ClickHouse & Kafka
 ClickHouse (CH)
e' un Columnar Database, con interfaccia SQL, distribuito con prestazioni ottime
sulle attivita' OLAP (On-Line Analytical Processing) ed in grado di effettuare
caricamenti di grandi quantita' di dati.
ClickHouse (CH)
e' un Columnar Database, con interfaccia SQL, distribuito con prestazioni ottime
sulle attivita' OLAP (On-Line Analytical Processing) ed in grado di effettuare
caricamenti di grandi quantita' di dati.
ClickHouse e' un Open Source con licenza Apache 2.0 e tutte le funzionalita'
sono disponibili senza limitazioni.
CH e' un'economica ed efficiente alternativa per mantenere ed interrogare
velocemente grandi quantita' di dati.
Kafka e' un sistema di messaggistica fault tolerant e scalabile
in grado consegnare milioni di messaggi al secondo.
Kakfa e' diventato lo standard di fatto per lo scambio di informazioni
nel mondo Big Data.
Sono molti gli ambiti in cui Kafka e ClickHouse possono operare insieme.
In questa paginetta vediamo come.
Questo documento presenta gli aspetti dell'integrazione tra ClickHouse e Kafka:
ClickHouse ,
Kafka,
Primi passi,
Utilizzo,
Configurazione e tuning,
...
utilizzando un approccio pratico con esempi.
ClickHouse
ClickHouse utilizza un approccio differente rispetto
alla rappresentazione ISAM
e con indici B-Tree tipica dei DB relazionali
memorizzando i dati per colonna.
Questo consente di utilizzare algoritmi differenti nell'accesso ai dati
che possono essere eseguiti in parallelo.
Innanzi si utilizzano tutte le CPU sul nodo ospite,
ma e' possibile farlo anche in rete con piu' nodi.
Le query di ClickHouse in cluster scalano in modo pressoche' lineare come prestazioni.
L'interfaccia l'SQL rende facilmente utilizzabile ClickHouse a chiunque
conosca il linguaggio.
ClickHouse ha ottime prestazioni: e' migliaia di volte
piu' veloce nelle query OLAP rispetto ad un DB relazionale tradizionale.
ClickHouse non presenta la latenza tipica di alcuni DB NoSQL rispondendo
in modo quasi real time alle richieste OLAP.
Anche l'inserimento massivo di dati e' ottimizzato consentendo
il caricamento di milioni di record al secondo.
ClickHouse, oltre che come database per query analitiche,
grazie veloce ingestione di dati ed alla loro compressione,
puo' essere utilizzato efficacemente per mantenere e consolidare i dati.
Kafka
 Kafka e' un sistema di messaggistica sviluppato inizialmente da LinkedIn
e quindi mantenuto come progetto Open Source da Apache [NdA 2012-10].
Il codice e' principalmente scritto in Scala,
un moderno linguaggio ad oggetti
che viene compilato in bytecode Java.
Kafka e' un sistema di messaggistica sviluppato inizialmente da LinkedIn
e quindi mantenuto come progetto Open Source da Apache [NdA 2012-10].
Il codice e' principalmente scritto in Scala,
un moderno linguaggio ad oggetti
che viene compilato in bytecode Java.
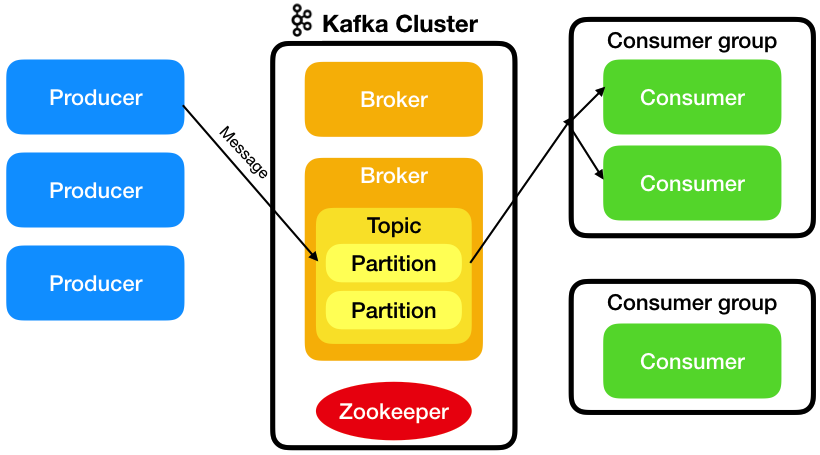
Kafka e' distribuito, partizionato, fault-tolerant e puo' scalare per gestire milioni di messaggi al secondo.
Un Kafka cluster e' costituito da piu' Broker, riceve i messaggi dai Producer
e li consegna ai Consumer.
I messaggi sono raggruppati in categorie chiamate Topic. Un Topic puo' essere costituito
da una o piu' Partition che vengono elaborate in parallelo da broker diversi, eventualmente
su server differenti. Le partizioni possono essere replicate per fornire l'HA.
Per ogni partizioni replicata viene eletto un leader mentre gli altri broker sono follower.
Per l'elezione del leader viene utilizzato Zookeeper.
I consumer sono raggruppati in Consumer Group che possono avere due politiche di consegna:
- Publish-Subscribe System: i messaggi arrivano a tutti i Consumer del Consumer Group
- Queue System: i messaggi vengono raccolti dal primo Consumer che li raccoglie
Kafka garantisce che nessun messaggio venga perso e che i messaggi vengano consegnati
nello stesso ordine con cui sono stati inseriti (per topic/partizione o commit log).
Kafka viene utilizzato in diversi contesti; tra gli altri:
Stream Processing, Metrics, Log Aggregation.
Primi passi
ClickHouse dispone di un
Engine Kafka
che integra l'accesso al sistema di messaggistica.
Per utilizzare Kafka ClickHouse bastano... semplici comandi SQL!
Per creare utilizzare l'Engine Kafka la sintassi e':
CREATE TABLE table_name (
...
) Engine = Kafka()
SETTINGS
kafka_broker_list = 'host:port',
kafka_topic_list = 'topic1,topic2,...',
kafka_group_name = 'group_name',
kafka_format = 'data_format'[,]
[kafka_row_delimiter = 'delimiter_symbol',]
[kafka_schema = '',]
[kafka_num_consumers = N,]
[kafka_skip_broken_messages = N]
Tutto qui?
Ora basta leggere dalla tabella per consumare i messaggi provenienti da Kafka:
CREATE TABLE iot_queue (
time_ref DateTime,
sensor String,
metric String,
measure Float64
) ENGINE = Kafka('localhost:9092', 'topic1', 'group1')
SETTINGS
kafka_format = 'JSONEachRow',
kafka_num_consumers = 1,
kafka_row_delimiter = '\n',
kafka_skip_broken_messages = 1;
SELECT * FROM iot_queue;
Gia' fatto?!
Si!
La DDL crea una tabella con Engine Kafka accedendo ad un cluster locale (le porte di Kafka di default sono 9092 e 9093 per l'SSL).
Con la select si consumano i dati inviati sul topic1.
Importante e' la definizione del consumer group che consente di operare in parallelo o in HA.
Ma questa era solo una prova...
Utilizzo
Funziona gia' tutto ma
in realta' l'utilizzo di una SELECT per leggere i dati da Kafka,
se non per effettuare verifiche puntuali sui dati,
non e' la modalita' ottimale...
Una funzionalita' molto importante di ClickHouse, che puo' essere sfruttata in questo caso,
e' quella delle Materialized View.
 L'idea di base e' molto semplice: la tabella creata con l'Engine Kafka raccoglie i dati
che vengono automaticamente letti da una Materialized View che li appoggia su una normale tabella
Merge Tree.
Ecco i comandi per creare la MV agganciata alla tabelle Kafka creata in precedenza:
L'idea di base e' molto semplice: la tabella creata con l'Engine Kafka raccoglie i dati
che vengono automaticamente letti da una Materialized View che li appoggia su una normale tabella
Merge Tree.
Ecco i comandi per creare la MV agganciata alla tabelle Kafka creata in precedenza:
CREATE TABLE iot_storage (
time_ref DateTime Codec(DoubleDelta, LZ4),
sensor String,
metric String,
measure Float64 Codec(T64, LZ4)
) ENGINE = MergeTree
PARTITION BY toYYYYMM(time_ref);
CREATE MATERIALIZED VIEW iot_mv TO iot_storage
AS SELECT *
FROM iot_queue;
La Storage Table fornisce mantiene in modo persistente i dati provenienti da Kafka,
come tutte le tabelle CH verra' partizionata e conterra' dati fortemente compressi,
potra' avere un TTL, ...
Sulla stessa tabella Kafka possono essere definite piu' materialized view,
ciascuna con il livello di dettaglio desiderato, che vengono aggiornate
automaticamente via via che i dati sono raccolti dalla tabella Consumer.
CREATE MATERIALIZED VIEW daily_stat
AS SELECT toDate(toDateTime(timestamp)) AS day, sensor, metric,
avgState(measure) as avg_measure, countState(*) as total
FROM iot_queue GROUP BY day, sensor, metric;
SELECT sensor, sumMerge(total) FROM daily_stat GROUP BY sensor;
Dal punto di vista di Kafka il contenuto dei messaggi e' completamente libero.
CH pero' deve raccogliere il messaggio in una struttura tabellare,
quindi il formato dei messaggi ha molta importanza.
Come formati CH accetta tutti i formati di INPUT
accettati dalla INSERT.
L'elenco ufficiale
li riporta tutti... tra i principali:
TabSeparated,
TabSeparatedWithNames,
CSV,
CSVWithNames,
JSONEachRow,
Parquet,
...
L'Engine CH e' molto veloce ed una tabella con un singolo Consumer e' adatta
alla maggioranza dei carichi.
Nella definizione della tabella kafka e' possibile utilizzare un numero superiore di Consumer,
utilizzando il relativo
parametro. E' pero' importante non superare il numero di partizioni definite sul Topic.
Se si utilizza un cluster e si vuole parallelizzare la raccolta dei messaggi da Kafka,
e' sufficiente definire lo stesso Consumer Group sulle tabelle Kafka ed una tabella distribuita
come base table; anche in questo caso non deve essere superato il numero di partizioni
del Topic altrimenti i Consumer potrebbero bloccarsi.
La materialized view utilizzata per leggere i messaggi dalla tabella su Engine Kafka
bufferizza i messaggi per rendere piu' efficiente l'inserimento dei dati.
Questo genera un leggero ritardo ma e' inevitabile ed e' lo stesso di quando vengono
eseguite INSERT singole.
Dalla versione 19.14 sono disponibili, per l'Engine Kafka,
le seguenti colonne virtuali:
- _topic — Kafka topic
- _key — Key of the message
- _offset — Offset of the message
- _timestamp — Timestamp of the message
- _partition — Partition of Kafka topic
Ecco come sfruttare le nuove colonne per controllare il lag dei caricamenti con Kafka:
CREATE MATERIALIZED VIEW kafka_mv TO kafka_store_tab
(
`timestamp_k` DateTime,
`timestamp_ch` DateTime,
`timestamp` DateTime,
`Device_ID` String,
...
) AS
SELECT
_timestamp AS timestamp_k,
now() AS timestamp_ch,
Timestamp,
Device_ID,
...
FROM kafka_engine_tab;
SELECT
timestamp as t,
avg(timestamp_ch-timestamp_k) KafkaLAG,
avg(timestamp_ch-Collection_Date_Time) DataLAG
FROM kafka_store_tab
-- WHERE condition if needed
GROUP BY t
ORDER BY t;
Configurazione
L'Engine Kafka e' implementato utilizzando la libreria
librdkafka che e' la libreria C/C++ Apache Kafka di riferimento
[NdA la versione piu' recente della libreria e' la 1.1 ed e' utilizzata
dalla versione 19.11.3.11 del 2019-07 di ClickHouse].
Oltre ai parametri disponibili al momento della creazione delle tabelle
e' possibile impostare una serie di impostazioni di configurazione di dettaglio.
Come e' noto il file di configurazione di ClickHouse e' /etc/clickhouse-server/config.xml
ed e' utilizzato anche per configurare l'Engine Kafka.
Sono disponibili due tipologie di parametri con il prefisso:
kafka, relativi alle impostazioni globali, e kafka_topic,
relativi ai topic.
L'elenco completo dei parametri e' pubblicato su
documentazione della libreria librdkafka.
La configurazione si effettua nel solito file config.xml
ma generalmente le impostazioni di default sono gia' adeguate.
La configurazione e' invece necessaria
se viene utilizzato l'SSL o vanno impostati dimensioni differenti dei messaggi.
Nel seguito un esempio per configurare il debug (che invia tutti i messaggi nel file stderr.log):
<yandex>
...
<kafka>
<debug>all</debug>
</kafka>
...
</yandex>
L'attivazione del debug produce un output significativo...
va utilizzata lo stretto tempo necessario a verificare i problemi.
Questo documento non entra nei dettagli della configurazione dei broker Kafka...
tuttavia qualche elemento puo' essere comunque utile!
Per consumare in parallelo dallo stesso topic e' necessario
definire un numero sufficiente di partizioni:
tipicamente il doppio del numero di consumer.
In ogni caso il numero dei consumer in un consumer group non deve superare il numero di partizioni.
Su ClickHouse e' opportuno mantenere il parametro kafka_num_consumers=1
e, se e' realmente necessario parallelizzare le operazioni,
definire piu' tabelle con Engine Kafka sullo stesso consumer group
(sullo stesso nodo o su nodi differenti in cluster con Engine Distribuited).
Se il numero di tabelle con Engine=Kafka e' elevato e' possibile che il
background_schedule_pool_size non sia adeguato [NdA il default e' 16],
la verifica si effettua monitorando il valore della metrica BackgroundSchedulePoolTask.
Per una configurazione in HA di Kafka e' necessario disporre di almeno 3 broker
con repl.factor=3 e min.insync.replicas=2.
E' possibile scalare aumentando il numero di broker kafka.
Come e' noto una configurazione Kafka richiede ZooKeeper;
per una configurazione in HA e' necessario un cluster (ensemble) di 3 nodi ZooKeeper.
Con 3 nodi si sopporta la caduta di un nodo, con 5 nodi possono essere fuori linea fino a due nodi.
Piu' nodi sono presenti nel cluster Zookeeper piu' rallenta.
Zookeeper richiede poca latenza quindi generalmente si installa su server dedicati
o che operano con servizi con poco carico.
Per una configurazione in replica o (XOR) in sharding di Clickhouse sono sufficienti due nodi.
Clickhouse utilizza ZooKeeper solo per la replica; lo Zookeeper utilizzato da Kafka e da Clickhouse
puo' essere lo stesso (tipicamente Zookeeper e' utilizzato da piu' servizi).
Come base table per le materialized view su Kafka possono essere utilizzate
normali tabelle MergeTree o anche tabelle Distribuited.
Quando sono presenti piu' ambienti puo' essere utile utilizzare le macro per rendere
parametrica la definizione delle tabelle con Engine Kafka
[NdA nell'esempio e' utilizzata la sintassi valida dalla 19.14 che e' piu' esplicativa]:
...
ENGINE = Kafka()
SETTINGS kafka_broker_list = '{kafka_cluster}',
kafka_topic_list = '{env}.TOPIC_I',
kafka_group_name = '{replica}.CONSUMER_G',
kafka_format = 'CSV',
kafka_num_consumers = 1,
kafka_skip_broken_messages = 1;
Lo skip dei messaggi con formato errato ha un comportamento un poco particolare
ed il numero di consumer non va aumentato [NdA comunque il thread per il trattamento dei messaggi e' solo uno]...
piuttosto puo' essere utile effettuare il tuning dei parametri background_pool_size e background_schedule_pool_size
ma sono dettagli che possono cambiare in release successive.
Varie ed eventuali
ClickHouse e' un database colonnare Open Source sviluppato da Yandex, con sorgenti su
Github
dal 2016 distribuito con una licenza molto libera:
Apache License 2.0.
Ovviamente anche Apache Kafka e' fornito con la licenza Apache.
La documentazione ufficiale ClickHouse sull'Engine Kafka si trova a
questo link
e consiglio anche questa pagina,
scritta da chi mantiene il software:
ClickHouse Kafka FAQ.
L'engine Kafka su ClickHouse e' disponibile dal 2017-11:
v. 1.1.54310
e viene continuamente aggiornato:
multiple topics, custom separators, SETTINGS, background thread,
librdkafka 1.1, virtual columns, INSERT support (producer), atomic insert, ...
In alcune versioni di ClickHouse l'Engine Kafka presentava problemi
[NdA dalla 19.11.3.11 del 2019-07-18 alla 19.11.5.28 del 2019-08-05],
basta utilizzare la versione 19.11.7.40, meglio ancora 19.14.3.3 o successive.
Tra gli sviluppi futuri dell'Engine Kafka sono attesi:
il supporto del formato Avro (molto usato con Kafka perche' dinamico),
l'eliminazione di eventuali duplicati dovuti al rebalancing Kafka,
ulteriori metriche per il monitoraggio,
una gestione piu' efficiente del consuming,
MV atomiche, ...
eventuali altri sistemi di messaggistica (eg. MQTT)
oltre a Kafka !
Altri documenti su ClickHouse sono
Introduzione a ClickHouse,
Materialized views,
DBA scripts ed
Architettura ClickHouse.
Un'introduzione a Kafka (su MacOS) si trova in questo documento,
in realta' ci sono documenti molto migliori ma il link proposto e' in italiano e poi...
l'ho scritto io!