 TiDB
e' un Database Open Source compatibile con MySQL
progettato per supportare transazioni OLTP
e per scalare linearmente distribuendo su piu' nodi i dati.
TiDB
e' un Database Open Source compatibile con MySQL
progettato per supportare transazioni OLTP
e per scalare linearmente distribuendo su piu' nodi i dati.
TiDB
e' un Database Open Source compatibile con MySQL
progettato per supportare transazioni OLTP
e per scalare linearmente distribuendo su piu' nodi i dati.
Dal punto di vista tecnico TiDB utilizza... insomma volete distribuire la vostra base dati in Cloud? Allora continuate a leggere!
Questo documento presenta gli aspetti introduttivi di TiDB: Introduzione, Installazione, Utilizzo, ... utilizzando un approccio pratico con molti esempi.
Il documento si riferisce alla versione di TiDB 2.1 ma i contenuti valgono anche per altre versioni.
TiDB e' un NewSQL database hybrid transactional and analytical processing (HTAP) Open Source sviluppato da PingCAP.
TiDB e' progettato per un carico HTAP
ovvero per supportare sia query OLTP (On-Line Transaction Processing)
che OLAP (On-Line Analytical Processing).
In pratica TiDB ha buone prestazioni con un numero elevato
di query CRUD e soddisfa le proprieta'
ACID (Atomicity, Consistency, Isolation, Durability) delle transazioni;
nello stesso tempo e' adatto ad eseguire query OLAP
distribuendo l'elaborazione su piu'
nodi come opportuno.
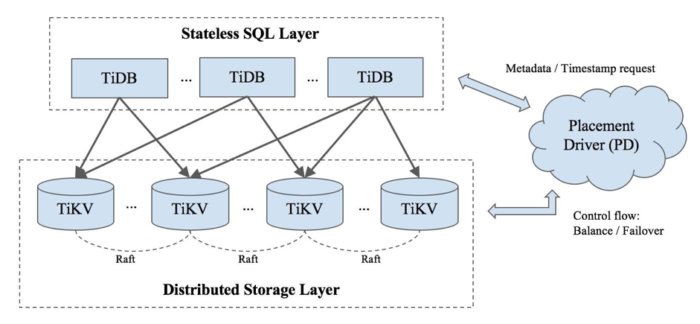 Dal punto di vista architetturale sono presenti tre tipologie di nodi:
Dal punto di vista architetturale sono presenti tre tipologie di nodi:
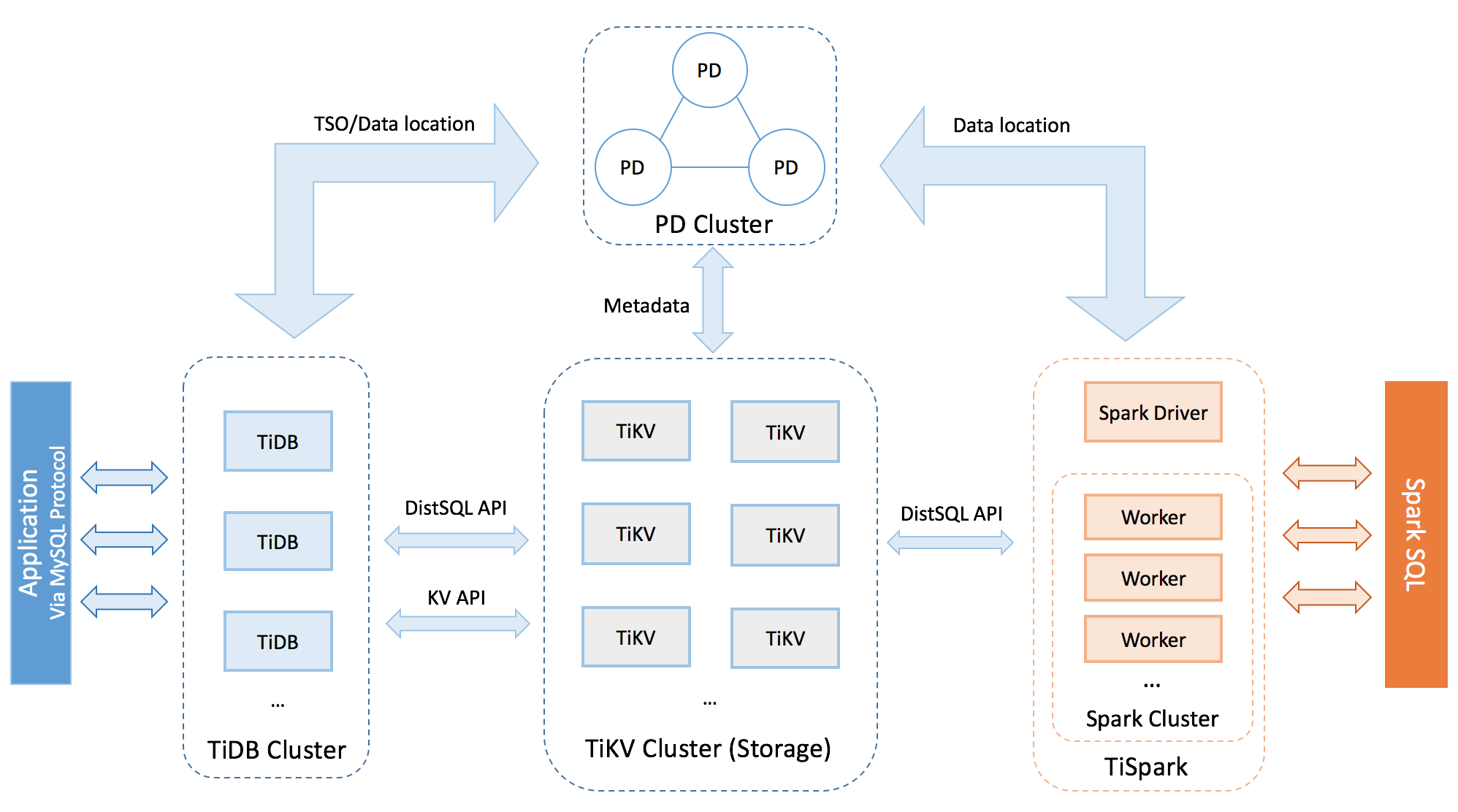
TiDB e' la componente di database che si occupa di raccogliere le connessioni utente,
di analizzare la sintassi delle richieste, di eseguire i passi di ottimizzazione
e richiedere i dati agli Engine di Storage.
Il protocollo di connessione a TiDB cosi' come il dialetto SQL
utilizzato sono quelli MySQL.
Questo significa che qualsiasi applicazione o tool utilizzato con
MySQL puo' essere utilizzato con TiDB.
Deve essere notato che TiDB tecnicamente *non* e' un fork MySQL,
anche se si comporta come un database MySQL le funzionalita' sono implementate
in modo diverso e sono presenti alcune differenze significative.
TiKV e' lo storage Engine.
Per la memorizzazione dei dati utilizza la tecnica Key-Value
di
RocksDB
[NdA un database embedded disponibile anche come Engine su MySQL Percona Server e su MariaDB].
I dati sono replicati su piu' nodi utilizzando il protocollo di consenso
Raft.
Le coppie chiave-valore vengono divise per range in Region di dimensioni fisse,
la region e' l'unita' minima di replicazione.
Per ogni region vi e' un nodo Leader a cui vengono indirizzate tutte le letture e le scritture,
mentre le altre copie del Region Group
saranno sincronizzate in two-phase-commit per garantire i dati anche in caso di fault.
Per la gestione delle transazioni viene usato il multi-version concurrency control (MVCC)
ed il locking ottimistico: sono due tecniche consolidate che garantiscono le propieta' ACID
e buone prestazioni.
Il Placement Driver si occupa tra le altre cose di gestire i metadati, schedulare le migrazioni delle region per evitare hotspot e riconfigurare i componenti nel caso di failure. Tutti compiti importanti!
Le metriche di utilizzo, da tutti i componenti, sono pubblicate per Prometheus sull'URL localhost:10080/metrics [NdA ed ovviamente sono facilmente visualizzabili in Grafana]. Se si utilizza il deploy con Ansible Prometheus e Grafana vengono installati in automatico.
Anche se non e' presente in tutte le configurazioni vi sono moduli aggiuntivi. Particolarmente interessanti e' TiSpark che risponde alle query OLAP utilizzando sempre i dati mantenuti dai TiKV.
Abbiamo visto un'accenno dell'architettura, che non e' cosi' semplice...
al contrario l'utilizzo di TiDB e' molto semplice per le applicazioni!
Basta connettersi ad un qualsiasi nodo TiDB con un client o un driver MySQL
e funziona senza differenze o quasi!
L'installazione di TiDB e' semplice... se si effettua per un ambiente di test su un Mac!
In realta' e' stato installato il solo componente TiDB
con un engine locale...
l'affidabilita', le prestazioni e
l'architettura complessiva sono notevolmente diverse;
ma e' cosi' possibile sperimentare le funzionalita' del database TiDB.
Ora basta collegarsi con un qualsiasi client MySQL alla porta 4000!
[NdA la porta di default di TiDB e' 4000 e non 3306]
Un deployment di produzione richiede un minimo di progettazione per definire il numero di nodi da dedicare a ciascun compito. TiDB permette diverse modalita' di installazione (eg. Kubernetes, Ansible, ...) e la scelta dipende anche dall'infrastruttura gia' presente.
Per un'installazione di produzione l'HA e' un requisito fondamentale e quindi i vari componenti
vanno configurati in modo che non si abbiano SPOF.
Il numero di nodi di database e di store e' indipendente:
in generale verranno aggiunti a seconda del tipo di carico.
Un aspetto importante per la scalabilita' e' che i componenti TiDB sono stateless
quindi possono essere aggiunti in modo dinamico.
I nodi TiKV ovviamente non sono stateless ma il PD li gestisce in modo
automatico: all'aggiunta di un nuovo nodo vengono replicate le region e,
quando sincronizzate, possono diventare Leader del Raft Group.
La configurazione di base di un nodo sono 16 core, 32GB di RAM, schede 10Gb e, per i nodi TiKV, fino a 2TB di dischi SSD. Alcune indicazioni sono minimali (eg. RAM), altre fortemente consigliabili (eg. schede 10Gb).
Sono disponibili diverse modalita' di installazione (Kubernetes, Ansible, Docker, Binary) come riportato nella documentazione ufficiale.
Per utilizzare TiDB bastano... semplici comandi SQL!
Vediamo come accedere:
A prima vista le differenze sono poche ma in realta' alcune sono semplicemente mascherate per ottenere una maggiore compatibilita' con i tool MySQL. Ad esempio creando una tabella sembrera' utilizzare l'Engine InnoDB... pero' non e' cosi!
Deve essere notato che TiDB *non* e' un fork MySQL, anche se si comporta come un MySQL 5.7, le funzionalita' sono implementate in modo diverso e sono presenti molteplici differenze.
Nella maggior parte dei casi
il dialetto SQL, i datatype, le funzioni, gli errori, gli isolation level,
...
anche il risultato della funzione version()
sono come quelli MySQL.
Vediamo nel seguito le differenze piu' significative.
Nella CREATE TABLE TiDB accetta la clausola ENGINE ed
il comando SHOW CREATE TABLE mostra le tabelle come
se fossero tutte InnoDB.
In realta' le tabelle utilizzano lo Storage TiKV.
I campi SERIAL non crescono per valori consecutivi e crescenti
ma sono allocati a gruppi dai diversi server.
L'EXPLAIN e' molto differente
[NdA personalmente preferisco quello di TiDB].
Le DDL sono asincrone!
La modifica di una struttura di una tabella,
per un database distribuito,
e' un'attivita' complessa e potenzialmente rischiosa.
TiDB ha risolto il problema
spezzando ogni richiesta in passi successivi
eseguiti in modo asincrono.
In TiDB il character set utilizzato e' UTF8 (quello vero e quindi equivalente a utf8mb4 di MySQL)
con collation binary.
Il locking di TiDB e' ottimistico, quindi vi sono minori condizioni di attesa
ma possono verificarsi rollback:
le applicazioni debbono evitare i conflitti e/o gestire l'eventuale segnalazione.
Una importante serie di funzionalita' MySQL non sono presenti in TiDB: Stored Procedures, Functions, Views, Triggers, Events, FOREIGN KEY constraints, FULLTEXT, CREATE TABLE AS SELECT, ...
Alcune delle incompatibilita' riportate verranno colmate a breve (eg. view in TiDB 3.0) ma altre sono dovute alle differenti architetture presenti e quindi resteranno tali. E' anche previsto vengano inserite in TiDB nuove funzionalita' che non sono presenti in MySQL 5.7; tra queste le windows function che sono molto utili per le query analitiche [NdA in effetti le windows functions sono presenti in MySQL 8 ed in MariaDB 10.2].
Maggiori dettagli sono riportati nella documentazione ufficiale.
Un'installazione di produzione prevede almeno tre nodi TiKV e due TiDB ma questo e' solo il punto di partenza. La principale caratteristica di TiDB e' quella di poter scalare orrizzontalmente aggiungendo ulteriori nodi quando necessario.
MySQL ha un'elevata
scalabilita' e puo' essere utilizzato in Cloud
con migliaia o milioni di accessi.
E' infatti possibile replicare in cascata decine o centinaia di database MySQL.
Tuttavia questo vale solo per le letture.
La parte di scrittura deve essere eseguita su un solo master che quindi puo' scalare
solo verticalmente.
Anche le piu' recenti evoluzioni quali
Galera Cluster e
MySQL InnoDB Cluster
non scalano prestazionalmente sulle scritture.
In effetti le prestazioni massime le fornisce la replica asincrona con un solo master...
L'alternativa e' lo sharding, che con MySQL puo' essere effettuato in modo applicativo.
Con TiDB lo sharding e' nativo e non richiede nessuna modifica applicativa. Le Region sono l'unita' minima utilizzata per bilanciare il carico. Il Placement Driver si occupa di definire le repliche leader sui TiKV cui vengono dirette le letture e le scritture dei TiDB. Se il carico non e' bilanciato e vi sono degli Hot Spot il PD modifica le assegnazioni delle Region. Quando viene aggiunto un nuovo TiKV inizialmente vengono solo replicati i dati, quindi il PD promuovera' alcune sue region a leader indirizzando cosi' il carico. In questo modo tutte le attivita' sui dati, sia di lettura che di scrittura, scalano in modo lineare all'aggiunta di nodi.
Ancora piu' semplice e' la gestione dei nodi di tipo TiDB:
poiche' sono componenti stateless possono essere aggiunti quando necessario
ed un normale load balancer puo' gestirne il bilanciamento.
I nodi PD non sono tipicamente un bottleneck e quindi tre nodi,
eventualmente in condivisione con i TiDB, sono sempre sufficienti.
I deploy piu' significativi di TiDB utilizzano centinaia di nodi fisici distribuiti su piu' datacenter.
TiDB e' adatto ad installazioni significative quando MySQL
non puo' piu' scalare verticalmente
o quando si ha un carico significativo di query OLAP.
Sono situazioni che si verificano con grandi basi dati di produzione
accedute da applicazioni complesse.
In tali ambienti e' difficile eseguire una minor update del database...
figuriamoci cambiarne l'architettura!
C'e' un'importante funzionalita' di TiDB: la possibilita' di configurarlo come Slave di una replica MySQL. In questo modo e' possibile effettuare un PoC (Proof of Concept) efficace su un ambiente complesso di grandi dimensioni.
In questo caso si utilizza il tool DM-worker che puo' connettersi come Slave
verso un server MySQL or MariaDB.
Un singolo DM-worker sincronizza i dati da un instanza MySQL su una o piu' istanze TiDB.
E' anche possibile utilizzare piu'
DM-workers per raccogliere i dati da diverse istanze MySQL e consolidarle
su un unica istanza TiDB.
La tecnica adottata per il PoC puo' anche essere utilizzata per la migrazione definitiva dei dati riducendo il periodo di disservizio.
TiDB e' un database giovane: ha buone prestazioni, e' scalabile ma presenta anche qualche limite... vedremo!
E' consigliata infine la lettura di uno dei primi articoli su TiDB che descrive l'implementazione delle modifiche asincrone delle strutture dati [NdA tranquilli: non e' in inglese :]
Titolo: TiDB
Livello: Medio
Data:
1 Aprile 2019
Versione: 1.0.0 - 1 Aprile 2019
Autore: mail [AT] meo.bogliolo.name