Kafka su MacOS X
Kafka e' un potente sistema Open Source per lo scambio di messaggi tra applicazioni
ed ambienti.
In questo documento vediamo come installare ed utilizzare Kafka su MacOS.
Tipicamente le installazioni di produzione di Kafka si effettuano in cluster
e su sistemi Linux...
ma perche' non provarlo su Mac?
Naturalmente i contenuti del documento valgono in generale anche per altri ambienti
ospite [NdA mutatis mutandis, in particolare sulla parte di installazione].
Kafka
 Kafka e' un sistema di messaggistica sviluppato inizialmente da LinkedIn
e quindi mantenuto come progetto Open Source da Apache [NdA 2012-10].
Il codice e' principalmente scritto in Scala,
un moderno linguaggio ad oggetti che viene compilato in bytecode Java.
Molti dei tool per Kafka sono invece scritti in Java;
sono comunque disponibili librerie per i principali linguaggi di programmazione
(eg. la libreria librdkafka per C/C++).
Kafka e' un sistema di messaggistica sviluppato inizialmente da LinkedIn
e quindi mantenuto come progetto Open Source da Apache [NdA 2012-10].
Il codice e' principalmente scritto in Scala,
un moderno linguaggio ad oggetti che viene compilato in bytecode Java.
Molti dei tool per Kafka sono invece scritti in Java;
sono comunque disponibili librerie per i principali linguaggi di programmazione
(eg. la libreria librdkafka per C/C++).
Dal punto di vista tecnico
Producer e Consumer utilizzano solo una porta socket per connetersi a Kafka: 9092 (per default).
In realta' le porte possibili sono le seguenti (sono indicati i default):
- 9092: kafka default port
- 9093: kafka SSL listeners
- 2181 : zookeeper client connection
- 2888 : zookeeper follower connection
- 3888 : zookeeper inter nodes connection
I messaggi sono salvati come semplici file sul file system ospite dei Broker
mentre Kafka mantiene complesse liste di puntatori per gestire
in modo efficiente tutte le trasmissioni.
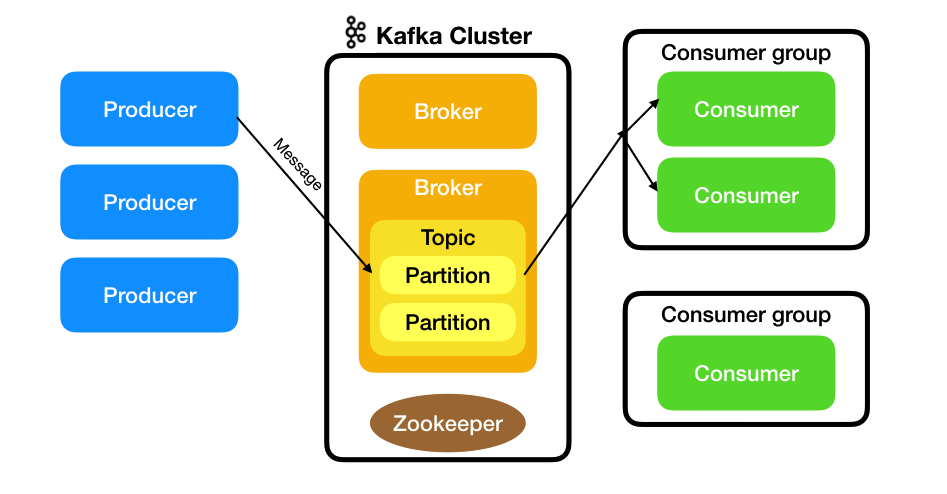 Un Kafka cluster e' costituito da piu' Broker, riceve i messaggi dai Producer
e li consegna ai Consumer.
Un Kafka cluster e' costituito da piu' Broker, riceve i messaggi dai Producer
e li consegna ai Consumer.
I messaggi sono raggruppati in categorie chiamate Topic. Un Topic puo' essere costituito
da una o piu' Partition che vengono elaborate in parallelo da broker diversi, eventualmente
su server differenti.
Le Partition, chiamate anche commit log, mantengono per la retention prevista i
messaggi inviati dai Producers che vengono accodati.
I Consumer raccolgono i messaggi in modo ordinato e ciascuno in modo indipendente.
Le partizioni possono essere replicate su broker differenti per fornire l'HA.
Per ogni partizione replicata viene eletto un leader mentre gli altri broker sono follower.
Per l'elezione del leader viene utilizzato Zookeeper.
I sistemi di code hanno tipicamente due modelli alternativi:
- Publish-Subscribe System: i messaggi arrivano a tutti in parallelo
- Queue System: i messaggi vengono raccolti in ordine
Il limite dei queue system e' che la configurazione e' in alternativa...
In Kafka i consumer sono raggruppati in Consumer Group permettendo cosi'
di applicare sullo stesso topic sia l'elaborazione parallela suddividendo i messaggi
che la raccolta da parte di piu' applicazioni.
Kafka garantisce che nessun messaggio venga perso e che i messaggi vengano consegnati
nello stesso ordine con cui sono stati inseriti (per topic/partizione o commit log).
Kafka e' distribuito, partizionato, fault-tolerant
e puo' scalare per gestire milioni di messaggi al secondo in architetture complesse.
Kafka viene utilizzato in diversi contesti; tra gli altri:
Stream Processing, Metrics, Log Aggregation.
Installazione e configurazione
Il primo componente da installare e' lo Zookeeper.
Con Homebrew e' banale:
brew install zookeeper
Ora tocca a Kafka:
brew install kafka
Homebrew installa l'ultima versione di ogni componente...
Per attivare i servizi:
brew services start zookeeper
brew services start kafka
Il file di configurazione di Zookeeper e' /usr/local/etc/zookeeper/zoo.cfg
mentre la directory di configurazione di Kafka e' /usr/local/etc/kafka.
I parametri presenti ed i default consentono di operare senza problemi...
E' evidente che la configurazione su macOS e' davvero semplice... ma su gli altri sistemi?
Non e' molto piu' complessa: basta seguire quanto riportato sulla
documentazione ufficiale!
Zookeeper utilizza per default la porta 2181;
e' possibile utilizzare il client zkCli per controllarne lo stato
con semplici comandi (eg. help, ls /, ls /brokers/topics, ).
E' anche possibile connettersi direttamente alla porta socket come fanno
i seugenti controlli:
echo stat | nc localhost 2181
echo mntr | nc localhost 2181
echo isro | nc localhost 2181
Il broker Kafka utilizza per default la porta 9092, per controllare
se funziona... lo si puo' chiedere a Zookeeper con:
echo dump | nc localhost 2181 | grep brokers
In effetti e' piu' diretto il controllo seguente:
kafka-topics --bootstrap-server localhost:9092 --list
Per creare i topic... continuate a leggere!
Topic
Il Topic e' un concetto fondamentale su Kafka perche'
l'invio e la ricezione dei messaggi sono sempre relativi ad un Topic.
Con Kafka, oltre al server che si occupa della gestione dei messaggi,
sono presenti una serie di comandi di utilita' tra cui kafka-topics
che consente di gestire i topics:
kafka-topics --bootstrap-server localhost:9092 --create --replication-factor 1 --partitions 1 --topic Dimmelo
kafka-topics --bootstrap-server localhost:9092 --list
kafka-topics --bootstrap-server localhost:9092 --alter --partitions 2 --topic Dimmelo
In questo modo abbiamo creato un Topic "Dimmelo" e lo abbiamo configurato con 2 partizioni.
Siamo pronti a trasmettere!
Per fare questo utilizziamo i tool kafka-console-producer e kafka-console-consumer:
|
$ kafka-console-producer --broker-list localhost:9092 --topic Dimmelo
>Primo messaggio
>Secondo
>Ora finisco con ^D
>^D
$ kafka-console-producer --broker-list localhost:9092 --topic Dimmelo
>Eccomi di nuovo!!!
|
$ kafka-console-consumer --bootstrap-server localhost:9092 --topic Dimmelo
Primo messaggio
Secondo
Ora finisco con ^D
Eccomi di nuovo!!!
|
Abbiamo utilizzato due sessioni ma e' possibile utilizzarne a piacere...
ogni messaggio pubblicato da un Publisher verra' ricevuto da tutti i Consumer attivi.
Entrambe i comandi hanno piu' opzioni... sicuramente interessanti sono
--partion per indicare la partizione,
--from-beginning per indicare l'offset,
e --offset per indicare la posizione del messaggio.
Per default l'offset e' latest quindi il consumer si mette in coda e legge i nuovi messaggi,
ma e' anche possibile indicare earliest che consente di leggere dal primo messaggio
del Topic (ovviamente che non sia ancora stato cancellato).
Oltre ai topic creati dagli amministratori o dalle applicazioni
ve ne sono alcuni "interni":
- __consumer_offsets: mantiene le informazioni sugli offset di ciscun topic;
viene periodicamente compresso [NdA e' presente dalla 0.9, in precedenza l'informazione era mantenuta su Zookeeper].
- _schema: per la gestione degli schema Avro [NdA teoricamente questo non e' di Kafka ma di Confluent].
HA
Questo capitolo e' solo introduttivo poiche' i concetti e le tecniche
per l'HA (High Availability) e la scalabilita' sono impegnativi...
ma speriamo di riuscire a fornire indicazioni sufficienti ad orizzontarsi.
Kafka nasce come strumento distribuito per garantire l'alta affidabilita' e la scalabilita':
la configurazione standalone e' un caso particolare
del caso piu' generale della configurazione in cluster.
Per il mantenimento della configurazione e la replica Kafka utilizza ZooKepeer,
quindi vediamo le caratteristiche di entrambe i cluster.
Un cluster ZooKeeper e' chiamato Ensemble.
E' consigliabile utilizzare un numero dispari di nodi
in modo che il raggiungimento del Quorum non presenti ambiguita' e rischi di split brain.
Con tre nodi si sopporta la caduta di un nodo, con cinque nodi sono due i nodi che possono essere offline.
In una configurazione di produzione il minimo e' 3 nodi,
sono consigliati 5 nodi se si vuole l'alta affidabilita'
anche durante attivita' di manutenzione ed upgrade.
E' sconsigliato utilizzare piu' di 7 nodi
per evitare rallentamenti dovuti al protocollo di consenso (ZAB).
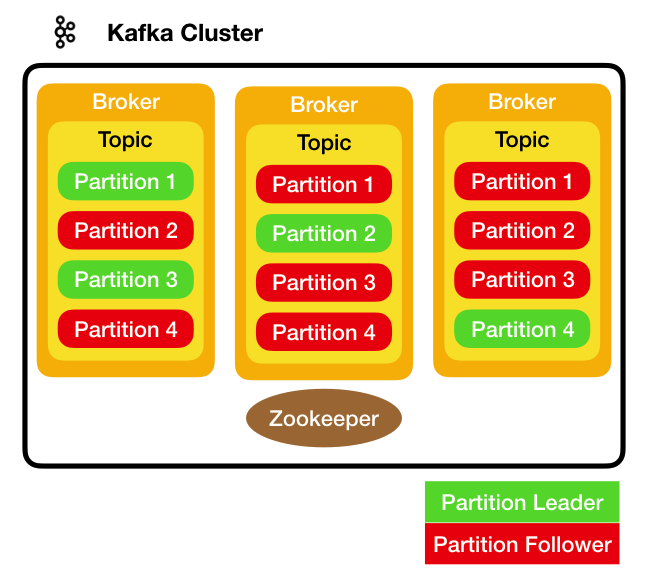 Un cluster Kafka e' costituito da Broker attivi su nodi differenti
[NdA i broker possono essere attivati anche sullo stesso nodo utilizzando porte socket differenti
ma in questo caso ovviamente non forniscono nessun vantaggio da punto della disponibilita' del servizio].
Ogni partizione puo' essere replicata su N Broker, il Topic resta fruibile purche' ne resti almeno 1 attivo,
ovvero e' possibile sopportare la caduta di N-1 nodi.
Il numero di nodi di un Cluster Kafka dipende dal carico e non ha vincoli particolari.
Kafka supporta anche configurazioni con repliche remote ad esempio tra CED differenti.
Un cluster Kafka e' costituito da Broker attivi su nodi differenti
[NdA i broker possono essere attivati anche sullo stesso nodo utilizzando porte socket differenti
ma in questo caso ovviamente non forniscono nessun vantaggio da punto della disponibilita' del servizio].
Ogni partizione puo' essere replicata su N Broker, il Topic resta fruibile purche' ne resti almeno 1 attivo,
ovvero e' possibile sopportare la caduta di N-1 nodi.
Il numero di nodi di un Cluster Kafka dipende dal carico e non ha vincoli particolari.
Kafka supporta anche configurazioni con repliche remote ad esempio tra CED differenti.
Per ogni partizione Kafka sceglie un Broker Leader che gestisce tutte le scritture e le letture;
tutti gli altri Broker sono Follower e replicano i dati per garantire l'alta affidabilita'.
Quando una replica e' allineata viene detta ISR (in-sync replica); i caso di caduta del nodo
che ospita il broker leader di una partizione il nuovo leader verra' scelto tra le ISR.
E' molto importante sottolineare che su un Topic possono essere definite piu' partizioni,
in questo modo i Broker Leader sono su nodi diversi distribuendo cosi' il carico di lettura
e scrittura dei messaggi.
Nella figura a destra sono rappresentati 3 Broker ed il primo risulta Leader per le partizioni
1 e 3...
Tutti i Producer ed i Consumer effettuano gli accessi sulla partizione Leader
mentre le partizioni Follower vengono semplicemente mantenute allineate.
Nelle configurazione piu' semplici ZooKeeper e Kafka possono utilizzare gli stessi nodi,
ma nelle configurazione complesse sono presenti altri componenti ed il numero di nodi sale...
Basta parole, vediamo un esempio!
Per provare su Mac una configurazione con piu' Broker dobbiamo preparare un nuovo file di configurazione.
Possiamo fare cosi:
cp /usr/local/etc/kafka/server.properties /usr/local/etc/kafka/server-two.properties
vi /usr/local/etc/kafka/server-two.properties
I parametri che e' importante modificare sono:
broker.id=2
log.dirs=/usr/local/var/lib/kafka-logs-2
listeners=PLAINTEXT://:9093
Avviamo il nuovo Broker con:
kafka-server-start /usr/local/etc/kafka/server-two.properties
Ed ora possiamo riprendere a giocare con i messaggi!
Utile in questo caso e' utilizzare il parametro --replication-factor 2
al momento della creazione del topic con kafka-topics.
Ovviamente e' possibile attivare piu' Broker e controllare il funzionamento
avviando e bloccando i processi.
Perche' i producer ed i consumer sfruttino l'HA e' necessario che li indirizzino correttamente
con l'opzione:
--broker-list localhost:9092,localhost:9093
Varie ed eventuali
Questa paginetta e' introduttiva e non presenta molti degli importanti aspetti di Kafka...
sicuramente da citare sono
le configurazioni dei listener (con impatti sul networking),
la retention dei messaggi (con forti impatti sullo storage e le prestazioni),
il formato dei messaggi (eg. schema registry),
la programmazione (perche' tipicamente i messaggi sono inviati da applicazioni)
e, non da ultimo, gli aspetti sulla sicurezza.
A volte c'e' qualche simpatico problema con
Java su Mac, ma si risolvono tutti!
Sull'installazione di Java con l'OpenJDK su Mac vi sono alcune indicazioni in
questo documento.
Le versioni di Kafka e di ZooKepeer utilizzate in questo documento sono
rispettivamente la 2.3 e 3.4...
quale riferimento sulle versioni di Kafka potete utilizzare la seguente tabella
estratta da questo fantastico documento
(Sources: Downloads
Wikipedia
):
| Version |
Status |
Features |
Last release |
Date (from) |
Date (last) |
Notes |
| 3 | Production
| Self-managed quorum (based on Raft protocol), stronger delivery guarantees for the Kafka producer,
optimizations in OffsetFetch and FindCoordinator.
Deprecation: Java 8, Scala 2.12, message formats v0 and v1.
(3.1.0 2022-01): Topic ID in FetchRequest, latency in mills and nanos, SASL/OAUTHBEARER with support for OIDC, Java 17 support
Deprecation: eager rebalance protocol
| 3.1.0 | 2021-09 | 2022-01 |
|
| 2 | Production
| ACL, Quota management; Java 7 desupport
(2.5 2020-04): TLS 1.3 support, TLS 1.2 as default, more metrics, ZooKeeper 3.5.7; Scala 2.11 desupport
(2.6 2020-08): TLS 1.3 default for Java 11, ZooKeeper 3.5.8, scaling out of Kafka Streams
(2.7 2020-12): Configurable TCP connection timeout, Throttle topic operations, Sliding-Window for Aggregations
(2.8 2021-04): Self-managed quorum, broker creation rate limit, describe cluster API
| 2.8.1 | 2018-07 | 2021-09 |
|
| 1 | EOL
| Scala 2.11 and 2.12, Java 9 support, more metrics, improved stream API, ...
| 1.1.1 | 2017-11 | 2018-07 |
|
| 0 | EOL |
(0.7 2012-01): Apache incubator first release
(0.9 2015-11): Connect API; Scala 2.9 desupport
(0.10 2016-05): Streams API, brokers forward compatible
| 0.11.3 | 2010-11 | 2018-07 |
|
Kafka e' presente in tutte le distribuzioni Hadoop
quale sistema di messaggistica (eg. Hortonworks).
Oracle fornisce un handler Kafka Connect nella suite Oracle GoldenGate for Big Data.
Un Kafka consumer e' integrato nel database colonnare ClickHouse.
I principali RDBMS possono essere integrati con Kafka Connect, Debezium
[NdA nell'attuale versione 0.9 sono supportati MySQL, PostgreSQL e MongoDB], JDBC Sink, ...
Le persone che hanno sviluppato inizialmente il software in LinkedIn hanno poi creato
la societa' Confluent.
Confluent e' uno dei principali contributori di Kafka e fornisce una piattaforma integrata
con tool aggiuntivi.
Un altro protocollo di messaging molto diffuso e'
MQTT.
Ha meno funzionalita' di Kafka ma e' piu' semplice ed ha requisiti veramente
minimi quindi e' molto utilizzato per l'IoT (Internet of Things).