

ClickHouse
e' un Columnar Database SQL, distribuito ed Open Source con ottime prestazioni
sulle attivita' OLAP (On-Line Analytical Processing).
In questa paginetta ne vediamo l'architettura,
le integrazioni con altri strumenti e le configurazioni piu' complesse.
ClickHouse e' di semplice installazione, gestione ed utilizzo (SQL).
Anche se di recente introduzione ha raggiunto ultimamente
una buona maturita' e completezza funzionale per essere
utilizzato in ambienti di produzione.
Gli argomenti contenuti in questa pagina sono:
Architettura,
Amministrazione,
Database Design,
Integrazioni (MySQL, Kafka, JDBC, ODBC, ProxySQL, Grafana, ...),
Cluster: replica e sharding,
Benchmark,
Versioni ed aggiornamenti,
...
Nel documento Introduzione a ClickHouse
si trovano invece gli aspetti base quali l'installazione,
e le Query OLAP
utilizzando un approccio pratico con esempi di query SQL.
Il documento si riferisce alla versione 19.4 di ClickHouse
ma i contenuti valgono anche per altre versioni.
La tipica applicazione dei database relazionali e' su ambienti OLTP (OnLine Transaction Processing)
in cui la velocita' di esecuzione e la gestione delle transazioni sono gli elementi caratteristici.
In questo i database relazionali, utilizzati con il linguaggio SQL,
sono da anni la tecnologia piu' utilizzata per gli OLTP.
La rappresentazione tabellare dei dati e gli indici
sono molto efficienti per accedere ai record da selezionare/modificare nelle transazioni.
Quando pero' e' necessario analizzare basi dati di grandi dimensioni
in modo completo i tempi si allungano e passano dai millisecondi ai secondi ed alle ore per
le elaborazioni piu' complesse.
Con il termine OLAP (On-Line Analytical Processing)
si indicano tecniche ed architetture adatte ad analizzare
grandi basi dati in tempi molto brevi.
ClickHouse e' il recente database colonnare sviluppato da Yandex
[NdA Yandex e' il piu' importante motore di ricerca russo]
adatto alle attivita' OLAP.
ClickHouse utilizza un approccio differente rispetto
alla rappresentazione ISAM
e con indici B-Tree tipica dei DB relazionali
memorizzando i dati per colonna.
Questo consente di utilizzare algoritmi per l'accesso ai dati
che possono essere eseguiti in parallelo.
Con ClickHouse si utilizzano tutte le CPU sul nodo ospite,
ma e' possibile farlo anche in rete con piu' nodi.
Le query di ClickHouse in cluster scalano in modo pressoche' lineare come prestazioni.
L'installazione si esegue con un paio di comandi e praticamente non c'e' bisogno di configurazione e di tuning. L'interfaccia l'SQL rende facilmente utilizzabile ClickHouse a chiunque.
Infine le prestazioni: come altri DB column-oriented ClickHouse e' migliaia di volte piu' veloce nelle query OLAP rispetto ad un DB relazionale tradizionale. ClickHouse non presenta la latenza di altri DB NoSQL rispondendo in modo quasi real time alle richieste.
Riassumendo ClickHouse trova la sua applicazione sia quando siano necessarie ottime prestazioni con query analitiche, grazie alle sue prestazioni quasi realtime, sia quando sia necessario mantenere grandi quantita' di dati, grazie alla notevole velocita' nell'ingestion ed alla compressione dei dati.
ClickHouse (CH) e' un database
column-oriented.
Questo significa che i dati non sono organizzati per righe,
come avviene per tutti i database relazionali tradizionali;
i dati sono memorizzati su un file per ogni colonna,
organizzati come in un indice e compressi.
ClickHouse partiziona automaticamente i dati per chiave primaria.
Il partizionamento di default e' sul tempo con bucket di un mese.
Oltre all'organizzazione per colonne alla compressione ed al partizionamento ClickHouse utilizza algoritmi di calcolo parallelo [NdA ritengo che CH utilizzi il set d'istruzioni Streaming SIMD Extensions SSE 4.2 per Vectorizing compiling].
Quando si effettua una query ClickHouse suddivide il lavoro in piu' thread ed effettua le operazioni in memoria utilizzando tutte le CPU e tutta la RAM disponibili. Questo rende incredibilmente piu' veloci le ricerche rispetto ad un DB tradizionale sopratutto quando vanno analizzati tutti i dati.
|
|
|
 I datatype disponibili in ClickHouse sono stati scelti per ottenere le massime prestazioni.
Piu' i dati sono compatti e migliori sono le prestazioni: va sempre scelto
il tipo di dato piu' adatto e di minori dimensioni.
Per i valori numerici:
UInt8, UInt16, UInt32, UInt64, Int8, Int16, Int32, Int64,
Float32, Float64,
Decimal e
Boolean.
Per le stringhe si usa praticamente un solo datatype:
String in qualche caso puo' essere utile anche il
FixedString(N). CH non gestisce l'encoding e le stringhe sono semplicemente una serie di byte...
Per le date:
Date,
DateTime.
Molto efficiente e' il datatype Enum che pero' richiede definire nella DDL
tutti i valori possibili.
I datatype disponibili in ClickHouse sono stati scelti per ottenere le massime prestazioni.
Piu' i dati sono compatti e migliori sono le prestazioni: va sempre scelto
il tipo di dato piu' adatto e di minori dimensioni.
Per i valori numerici:
UInt8, UInt16, UInt32, UInt64, Int8, Int16, Int32, Int64,
Float32, Float64,
Decimal e
Boolean.
Per le stringhe si usa praticamente un solo datatype:
String in qualche caso puo' essere utile anche il
FixedString(N). CH non gestisce l'encoding e le stringhe sono semplicemente una serie di byte...
Per le date:
Date,
DateTime.
Molto efficiente e' il datatype Enum che pero' richiede definire nella DDL
tutti i valori possibili.
Poiche' i dati sono raggruppati per colonna e quindi molto omogenei,
ClickHouse e' in grado di comprimere efficacemente anche i dati numerici.
La compressione dati e' molto utile anche per minimizzare lo spazio
occupato: una base dati ClickHouse e' tipicamente molto piu' piccola del DB di origine.
ClickHouse e' costituito da un solo processo clickhouse-server, avviato con systemd, che gira
come utente clickhouse.
Internamente sono presenti decine di thread che operano in modo indipendente.
Le porte socket utilizzate sono 3:
ClickHouse puo' essere utilizzato su server singolo (e' disponibile anche come immagine Docker
su container) oppure configurato in cluster con shards e/o repliche.
Grazie alla particolare struttura di memorizzazione dei dati
le query eseguite in cluster scalano le prestazioni in modo lineare
sul numero di shard utilizzati.
Le repliche sono di tipo asincrono ed aggiornate in modalita' multimaster.
La replica opera a livello di singola tabella ed e' indipendente dallo sharding.
Per la gestione dei nodi e' previsto l'utilizzo di ZooKeeper, che e' fortemente consigliato
quando il numero di nodi e' elevato e si utilizzano le repliche
[NdA ZooKeeper non e' obbligatorio per lo sharding ma lo e' per creare le repliche].
ZooKeeper va posto su un nodo differente da quelli di ClickHouse poiche' necessita di una bassa latenza e CH
tende ad monopolizzare i server quando eseguono le query.
Un cluster ClickHouse non e' elastico e vanno riconfigurate le tabelle per ridistribuire gli shard
all'inserimento di un nuovo nodo.
Per ogni tabella e' possibile scegliere un tipo di memorizzazione
dei dati: l'Engine.
Vi sono diverse tipologie di Engine, il piu' importante e' il MergeTree
ed i suoi derivati. Con il MergeTree i dati sono ordinati per Primary Key e
viene eseguito il pruning delle query sulla partitioning key.
In fase di inserimento i dati vengono scritti velocemente in parti
e quindi uniti (merge) successivamente da un thread asincrono.
La replica e' configurata utilizzando gli Engine della famiglia MergeTree:
ReplicatedMergeTree,
ReplicatedSummingMergeTree,
ReplicatedReplacingMergeTree,
ReplicatedAggregatingMergeTree,
ReplicatedCollapsingMergeTree,
ReplicatedVersionedCollapsingMergeTree,
ReplicatedGraphiteMergeTree.
Si differenziano per la gestione dei dati gli Engine:
ReplacingMergeTree,
SummingMergeTree,
AggregatingMergeTree,
CollapsingMergeTree,
VersionedCollapsingMergeTree,
GraphiteMergeTree.
Tra gli altri Engine e' importante la familia dei Log
(StripeLog,
Log,
TinyLog),
l'Engine MEMORY,
DICTIONARY,
FILE,
...
Molti sono gli Engine speciali per accedere a dati esterni (eg. File, URL),
per eseguire JOIN in memoria, ...
Da ultimo, ma non per importanza, l'Engine Distribuited
che consente di distribuire le tabelle in shard.
Per i piu' curiosi la struttura delle principali directory e file di ClickHouse e' riassunta in questo schema:
Nello schema si possono notare l'organizzazione per database/tabella/parte/colonna ed i vari file di servizio...
Ulteriori dettagli sono riportati nella documentazione ufficiale.
Poiche' la famiglia di Engine MergeTree e' la piu' importante merita una trattazione a parte.
Il nome dell'Engine indica la modalita' di trattamento dei dati che e' ottimizzato
per trattare grandi quantita' di dati.
I dati vengono inseriti in modo ordinato in parts che, solo successivamente
con un merge, vengono unite alla partition (indicativamente entro 15 minuti).
I merge avvegono indicativamente entro 15 minuti mentre le parts inattive vengono
tipicamente cancellate dopo 10 minuti. Eventuali dati corrotti vengono posti nella
directory detached.
Si tratta di un algoritmo classico per l'ordinamento dei dati...
si capisce bene con un esempio.
Supponiamo di avere un grosso mazzo di carte ordinato a cui vogliamo aggiungere
un altro mazzetto. Possiamo inserire ad una ad una le carte ma occorrera' tempo.
E' piu' efficiente se ordiniamo anche il secondo mazzetto e quindi effettuiamo
l'inserimento ordinato: ecco il Merge.
C'e' un ulteriore vantaggio, le Part da modificare vengono copiate
e quando abbiamo terminato possiamo rilasciare i mazzetti intermedi all'MVCC,
in questo modo le query non sono rallentate dalle operazioni di INGEST dei dati.
Le tabelle MergeTree sono sempre partizionate. La chiave di partizionamento piu' utilizzata e' il timestamp con granularita' mensile. E' sconsigliato superare le 1000 partizioni per tabella. In system.parts e' riportato l'elenco completo delle partitions e delle loro parts. Il name delle parts (eg. 201801_1_8_2) e' composto da:
Gli inserimenti non bloccano mai le query, che vengono eseguite sulle parts attive.
Le UPDATE e DELETE in ClickHouse hanno la sintassi ALTER TABLE
e vengono chiamate mutation.
Le mutation
vengono registrate immediatamente sul file system (o su ZooKeeper se in replica)
ma vengono eseguite successivamente in modo ordinato tra loro (FIFO)
senza interferire con le query.
Le mutation persistono eventuali riavvi del server,
non e' possibile effettuarne il rollback ma solo il KILL
che interrompe la modifica nel punto in cui si trova.
Quanto riportato vale per tutti gli Engine di tipo MergeTree che si distinguono tra loro per altre funzionalita' come la replica (eg. ReplicatedMergeTree), la deduplica (eg. ReplacingMergeTree), l'aggregazione (eg. AggregatingMergeTree), ...
Il file di configurazione e' /etc/clickhouse-server/config.xml. E' possibile modificare i parametri online con il comando SET ma al riavvio i parametri riprenderanno i valori di default. In genere non e' necessario modificare la configurazione iniziale se non per impostare il data path, il binding per il listen ed eventuali cambi di porte socket.
Una volta installato ClickHouse puo' essere immediatamente utilizzato.
E' possibile accedere alla base dati senza utente/password e solo da localhost
[NdA in realta' per default si usa l'utente default che e' configurato senza password].
Le utenze non sono gestite all'interno del database ma
vanno configurate nel file /etc/clickhouse-server/users.xml
indicando il nome dell'utente e la password.
Di solito le attivita' in corso sul sistema si controllano con SHOW PROCESSLIST
e l'elenco delle tabelle con SHOW DATABASES, SHOW TABLES, SHOW CREATE TABLE.
Ma in realta' e' disponibile un completo Data Dictionary, nel database system,
che contiene gli oggetti definiti (eg. tables, columns, parts),
le attivita' (eg. processes, merges), ...
C'e' anche l'analogo della tabella DUAL (che e' noto contenere 'X')...
pero' sicuramente si sono sbagliati perche' la tabella si chiama ONE
ma contiene 0 :)
Sono particolarmente importanti per il monitoraggio le seguenti tabelle:
system.metrics, system.events e system.asynchronous_metrics [NdE oltre alla gia' citata system.parts].
CH puo' esportare le metriche su Graphite.
Sono disponibili i truculenti comandi KILL QUERY (eg KILL QUERY where query_id = 'xxx' dove il query_id si ottiene con SHOW PROCESSLIST) e KILL MUTATION. Il primo uccide le query, il secondo uccide le DELETE e le UPDATE che, in ClickHouse, sono comandi di ALTER ed eseguiti in modo asincrono.
Per una configurazione di produzione sono consigliate le impostazioni di sistema definite nella documentazione ufficiale. Un prerequisto di ClickHouse sono le CPU x64 e la presenza delle SSE 4.2 (Streaming SIMD Extensions). Le SSE 4.2 sono disponibili in tutti i processori piu' recenti, per verificarlo:
cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
...
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush
mmx fxsr sse sse2 ss ht syscall nx lm constant_tsc rep_good nopl pni pclmulqdq
ssse3 cx16 sse4_1 sse4_2 popcnt aes hypervisor lahf_lm retpoline kaiser
bugs : cpu_meltdown spectre_v1 spectre_v2
...
Nota importante: dalla versione 20.4 sono disponibili i comandi GRANT e CREATE USER
come descritto in questa paginetta.
Quanto segue e' valido comunque per tutte le versioni di Clickhouse
mentre i GRANT possono essere utilizzati solo dalla 20.x.
Le utenze sono configurate nel file /etc/clickhouse-server/users.xml
indicando il nome dell'utente e la password.
La password puo' essere indicata in chiaro o, meglio, crittografata con:
echo -n "MySecurePassword" | sha256sum | tr -d '-'
[NdA sha256sum e' disponibile anche su MacOS:
brew install coreutils].
Ecco un esempio di configurazione:
Sono molteplici le configurazioni possibili e le personalizzazioni sia a livello di
profilo,
di quota
che di utente stesso.
I profili presenti per default sono default e readonly.
Tra le diverse impostazioni e' particolare quella del readonly perche' assume 3 valori
[NdA molti tool funzionano solo con 0 (RW) o 2 (RO+change config) come impostazione e non con 1 (RO)].
E' invece normale l'impostazione di allow_ddl...
Tra le impostazione dell'utente e' possibile indicare l'elenco dei database
utilizzabili:
Per default si accede a tutti i database. Le impostazioni di readonly e l'elenco dei database sono disgiunti: non e' possibile consentire un database in lettura ed un altro in lettura/scrittura [NdA sono previste variazioni in roadmap].
Ovviamente su una base dati analitica la gestione degli spazi e' fondamentale perche' la grande quantita' di dati lo impone.
Il primo grosso vantaggio di CH e' che comprime in modo molto significativo i dati.
La compressione e' automatica ed e' configurabile anche se il default (LZ4) e' adatto
alla maggioranza delle situazioni.
Naturalmente la compressione avviene per colonna,
il che consente maggiori risparmi rispetto alla rappresentazione ISAM:
per ogni colonna e' possibile effettuare una scelta differente
tra i diversi algoritmi disponibili.
La verifica della quantita' di spazio risparmiato si effettua con:
SELECT database, table, column, type,
column_data_compressed_bytes compressed,
column_data_uncompressed_bytes,
(column_data_uncompressed_bytes-column_data_compressed_bytes)*100/column_data_uncompressed_bytes ratio
FROM system.parts_columns
WHERE active
AND database<>'system'
AND column_data_uncompressed_bytes>0
ORDER BY database, table, column;
CH utilizza gli statement standard di TRUNCATE sia a livello di tabella che di partizione. Il partizionamento consigliato e': PARTITION BY toYYYYMM(Date Column) [NdA una volta era l'unico possibile]. Naturalmente possono essere cancellate le partizioni con i dati da storicizzare, il comando e'
Un parametro molto utile nella creazione di una tabella e' il TTL (Time To Live) ovvero la retention automatica del dato [NdA introdotto nella versione 19.6.2.11 2019-05 con alcuni fix nelle versioni successive]. Puo' essere impostato a livello di tabella e/o di singola colonna: viene applicato il primo che scade. La cancellazione non e' immediata ma avviene solo in fase di merge delle Part. Un esempio di impostazione e':
CREATE TABLE iot_data( timestamp DateTime, device String, ... value UInt32) ENGINE = MergeTree PARTITION BY toYYYYMM(timestamp) ORDER BY (timestamp, device) TTL timestamp + toIntervalMonth(6) SETTINGS index_granularity = 8192;
Anche se con le ultime versioni sarebbe tecnicamente possibile... e' comunque sconsigliabile effettuare cancellazioni con la DELETE [NdA che in ClickHouse la sintassi e' ALTER TABLE ... DELETE]. In effetti una mutation prima occupa piu' spazio e, se tutto va bene, lo libera dopo "lentamente" ma sopratutto e' molto meno efficiente.
Per sicurezza non e' possibile cancellare oggetti piu' grandi di 50GB, in effetti ricaricarli puo' essere impegnativo... Per farlo o si crea un file con touch /home/clickhouse/flags/force_drop_table oppure si imposta a 0 il parametro max_[table/partition]_size_to_drop [NdA meglio il touch del file, il controllo e' utile].
Il log e' mantenuto nel file /var/log/clickhouse-server/clickhouse-server.log che contiene eventuali errori e segnalazioni. Il livello di dettaglio e' definito nella sezione <logger> ed il default e' trace [NdA in effetti un po' elevato si puo' abbassare a information. I livelli disponibili sono: trace, debug, information, notice, warning, error, critical, fatal, none]. Il file /var/log/clickhouse-server/clickhouse-server.err.log contiene solo gli errori, con i relativi stack trace, ed e' di dimesioni piu' ridotte.
La destinazione del trace di tutte le query e dei thread eseguiti e' definita per default ma vengono tracciate solo le sessioni che hanno impostato esplicitamente log_queries=1. Per impostare il tracing per tutti gli accessi [NdA consigliabile su un sistema di produzione] si puo' configurare come segue il profilo di default nel file users.xml:
A differenza di un OLTP con un OLAP il tracing di tutti gli accessi non e' eccessivo
[NdA CH non effettua il logging delle INSERT].
Se si vuole monitorare l'intero cluster e' possibile utilizzare una tabella distribuita:
CREATE TABLE system.query_log_all AS system.query_log ENGINE = Distributed(ClusterName, system, query_log);
E' anche possibile monitorare tutte le attivita' sulle Parts, abilitando la sezione <part_log>. Per default e' disabilitata anche perche' le attivita' sulle Parts sono molto frequenti in CH.
Sul client e' possibile abilitare il logging della sessione con set send_logs_level='trace'. E' molto dettagliato e, anche se non fornisce un vero query plan, e' molto utile anche per l'ottimizzazione delle query.
Il disegno logico delle tabelle in ClickHouse e' quello tipico dei
Data Warehouse
[NdA il link e' ad un documento dello scorso millenio, ma ancora valido].
Sono tipicamente utilizzate grandi FACT TABLE con tutte le colonne necessarie all'analisi.
Una tabella ClickHouse puo' avere centinaia di colonne senza che questo comporti rallentamenti.
A differenza dei formati basati sull'ISAM la memorizzazione per colonne non subisce rallentamenti se
il tracciato record e' di elevate dimensioni e vengono aggiunte colonne.
Anche la denormalizzazione non porta a svantaggi, anzi consente un accesso piu' veloce evitando i join.
Anche se sintatticamente sono supportati i JOIN in ClickHouse
[NdA inizialmente un solo join ma ora anche i multijoin e tutte le subquery]
non sono efficienti come le altre operazioni.
Risultano piu' efficienti i DICTIONARY che effettuano i lookup tipici delle star o snowflake queries.
Parere personale: utilizzare una sola tabella senza tabelle per le dimensioni,
la ridondanza dei dati viene risolta dalla rappresentazione colonnare.
Insomma le classiche fact table dei DWH.
Con ClickHouse tipicamente non si creano indici.
Non servono: praticamente ogni colonna e' un indice per come
e' memorizzata e trattata.
Per default tutti i dati sono compressi ma e' anche possibile indicare il tipo di compressione
singolarmente per ogni colonna.
Considerato che i dati sono fisicamente memorizzati per colonna e sono quindi molto
omogenei, i fattori di compressione sono tipicamente molto elevati.
I datatype di ClickHouse sono molto efficienti e vanno scelti con cura...
minore e' la dimensione della colonna maggiore sara' la compressione
e migliori le prestazioni.
Sono presenti tutti i datatype tipici di un relazionale;
i datatype numerici sono distinti per numero di bit (eg. UInt32, Float64);
le String non hanno limiti ed encoding [NdA ma puo' essere specificato
il COLLATE nell'ORDER BY];
i NULL sono gestiti come un datatype aggiuntivo: Nullable(TypeName);
sono disponibili anche strutture complesse: Array(T).
Quando possibile e' molto vantaggioso utilizzare i datatype Enum8 (che corrisponde ad un Int8)
che rappresentano con un solo numero stringhe di qualsiasi lunghezza.
E' di recente introduzione l'indicazione di LowCardinality che puo' essere impostata
anche online con:
ALTER TABLE emp MODIFY COLUMN job LowCardinality(String)
Ancora piu' recenti [NdA 2019-07 19.11] sono altri algoritmi di encoding come: Delta (timeseries), DoubleDelta (counters), Gorilla (gauges), T64 (non random integers). E' possibile applicare l'encoding e la compression (LZ4 o ZSTD) in sucessione ad una colonna con la sintassi: DateTime Codec(DoubleDelta, LZ4).
ClickHouse non memorizza i valori NULL per nessun datatype nativo.
Per implementare le colonne definite come Nullable ClickHouse utilizza una colonna ulteriore
[NdA sintatticamente Nullable e' una data type function, come LowCardinality].
Le colonne con valori a NULL sono meno efficienti e, se possibile, i NULL non vanno utilizzati.
Possono essere aggiunte colonne calcolate utilizzando la clausola MATERIALIZED;
le colonne definite in questo modo non vengono estratte con una SELECT *
ma vanno richiamate esplicitamente e, ovviamente, non possono essere utilizzate nelle INSERT
[NdA su altri database relazionali vengono chiamate virtual columns
ed utilizzano generalmente la clausola GENERATED].
E' possibile utilizzate un valore di DEFAULT per una colonna che vale sia in inserimento
che nella lettura; questo e' particolarmente comodo per tabelle di grandi dimensioni
cui vengono aggiunte nuove colonne con un ALTER TABLE ADD COLUMN...
Gli Engine della famiglia Merge hanno un partizionamento nativo che puo' essere indipendente
dalla primary key.
Naturalmente se le colonne di partizionamento sono utilizzate nelle query, ClickHouse effettua
il pruning e riduce ulteriormente i tempi di esecuzione.
Nella progettazione e' molto importante definire una granulatita' di partizionamento
adeguata (eg. 2 partizioni non danno vantaggi prestazionali e 10.000 uccidono
il sistema ospite sul numero degli open file).
La chiave di ordinamento o primary key non e' necessariamente univoca ed ed e' distinta dalla chiave di partizionamento. Per default l'ordinamento e' lo stesso del partizionamento ma puo' essere specificato indicando un numero maggiore di colonne.
E' possibile definire colonne virtuali, che corrispondono a calcoli eseguiti su altre colonne ma non sono memorizzati, e viste, che corrispondono a query salvate.
Particolarmente efficienti per i raggruppamenti sono le MATERIALIZED VIEW
che vengono aggiornate quando sono eseguiti i batch di INSERT sulla tabella
su cui sono definite.
Gli eventuali raggruppamenti sono eseguiti solo per gruppi di dati inseriti
quindi va utilizzato un Engine di aggregazione (eg. SummingMergeTree)
e GROUP BY anche nelle ricerche
(perche' l'aggregazione non e' necessariamente immediata).
Lo sharding viene definito utilizzando l'Engine Distribuited.
In pratica vanno create e popolate le tabelle locali e poi definito l'oggetto distribuito.
Il suo utilizzo richiede quindi una corretta definizione da parte del progettista del database.
Lo sharding quindi non e' automatico ma va definito in fase di creazione degli oggetti
pero' le prestazioni sono ottime perche' ClickHouse scala in modo lineare eseguendo
parte delle query sui diversi nodi coinvolti.
Una volta installato ClickHouse puo' essere utilizzato immediatamente. Rispetto ad una configurazione standard non vi sono parametri particolari su cui effettuare il tuning. Come gia' riportato e' invece molto importante il disegno fisico della base dati ovvero la scelta degli Engine e delle chiavi di partizionamento.
ClickHouse ha un uso aggressivo delle CPU e della memoria: meglio utilizzare un sistema dedicato.
Ad ogni query ClickHouse restituisce il numero di record trattati ed il throughput. I valori dipendono dall'HW disponibile ma sono tipicamente >> 1GB/sec.
Naturalmente processori veloci ed una grande quantita' di memoria
consentono buone prestazioni anche con DB di grandi dimensioni e query complesse.
Se la base dati e' di modeste dimensioni (eg. sotto i 100GB) viene tenuta
praticamente in memoria, altrimenti ClickHouse accede al disco.
Ovviamente i dischi migliori sono gli SSD, ma anche normali dischi SATA
vengono acceduti in modo efficiente.
In generale meglio scalare orizontalmente utilizzando piu' server con dischi locali.
A differenza dei relazionali tradizionali
ClickHouse puo' struttare
un elevato numero di Core
anche su una sola query pesante.
La dimensione del DB non e' limitata dalla RAM ma sicuramente un'ampia dotazione
di memoria rende piu' veloci tutte le elaborazioni (eg. 128GB).
Gli algoritmi vettorizzati e paralleli di ClickHouse tendono ad utilizzare tutte le risorse di sistema quando vi sono attivita' da eseguire. E' quindi opportuno installare ClickHouse su server dedicati. In caso di utilizzo ZooKeeper (serve per le repliche) va installato su nodi diversi da quelli di ClickHouse.
Per un'installazione di produzione come pacchetti sono da preferire i DEB ufficiali
(quindi i sistemi linux Debian o Ubuntu),
ma sono disponibili anche gli RPM per CentOS/RH/Fedora/... o i sorgenti.
Altre configurazioni di dettaglio sul sistema operativo:
utilizzare il performance scaling governor, disabilitare le Huge Pages,
utilizzare lo scheduler CFQ (noop per gli SSD), ...
Ulteriori dettagli sono riportati nella documentazione ufficiale.
Con ClickHouse si accede al database utilizzando l'interfaccia nativa sulla porta 9000 come fa il client clickhouse-client, o con l'interfaccia HTTP sulla porta 8123.
ClickHouse supporta i principali formati di file per effettuare un veloce caricamento/scaricamento dei dati. Tra gli altri TabSeparated, JSON, TSKV, Pretty, Native, CSV, ... Vediamo un esempio con quest'ultimo:
ClickHouse puo' essere richiamato da molteplici linguaggi di programmazione, anche se non supportati direttamente da Yandex ma forniti da terze parti.
 Sono disponibili i driver per l'accesso
JDBC ed
ODBC.
Sono disponibili i driver per l'accesso
JDBC ed
ODBC.
Utilizzando tali driver e l'SQL si puo' accedere da tutti i piu' diffusi strumenti
di BI e di accesso ai dati (eg. Tableau, DBeaver)
anche se, a volte, e' necessario qualche accorgimento per far
sopportare il dialetto SQL di ClickHouse e le sue impostazioni di default
(eg. readonly=2).
Sono disponibili due integrazioni native in ClickHouse: con il database
MySQL
e con il sistema di messaggistica
Kafka.
Leggere i dati da una tabella MySQL utilizzando l'apposito Engine e' molto semplice:
L'integrazione con MySQL e' disponibile anche a livello di database [NdA 19.10.1.5, 2019-07]: e' possibile definire come database remoto un database MySQL da cui leggere i dati. Anche se con ovvie limitazioni e' cosi' possibile accedere direttamente in lettura ad un intero database MySQL.
Molto interessante e' la possibilita' di utilizzare il wire protocol MySQL per connettersi a ClickHouse [NdA 19.8.3.8, 2019-06].
Veramente notevoli sono le integrazioni come replica secondaria implementate negli Engine MaterializeMySQL [NdA 20.8] e MaterializedPostgreSQL [NdA 21.8]. ClickHouse si comporta come uno slave di replica ed analizzando i binlog o i WAL mantiene aggiornate le proprie tabelle MergeTree. L'implementazione e' notevole perche' sono differenti i datatype, l'SQL delle DDL e... anche le UPDATE/DELETE che non esistono in ClickHouse e vengono gestite con un flag di segno per la cancellazione logica. Si tratta di Engine introdotti come feature sperimentali ma aggiornati con continuita' e sempre piu' completi.
L'integrazione con Kafka e' realizzata con la libreria librdkafka, maggiori dettagli sono riportati in questa pagina. In pratica una tabella viene agganciata ad un topic Kafka ed ogni lettura consumera' i messaggi raccolti fino a quel momento.
Anche se non ancora completamente implementate sono gia' descritte nella documentazione master ulteriori integrazioni: JDBC, ODBC e HDFS. Ovviamente quest'ultima e' particolarmente interessante perche' tutto il mondo dei Big Data e' basato su Hadoop/HDFS.
Particolarmente interessanti sono anche le integrazioni fornite da terze parti
tra cui
clickhouse-mysql-data-reader,
che mantiene i dati allineati da un DB MySQL mediante replica,
CHproxy
per controllare gli accessi,
ProxySQL,
che dispone del supporto per ClickHouse
e quindi consente di collegarsi a ClickHouse con un client MySQL.
Utilizzando la tecnica dei Foreign Data Wrapper
con questo clickhousedb_FDW
e' possibile accedere a ClickHouse da PostgreSQL.
Grafana e' uno strumento di visualizzazione di dati temporali Open Source molto potente e molto diffuso. Per l'accesso a ClickHouse e' fornito un apposito plugin. Il plugin fornisce inoltre una serie di macro (eg. $timeSeries, $timeFilter, $rate, ...) che permettono di semplificare la scrittura delle query temporali richieste da Grafana:
Il plugin si aggiorna con:
grafana-cli plugins update vertamedia-clickhouse-datasource
Hot news [2022-05]: la documentazione di Clickhouse e' in costante aggiornamento; in particolare sono particolarmente migliorate le parti relative alle integrazioni (Airbyte, dbt, JDBC, Kafka, MySQL, PostgreSQL, S3, Vector) ed alla connessione alle interfacce grafiche (Grafana, Metabase, Superset, Tableau).
ClickHouse offre due importanti funzioni di distribuzione la replica e lo sharding. E' possibile utilizzare piu' nodi in un cluster omogeneo ClickHouse.
La replica e' rivolta all'HA (High Availability).
E' vero che generalmente un OLAP non ha requisiti di disponibilita' stringenti,
tuttavia se le basi dati sono di grandi dimensione ed il numero di nodi
e' elevato, un problema HW/SW potrebbe richiedere molto tempo prima
di essere fissato.
Quando ClickHouse viene utilizzato per data ingestion
la disponibilita' del database 7x24 sia in lettura che in scrittura
e' invece fondamentale.
Ecco quindi che risulta utile la funzionalita' di replica.
La replica di ClickHouse e' asincrona e multi-master.
Lo sharding consente di scalare orizontalmente
quando un solo server non e' piu' sufficiente...
Quando la quantita' di dati non puo' piu' essere mantenuta su un solo nodo
o si vogliono migliorare le prestazioni e' possibili suddividere il dati
ed il carico su piu' nodi.
Dal punto di vista prestazionale, grazie agli algoritmi di calcolo parallelo,
ClickHouse scala quasi linearmente sul numero di nodi.
Sia la replica che lo sharding sono definiti per singola tabella. E' quindi possibile avere una serie di tabelle replicate, una serie di tabelle in sharding e tabelle locali ai singoli nodi Clickhouse.
Vediamo la configurazione di entrambe...
La replica e' rivolta all'HA (High Availability). Ecco come definire una tabella in replica:
CREATE TABLE ontime_replica (...)
ENGINE = ReplicatedMergeTree(
'/clickhouse_perftest/tables/{shard}/ontime',
'{replica}',
Timestamp,
(Year, Timestamp),
8192);
Su ogni nodo del cluster e' ora possibile interrogare la tabella in replica. Se avviene una modifica questa verra' replicata su tutti gli altri nodi (non immediatamente ma in modo asincrono).
E' importante ricordare che la replica e' multimaster:
quindi l'inserimento dei dati puo' avvenire su un un nodo qualsiasi
anche in parallelo.
Utilizzare nodi in replica consente anche di scalare sulle attivita'
in lettura;
non vengono invece scalate le prestazioni per le scritture,
scalare anche in scrittura e' necessario attivare lo sharding.
Lo sharding e' rivolto al miglioramento delle performance. In ClickHouse la definizione e' piuttosto semplice e si esegue in due passi:
CREATE TABLE bigdata_local (...) ENGINE = MergeTree(Timestamp, (Year, Timestamp), 8192);
CREATE TABLE bigdata_all AS ontime_local
ENGINE = Distributed(bigdata_3shards, default, bigdata_local, rand());
A questo punto qualsiasi attivita' svolta su bigdata_all in realta' viene distribuita
sulle tabelle locali con un miglioramente sulle performance pari al numero di nodi impiegati.
Tutti gli algoritmi utilizzati da ClickHouse
utilizzano thread diversi per agire sulle singole Parts:
come una singola query alloca tutti i processori su un server singolo
cosi', in presenza di un cluster, tutti i nodi collaborano per analizzare
i dati fino a restituire al nodo di partenza il risultato.
Per completezza e' necessario ricordare che le definizioni del cluster debbono essere
state preventivamente configurate sui nodi prima di poter utilizzare la
replica e lo sharding da SQL...
Questa e' una configurazione per la replica (con due repliche):
Per la replica e' inoltre necessario configurare ZooKeeper [NdA basta riportare il nome dei nodi e le porte nel file di configurazione]. ZooKeeper e' necessario per mantenere la consistenza delle repliche (eg. su un nodo singolo una ALTER TABLE e' sincrona, quando si utilizzano le repliche e' ZooKeeper che la prende in carico ed attende che sia eseguita su tutte le repliche).
Questa e' una configurazione per lo sharding (su tre nodi):
Ovviamente e' possibile utilizzare entrambe le configurazioni contemporaneamente;
ad esempio si possono avere quattro shard e tre repliche con un totale di 12 nodi in cluster.
Per accedere ai nodi in cluster e' possibile utilizzare BalancedClickhouseDataSource
nelle connessioni JDBC: in questo modo si accede ad un nodo scelto a random dalla lista dei nodi forniti.
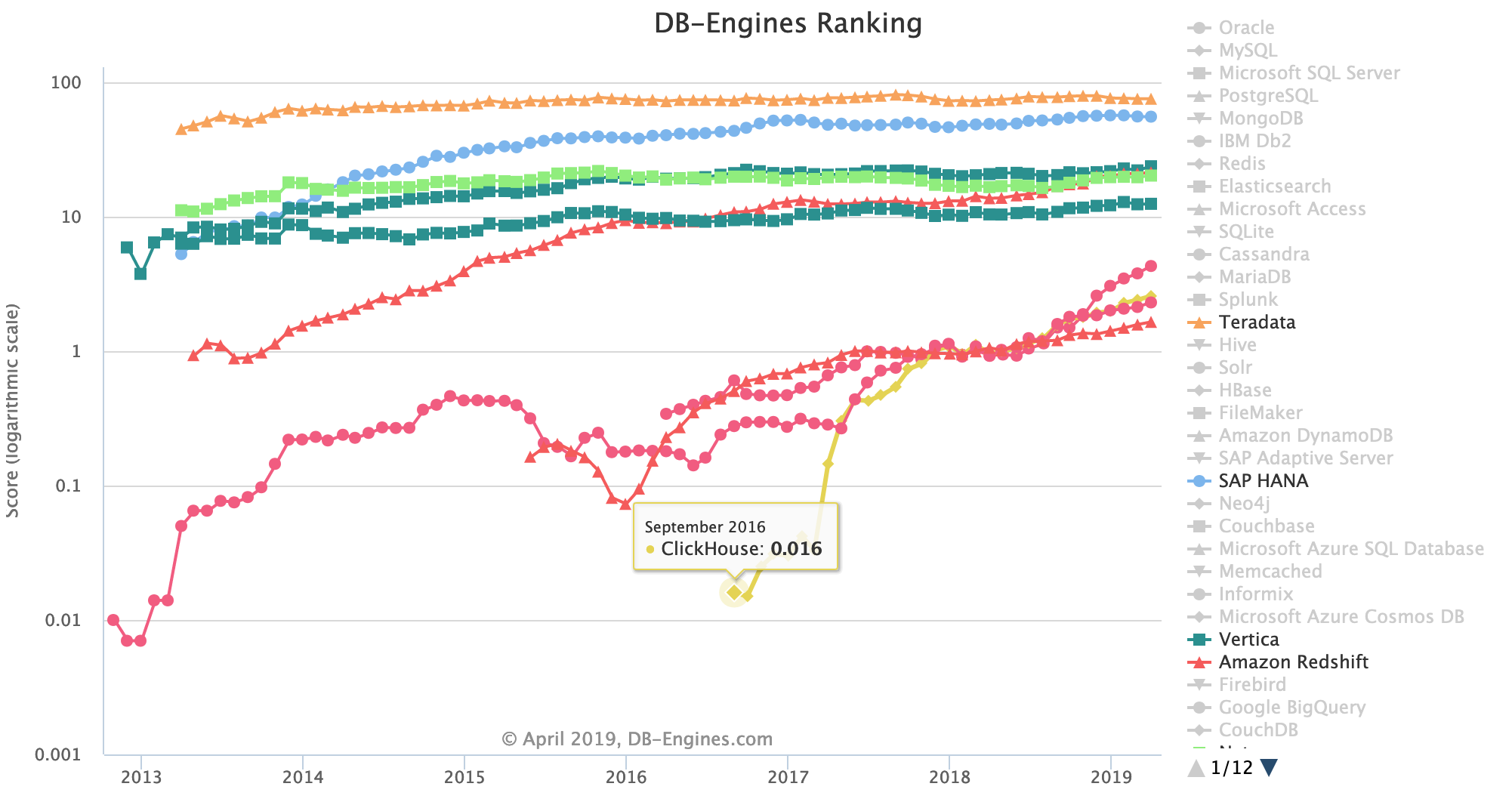 Yandex ha pubblicato una serie di test comparativi
di ClickHouse con altri DB OLAP.
Altri benchmarks sono stati pubblicati da
Altinity e da
Percona.
Yandex ha pubblicato una serie di test comparativi
di ClickHouse con altri DB OLAP.
Altri benchmarks sono stati pubblicati da
Altinity e da
Percona.
ClickHouse si distingue per le prestazioni quasi realtime,
in particolare rispetto ai database Big Data basati su Hadoop
che hanno generalmente una latenza molto maggiore.
Sulle query massive ClickHouse ottiene analoghi o migliori risultati anche rispetto
ai database In Memory, senza avere la limitazione di mantenere tutto il database in memoria.

Anche sull'ingestion dei dati ClickHouse ha ottime prestazioni ed effettua una notevole compressione dei dati. Nei benchmark (eg. TSBS: Time Series Benchmark Suite) risulta ben confrontabile con i principali DB verticali, pur non essendo un database Time Series.
I requisiti per installare ClickHouse sono molto ridotti ed e' possibile sfruttarne le capacita' anche su un singolo nodo. Quando le richieste salgono ClickHouse cresce lineramente con l'aggiunta di nodi [NdA anche non in modo elastico]. L'unico componente aggiuntivo di infrastruttura e' un cluster ZooKeeper per la gestione delle repliche.
I miei benchmark? EMP7 in 10 secondi... ClickHouse non e' granche' nell'eseguire i join!
Pero' e' terribilmente piu' veloce di un relazionale tradizionale (x100 o x1000) su query OLAP,
utilizzando fact table piatte o con DICTIONARY anziche' join si ottengono le migliori prestazioni (ulteriore x10),
utilizzando i datatype migliori si hanno ulteriori vantaggi prestazionali (ulteriore x2),
...
Dal punto di vista funzionale l'evoluzione e' rivolta a rendere piu' utilizzabile il prodotto (eg. ODBC).
Dal punto di vista funzionale... cosa c'entra con i benchmark?
Anche gli aspetti di integrazione ed di utilizzabilita' sono importanti!
ClickHouse supporta un dialetto SQL di base ma ricco di funzioni ottimizzate
per il trattamento dei dati e la loro conversione (il cast non e' automatico in CH).
Sono di recente introduzione la sintassi simplificata per i JOIN (con una sola condizione)
e la possibilita' di effettuare DELETE ed UPDATE dei dati (con una ALTER TABLE).
Recentissima e' l'introduzione di JOIN MULTIPLI (2019-03).
Nonostante la recente diffusione ClickHouse ha guadagnato molta popolarita' in poco tempo.
I pochi difetti: un SQL non completo, la non completa integrazione con strumenti esterni,
non gestisce le transazioni, ...
Tra i molti suoi vantaggi: semplicita' di installazione/gestione, licenza Open (veramente libera),
compressione dei dati, interfaccia SQL con efficaci estensioni, scalabilita' verticale ed orizzontale,
HA, ...
e da ultimo, visto che il titolo del capitolo e' Benchmark, ClickHouse ha ottime prestazioni!
[NdA Ovvero 16 miliardi di righe al secondo... sul mio PC come immagine Docker]
Mantenersi aggiornati con le versioni e' sempre importante... [NdE: serve a rimanere giovani e tutto e' piu' veloce :-]
Questo vale anche per ClickHouse in cui l'evoluzione in questi ultimi due anni e' stata molto rapida non tanto sulle prestazioni, gia' impressionanti dalle prime versioni, ma sul supporto dell'SQL (ALTER UPDATE/DELETE, JOIN syntax, ...) e delle integrazioni (MySQL, ODBC, ...).
I rilasci di ClickHouse sono disponibili in linea sul Changelog. Nel documento Your Server Stinks! e' mantenuta un'apposita sezione aggiornata su ClickHouse:
| |
|
|
|
|
|
|
| 19 | Production | Low-cardinality, KILL MUTATION, ALTER compression codecs, LowCardinality ... (19.4.0.49 2019-03) Multiple JOINS. (19.6.2.11 2019-05) TTL. | 19.13.3.26 | 2019-01 | 2019-08 | |
| 18 | Production | New version numbering: year+version. JOIN syntax, ... (18.1.0 2018-07) ALTER DELETE. (18.12.14 2018-09) ALTER UPDATE. | 18.16.1 | 2018-07 | 2018-12 | |
| 1 | Production | (1.1.54245 2017-07) pubblic release. Dictionary, distribuited DDL, HTTP interface. (1.1.54310 2017-11) custom partitioning, Kafka Engine, arithmetic with time intervals. (1.1.54337 2018-01) MySQL tables, ODBC support. (1.1.54388 2018-06) ALTER DELETE on replicated tables. | 1.1.54394 | 2017-07 | 2018-07 | |
| 0 | Production | Developed intitially for internal use for Yandex.Metrica, Open sourced on 2016-06 (Apache license 2.0). | 2016-06 |
Su GitHub vengono di frequente pubblicate versioni in Testing e Stable. In qualche caso si e' verificata qualche regressione sulle versioni disponibili su GitHub anche se indicate come Stable... occhio! Come per tutti i software conviene attendere che gli aggiornamenti siano stati descritti sul ChangeLog, verificarne le caratteristiche e provare le versioni prima di installarle in produzione.
La procedure di installazione e' gia' stata descritta nel precedente documento... la procedura di update, tranne rare eccezioni, prevede semplicemente l'aggiornamento dei package con il servizio non attivo:
Se si utilizza un Cluster semplicemente va aggiornato un nodo alla volta e ZooKeeper (con le repliche) si occupa dell'allineamento dei dati.
Il documento Introduzione a ClickHouse contiene una presentazione sulle funzioni di base mentre DBA scripts contiene alcuni dei comandi piu' utili per il DBA.
Titolo: Architettura ClickHouse
Livello: Medio
Data:
1 Aprile 2019 🐟
Versione: 1.0.5 - 1 Aprile 2022 🐟
©
Autore: mail [AT] meo.bogliolo.name