AlloyDB
Columnar Engine
 AlloyDB,
la base dati compatibile con PostgreSQL disponibile su Google,
presenta una serie di funzionalita' aggiuntive rispetto alla versione Community;
in questa breve paginetta vedremo il Columnar Engine.
AlloyDB,
la base dati compatibile con PostgreSQL disponibile su Google,
presenta una serie di funzionalita' aggiuntive rispetto alla versione Community;
in questa breve paginetta vedremo il Columnar Engine.
La rappresentazione dei dati per colonne fornisce prestazioni migliori
per le query analitiche.
Con AlloyDB e' possibile ospitare un carico ibrido di query transazionali e di query analitiche
sulla stessa base dati in modo ottimale.
Dopo una breve introduzione ai componenti di base
(PostgreSQL, AlloyDB),
si entra nei dettagli dell'Engine Colonnare
vedendo
la configurazione
e l'utilizzo.
Per ovvie ragioni di spazio questo documento e' stato scritto per DBA PostgreSQL
o quantomeno per chi PostgreSQL gia' lo conosce e lo utilizza...
Per chi non conosce AlloyDB si consiglia la lettura di
un documento introduttivo su PostgreSQL
PostgreSQL
e su AlloyDB.
PostgreSQL
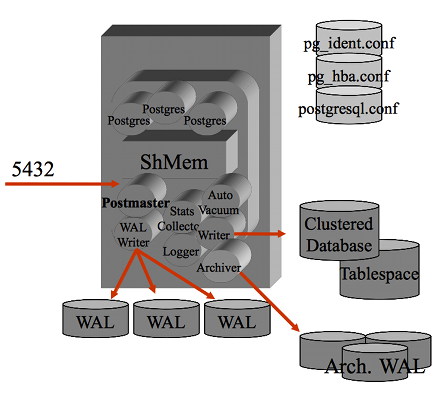 PostgreSQL
e' considerato a ragione il piu' completo e robusto RDBMS Open Source.
Le sue prestazioni ed affidabilita' sono paragonabili
a quelle dei piu' diffusi RDBMS commerciali
e su alcune funzionalita' e' il database di riferimento (eg. GIS).
I suoi principali punti di forza sono
una licenza molto aperta per tutti gli utilizzi,
la gestione completa ed efficiente delle transazioni (ACID),
ottime prestazioni ed affidabilita',
un SQL ricco di funzionalita'
(eg. subquery, referential integrity, inheritance, trigger, stored fuctions, 2PC,
full-text, JSON, analytics,
native partitioning, stored procedures, ...),
allineato ai piu' recenti standard ed estensibile (extension),
funzionalita' Object-Relational,
strumenti di amministrazione e gestione completi,
funzionalita' di replicazione/HA/DR incluse nel database.
PostgreSQL
e' considerato a ragione il piu' completo e robusto RDBMS Open Source.
Le sue prestazioni ed affidabilita' sono paragonabili
a quelle dei piu' diffusi RDBMS commerciali
e su alcune funzionalita' e' il database di riferimento (eg. GIS).
I suoi principali punti di forza sono
una licenza molto aperta per tutti gli utilizzi,
la gestione completa ed efficiente delle transazioni (ACID),
ottime prestazioni ed affidabilita',
un SQL ricco di funzionalita'
(eg. subquery, referential integrity, inheritance, trigger, stored fuctions, 2PC,
full-text, JSON, analytics,
native partitioning, stored procedures, ...),
allineato ai piu' recenti standard ed estensibile (extension),
funzionalita' Object-Relational,
strumenti di amministrazione e gestione completi,
funzionalita' di replicazione/HA/DR incluse nel database.
La gestione delle transazioni in PostgreSQL avviene con la tecnica del MVCC
(Multiversion Concurrency Control)
e la consistenza dei dati su disco e' assicurata con il logging sui WAL
(Write-Ahead Logging).
Un'instanza Postgres contiene piu' database.
All'interno di ogni database viene mantenuto un ricco Catalog
che consente di controllare con query SQL gli oggetti presenti
nella base dati (eg. pg_database, pg_class, pg_tables, ...) e l'andamento delle
attivita' (eg. pg_stat_activity, pg_locks, pg_settings, pg_stats,...).
Google fornisce in
Cloud SQL la base dati PostgreSQL
con una gestione in CLoud che
semplifica l'impostazione, il funzionamento e la scalabilita'.
Le basi dati Cloud SQL sono facilmente scalabili ed
automatizzano le principali attivita' di gestione del database (eg. update/upgrade, backup/restore, monitoring, storage management).
Tutte le basi dati vengono gestite da console grafica oppure con la CLI (gcloud) oppure con le API rest
oppure nella Cloud Shell con Terraform
in modo semplice e consistente.
Ma oltre alla versione community e' disponibile una versione potenziata
per la rete e le infrastrutture di Google chiamata AlloyDB!
AlloyDB
AlloyDB
e' l'implementazione Google di un database compatibile a PostgreSQL.
Come Cloud SQL for PostgreSQL anche AlloyDB e' una base dati gestita
(eg. tuning, backup, upgrade, scale, ...) e le versioni disponibili
fanno riferimento ad una precisa major version di PostgreSQL community.
Ma con AlloyDB vi sono importanti differenze rispetto a PostgreSQL:
- Storage Engine:
 AlloyDB utilizza uno storage engine proprietario sviluppato per il Cloud ed ottimizzato sull'infrastruttura Google.
Le tecniche di tiering e compressione consentono vantaggi prestazionali significativi rispetto ad un PostgreSQL standard
ad esempio nella fase di scrittura del WAL, particolarmente importante per la gestione delle transazioni.
AlloyDB utilizza uno storage engine proprietario sviluppato per il Cloud ed ottimizzato sull'infrastruttura Google.
Le tecniche di tiering e compressione consentono vantaggi prestazionali significativi rispetto ad un PostgreSQL standard
ad esempio nella fase di scrittura del WAL, particolarmente importante per la gestione delle transazioni.
- High Availability:
Con PostgreSQL e' possibile creare una configurazione in alta affidabilita' utilizzando
la replica, ma questo richiede configurazioni aggiuntive ed un'opportuna gestione.
Con AlloyDB le configurazioni in alta affidabilita' e la gestione del disaster recovery
sono molto semplici ed efficaci.
- Query Optimization:
L'ottimizzatore di AlloyDB e' stato perfezionato utilizzando anche tecniche di machine learning
per tener conto della configurazione specifica presente in Cloud
e per migliorare le performance delle query piu' complesse.
AlloyDB consente un parallelismo piu' elevato rispetto ad una normale istanza PostgreSQL.
- Additional features:
Oltre alla maggioranza delle core extension di Postgres e alle extension aggiuntive piu' utili per il Cloud,
AlloyDB offre funzionalita' aggiuntive come l'Index Advisory, l'AlloyDB AI, ...
e naturalmente l'oggetto di questa paginetta: il Columnar Engine.
Columnar Engine
La tipica applicazione dei database relazionali e' per ambienti OLTP (On-Line Transaction Processing)
in cui la velocita' di esecuzione e la gestione delle transazioni sono gli elementi caratteristici.
I database relazionali accedono ai dati mendiante gli indici e utilizzano tenciche di logging delle modifiche effettuate.
Per questo utilizzo i database relazionali, utilizzati con il linguaggio SQL,
sono da anni la tecnologia piu' utilizzata per gli OLTP (OnLine Transation Processing).
La rappresentazione tabellare dei dati e gli indici sono molto efficienti per accedere
ai record da selezionare/modificare nelle transazioni.
Quando pero' e' necessario analizzare basi dati di grandi dimensioni in modo completo sono necessari
i famigerati SEQUENTIAL SCAN,
per queste elaborazioni i tempi si allungano e passano dai millisecondi
ai minuti ed alle ore per le elaborazioni piu' complesse.
Con il termine OLAP (OnLine Analytical Processing) si indicano tecniche
ed architetture adatte ad analizzare in tempi molto brevi grandi basi dati.
I database colonnari utilizzano un approccio differente rispetto alla rappresentazione ISAM con indici B-Tree,
tipica dei DB relazionali, memorizzando i dati per colonna.
Il livello di compressione ottenibile memorizzando separatamente ogni colonna e'
di ordini di grandezza superiore rispetto a campi distinti e non ordinati.
Le dimensioni complessive delle singole colonne risultano ridotte e possono spesso essere mantenute tutte in memoria.
Questo consente di utilizzare algoritmi differenti nell'accesso ai dati
che possono essere eseguiti in parallelo su tutti i processori disponibili
e, in con alcuni motori anche in rete con piu' nodi.
Anche se sono necessarie scansioni complete dei dati queste avvengono solo sulle colonne interessate (eg. SUM(SAL)).
Su query di tipo OLAP
la rappresentazione colonnare dei dati, rispetto alla rappresentazione per righe,
tipicamente fornisce risultati in tempi di ordini di grandezza inferiori (eg. x100).
Il vantaggio e' quindi effettivamente notevole.
Ma non tutte i tipi di workload sono adatti ad una rappresentazione colonnare dei dati.
Spesso si era costretti ad utilizzare database differenti per la parte OLTP ed OLAP
utilizzando ETL o procedure applicative per ribaltare i dati.
AlloyDB utilizza una tecnica specifica permettendo di gestire un carico HTAP
(Hybrid Transactional and Analytical Processing) senza richiedere spostamenti di dati.
I dati vengono mantenuti sulle normali strutture di PostgreSQL ed in modo automatico
vengono analizzate le query presenti sul database per inserire le colonne piu' opportune
nel Column Store che viene mantenuto in memoria.
Il Columnar Engine di AlloyDB determina quali colonne rappresentare
nel Column Store e le carica automaticamente.
L'ottimizzatore di PostgreSQL e' stato modificato per tener conto di questa
rappresentazione ed e' in grado di utilizzare il column store per eseguire
le query analitiche mentre utilizza i normali algoritmi di PostgreSQL
per eseguire le query OLTP.
In questo modo con AlloyDB, senza alcuna modifica alle applicazioni ed ai dati,
senza alcuna necessita' di ETL e di sincronizzazioni tra database,
e' possibile ottenere significativi miglioramenti prestazionali
sulle query analitiche.
Configurazione
Il motore colonnare di AlloyDB per default non e' attivo
[NdA in realta' e' una delle scelte impostabili in fase di creazione del cluster]
ma la sua configurazione e' molto semplice.
Per attivare il Columnar Engine e' sufficiente impostare il Flag
google_columnar_engine.enabled ad on e riavviare.
Questo e' l'unico parametro necessario per attivare il motore colonnare.
Le opzioni sono molte e tutte configurabili con opportuni Flag.
La memoria assegnata al motore colonnare e' per default il 30% della memoria assegnata all'istanza
ma e' possibile modificare l'impostazione utilizzando il Flag google_columnar_engine.memory_size_in_mb.
Anche questo flag richiede il riavvio.
Una volta attivato l'engine per default ricerca automaticamente
le colonne da trattare (Flag google_columnar_engine.enable_auto_columnarization ad on)
controllando le attivita' presenti sulla base dati.
Un'alternativa e' quella di dichiarare l'elenco delle tabelle da trattare impostando
google_columnar_engine.relations.
L'elenco completo dei flag disponibili e' descritto in dettaglio nella
documentazione ufficiale,
ma per i piu' curiosi e' riassunto nella seguente tabella:
| Parameter | Value | Context | Description
|
| google_columnar_engine.adaptive_auto_refresh_schedule | | sighup | The schedule for adaptive auto refresh
|
| google_columnar_engine.auto_columnarization_schedule | | sighup | The schedule for auto columnarization
|
| google_columnar_engine.columnar_hash_joins_cost_factor | 100 | user | Factor by which cost of disfavored paths will be multiplied by, when google_columnar_engine.force_group_columnar_hash_joins is enabled.
|
| google_columnar_engine.enable_aggregate_distinct_in_aggregate_pushdown | off | user | Indicates whether to do SELECT AggFunc(DISTINCT) optimizations in aggregate pushdown.
|
| google_columnar_engine.enable_auto_columnarization | on | sighup | Enable auto columnarization
|
| google_columnar_engine.enable_auto_columnarization_local_storage_spill | off | sighup | Enable auto columnarization with local storage spill
|
| google_columnar_engine.enable_auto_cu_selection | off | user | Indicates whether auto CU selection is enabled.
|
| google_columnar_engine.enable_columnar_scan | on | user | Sets whether to enable columnar scan (for session).
|
| google_columnar_engine.enable_hashed_inlist | off | user | Indicates whether hashed INLISTs are enabled.
|
| google_columnar_engine.enable_materialized_view | on | user | Indicates whether materialized view can be loaded into columnar engine.
|
| google_columnar_engine.enable_select_distinct_in_aggregate_pushdown | on | user | Indicates whether to do SELECT DISTINCT optimizations in aggregate pushdown.
|
| google_columnar_engine.enable_timestamptz_date | on | user | Sets whether to enable columnar scan for timestamptz_date
|
| google_columnar_engine.enable_vectorized_join | off | user | Sets whether to enable joins using vectorized method
|
| google_columnar_engine.enable_vectorized_join_on_storage | off | user | Sets whether to enable vectorized joins if the columns are in storage
|
| google_columnar_engine.enabled | off | postmaster | Enable google columnar engine.
|
| google_columnar_engine.enforce_new_defaults | off | postmaster | Enforce new defaults for columnar engine.
|
| google_columnar_engine.heap_fragmentation_max_percentage | 1 | sighup | Expected fragmentation in the heap
|
| google_columnar_engine.ipc_reduction_ratio_for_vec_join | 0.8 | user | Sets the planner's ipc cost reduction ratio for vectorized join
|
| google_columnar_engine.memory_size_in_mb | 4800 | postmaster | Sets the size (in MB) of the shared memory for columnar engine.
|
| google_columnar_engine.parallel_distinct_aggregate_pushdown_threshold | 1 | user | Threshold for doing parallel SELECT AggFunc(DISTINCT) optimizations.
|
| google_columnar_engine.populate_detoasted_max_bytes | 64 | sighup | Column values are stored detoasted up to given max bytes per column
|
| google_columnar_engine.refresh_threshold_percentage | 50 | sighup | Threshold on invalid blocks percentage for refreshing the columnar unit
|
| google_columnar_engine.refresh_threshold_scan_count | 5 | sighup | Threshold on scan count without interleaving DMLs for refreshing the columnar unit
|
| google_columnar_engine.refresh_threshold_scan_count_by_costing | 20 | sighup | Threshold on scan count without interleaving DMLs for refreshing the columnar unit
|
| google_columnar_engine.relations | | sighup | Tables which need to be present in the columnar cache.
|
| google_columnar_engine.scan_mode | 0 | user | Scan Mode (0:Voxel, 1:Native, 2:RowStore)
|
| google_columnar_engine.vacuum_materialized_view_before_population | on | user | Vacuum materialized view before repopulate on primary if the mv is in columnar engine.
|
Utilizzo
Ora che il motore colonnare e' abilitato possiamo utilizzarlo.
Il modo piu' semplice di operare e' quello di utilizzare la ricerca automatica delle colonne.
In pratica, con una schedulazione che avviene per default ogni ora, vengono analizzate
le query effettuate sulla base dati e portate nel Column Store gli oggetti selezionati.
E' possibile variariare le diverse impostazioni sia con Flag che con funzioni SQL
e controllare le colonne effettivamente inserite nel Column Store.
La seconda possibilita' e' quella di impostare manualmente l'elenco delle colonne
impostando il flag
google_columnar_engine.relations con
DATABASE_NAME.SCHEMA_NAME.TABLE_NAME(COLUMN_LIST).
In questo caso e' necessaria un'operativita' maggiore
ed una conoscenza puntuale del tipo di attivita' presenti sul sistema.
E' una modalita' che permette piu' controllo da riservare ai casi in cui
le impostazioni automatiche non sono sufficienti.
Vediamo qualche esempio:
SELECT *
FROM g_columnar_schedules;
SELECT database_name, schema_name, relation_name, column_name
FROM g_columnar_recommended_columns;
SELECT google_columnar_engine_memory_available();
SELECT memory_name, pg_size_pretty(memory_total) as memory_total,
pg_size_pretty(memory_available) as memory_available,
memory_available_percentage
FROM g_columnar_memory_usage;
SELECT * FROM google_columnar_engine_recommend(mode => 'RECOMMEND_SIZE');
SELECT database_name, schema_name, relation_name, status, size, pg_size_pretty(size) as size_hr,
columnar_unit_count, invalid_block_count, total_block_count
FROM g_columnar_relations;
SELECT database_name, schema_name, relation_name, column_name, size_in_bytes, last_accessed_time
FROM g_columnar_columns;
SELECT google_columnar_engine_reset_recommendation(drop_columns => true);
SELECT google_columnar_engine_add(relation => 'TABLE_NAME',
columns => 'COLUMN_LIST');
SELECT *
FROM pg_stat_statements(TRUE) AS pg_stats
FULL JOIN g_columnar_stat_statements AS g_stats
ON pg_stats.userid = g_stats.user_id AND
pg_stats.dbid = g_stats.db_id AND
pg_stats.queryid = g_stats.query_id
WHERE columnar_unit_read > 0;
Le query SQL utilizzano automaticamente il Columnar Engine
quando l'ottimizzatore lo ritiene opportuno;
non e' necessaria nessuna modifica alle applicazioni o alle SELECT utilizzate.
Per verificare il piano d'esecuzione le query
possono essere analizzate con un normale EXPLAIN.
L'utilizzo del column store e' riportato con l'uso di
Custom Scan (columnar scan) o di
Parallel Custom Scan (columnar scan).
Come per gli altri algoritmi a disposizione dell'ottimizzatore
anche l'uso del Columnar Engine puo' essere disabilitato
agendo su un parametro di tuning con context user;
il parametro e'
google_columnar_engine.enable_columnar_scan ma in realta' vi sono una decina
di parametri utilizzabili per effettuare configurazione personalizzata.
Quando avvengono modifiche sulle colonne del column store
i dati vengono invalidati e debbono essere ricostruiti.
La colonna invalid_block_count della tabella g_columnar_relations
riporta in modo esplicito questa condizione.
Varie ed eventuali
Puo' essere interessante interessante il confronto del Columnar Engine di AlloyDB con database colonnari
(eg. Clickhouse)
ma a mio avviso e' ancora piu' significativo il confronto con
l'opzione Oracle Database In-Memory
o con SAP HANA.
Il documento
Your server stinks!
e' sempre aggiornato
sui rilasci delle release
PostgreSQL
e di
Cloud SQL.
Anche per AlloyDB e' stata raccola una breve
storia delle releases.