Hortonworks
In questo documento viene descritto, in forma molto pratica,
l'utilizzo della distribuzione HDP
(Hortonworks
Data Platform) per
Apache Hadoop.
Hadoop e' una piattaforma di storage e di capacita' di calcolo
in grado di scalare in modo lineare su centinaia di server e
gestire quantita' di dati superiori ai Peta (non e' una parolaccia: sono 1024 Tera).
Hortonworks e' una distribuzione che contiene l'intero ecosistema Hadoop
ed e' 100% Open Source.
Distribuzioni Hadoop
Una breve introduzione e' necessaria per non fare confusione...
 Apache Hadoop e' un software Open Source per il distributed computing
che consente la gestione quantita' enorme di dati su sistemi a basso costo.
L'idea di base e' quella di aumentare la capacita' computazionale di
un sistema aggiungendo server a basso costo (scalabilita' orizzontale)
mediante un framework che si occupa di distribuire e replicare i dati
e le elaborazioni. Questo consente di gestire quantita' enormi di dati
(Big Data) senza richiedere HW apposito dedicato
(come avviene con la scalabilita' verticale).
Apache Hadoop e' un software Open Source per il distributed computing
che consente la gestione quantita' enorme di dati su sistemi a basso costo.
L'idea di base e' quella di aumentare la capacita' computazionale di
un sistema aggiungendo server a basso costo (scalabilita' orizzontale)
mediante un framework che si occupa di distribuire e replicare i dati
e le elaborazioni. Questo consente di gestire quantita' enormi di dati
(Big Data) senza richiedere HW apposito dedicato
(come avviene con la scalabilita' verticale).
Hadoop e' ottimo per gestire quantita' enormi di dati con algoritmo che
dividono il carico elaborativo tra tutti i nodi del cluster (Map)
e quindi raggruppano i risultati ottenuti (Reduce).
Hadoop e' utilizzato efficacemente in configurazioni con decine o centinaia
di nodi che ospitano applicazioni batch o stream
che non potrebbero essere elaborate
su architetture tradizionali.
I componenti principali di Hadoop sono l'Hadoop Distributed File System (HDFS),
l'algoritmo di distribuzione del processing MapReduce
e YARN il sistema di controllo (API REST di MRv2).
Inoltre utilizzano Hadoop o si interfacciano ad esso decine di altri progetti
[NdE progetti e sottoprogetti Apache per essere precisi] come:
HBase (database distribuito per large tables),
Hive (infrastruttura data warehouse e standard SQL per Hadoop),
Pig (linguaggio di interrogazione adatto al calcolo parallelo),
ZooKeeper (per gestire la configurazione del cluster), ...
Le funzionalita' di alcuni componenti a volte si sovrappongono e comunque vanno integrati tra loro.
Capire quali sono i componenti di Hadoop necessari, installarli e mantenerli allineati
correttamente non e' facile;
gestire centinaia di server installati richiede un impegno significativo...
Per questo sono nate distribuzioni che contengono l'intero ecosistema Hadoop
gia' configurato e funzionante. Le distribuzioni piu' significative sono:
 Cloudera: e' stata la prima distribuzione basata su Hadoop ed e' la piu' diffusa.
Utilizza i moduli Open Source e, per la gestione, fornisce un ambiente proprietario
di facile comprensione ed utilizzo.
Cloudera: e' stata la prima distribuzione basata su Hadoop ed e' la piu' diffusa.
Utilizza i moduli Open Source e, per la gestione, fornisce un ambiente proprietario
di facile comprensione ed utilizzo.
 MapR: e' considerata la distribuzione con le migliori performances, grazie
anche alla sostituzione di alcuni componenti Open Source con moduli ottimizzati (eg. HDFS con MapR-FS).
Anche MapR utilizza moduli proprietari per la gestione.
MapR: e' considerata la distribuzione con le migliori performances, grazie
anche alla sostituzione di alcuni componenti Open Source con moduli ottimizzati (eg. HDFS con MapR-FS).
Anche MapR utilizza moduli proprietari per la gestione.
 Hortonworks : e' una distribuzione completamente Open Source anche per i componenti di gestione.
Hortonworks : e' una distribuzione completamente Open Source anche per i componenti di gestione.
Anche se Hortonworks e' la distribuzione piu' recente, e' quella che ha avuto la crescita
piu' significativa in quest'ultimo periodo:
Hortonworks e' molto apprezzata per la qualita' delle proprie
releases e per il numero elevato di committers sui progetti Open Source legati ad Hadoop.
Il documento non entra nel dettaglio dei vari componenti Hadoop:
naturalmente il lettore li conosce gia' tutti benissimo!
In precedenza avevo gia' scritto qualche riga su alcuni di essi:
HDFS,
PIG,
Hive.
Questa pagina contiene esempi pratici su HDP (basati sulla versione 2.3 di luglio 2015 ed aggiornati alla versione 2.6):
Installazione di Hortonworks,
Contenuti,
Amministrazione ed Ambari,
Utilizzo,
Storia,
...
Installazione Hortonworks
Sono possibili diverse modalita' di installazione della distribuzione Hortonworks...
Tra le diverse possibili ne descriviamo solo due: la piu' semplice (Sandbox) e quella di produzione
(Ambari).
Come versione utilizziamo la 2.3 di produzione perche'... e' disponibile da oggi! [NdE 22 luglio 2015]
L'installazione della Sandbox e' costituita dall'immagine di una macchina virtuale che
contiene l'intero ambiente gia' configurato.
Si tratta dell'installazione piu' semplice: basta far partire la macchina sul virtualizzatore
[NdE sono supportati i principali ambienti di virtualizzazione: VirtualBox, VMWare o Hyper-V].
L'unica avvertenza e' che la Sandbox ha requisiti significativi (consigliati 4 vCPU e 8GB RAM)
perche' l'insieme di ambienti che contiene e' significativo: va ospitata su un sistema adeguato.
- Ovviamente il primo passo e' il download dal sito ufficiale!
- E' ora sufficiente importare il file .ova [NdE utilizzando Virtualbox 5.0]:

- Qualche minuto di pazienza e la VM viene importata. Ora basta avviarla e parte una CentOS con tutti i servizi necessari.
Ecco cosa appare al termine:

- Non serve collegarsi a Linux [NdA ovviamente l'ho fatto perche' sono curioso:
ma e' un linux normale
cui si accede come root/hadoop in SSH sulla porta 2222],
tutte le attivita' possono essere svolte da browser:

Per un ambiente di produzione, tipicamente installato su decine o centinaia di server
la modalita' consigliata di installazione e' utilizzando Apache Ambari.
La prima fase per un set-up di produzione e' quello del sizing.
Vanno valutati i dati raccolti e la retention per un corretto dimensionamento degli spazi
(tenendo conto del livello di replica su Hadoop, dello spazio per le elaborazioni e dell'eventuale compressione).
Altro aspetto fondamentale da valutare sono le elaborazioni (tipologia, durata, frequenza e latenza).
Con questi dati e' possibile effettuare un sizing dei nodi Master
(NameNode, Standby NameNode, JobTracker, HBase Master)
e dei nodi Workers (DataNode, TaskTracker, RegionServers) in termini di CPU, memoria e disco.
Un'alternativa e' quella del deploy su un cloud privato o pubblico:
tenendo bene in conto gli aspetti di sicurezza dei dati e delle prestazioni
che, su sistemi virtualizzati, presentano notevoli differenze rispetto all'uso di sistemi fisici.
Va utilizzata una versione Hadoop recente ed si avranno prestazioni inferiori
ma con il vantaggio di una maggiore flessibilita'.
Una volta effettuata la fase di progettazione e di setup di base dei sistemi (installazione OS, setup SSH) si procede con
l'installazione di un server Ambari da repository con [NdE per CentOS 6]:
# wget -nv http://public-repo-1.hortonworks.com/ambari/centos6/2.x/updates/2.1.0/ambari.repo -O /etc/yum.repos.d/ambari.repo
# yum install ambari-server
...
# ambari-server setup
# ambari-server start
Ambari ora e' accessibile via browser sulla porta 8080 con utenza admin/admin
ed e' possibile lanciare il wizard che installa la distribuzione HDP su tutti i sistemi!
Contenuti Hortonworks
Ma cosa contiene la distribuzione HDP?
Questa figura e' un'ottimo riassunto:
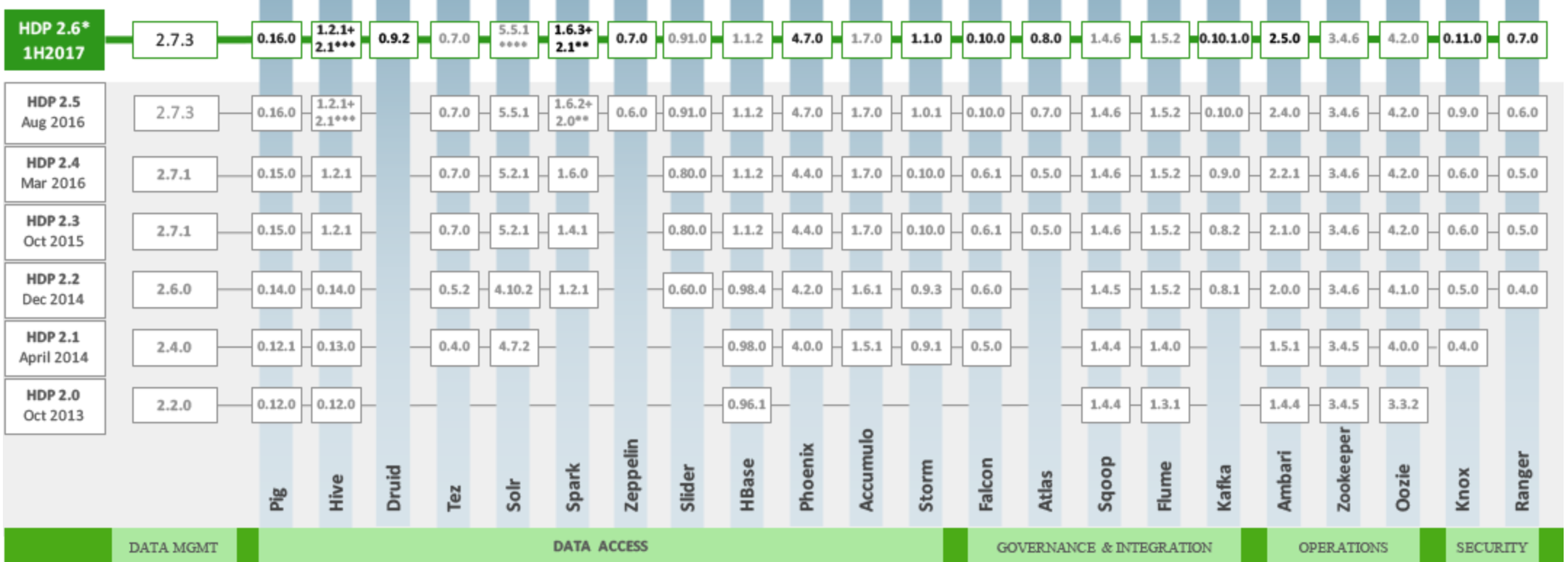
In pratica oltre ad Hadoop 2.7.x sono presenti molteplici programmi per l'accesso ai dati
(eg. Pig, Hive) e per la gestione di Hadoop.
Sono presenti anche alcuni dei progetti piu' recenti ed interessanti (eg. Apache Spark)
e tutte le versioni sono aggiornate.
Nella distribuzione vengono anche inclusi i linguaggi di supporto (eg. Python),
gli RDBMS (eg. MySQL (utilizzato da Hive e da Ranger), PostgreSQL (utilizzato da Ambari)),
il JavaServer Tomcat (utilizzato da Oozie), ...
che sono componenti necessari per il funzionamento dell'intero ecosistema.
Con l'avanzamento delle release intermedie di HDP vengono distribuite versioni
aggiornate dei vari componenti.
Ad esempio con la sandbox 2.3.2 [NdE 2015-10] sono stati aggiornati:
Spark 1.4.1, HBase 1.1.2, ...
Per la versione 3 [NdA sorgente https://hortonworks.com/products/data-platforms/hdp/] sono attesi parecchi cambiamenti,
a partire dall'utilizzo di Hadoop 3.1:

Tutti i componenti sono configurati ma alcuni non sono attivati per default.
Come farli partire? Nel prossimo capitolo!
Amministrazione ed Ambari
L'amministrazione viene svolta sopratutto con Ambari.
Apache Ambari e' una di quei programmi che e' molto piu' facile da utilizzare che da spiegare!

La dashboard di Ambari e' un elemento caratterizzante delle distribuzioni Hortonworks
ed in particolare dell'ultima versione [NdE 2.3]:
e' completa e dettagliata ma al tempo stesso di immediata comprensione e di facile utilizzo.
Da un'unica videata e' possibile controllare lo stato di ciascun componente,
attivarlo o fermarlo, metterlo in modalita' di Manteniance o controllarne gli allarmi,
visualizzare le metriche di utilizzo,
controllare i singoli host, aggiornare le versioni di ogni componente,
...
Anche se apparentemente semplice
in realta' dal punto di vista tecnico Ambari e' molto complesso perche'
implementa funzionalita' differenti quali la gestione delle versioni
e la raccolta di dati statistici, la gestione dei componenti e
l'allarmistica, ... in modo affidabile e scalabile come richiesto
dalle configurazioni di maggiori dimensioni.
La quasi totalita' dei componenti dell'ecosistema Hadoop viene avviata e gestita con Ambari
ma c'e' qualche eccezione da gestire in modo classico dalla console.
Per accedere si utilizza l'SSH (root/hadoop), se utilizzare una tastiera italiana
potete utilizzare il comando loadkeys it .
Uno dei pochi tool che non si gestisce da Ambari e' Ranger:
service ranger-admin start
service ranger-usersync start
[NdA nelle ultime distribuzioni Ambari puo' gestire Ranger...]
Utilizzo
L'accesso alle principali funzionalita' di HDP avviene principalmente con un browser.
La maggioranza dei tool ha una user inferface web o REST.
Ecco le URL principali:
Per un semplice accesso ai dati
un buon punto di partenza e' Hue.
Ma chi e' Hue?
Hue e' un'insieme di web application che consentono di gestire i dati su Hadoop:

Le icone riportate indicano il tool utilizzato (eg. Hive, Pig, HCatalog, Oozie, ...),
con un click appare la relativa interfaccia web.
Come tutte le interfacce grafiche sono di semplice utilizzo: basta
seguire il link gia' riportato!
Nella distribuzione HDP come sandbox
sono gia' compresi diversi fileset di esempio ed e' possibile utilizzare i tutorial ufficiali...
Buon divertimento!
Storia
Hortonworks e' una distribuzione recente ma che ha guadagnato molto velocemente
consenso e vanta un numero sempre crescente di installazioni.
Su questa pagina e' mantenuto aggiornato l'elenco delle release HDP
(Source: Hortonworks)
| Distribution |
Version |
Status |
Features |
Last release |
Date (from) |
Notes |
| Hortonworks | HDP | | Hortonworks Data Platform is a fully Open Source distribution
available on both Linux and MS-Windows. | | |
|
| HDP | 3.0 | Production | Hadoop 3.1.0,
container support, GPU processing, Hybrid Cloud provisioning.
Almost all components upgraded: Oozie 4.3.1, Hive 3.0.0, Druid 0.12.0, Zeppelin 0.8.0, HBase 2.0.0, Knox 1.0.0, Ranger 1.0.0, Atlas 1.0.0, Ambari 2.7.0, ...
Desupport: Flume, Falcon, Manhout, ...
| 3.0 | 2018 |
|
| HDP | 2.6 | Production | Hadoop 2.7.3. Upgraded components: Druid 0.9.2, Spark 1.6.3/2.1, Zeppelin 0.7.0, Atlas 0.8.0, Kafka 0.10.1, Ambari 2.5.0, Knox 0.11.0, Ranger 0.7.0, ...
| 2.6.5 | 2017-04 |
|
| HDP | 2.5 | Production | Hadoop 2.7.3. Upgraded components: Ambari 2.4.0, Spark 1.6.2/2.0, Kafka 0.10.0, Pig 0.16.0, Hive 1.2.1/2.1, Zeppelin 0.6.0, Knox 0.9.0, Ranger 0.6.0, ...
| 2.5 | 2016-08 | 2018-08
|
| HDP | 2.4 | Production | Hadoop 2.7.1. Upgraded components: Ambari 2.2.1, Spark 1.6.0, HBase 1.1.2, Kafka 0.9.0.
| 2.4 | 2016-03 | 2018-03
|
| HDP | 2.3 | Production | Hadoop 2.7.1, Hive 1.2.1, Ambari 2.1, Spark 1.3.1, Ranger 0.5. Smart Hadoop configuration, dashboards. Added support for Apache Atlas 0.5 (governance module), Cloudbreak 1.0. (2.3.2): Spark 1.4.1.
| 2.3.2 | 2015-07 | 2017-07
|
| HDP | 2.2 | Production | Hadoop 2.6, Hive 0.14. Added support for Apache Spark 1.2.1, Slider 0.60 and Ranger 0.4.
Deprecated: Nagios, Ganglia.
| 2.2.8 | 2014-12 | 2016-12
|
| HDP | 2.1 | Production | Hadoop 2.4.0, Hive 0.13, Hbase 0.98, Flacon 0.5, Flume 1.4, Ambari 1.6, ...
Added support for Solr, Tez, Storm, Falcon, Knox.
| 2.1.15 | 2014-04 |
|
| HDP | 2.0 | Production | Hadoop 2.2.0, Hive 0.12, Hbase 0.96, Flume 1.4, Ambari 1.4.1, ...
| 2.0.12 | 2013-10 |
|
| HDP | 1.3 | Production |
Hadoop 1.2.0 (HDFS, YARN, MapReduce), Pig 0.11, Hive 0.11.0,
Apache HBase 0.94.6, Sqoop 1.4.3, ... Oracle connectors. HDFS snapshot for PITR.
| 1.3.10 | 2013-05 |
|
| HDP | 1.2 | Production |
Hadoop 1.1.2, Pig 0.10.1, Hive 0.5.0, HBase 0.94.2.
| 1.2 | 2013-02 |
|
| HDP | 1.1 | Production |
Some upgrades: Sqoop 1.4.2.
| 1.1 | 2012-09 |
|
| HDP | 1.0 | Production |
Based on Apache Hadoop 1.0.3. Contains:
Pig 0.9.2,
Hive 0.9.0,
Apache HBase 0.92.1,
Sqoop 1.4.1,
Oozie 3.1.2,
Apache ZooKeeper 3.3.4,
Ganglia 3.2.0,
Nagios 3.2.3, ...
| 1.0 | 2012-06 |
|