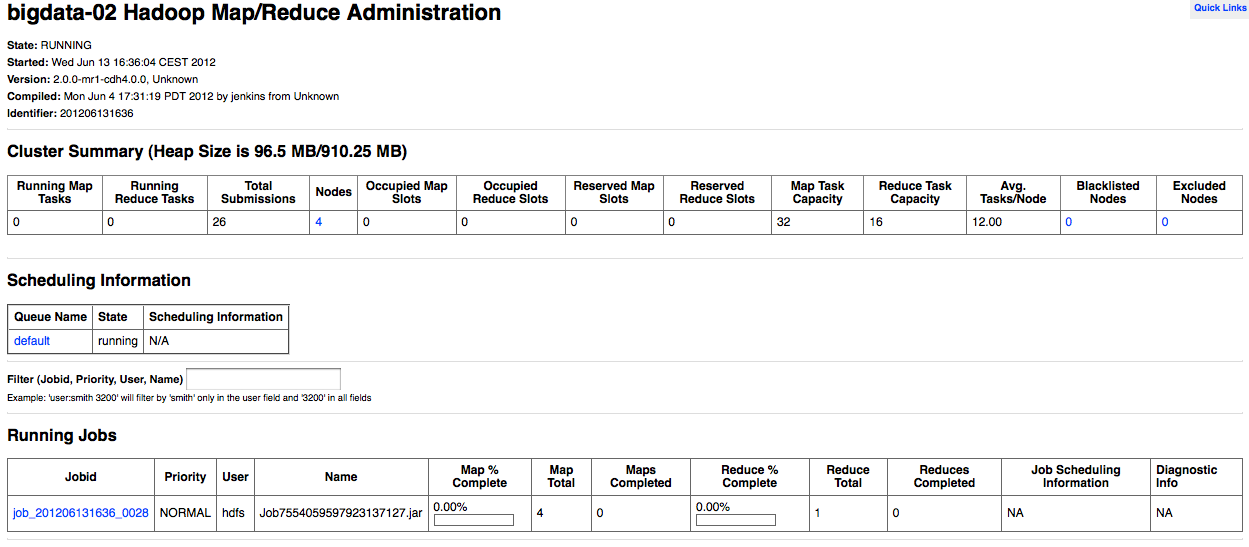
Per monitorare le esecuzioni in corso si puo' accedere all'URL di gestione del nameserver
(default sulla porta 50030).
Ecco un paio di videate di esempio:

Pig
Pig ovviamente e' un maiale ed il suo prompt e' sgrunt>
A parte gli scherzi un buon esempio che dimostra l'uso di Pig
e' il seguente (non e' mio: e' di twitter... ma era fatto troppo bene per prepararne uno simile).
Per capirlo basta... leggerlo!
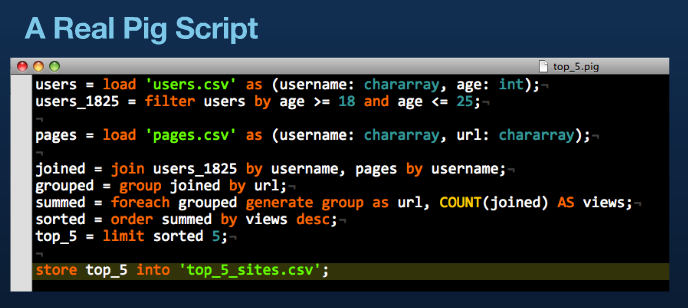
Dovrebbe essere chiaro l'utilizzo come linguaggio di interrogazione ad alto livello!
Chi si occupa di Big Data utilizza i comandi
Pig per creare script batch che operano sui dati di Hadoop.
Nel capitolo precedente abbiamo caricato un file su HDFS, ora lo utilizziamo per implementare
il benchmark emp7:
time pig <<EOF
a1 = load '/emp7/emp.csv' using PigStorage(',') as (empno: int, ename: chararray, deptno: int);
a2 = load '/emp7/emp.csv' using PigStorage(',') as (empno: int, ename: chararray, deptno: int);
a3 = load '/emp7/emp.csv' using PigStorage(',') as (empno: int, ename: chararray, deptno: int);
a4 = load '/emp7/emp.csv' using PigStorage(',') as (empno: int, ename: chararray, deptno: int);
a5 = load '/emp7/emp.csv' using PigStorage(',') as (empno: int, ename: chararray, deptno: int);
a6 = load '/emp7/emp.csv' using PigStorage(',') as (empno: int, ename: chararray, deptno: int);
a7 = load '/emp7/emp.csv' using PigStorage(',') as (empno: int, ename: chararray, deptno: int);
b = filter a1 by deptno==10;
c = join b by deptno, a2 by deptno, a3 by deptno, a4 by deptno, a5 by deptno, a6 by deptno, a7 by deptno;
d = group c all;
e = foreach d generate COUNT(c);
dump e;
quit;
EOF
Pig dispone dei principali costrutti dell'algebra relazionale e puo' richiamare i comandi Hadoop.
Pig e' interattivo ma quando viene richiesta un'operazione che genera una scrittura
vengono eseguite una serie di passi di complilazione ed ottimizzazione per determinare
i singoli passi da svolgere nel modo piu' efficiente.
Come linguaggio di interrogazione Pig e' simile all'algebra relazionale ma internamente
utilizza MapReduce per eseguire i comandi e sue le "tuple" possono essere molto piu' complesse
di una semplice riga di un relazionale.
Particolarmente potente e' la possibilita' di definire funzioni (UDF) che vengono
aggiunte agli operatori e
funzioni
gia' disponibili.
Pig e' utilizzato parecchio anche sulle installazioni Hadoop piu' significative.
Infatti e' possibile scrivere programmi su Hadoop utilizzando le API, ma uno script scritto con Pig
e' molto piu' breve e molto piu' semplice da scrivere e mantenere.
Su questo documento si trova qualche ulteriore esempio.
Utilizzo del manager
Il manager di Cloudera permette l'installazione dei nodi Hadoop, la loro gestione
ed aggiornamento in modo semplice da un'intuitiva console su browser.
Questo capitolo presenta le principali funzionalita' del manager.
Accedendo alla console (l'URL di default e' http://myhost.mydomain:7180)
e' necessario indicare username e password (default: admin admin):
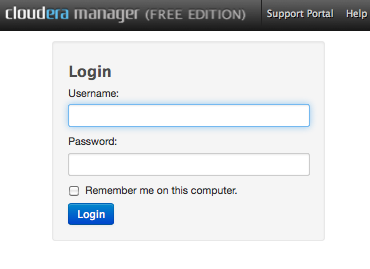
Si accede cosi' al manager:

Selezionando l'icona delle impostazioni:

Per controllare lo stato di un host e' possibile lanciare l'inspector:
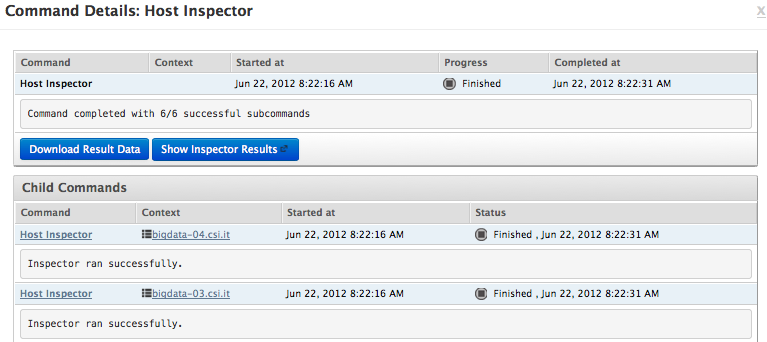
Ottenendo come risultato:

E' possibile svolgere attivita di aministrazione:

I servizi disponibili sono:

Le URL di amministrazione dei client sono:
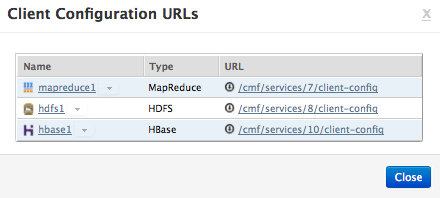
Installazione Cloudera
L'installazione di Cloudera e' tipicamente composta da un manager e da
una serie di nodi su cui vengono mantenuti i dati da Hadoop.
L'attuale versione di Cloudera Manager e' la 4 e consente di gestire fino a 50 nodi
nella versione Free [NdE CDH4 e' completamente libera, il manager e' free fino alla
gestione di 50 nodi oltre i quali richiede la sottoscrizione della versione Enterprise].
Sono possibili diverse modalita' di installazione.
Sicuramente la piu' comoda e' quella automatica:
Si installa il solo manager e da questo si effettua il deploy del software
su tutti i nodi!
Il download del software si effettua dal
sito ufficiale
scegliendo la versione di interesse [2Q 2012: 4.0.1 o 3.7.6].
E' in generale consigliato utilizzare sempre le versioni piu' recenti.
Lo script di installazione, da eseguire come root, e' .
Terminata l'installazione ci si connette alla console con un browser.
La porta di default e' 7180, l'utenza di amministrazione admin/admin.
I passi successivi richiedono la connessione SSH ai vari nodi ma il wizard di configurazione
e' molto semplice.
Pentaho
 Pentaho e' un diffuso ambiente di BI (Business Intelligence) Open Source.
Pentaho
contiene diversi pacchetti tra loro integrati che consentono la gestione
completa di tutte le problematiche della Business Intelligence e dei Data Warehouse.
Kettle
e' la componente ETL (Extract, Transform and Load) di
Pentaho,
ovvero si occupa del trasferimento e della trasformazione dei dati.
Trasferimento e trasformazione dei dati sono ovviamente fondamentali per i Big Data.
Pentaho e' un diffuso ambiente di BI (Business Intelligence) Open Source.
Pentaho
contiene diversi pacchetti tra loro integrati che consentono la gestione
completa di tutte le problematiche della Business Intelligence e dei Data Warehouse.
Kettle
e' la componente ETL (Extract, Transform and Load) di
Pentaho,
ovvero si occupa del trasferimento e della trasformazione dei dati.
Trasferimento e trasformazione dei dati sono ovviamente fondamentali per i Big Data.
L'ultima versione community di Kettle [4.3 2Q 2012] introduce il supporto ai principali ambienti
Big Data e NoSQL.
Per configurare su Pentaho l'utilizzo della recente versione Cloudera CDH4 vanno seguiti i
passi di questa
recentissima nota
[NdE disponibile dal 26-JUN-2012].
Una volta effettuata la configurazione e' possibile richiamare i dati ospitati su Hadoop
e sugli altri prodotti della CDH4
come se fossero su normali file system o database relazionali.
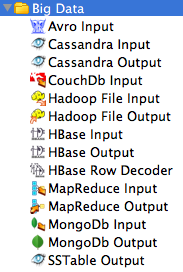
A destra sono riportate le immagini degli step Big Data
utilizzabili nei Job e nelle Trasformazioni di Kettle.
E' un elenco in costante aggiornamento:
rimanete sintonizzati!
Maggiori dettagli si trovano nelle pagine su Pentaho
e su Kettle.